

Micro-motion Parameters Estimation of Ballistic Targets Based on Wide-band Radar Three Dimensional Interferometry
-
摘要:
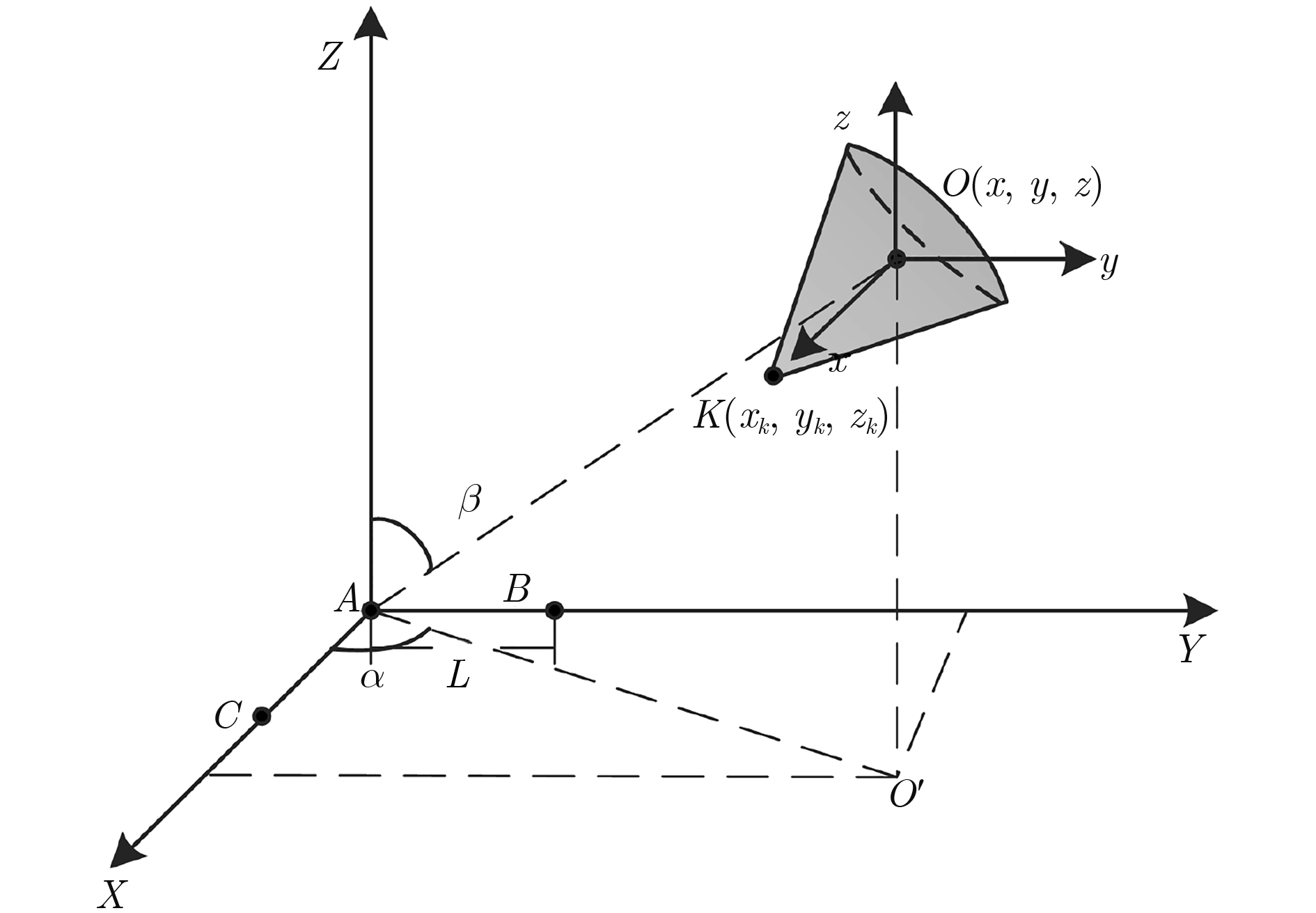
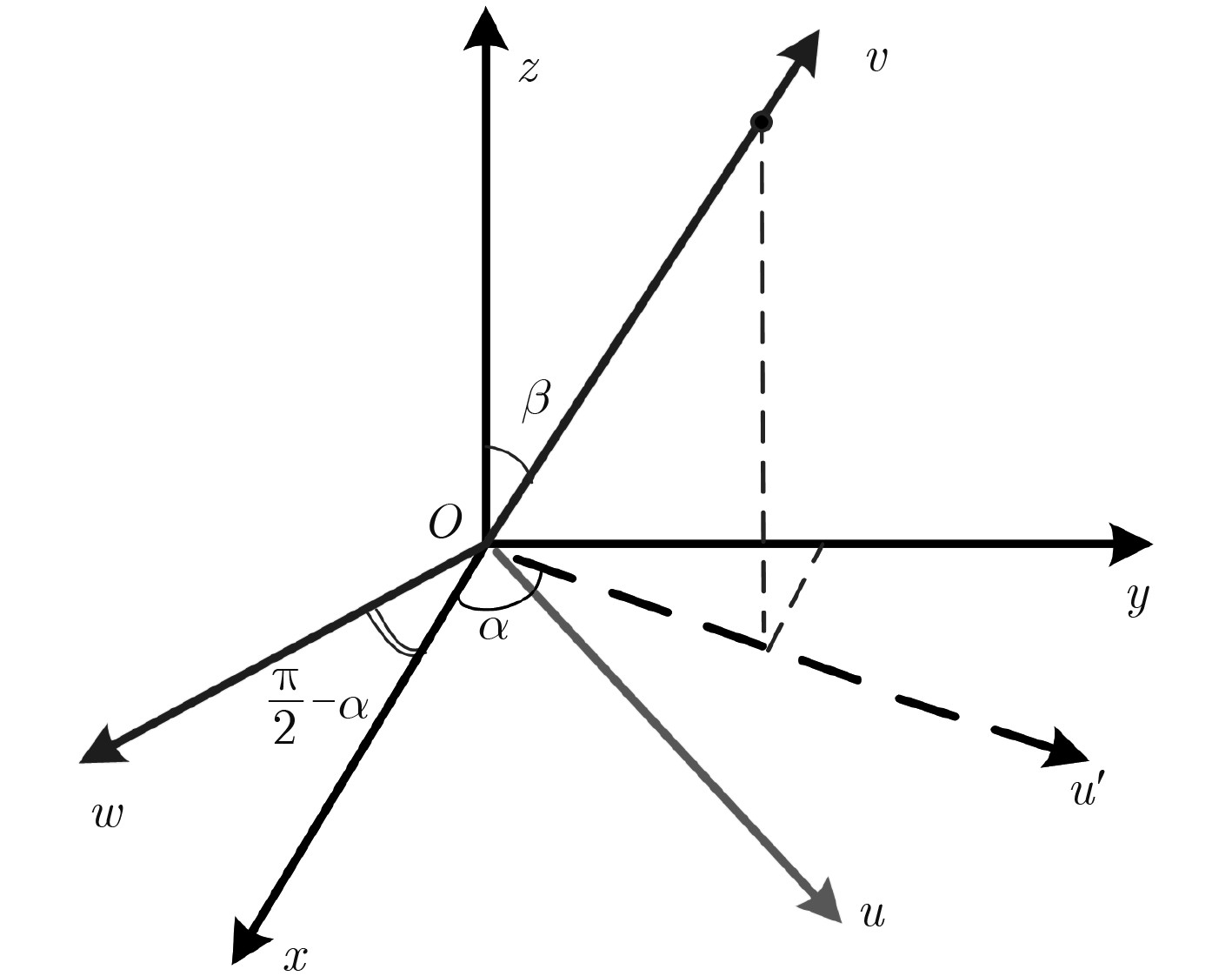
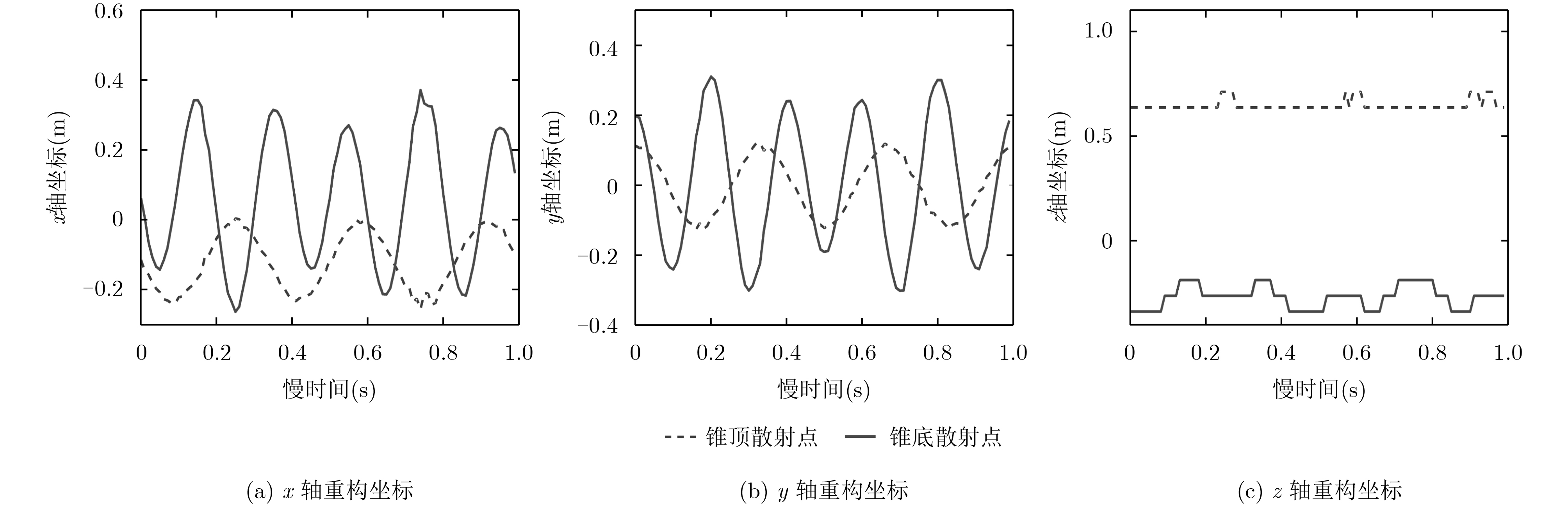
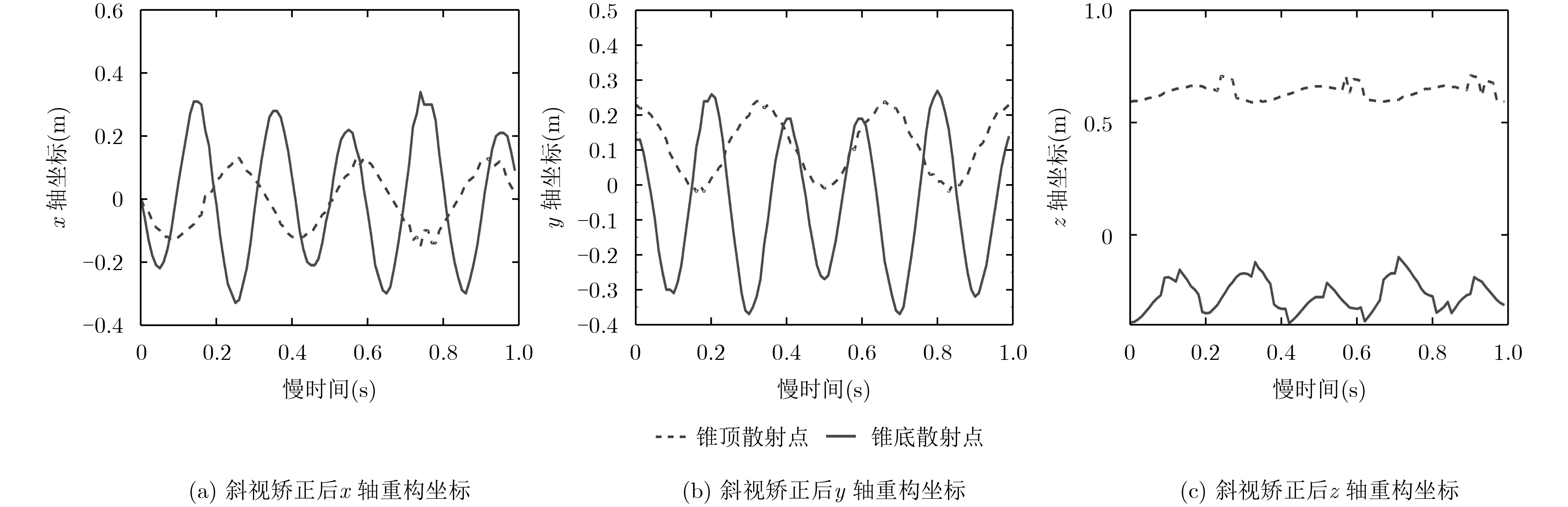
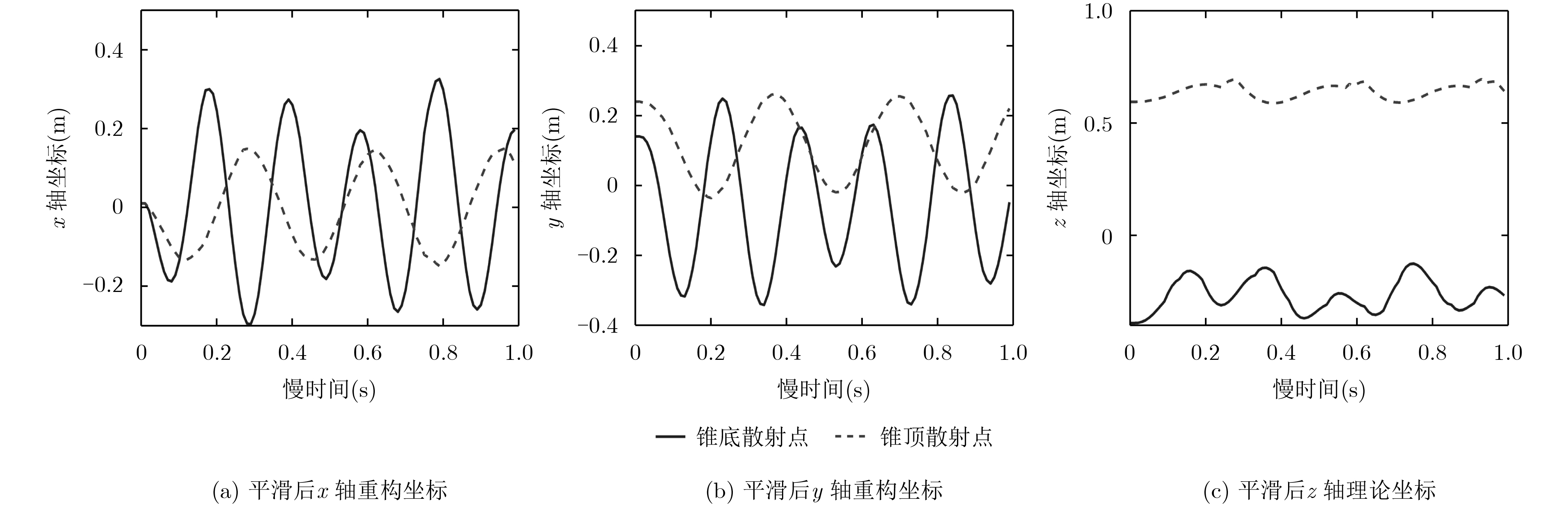
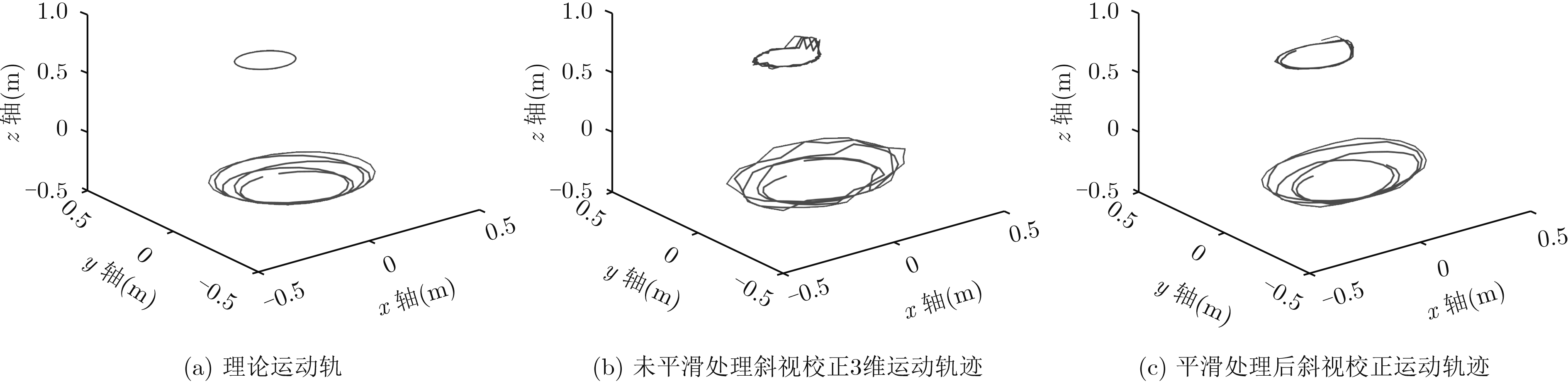
宽带雷达微动目标3维干涉测量可为目标运动几何参数估计提供重要信息。该文针对宽带雷达斜视3维干涉测量微动目标参数估计,提出一种斜视校正干涉测量微动几何参数估计方法。方法对L型天线阵列中各天线接收回波进行干涉测距测角,通过建立2元2次非线性方程和坐标变换实现斜视扭曲校正,得到目标散射中心3维运动轨迹,继而采用滤波和优化求解实现目标微动几何参数估计,有效提高了微动目标运动几何参数估计准确性和平滑稳健性。
Abstract:Three dimensional interferometry of wide-band radar can provide crucial information for estimating the micro-motion and geometric parameters of targets. For estimation of the micro-motion parameters via three dimensional interferometry in the case of squint observing mode, an algorithm for micro-motion and geometric parameters based on squint calibration is proposed. The algorithm performs ranging and angle measuring for each antenna receiving echo in an L formation array. Moreover, the squint distortion is calibrated and three dimensional trajectories of scattering centers are obtained via establishing two elements and quadratic nonlinear equations and coordinate transformation. In addition, smoothing filtering and optimization are used to retrieve micro-motion and geometry parameters. The effectiveness and robustness of the proposed algorithm is confirmed via extensive experiments.
-
表 1 实验锥体目标参数
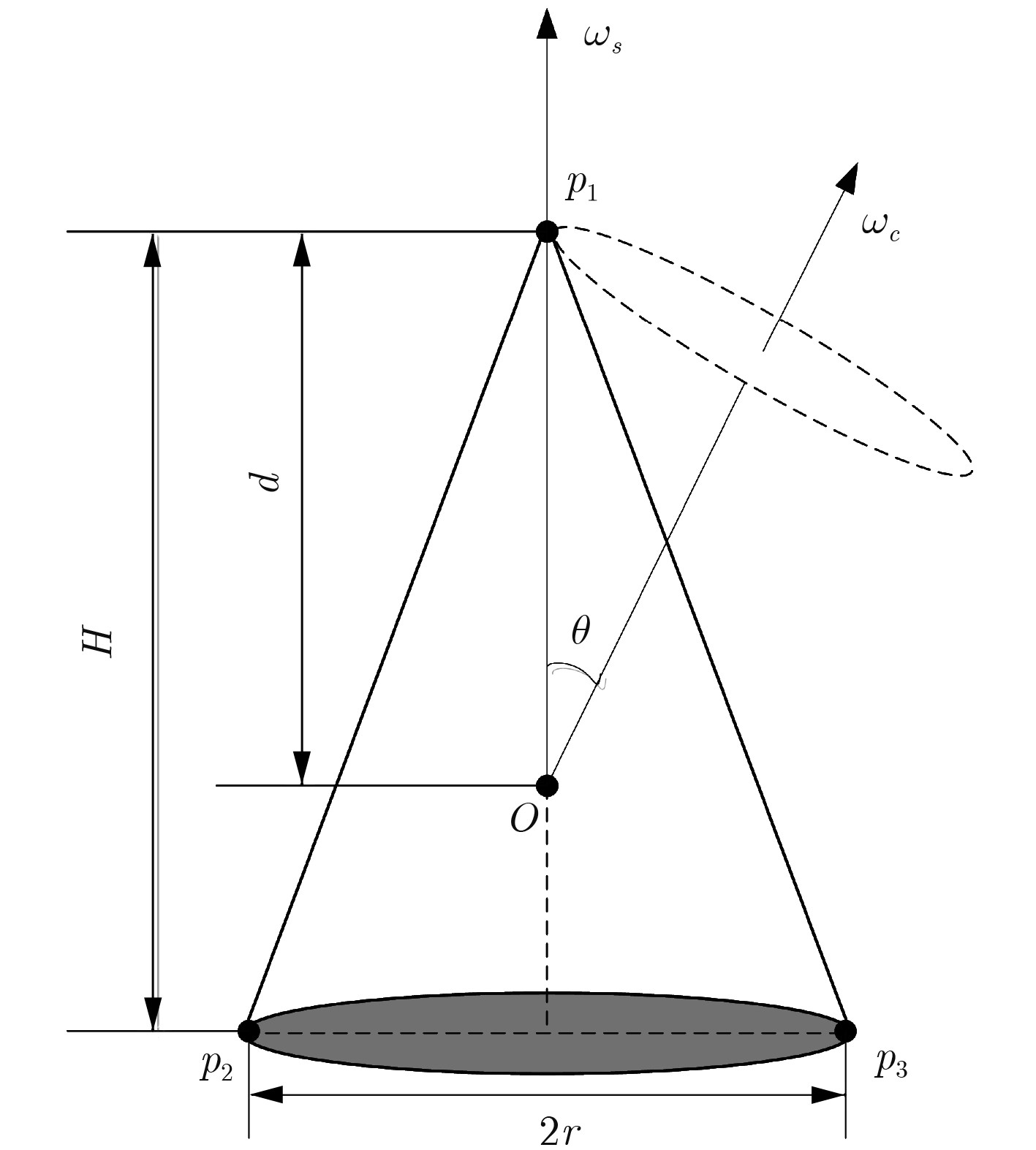
参数 数值 锥体高度H (m) 0.96 质心到锥顶距离d (m) 0.64 底面半径r (m) 0.25 自旋频率fs (Hz) 2 锥旋频率fz (Hz) 3 进动角θ (°) 10  下载: 导出CSV
下载: 导出CSV
表 2 雷达系统的主要参数
参数 数值 载频f0 (GHz) 10 带宽B (GHz) 1 脉冲宽度tp (μs) 10 脉冲重复周期prf (Hz) 100 驻留时间T (s) 1 基线长L (m) 200
下载: 导出CSV
表 3 曲线估计实验结果相似度(%)
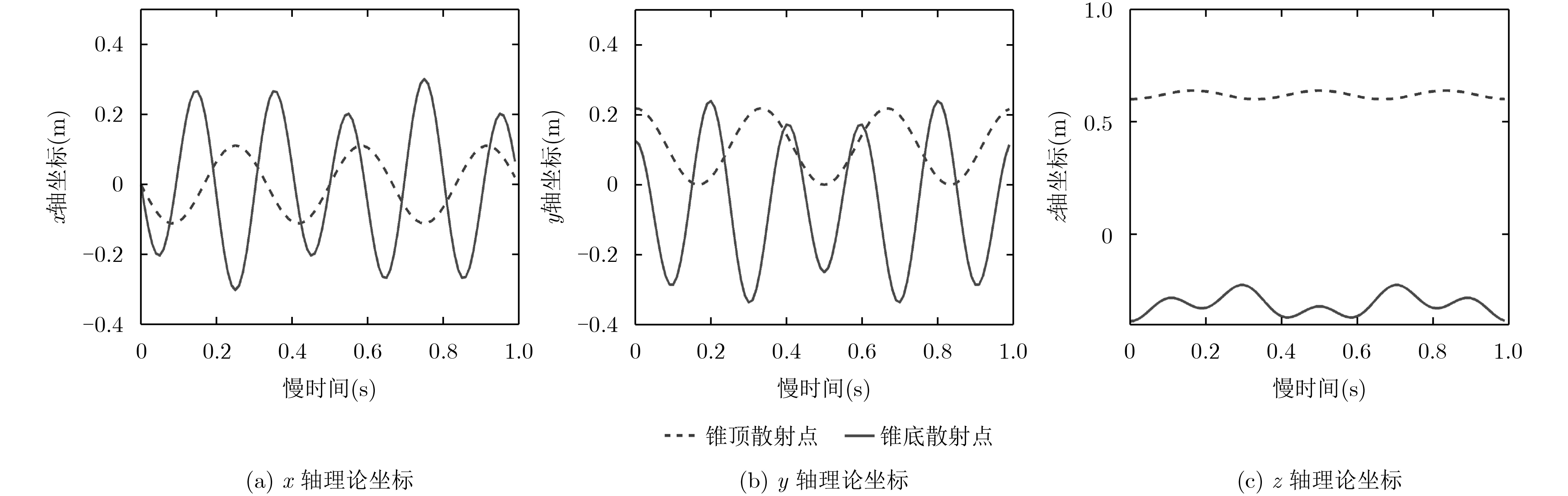
锥顶散射点x 锥顶散射点y 锥顶散射点z 锥底散射点x 锥底散射点y 锥底散射点z 文献[12]干涉测量 68.26 60.42 88.72 62.93 64.91 82.73 斜视校正干涉测量 88.56 90.41 96.59 90.84 91.24 87.28
下载: 导出CSV
表 4 目标参数估计结果
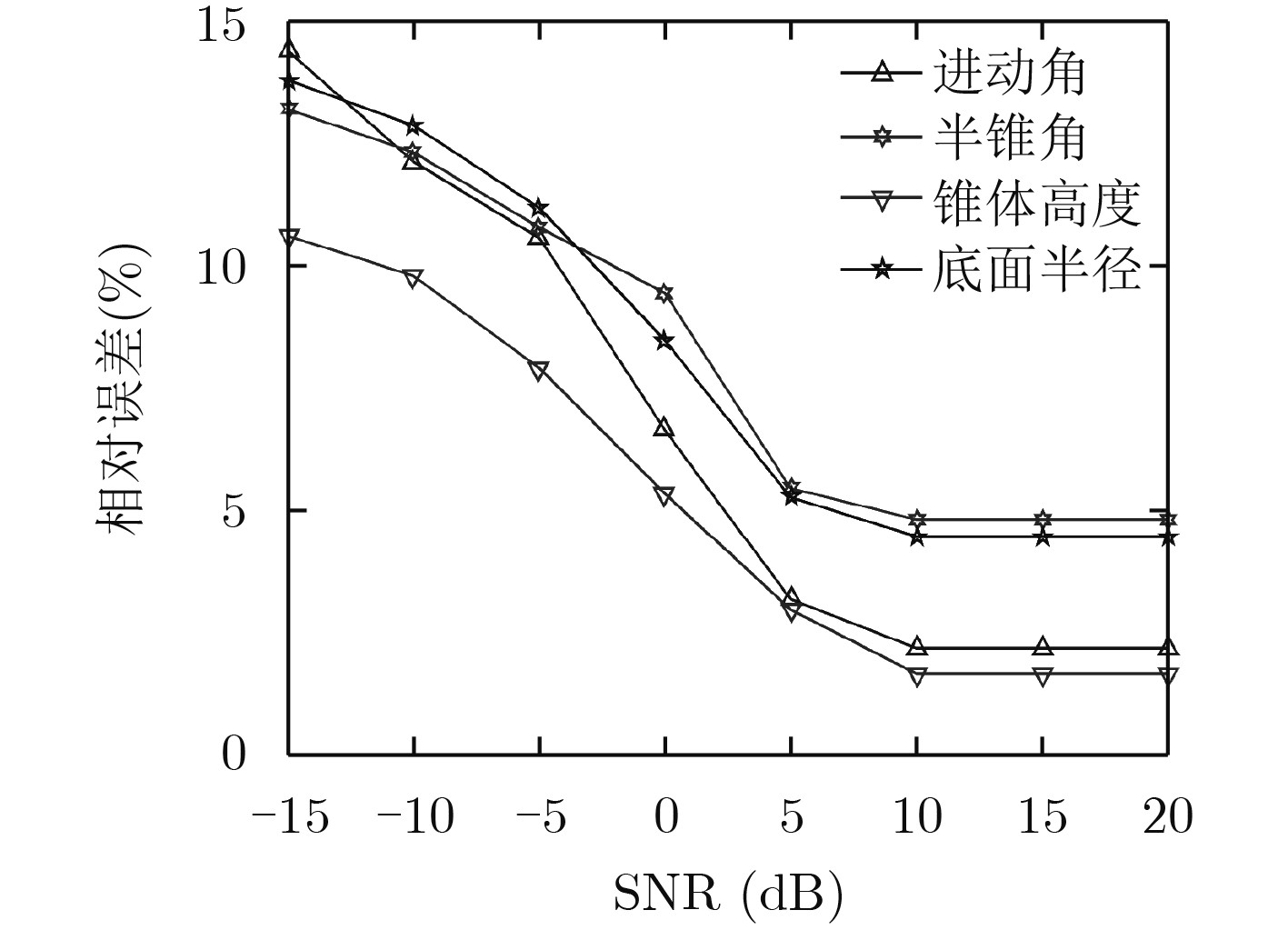
进动频率${f_c}\left( {\rm Hz} \right)$ 进动角$\theta \left( {^ \circ } \right)$ 半锥角$\eta \left( {^ \circ } \right)$ 锥体高度$H\left( {\rm m} \right)$ 底面半径$r\left( {\rm m} \right)$ 真实值 3 10.00 14.59 0.96 0.25 平滑处理估计值 3 9.60 15.25 0.95 0.26 未平滑处理估计值 3 12.49 18.17 0.87 0.31
下载: 导出CSV
-
CHEN V C, LI Fayin, HO Shen Shyang, et al. Micro-Doppler effect in radar: Phenomenon, model, and simulation study[J]. IEEE Transactions on Aerospace and Electronic Systems, 2006, 42(1): 2–21 doi: 10.1109/TAES.2006.1603402 束长勇, 张俊生, 黄沛霖, 等. 基于微多普勒的空间锥体目标微动分类[J]. 北京航空航天大学学报, 2017, 43(7): 1387–1394 doi: 10.13700/j.bh.1001-5965.2016.0500SHU Changyong, ZHANG Junsheng, HUANG Peilin, et al. Micro-motion classification of spatial cone target based on micro-Doppler[J]. Journal of Beijing University of Aeronautics and Astronautics, 2017, 43(7): 1387–1394 doi: 10.13700/j.bh.1001-5965.2016.0500 周叶剑, 张磊, 菅毛, 等. 多频调频稀疏分解的微动目标参数估计方法[J]. 电子与信息学报, 2017, 39(10): 2360–2365 doi: 10.11999/JEIT170163ZHOU Yejian, ZHANG Lei, JIAN Mao, et al. Micro-motion estimation for ballistic targets with multi-frequency chirp decomposition[J]. Journal of Electronics and Information Technology, 2017, 39(10): 2360–2365 doi: 10.11999/JEIT170163 LIU Yongxiang, ZHU Dekang, LI Kangle, et al. Micromotion characteristic acquisition based on wideband radar phase[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(6): 3650–3657 doi: 10.1109/TGRS.2013.2274478 FAN Huayu, REN Lixiang, LONG Teng, et al. A high-precision phase-derived range and velocity measurement method based on synthetic wideband pulse Doppler radar[J]. Science China Information Sciences, 2017, 60(8): 082301 doi: 10.1007/s11432-016-0097-4 蒋彦雯, 邓彬, 王宏强, 等. 基于双频联合处理的太赫兹InISAR成像方法[J]. 雷达学报, 2018, 7(1): 139–146 doi: 10.12000/JR17109JIANG Yanwen, DENG Bin, WANG Hongqiang, et al. An improved terahertz InISAR imaging method based on the joint processing of two frequency band data[J]. Journal of Radars, 2018, 7(1): 139–146 doi: 10.12000/JR17109 ZHAO Lizhi, GAO Meiguo, MARTORELLA M, et al. Bistatic three-dimensional interferometric ISAR image reconstruction[J]. IEEE Transactions on Aerospace and Electronic Systems, 2015, 51(2): 951–961 doi: 10.1109/TAES.2014.130702 MA Changzheng, YEO Tat Soon, ZHANG Qun, et al. Three-dimensional ISAR imaging based on antenna array[J]. IEEE Transactions on Geoscience and Remote Sensing, 2008, 46(2): 504–515 doi: 10.1109/TGRS.2007.909946 WANG Genyuan, XIA Xianggen, and CHEN V C. Three-dimensional ISAR imaging of maneuvering targets using three receivers[J]. IEEE Transactions on Image Processing, 2001, 10(3): 436–447 doi: 10.1109/83.908519 鲁耀兵, 张履谦, 周荫清, 等. 分布式阵列相参合成雷达技术研究[J]. 系统工程与电子技术, 2013, 35(8): 1657–1662 doi: 10.3969/j.issn.1001-506X.2013.08.12LU Yaobing, ZHANG Lüqian, ZHOU Yinqing, et al. Study on distributed aperture coherence-synthetic rader technology[J]. Systems Engineering and Electronics, 2013, 35(8): 1657–1662 doi: 10.3969/j.issn.1001-506X.2013.08.12 陈春晖, 张群, 罗迎, 等. 一种空间微动目标宽带雷达干涉三维成像方法[J]. 电子与信息学报, 2016, 38(12): 3144–3151 doi: 10.11999/JEIT161025CHEN Chunhui, ZHANG Qun, LUO Ying, et al. Interferometric three dimensional imaging method for space micro-motion target based on wideband radar[J]. Journal of Electronics &Information Technology, 2016, 38(12): 3144–3151 doi: 10.11999/JEIT161025 胡健, 罗迎, 张群, 等. 弹道目标宽带雷达干涉式三维成像与微动特征提取[J]. 电子与信息学报, 2017, 39(8): 1865–1871 doi: 10.11999/JEIT161134HU Jian, LUO Ying, ZHANG Qun, et al. Three-dimensional interferometric imaging and micro-motion feature extraction of ballistic targets in wideband radar[J]. Journal of Electronics &Information Technology, 2017, 39(8): 1865–1871 doi: 10.11999/JEIT161134 李丽亚, 刘宏伟, 纠博, 等. 斜视干涉逆合成孔径雷达成像算法[J]. 西安交通大学学报, 2008, 42(10): 1290–1294 doi: 10.3321/j.issn:0253-987X.2008.10.020LI Liya, LIU Hongwei, JIU Bo, et al. An interferometric inverse synthetic aperture radar imaging algorithm for squint model[J]. Journal of Xi’an Jiaotong University, 2008, 42(10): 1290–1294 doi: 10.3321/j.issn:0253-987X.2008.10.020 LIU Chenglan, HE Feng, GAO Xunzhang, et al. Squint-mode InISAR imaging based on nonlinear least square and coordinates transform[J]. Science China Technological Sciences, 2011, 54(12): 3332–3340 doi: 10.1007/s11431-011-4515-9 吕少霞. ISAR成像的横向定标算法研究[D]. [硕士论文], 哈尔滨工业大学, 2007.LÜ Shaoxia. Cross-range scaling algorithm based on ISAR imaging[D]. [Master dissertation], Harbin Institute of Technology, 2007. -




计量
- 文章访问数: 1807
- HTML全文浏览量: 1136
- PDF下载量: 62
- 被引次数: 0
 下载:
下载:
