

Action Recognition Based on Multi-model Voting with Cross Layer Fusion
-
摘要:
针对动作特征在卷积神经网络模型传输时的损失问题以及网络模型过拟合的问题,该文提出一种跨层融合模型和多个模型投票的动作识别方法。在预处理阶段,借助排序池化的方法聚集视频中的运动信息,生成近似动态图像。在全连接层前设置对特征信息进行水平翻转结构,构成无融合模型。在无融合模型的基础上添加第2层的输出特征与第5层的输出特征融合结构,构造成跨层融合模型。训练时,对无融合模型和跨层融合模型两种基本模型采用3种数据划分方式以及两种生成近似动态图像顺序进行训练,得到多个不同的分类器。测试时使用多个分类器进行预测,对它们得到的结果进行投票集成,作为最终分类结果。在UCF101数据集上,提出的无融合模型和跨层融合模型的识别方法与动态图像网络模型的方法相比,识别率有较大提高;多模型投票的识别方法能有效缓解模型的过拟合现象,增加算法的鲁棒性,得到更好的平均性能。
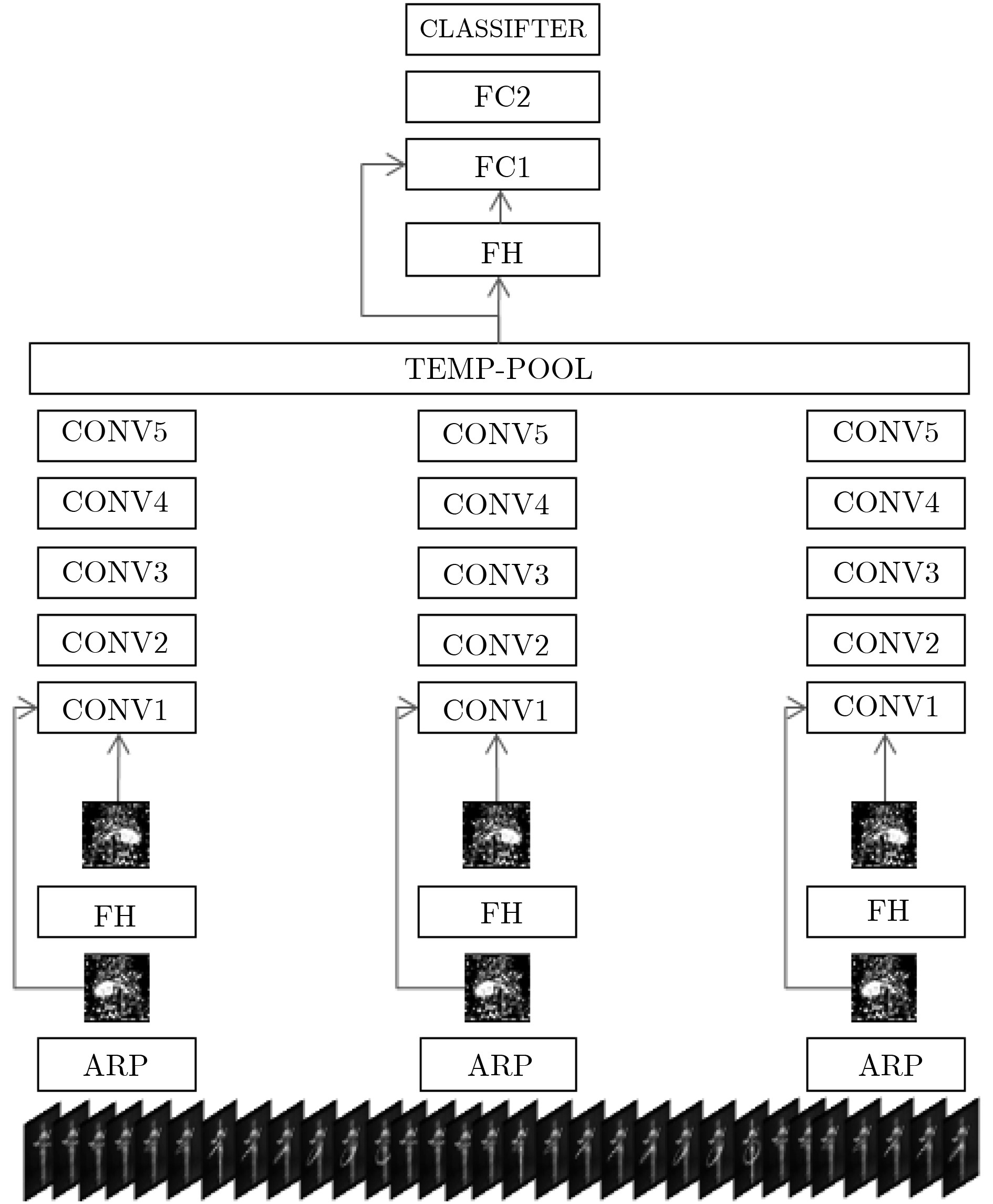
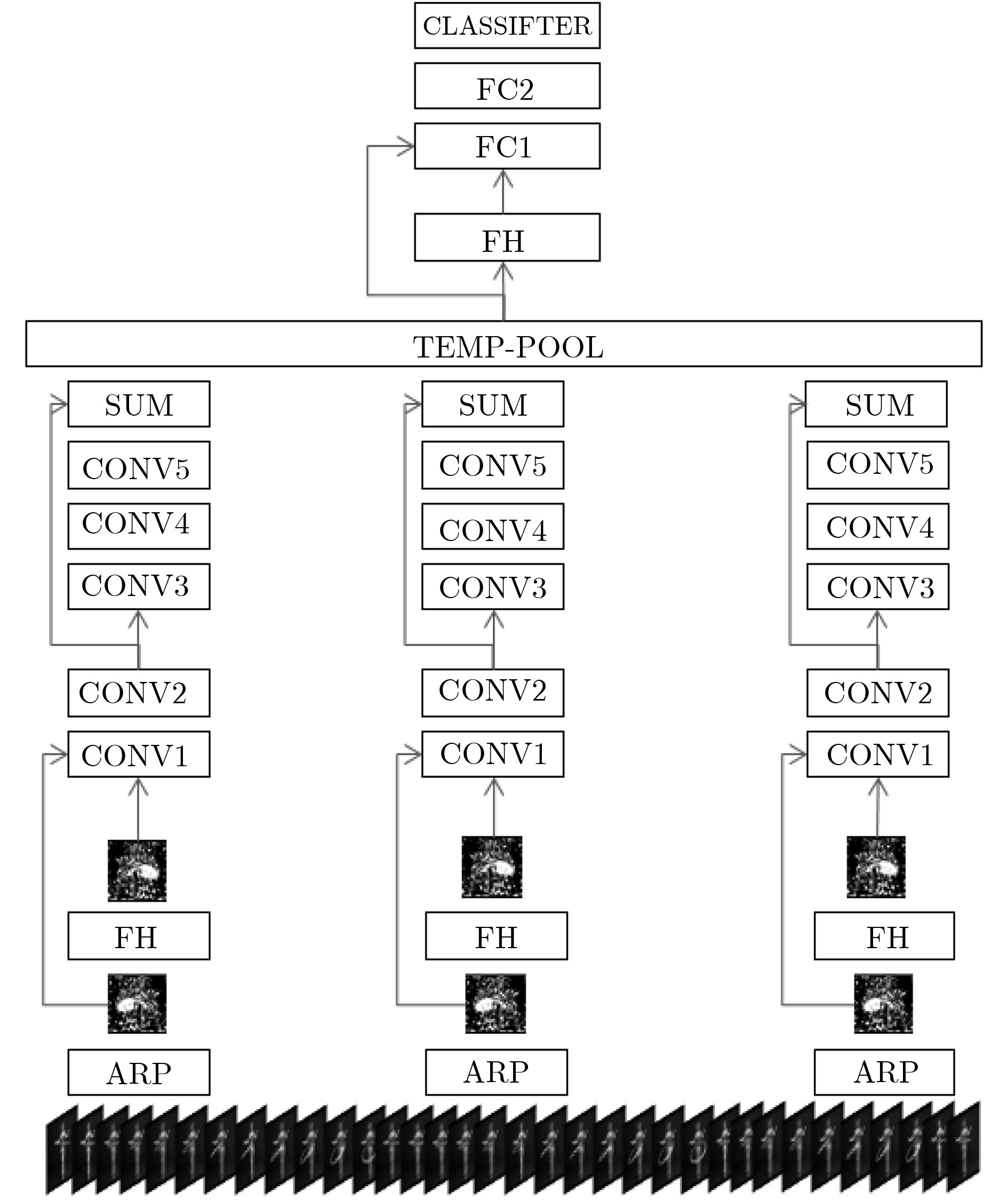
Abstract:To solve the problem of the loss in the motion features during the transmission of deep convolution neural networks and the overfitting of the network model, a cross layer fusion model and a multi-model voting action recognition method are proposed. In the preprocessing stage, the motion information in a video is gathered by the rank pooling method to form approximate dynamic images. Two basic models are presented. One model with two horizontally flipping layers is called " non-fusion model”, and then a fusion structure of the second layer and the fifth layer is added to form a new model named " cross layer fusion model”. The two basic models of " non-fusion model” and " cross layer fusion model” are trained respectively on three different data partitions. The positive and negative sequences of each video are used to generate two approximate dynamic images. So many different classifiers can be obtained by training the two proposed models using different training approximate dynamic images. In testing, the final classification results can be obtained by averaging the results of all these classifiers. Compared with the dynamic image network model, the recognition rate of the non-fusion model and the cross layer fusion model is greatly improved on the UCF101 dataset. The multi-model voting method can effectively alleviate the overfitting of the model, increase the robustness of the algorithm and get better average performance.
-
表 2 跨层融合模型动作识别准确度(%)
动作类 转呼啦圈 键盘打字 军队行进 弹吉他 掷铁饼 类平均 split1+正序 87.14 80.40 ${\underline{87.14}}$ ${\underline{91.33}}$ ${\underline{77.45}}$ 82.47 split1+反序 ${\underline{86.29}}$ 79.63 87.90 91.65 76.86 82.16 split2+正序 77.28 88.35 86.64 89.29 73.60 ${\underline{83.06}}$ split2+反序 76.66 ${\underline{88.88}}$ 86.27 90.88 71.31 83.87 split3+正序 78.72 89.25 87.02 91.21 78.20 83.03 split3+反序 78.91 86.46 86.99 90.66 76.65 82.79 注:粗体数字代表动作类中识别率最高,带下划线数字代表动作类的识别率次高。  下载: 导出CSV
下载: 导出CSV
-
BLACKBURN J and RIBEIRO E. Human Motion Recognition Using Isomap and Dynamic Time Warping[M]. Berlin Heidelberg: Springer, 2007: 285–298. QU Hang and CHENG Jian. Human action recognition based on adaptive distance generalization of isometric mapping[C]. Proceedings of the International Congress on Image and Signal Processing, Bangalore, India, 2013: 95–98. doi: 10.1109/cisp.2012.6469785. WANG Heng, KLÄSER A, SCHMID C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International Journal of Computer Vision, 2013, 103(1): 60–79. doi: 10.1007/s11263-012-0594-8 WANG Heng and SCHMID C. Action recognition with improved trajectories[C]. Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2013: 3551–3558. doi: 10.1109/iccv.2013.441. OHNISHI K, HIDAKA M, and HARADA T. Improved dense trajectory with cross streams[C]. ACM on Multimedia Conference, Amsterdam, Holland, 2016: 257–261. doi: 10.1145/2964284.2967222. AHAD M A R, TAN J, KIM H, et al. Action recognition by employing combined directional motion history and energy images[C]. IEEE Conference On Computer Vision and Pattern Recognition. San Francisco, USA, 2010: 73–78. doi: 10.1109/CVPRW.2010.5543160. BILEN H, FERNANDO B, GAVVES E, et al. Dynamic image networks for action recognition[C]. Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 3034–3042. doi: 10.1109/cvpr.2016.331. CHERIAN A, FERNANDO B, HARANDI M, et al. Generalized rank pooling for activity recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 3222–3231. doi: 10.1109/cvpr.2017.172. SIMONYAN K and ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]. Proceedings of the International Conference on Neural Information Processing Systems, Sarawak, Malaysia, 2014: 568–576. doi: 10.1109/iccvw.2017.368. LIU Hong, TU Juanhui, and LIU Mengyuan. Two-stream 3D convolutional neural network for skeleton-based action recognition[OL]. https://arxiv.org/abs/1705.08106, 2017. MOLCHANOV P, GUPTA S, KIM K, et al. Hand gesture recognition with 3D convolutional neural networks[C]. Proceedings of the Computer Vision and Pattern Recognition Workshops, Boston, USA, 2015: 1–7. doi: 10.1109/cvprw.2015.7301342. ZHU Yi, LAN Zhenzhong, NEWSAM S, et al. Hidden two-stream convolutional networks for action recognition[OL]. https://arxiv.org/abs/1704.00389, 2017. WEI Xiao, SONG Li, XIE Rong, et al. Two-stream recurrent convolutional neural networks for video saliency estimation[C]. Proceedings of the IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, Cagliari, Italy, 2017: 1–5. doi: 10.1109/bmsb.2017.7986223. SHI Yemin, TIAN Yonghong, WANG Yaowei, et al. Sequential deep trajectory descriptor for action recognition with three-stream CNN[J]. IEEE Transactions on Multimedia, 2017, 19(7): 1510–1520. doi: 10.1109/TMM.2017.2666540 SONG Sibo, CHANDRASEKHAR V, MANDAL B, et al. Multimodal multi-stream deep learning for egocentric activity recognition[C]. Proceedings of the Computer Vision and Pattern Recognition Workshops, Las Vegas, USA, 2016: 24–31. doi: 10.1109/cvprw.2016.54. NISHIDA N and NAKAYAMA H. Multimodal Gesture Recognition Using Multi-Stream Recurrent Neural Network[M]. New York, Springer-Verlag, Inc., 2015: 682–694. 朱丽, 吴雨川, 胡峰, 等. 老年人动作识别系统研究[J]. 计算机工程与应用, 2017, 53(14): 24–31. doi: 10.3778/j.issn.1002-8331.1703-0470ZHU Li, WU Yuchuan, HU Feng, et al. Study on action recognition system for the aged[J]. Computer engineering and Application, 2017, 53(14): 24–31. doi: 10.3778/j.issn.1002-8331.1703-0470 寿质彬. 基于神经网络模型融合的图像识别研究[D]. [硕士论文], 华南理工大学, 2015.SHOU Zhibin. Research on image recognition base on neural networks and model Combination[D]. [Master dissertation], South China University of Technology, 2015. HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. DIETTERICH T G. Ensemble methods in machine learning[J]. 1st International Workshgp on Multiple Classifier Systems, 2000, 1857(1): 1–15. doi: 10.1007/3-540-45014-9_1 FERNANDO B, GAVVES E, ORAMAS M J, et al. Modeling video evolution for action recognition[C]. Proceedings of the Computer Vision and Pattern Recognition, Boston, USA, 2015: 5378–5387. doi: 10.1109/cvpr.2015.7299176. SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[OL]. https://arxiv.org/abs/1212.0402, 2012. TRAN A and CHEONG L F. Two-stream flow-guided convolutional attention networks for action recognition[C]. Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 2017: 3110–3119. doi: 10.1109/iccvw.2017.368. SRIVASTAVA N, MANSIMOV E, and SALAKHUTDINOV R. Unsupervised learning of video representations using LSTMs[C]. International Conference on Machine Learning, Lille, France, 2015: 843–852. -

 下载:
下载:


计量
- 文章访问数: 2198
- HTML全文浏览量: 949
- PDF下载量: 70
- 被引次数: 0
