

Semi-supervised Indoor Fingerprint Database Construction Method Based on the Nonhomogeneous Distribution Characteristic of Received Signal Strength
-
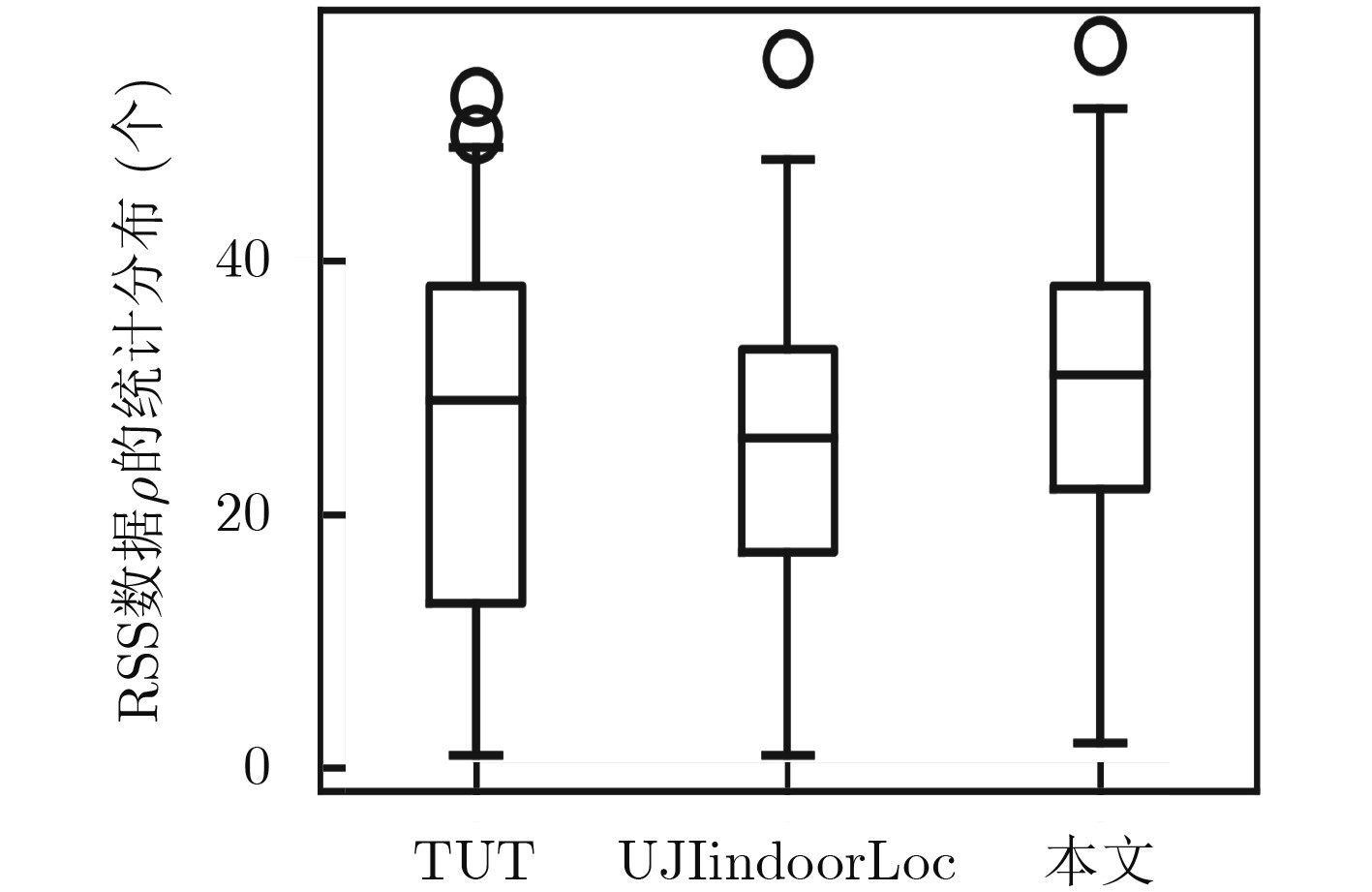
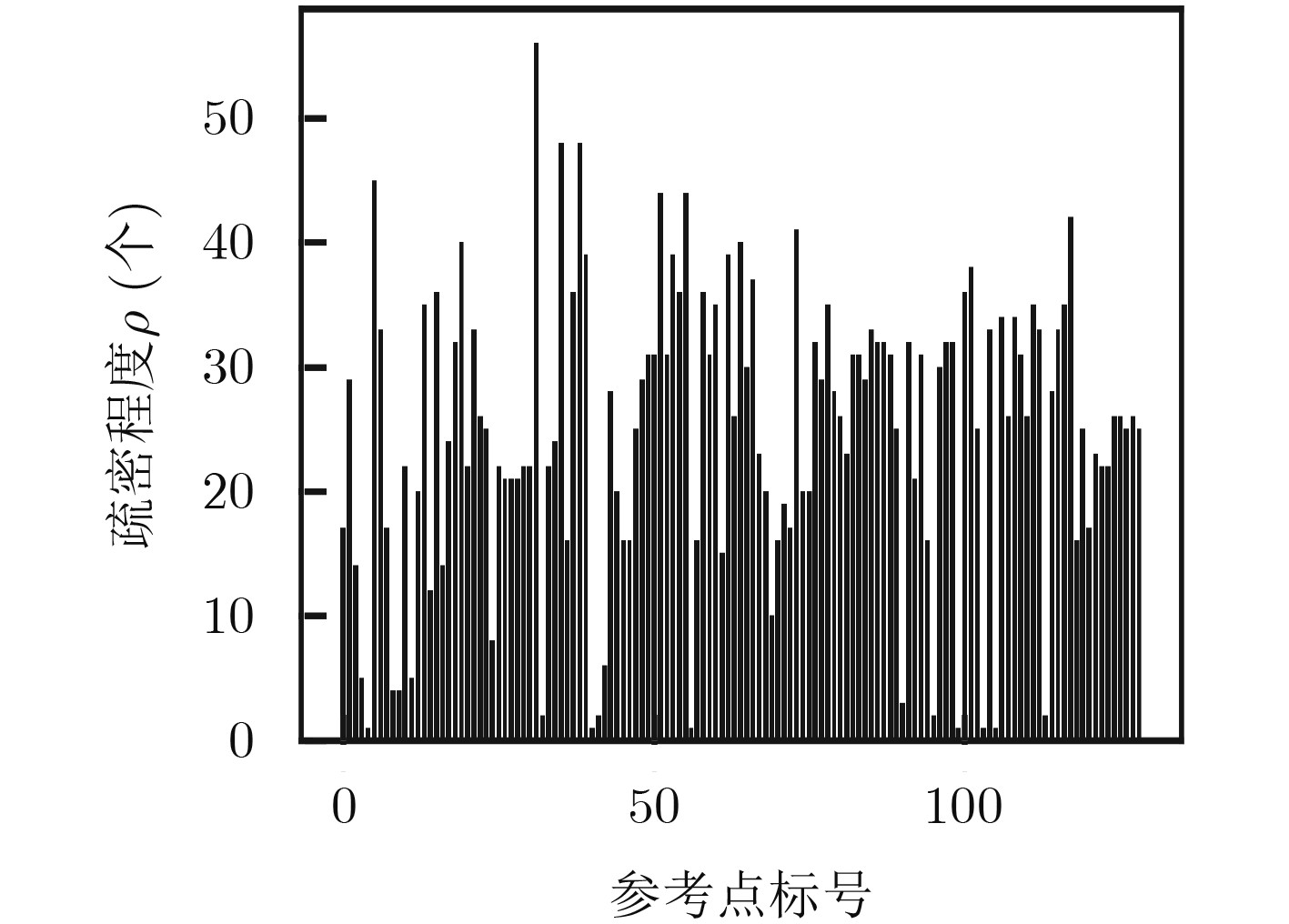
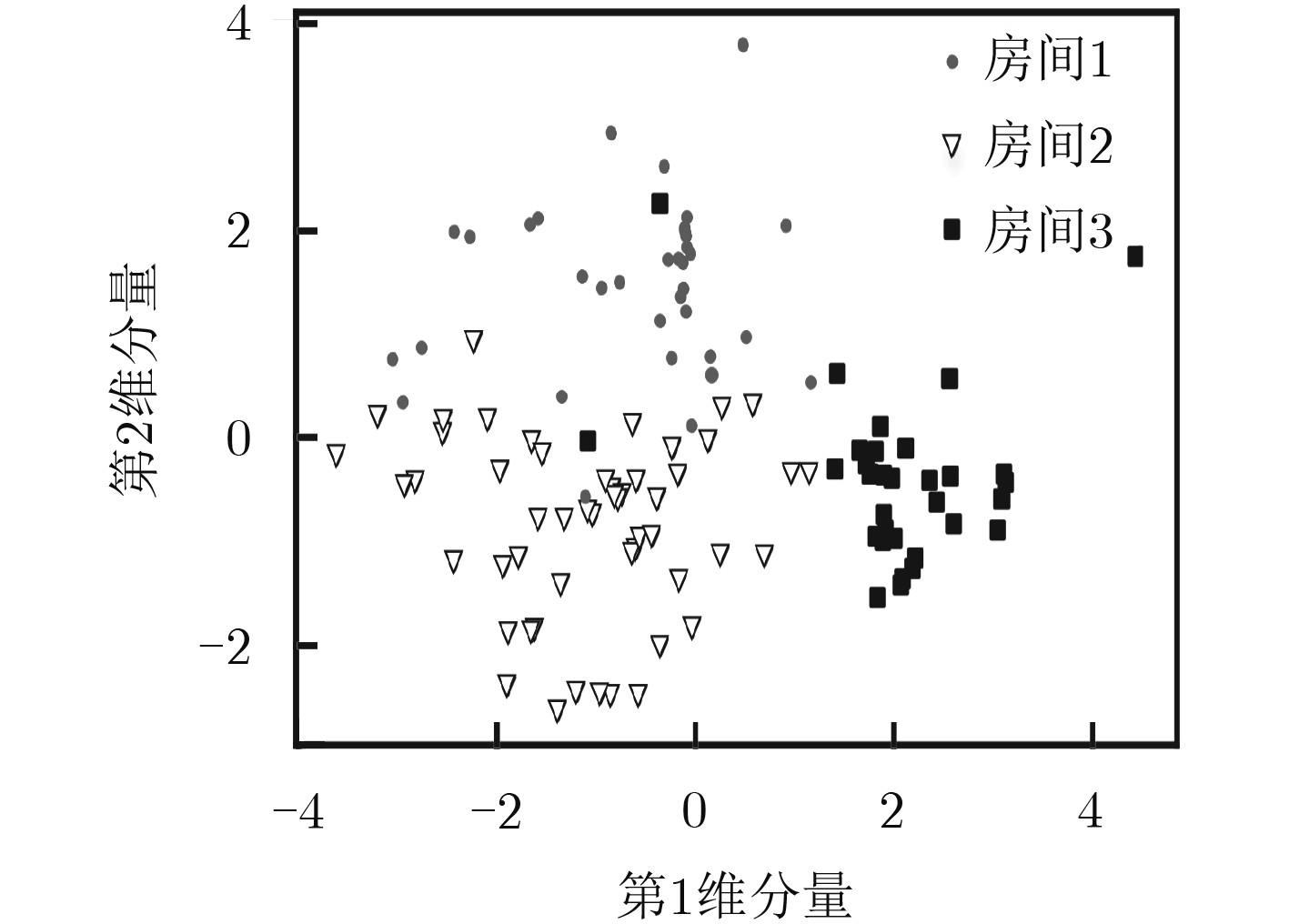
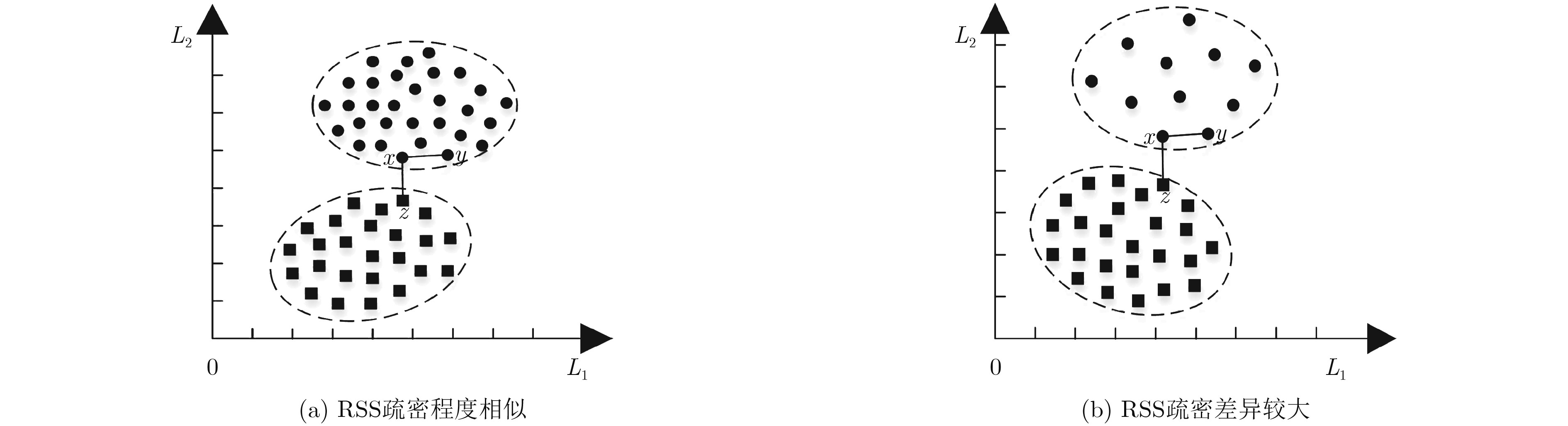
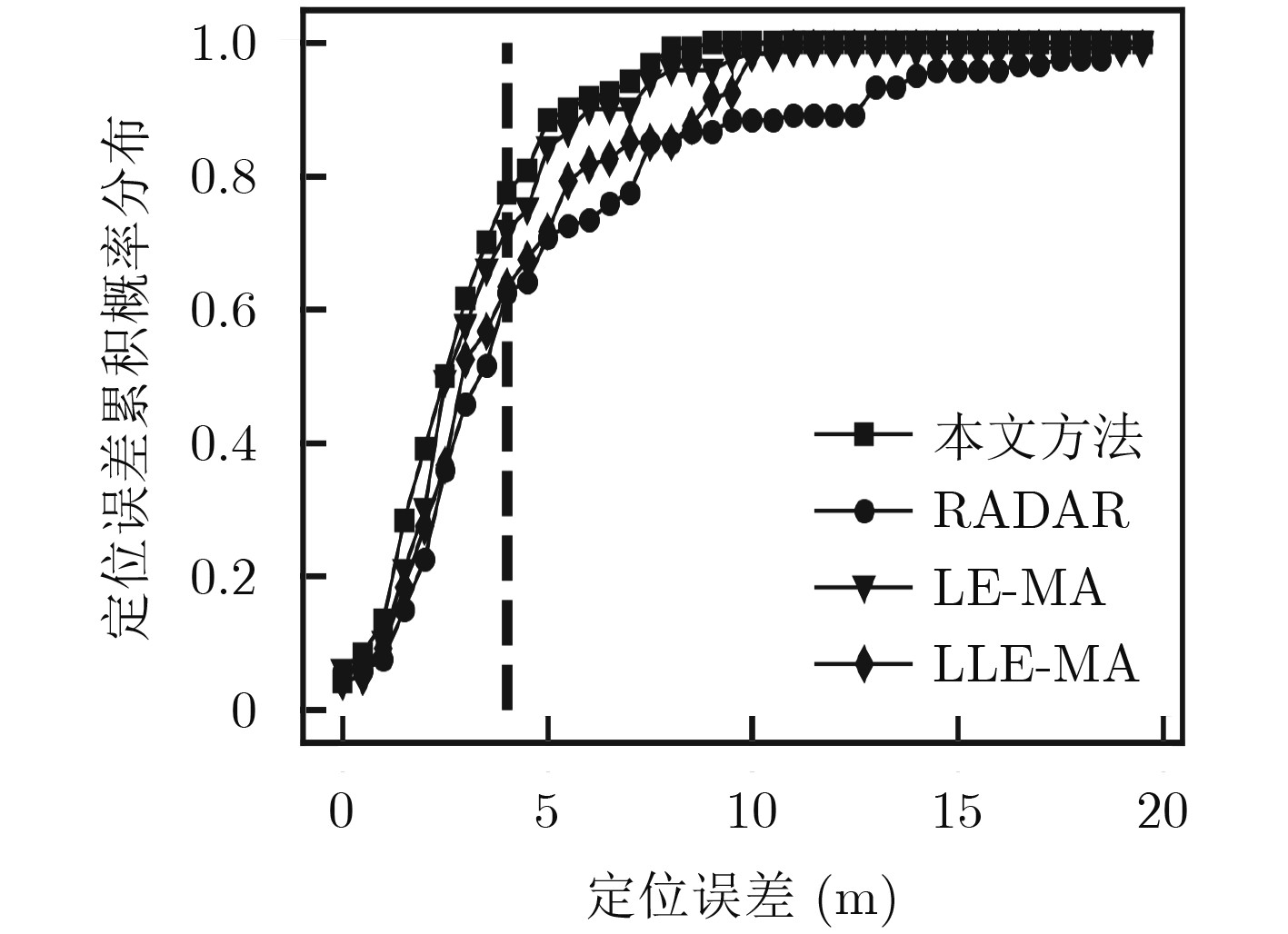
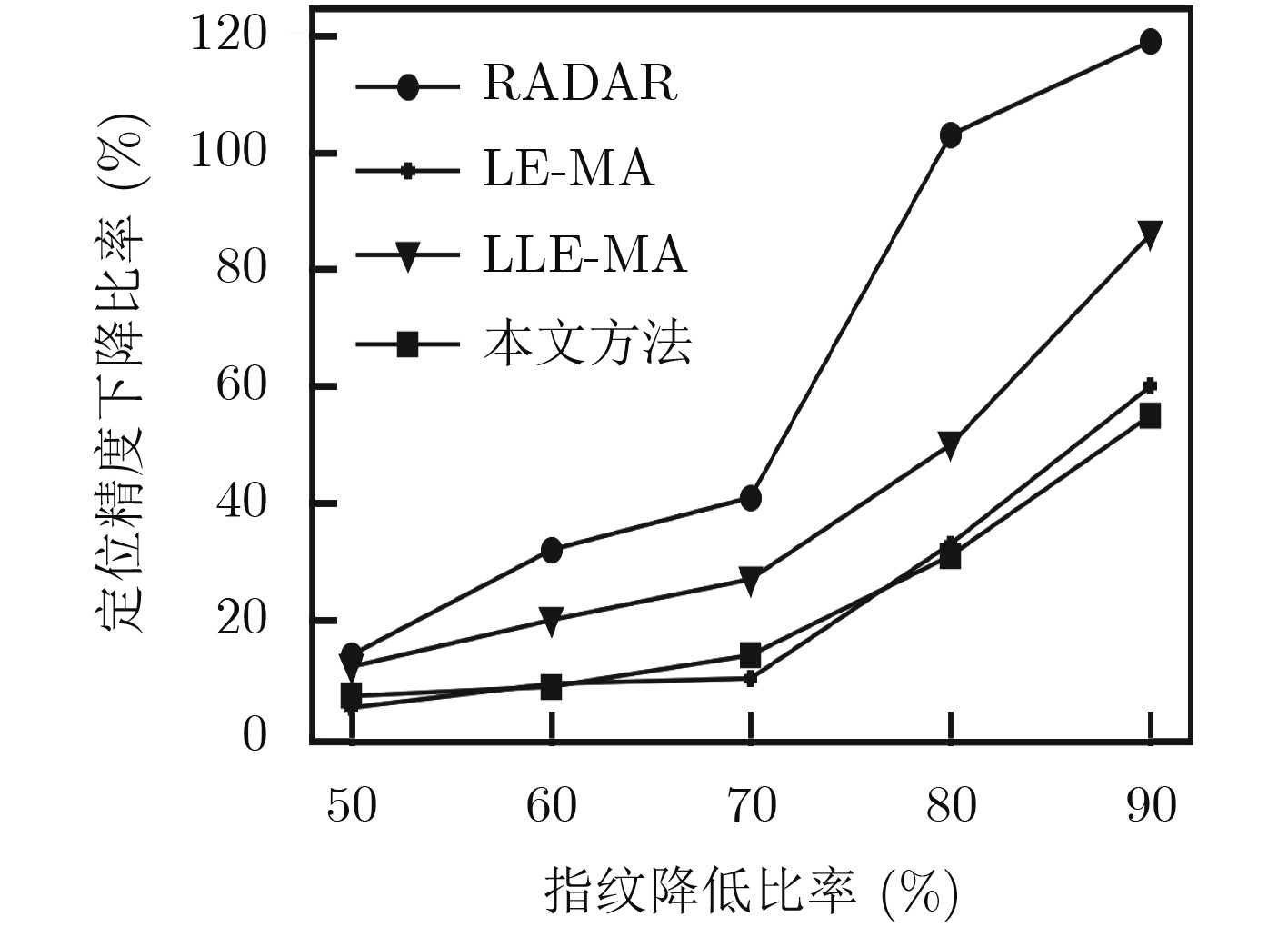
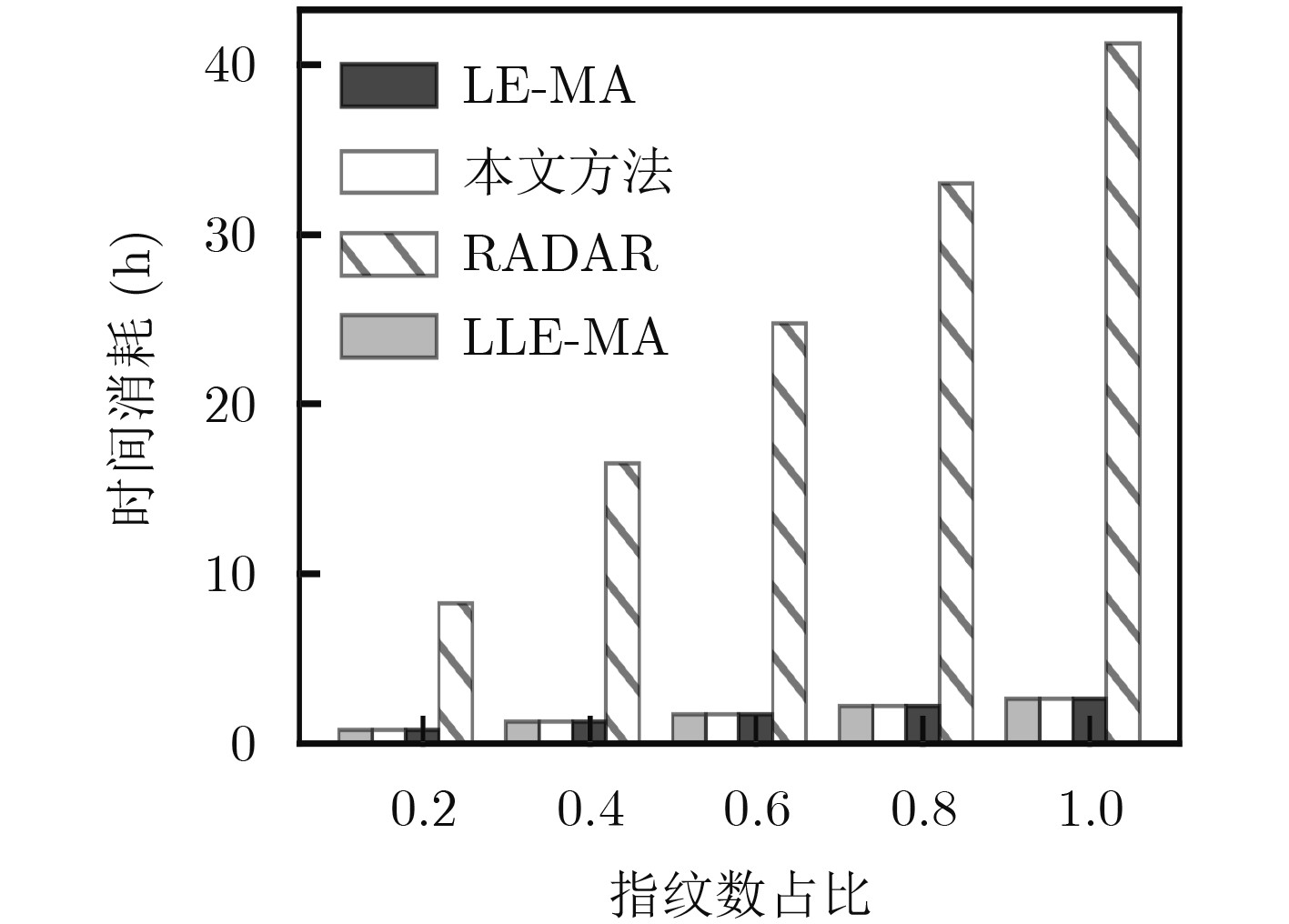
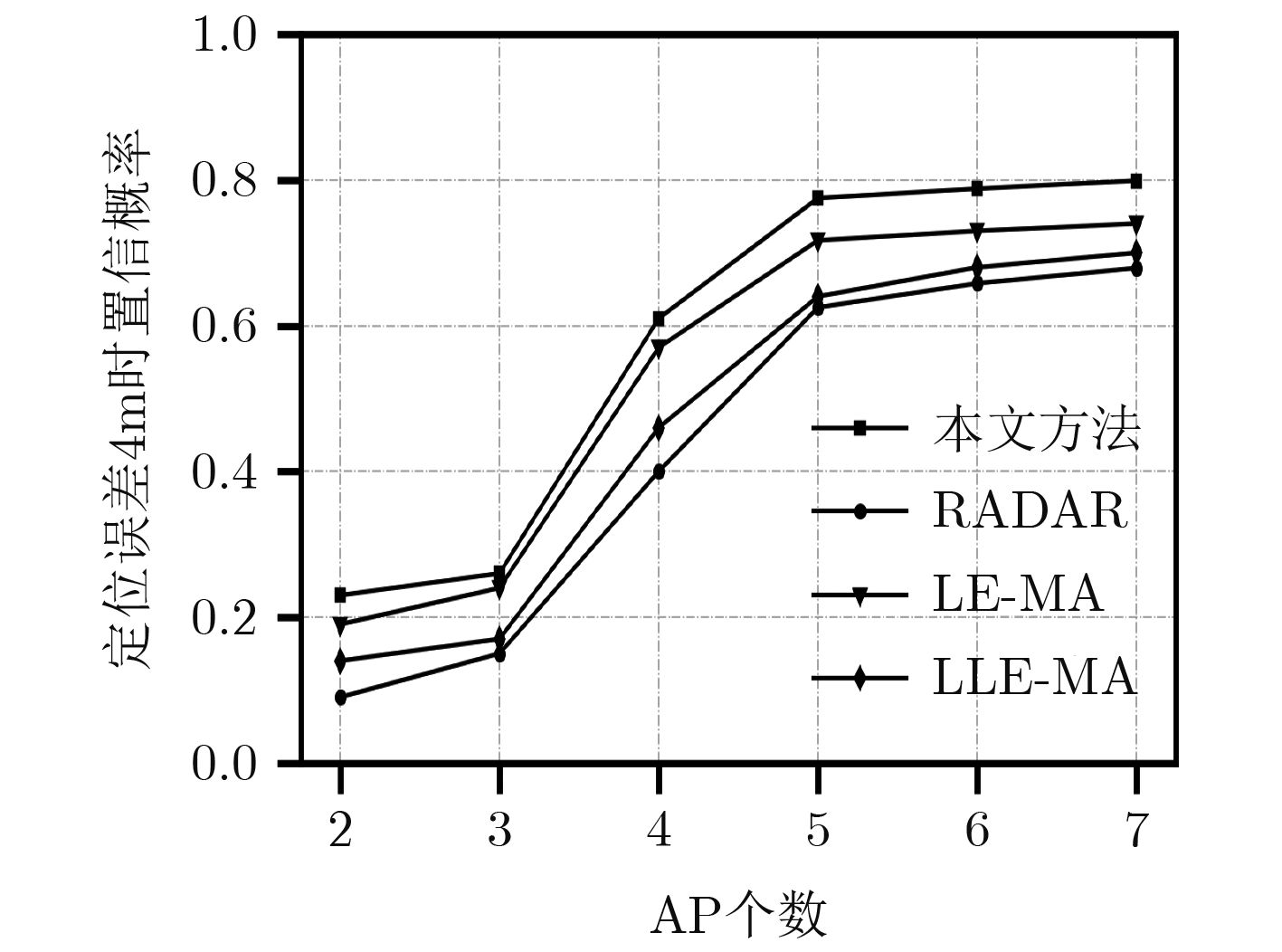
摘要: 室内定位中半监督学习的指纹库构建方法能够降低人力开销,但忽略了高维接收信号强度(RSS)数据不均匀的非齐分布特点,影响定位精度,针对此问题该文提出一种基于RSS非齐性分布特征的半监督流形对齐指纹库构建方法。该算法运用局部RSS尺度参数以及共享近邻相似性构造权重矩阵,得到精确反映RSS数据流形结构的权重图,利用该权重图通过求解流形对齐的目标函数最优解,实现运用少量标记数据对大量未标记数据的位置标定。实验结果表明,该算法可以显著降低离线阶段数据采集的工作量,同时可以取得较高的定位精度。Abstract: The radio map construction is time consuming and labor intensive, and the conventional semi-supervised based methods usually ignore the influence of the uneven distribution of high-dimensional Received Signal Strength (RSS). In order to solve that problem, a semi-supervised radio map construction approach which is based on the nonhomogeneous distribution characteristic of RSS is proposed. The approach utilizes the RSS local scale and common neighbors similarities to calculate the weighted matrix. Thus, the weighted graph that reflects accurately the structure of RSS data manifold is presented. In addition, the weighted graph is used to find the optimal solution of the objective function to calibrate the locations of plenty of unlabeled data by a small number of labeled RSS. The extensive experiments demonstrate that the proposed method is capable of not only constructing an accurate radio map at a low manual cost, but also achieving a high localization accuracy.
-
MELAMED R. Indoor localization: Challenges and opportunities[C]. 2016 IEEE/ACM International Conference on Mobile Software Engineering and Systems, Austin, USA, 2016: 1–2. 徐玉滨, 邓志安, 马琳. 基于核直接判别分析和支持向量回归的WLAN室内定位算法[J]. 电子与信息学报, 2011, 33(4): 896–901. doi: 10.3724/SP.J.1146.2010.00813XU Yubin, DENG Zhian, and MA Lin. WLAN indoor positioning algorithm based on KDDA and SVR[J]. Journal of Electronics &Information Technology, 2011, 33(4): 896–901. doi: 10.3724/SP.J.1146.2010.00813 KHALAJMEHRABADI A, GATSIS N, and AKOPIAN D. Modern WLAN fingerprinting indoor positioning methods and deployment challenges[J]. IEEE Communications Surveys & Tutorials, 2017, 19(3): 1974–2002. doi: 10.1109/COMST.2017.2671454 JI Yiming, BIAZ S, PANDEY S, et al. ARIADNE: A dynamic indoor signal map construction and localization system[C]. The 4th International Conference on Mobile Systems, Applications and Services, Uppsala, Sweden, 2006: 151–164. OUYANG R W, WONG K K S, LEA C T, et al. Indoor location estimation with reduced calibration exploiting unlabeled data via hybrid generative/discriminative learning[J]. IEEE Transactions on Mobile Computing, 2012, 11(11): 1613–1626. doi: 10.1109/TMC.2011.193 SOROUR S, LOSTANLEN Y, VALAEE S, et al. Joint indoor localization and radio map construction with limited deployment load[J]. IEEE Transactions on Mobile Computing, 2015, 14(5): 1031–1043. doi: 10.1109/TMC.2014.2343636 ZHOU Mu, TANG Yunxia, TIAN Zengshan, et al. Semi-supervised learning for indoor hybrid fingerprint database calibration with low effort[J]. IEEE Access, 2017, 5: 4388–4400. doi: 10.1109/ACCESS.2017.2678603 WANG Jin, TAN N, LUO Jun, et al. WOLoc: WiFi-only outdoor localization using crowdsensed hotspot labels[C]. IEEE Conference on Computer Communications, Atlanta, GA, USA, 2017: 1–9. CHAPELLE O and ZIEN A. Semi-supervised classification by low density separation[C]. The Tenth International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 2005: 57–64. STEVENS J R, RESMINI R G, and MESSINGER D W. Spectral-density-based graph construction techniques for hyperspectral image analysis[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(10): 5966–5983. doi: 10.1109/TGRS.2017.2718547 ZHU Manli and MARTINEZ A M. Pruning noisy bases in discriminant analysis[J]. IEEE Transactions on Neural Networks, 2008, 19(1): 148–157. doi: 10.1109/TNN.2007.904040 RODRIGUEZ A and LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492–1496. doi: 10.1126/science.1242072 LOHAN E S, TORRES-SOSPEDRA J, LEPPÄKOSKI H, et al. Wi-Fi crowdsourced fingerprinting dataset for indoor positioning[J]. Data, 2017, 2(4): 32. doi: 10.3390/data2040032 TORRES-SOSPEDRA J, MONTOLIU R, MARTíNEZ-USó A, et al. UJIIndoorLoc: A new multi-building and multi-floor database for WLAN fingerprint-based indoor localization problems[C]. 2014 International Conference on Indoor Positioning and Indoor Navigation, Busan, South Korea, 2014: 261–270. ZELNIK-MANOR L and PERONA P. Self-tuning spectral clustering[C]. Advances in Neural Information Processing Systems, Vancouver, British Columbia, Canada, 2005: 1601–1608. TORRES-SOSPEDRA J, MONTOLIU R, TRILLES S, et al. Comprehensive analysis of distance and similarity measures for Wi-Fi fingerprinting indoor positioning systems[J]. Expert Systems with Applications, 2015, 42(23): 9263–9278. doi: 10.1016/j.eswa.2015.08.013 BELKIN M and NIYOGI P. Laplacian eigenmaps for dimensionality reduction and data representation[J]. Neural Computation, 2003, 15(6): 1373–1396. doi: 10.1162/089976603321780317 HAM J, LEE D D and SAUL L K. Semisupervised alignment of manifolds[C]. The Tenth International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 2005: 120–127. BAHL P and PADMANABHAN V N. RADAR: An in-building RF-based user location and tracking system[C]. The Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Tel Aviv, Israel, 2000, 2: 775–784. -


 下载:
下载:

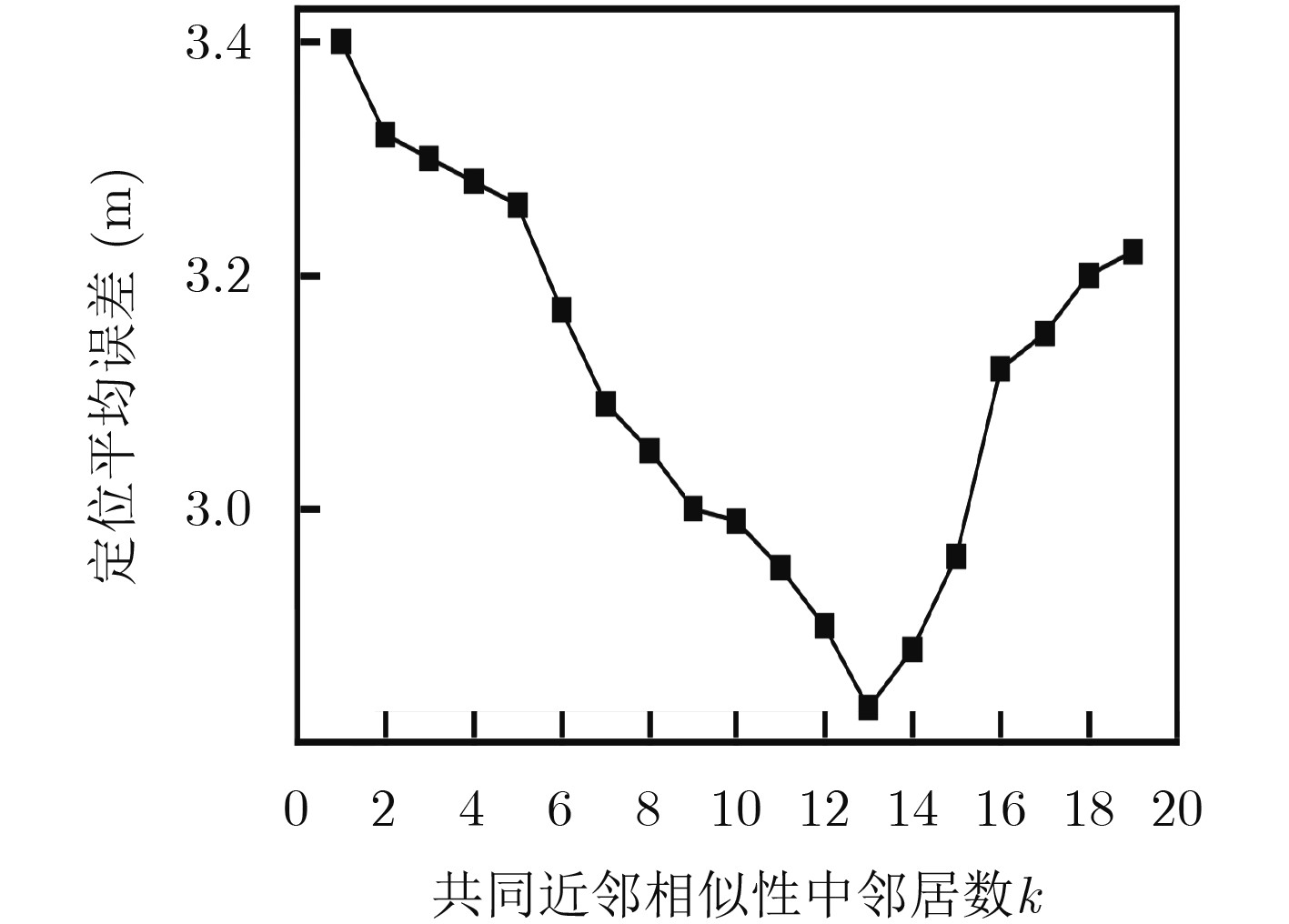


图(11)
计量
- 文章访问数: 3812
- HTML全文浏览量: 1135
- PDF下载量: 95
- 被引次数: 0
