

A Perspective-independent Method for Behavior Recognition in Depth Video via Temporal-spatial Correlating
-
摘要:
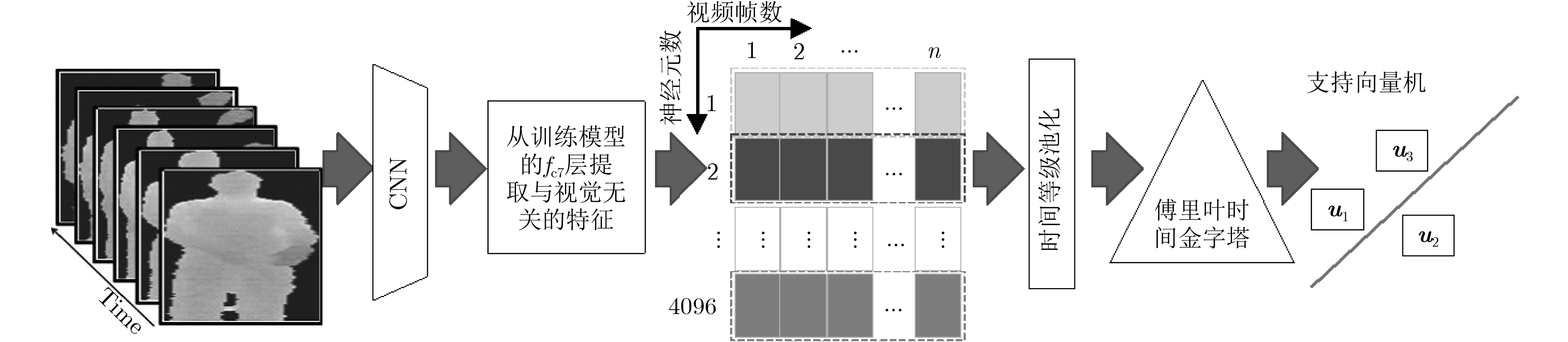
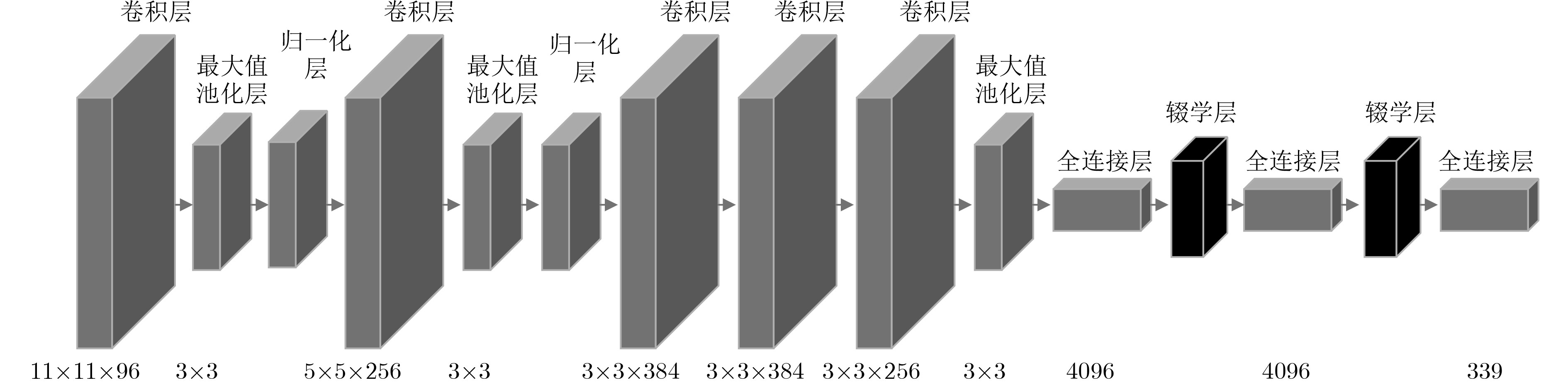
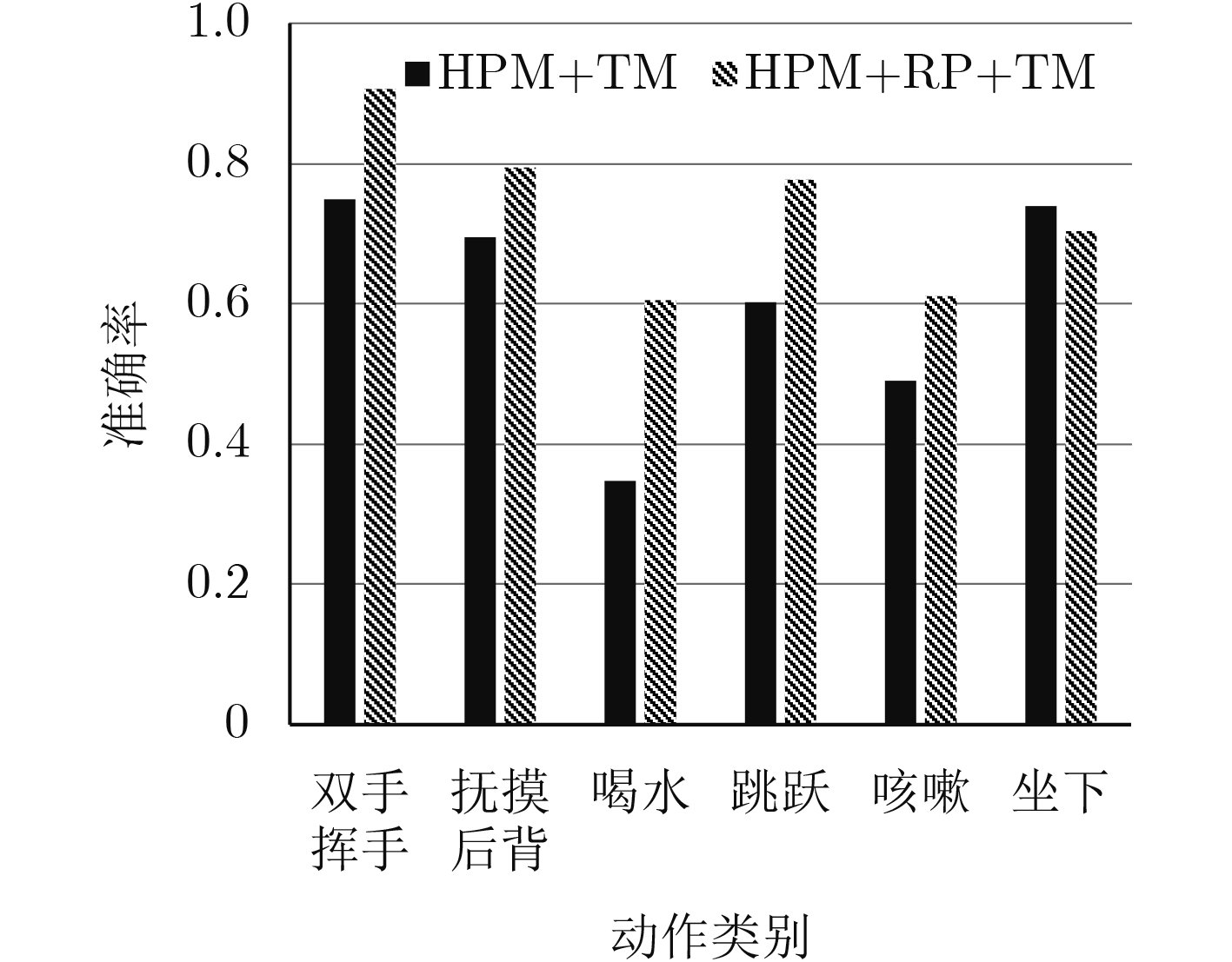
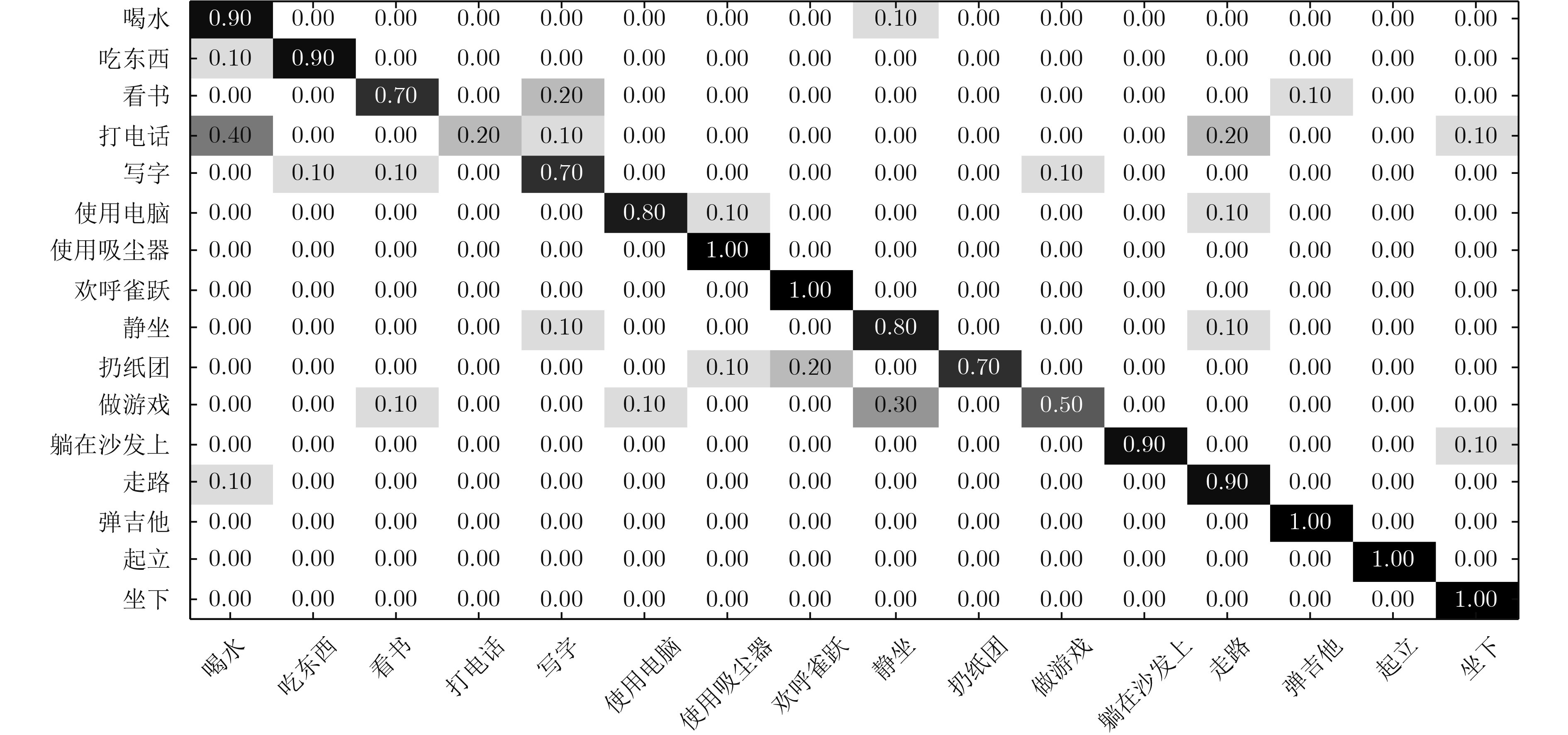
当前行为识别方法在不同视角下的识别准确率较低,该文提出一种视角无关的时空关联深度视频行为识别方法。首先,运用深度卷积神经网络的全连接层将不同视角下的人体姿态映射到与视角无关的高维空间,以构建空间域下深度行为视频的人体姿态模型(HPM);其次,考虑视频序列帧之间的时空相关性,在每个神经元激活的时间序列中分段应用时间等级池化(RP)函数,实现对视频时间子序列的编码;然后,将傅里叶时间金字塔(FTP)算法作用于每一个池化后的时间序列,并加以连接产生最终的时空特征表示;最后,在不同数据集上,基于不同方法进行了行为识别分类测试。实验结果表明,该文方法(HPM+RP+FTP)提高了不同视角下深度视频识别准确率,在UWA3DII数据集中,比现有最好方法高出18%。此外,该文方法具有较好的泛化性能,在MSR Daily Activity3D数据集上得到82.5%的准确率。
Abstract:Considering the low recognition accuracy of behavior recognition from different perspectives at present, this paper presents a perspective-independent method for depth videos. Firstly, the fully connected layer of depth Convolution Neural Network (CNN) is creatively used to map human posture in different perspectives to high-dimensional space that is independent with perspective to achieve the Human Posture Modeling (HPM) of deep-performance video in spatial domain. Secondly, considering temporal-spatial correlation between video sequence frames, the Rank Pooling (RP) function is applied to the series of each neuron activated time to encode the video time sub-sequence, and then the Fourier Time Pyramid (FTP) is used to each pooled time series to produce the final spatio-temporal feature representation. Finally, different methods of behavior recognition classification are tested on several datasets. Experimental results show that the proposed method improves the accuracy of depth video recognition in different perspectives. In the UWA3DII datasets, the proposed method is 18% higher than the most recent method. The proposed method (HPM+RP+FTP) has a good generalization performance, achieving a 82.5% accuracy on dataset of MSR Daily Activity3D.
-
表 1 UWA3D Multiview ActivityII数据集的动作识别准确性(%)
训练视角 V1&V2 V1&V3 V1&V4 V2&V3 V2&V4 V3&V4 平均准确率 测试视角 V3 V4 V2 V4 V2 V3 V1 V4 V1 V3 V1 V2 文献[6] 45.0 40.4 35.1 36.9 34.7 36.0 49.5 29.3 57.1 35.4 49.0 29.3 39.8 文献[7] 49.4 42.8 34.6 39.7 38.1 44.8 53.3 33.5 53.6 41.2 56.7 32.6 43.4 文献[18] 52.7 51.8 59.0 57.5 42.8 44.2 58.1 38.4 63.2 43.8 66.3 48.0 52.2 文献[17] 60.1 61.3 57.1 65.1 61.6 66.8 70.6 59.5 73.2 59.3 72.5 54.5 63.5 HPM(fc7)+RP 80.2 74.9 69.9 76.4 49.2 63.8 71.4 59.9 80.7 76.9 84.4 68.4 71.3 HPM(fc7)+FTP 80.6 80.5 75.2 82.0 65.4 72.0 77.3 67.0 83.6 81.0 83.6 74.1 76.9 HPM(fc6)+RP+FTP 83.9 81.3 74.8 82.0 66.2 72.8 78.8 70.0 83.3 79.1 85.9 75.9 77.8 HPM(fc7)+RP+FTP 85.8 81.6 76.3 80.5 61.7 76.5 78.1 71.5 82.9 81.7 85.9 76.3 78.3 注:V1, V2, V3, V4分别表示正面视角、左侧视角、右侧视角、顶部视角  下载: 导出CSV
下载: 导出CSV
-
ZHOU Yang, NI Bingbing, HONG Richang, et al. Interaction part mining: A mid-level approach for fine-grained action recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3323–3331. doi: 10.1109/CVPR.2015.7298953. WANG Jiang, NIE Xiaohan, XIA Yin, et al. Cross-view action modeling, learning, and recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2649–2656. doi: 10.1109/CVPR.2014.339. LIU Peng and YIN Lijun. Spontaneous thermal facial expression analysis based on trajectory-pooled fisher vector descriptor[C]. IEEE International Conference on Multimedia and Expo, Hong Kong, China, 2017: 835–840. doi: 10.1109/ICME.2017.8019315. YANG Xiaodong and TIAN Yingli. Super normal vector for activity recognition using depth sequences[C]. IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 804–811. doi: 10.1109/CVPR.2014.108. ZHANG Baochang, YANG Yun, CHEN Chen, et al. Action recognition using 3D histograms of texture and a multi-class boosting classifier[J]. IEEE Transactions on Image Processing, 2017, 26(10): 4648–4660 doi: 10.1109/TIP.2017.2718189 YIN Xiaochuan and CHEN Qijun. Deep metric learning autoencoder for nonlinear temporal alignment of human motion[C]. IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 2016: 2160–2166. doi: 10.1109/ICRA.2016.7487366. SHAHROUDY A, LIU Jun, NG T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115. KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]. IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1725–1732. doi: 10.1109/CVPR.2014.223. HAIDER F, CAMPBELL N, and LUZ S. Active speaker detection in human machine multiparty dialogue using visual prosody information[C]. IEEE Global Conference on Signal and Information Processing, Washington, D.C., USA, 2016: 1207–1211. doi: 10.1109/GlobalSIP.2016.7906033. SIMONYAN K and ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[J]. Advances in Neural Information Processing Systems, 2014, 1(4): 568–576 doi: 10.1002/14651858.CD001941.pub3 TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]. IEEE International Conference on Computer Vision, Honolulu, USA, 2015: 4489–4497. doi: 10.1109/ICCV.2015.510. DONAHUE J, HENDRICKS L A, ROHRBACH M, et al. Long-term recurrent convolutional networks for visual recognition and description[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 677–691 doi: 10.1109/TPAMI.2016.2599174 GUPTA S, GIRSHICK R, ARBELEZ P, et al. Learning rich features from RGB-D images for object detection and segmentation[C]. European Conference on Computer Vision, Zurich, Switzerland, 2014: 345–360. doi: 10.1007/978-3-319-10584-0_23. FERNANDO B, GAVVES E, ORAMAS J, et al. Rank pooling for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 773–787 doi: 10.1109/TPAMI.2016.2558148 WANG Jiang, LIU Zicheng, WU Ying, et al. Learning actionlet ensemble for 3D human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5): 914–927 doi: 10.1109/TPAMI.2013.198 RAHMANI H and MIAN A. 3D action recognition from novel viewpoints[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1506–1515. doi: 10.1109/CVPR.2016.167. RAHMANI H and MIAN A. Learning a non-linear knowledge transfer model for cross-view action recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 2458–2466. doi: 10.1109/CVPR.2015.7298860. RAHMANI H, MAHMOOD A, HUYNH D Q, et al. HOPC: Histogram of oriented principal components of 3D pointclouds for action recognition[C]. European Conference on Computer Vision, Zurich, Switzerland, 2014: 742–757. doi: 10.1007/978-3-319-10605-2_48. JALAL A, KAMAL S, and KIM D. A depth video sensor-based life-logging human activity recognition system for elderly care in smart indoor environments[J]. Sensors, 2014, 14(7): 11735–11759 doi: 10.3390/s140711735 MULLER M and RODER T. Motion templates for automatic classification and retrieval of motion capture data[C]. ACM Siggraph/eurographics Symposium on Computer Animation, Vienna, Austria, 2006: 137–146. doi: 10.1145/1218064.1218083. WANG Jiang, LIU Zicheng, WU Ying, et al. Mining actionlet ensemble for action recognition with depth cameras[C]. IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 1290–1297. doi: 10.1007/978-3-319-04561-0_2. CAVAZZA J, ZUNINO A, BIAGIO M S, et al. Kernelized covariance for action recognition[C]. International Conference on Pattern Recognition, Cancun, Mexico, 2016: 408–413. doi: 10.1109/ICPR.2016.7899668. -



计量
- 文章访问数: 2122
- HTML全文浏览量: 776
- PDF下载量: 68
- 被引次数: 0
 下载:
下载:
