

Three-dimensional Interferometric Imaging and Micro-motion Feature Extraction of Rotating Space Targets Based on Narrowband Radar
-
摘要:
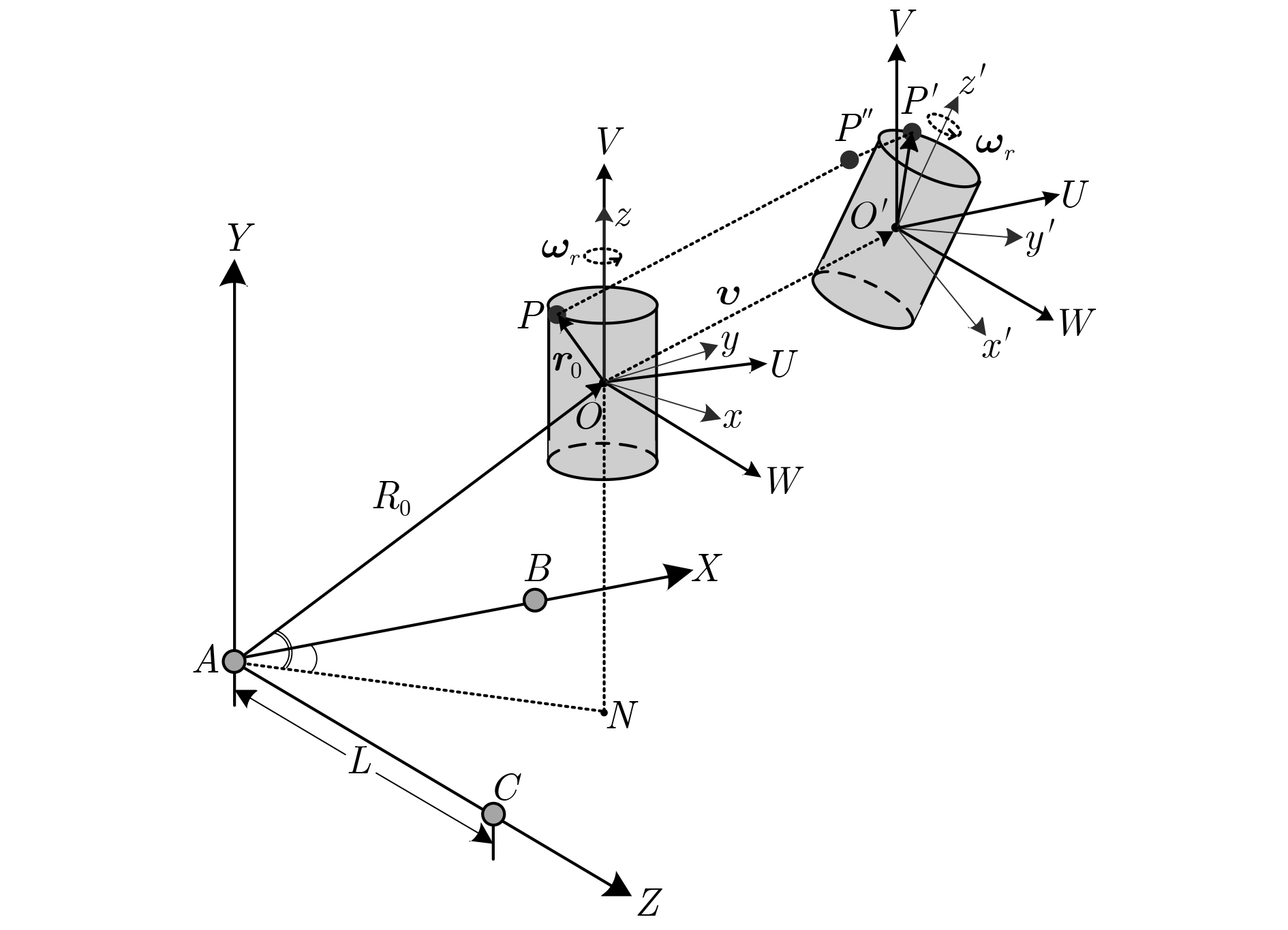
该文根据干涉式逆合成孔径雷达(InISAR)中多天线干涉处理的思想,提出一种基于L型3天线模型的空间旋转目标3维成像与3维微动特征提取方法。将微多普勒效应理论与多天线干涉处理技术相结合,在时频面上通过Viterbi算法分离散射点并进行干涉处理获取目标在各时刻沿基线方向的2维投影坐标;根据目标微动特性,采用非迭代椭圆拟合方法重构出散射点的高度维信息,实现目标的真实3维成像,并在成像过程中提取目标的3维微动特征参数。仿真实验验证了所提方法的有效性与鲁棒性。
Abstract:Inspired by the idea of multi-antenna interferometric processing in Interferometric Inverse Synthetic Aperture Radar (InISAR), by utilizing an L-shaped three-antenna imaging model, a Three-Dimensional (3-D) interferometric imaging and micro-motion feature extraction method for rotating space targets is proposed. Based on the integration of micro-Doppler (m-D) effect theory and multi-antenna interferometry processing technology, the m-D curves corresponding to different scatterers are obtained on the time-frequency plane and separated via Viterbi algorithm effectively, and then the projected coordinates of scatterers along the direction of baselines are reconstructed by interferometric processing. The height information of scatterers is solved by ellipse fitting, and 3-D imaging for the rotating space target is realized. Meanwhile, some 3-D micro-motion features are exactly extracted during imaging. Simulation results validate the effectiveness and the robustness of the method.
-
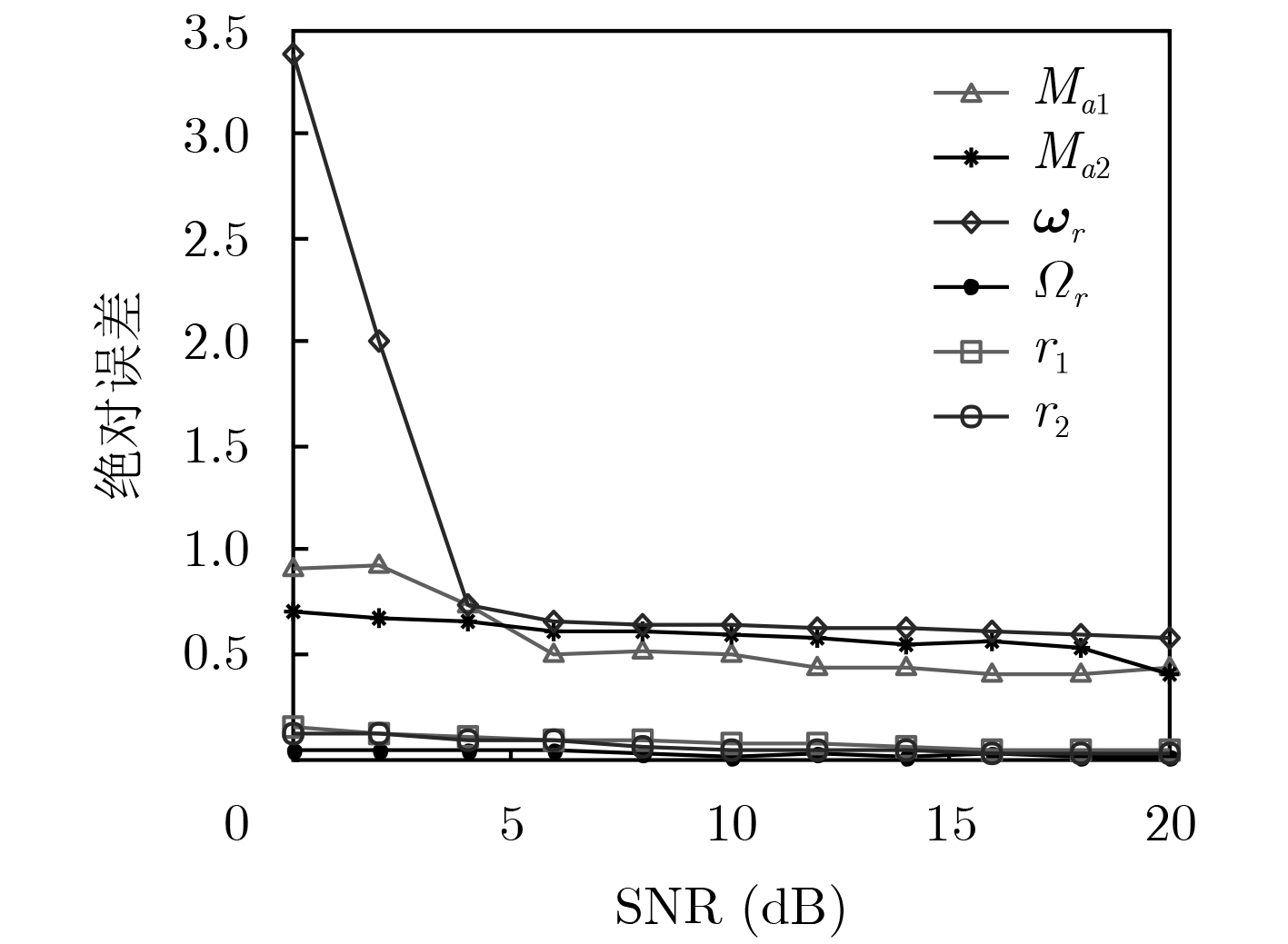
表 1 3维微动特征提取结果与估计误差
参数 ${M_{a1}}$ (Hz) ${M_{a2}}$ (Hz) ${\varOmega _r}$ (rad/s) ${r_1}$ (m) ${r_2}$ (m) ${{{ω}}_r}$ (rad/s) 理论值 546.3059 182.1020 10.8828 3.6742 1.5000 [6.6908, –8.5830, –0.0121] 估计值 546.2000 182.4000 10.8900 3.6786 1.4166 [6.6980, –8.5774, –0.0151] 绝对误差 0.1059 0.2980 0.0072 0.0044 0.0834 0.0287  下载: 导出CSV
下载: 导出CSV
-
ZHANG Qun, LUO Ying, and CHEN Yongan. Micro-Doppler Characteristics of Radar Targets[M]. Amsterdam: Elsevier, 2016: 3–54. SATO T. Shape estimation of space debris using single-range Doppler interferometry[J]. IEEE Transactions on Geoscience and Remote Sensing, 1999, 37(2): 1000–1005. doi: 10.1109/36.752218 WANG Qi, XING Mengdao, LU Guangyue, et al. Single range matching filtering for space debris radar imaging[J]. IEEE Geoscience and Remote Sensing Letters, 2007, 4(4): 576–580. doi: 10.1109/LGRS.2007.903059 BAI Xueru, SUN Guangcai, WU Qisong, et al. Narrow-band radar imaging of spinning targets[J]. Science China (Information Science) , 2011, 54(4): 873–883. doi: 10.1007/s11432-011-4182-2 ZHANG Qun, YEO T S, DU Gan, et al. Estimation of three-dimensional motion parameters in interferometric ISAR Imaging[J]. IEEE Transactions on Geoscience and Remote Sensing, 2004, 42(2): 292–300. doi: 10.1109/TGRS.2003.815669 MA Changzheng, YEO T S, ZHANG Qun, et al. Three-dimensional ISAR imaging based on antenna array[J]. IEEE Transactions on Geoscience and Remote Sensing, 2008, 46(2): 504–515. doi: 10.1109/TGRS.2007.909946 胡健, 罗迎, 张群, 等. 弹道目标宽带雷达干涉式三维成像与微动特征提取[J]. 电子与信息学报, 2017, 39(8): 1865–1871. doi: 10.11999/JEIT161134HU Jian, LUO Ying, ZHANG Qun, et al. Three-dimensional interferometric imaging and micro-motion feature extraction of ballistic targets in wideband radar[J]. Journal of Electronics &Information Technology, 2017, 39(8): 1865–1871. doi: 10.11999/JEIT161134 SURESH P, THAYAPARAN T, OBULESU T, et al. Extracting micro-Doppler radar signatures from rotating targets using Fourier-Bessel transform and time-frequency analysis[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(6): 3204–3210. doi: 10.1109/TGRS.2013.2271706 ZHANG Qun, YEO T S, TAN H S, et al. Imaging of a moving target with rotating parts based on the Hough transform[J]. IEEE Transactions on Geoscience and Remote Sensing, 2008, 46(1): 291–299. doi: 10.1109/TGRS.2007.907105 FITZGIBBON A, PILU M, and FISHER R B. Direct least squares fitting of ellipses[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(5): 476–480. doi: 10.1109/34.765658 梁必帅, 张群, 娄昊, 等. 基于微动特征关联的空间自旋目标宽带雷达三维成像[J]. 电子与信息学报, 2013, 35(9): 2133–2140. doi: 10.3724/SP.J.1146.2012.01537LIANG Bishuai, ZHANG Qun, LOU Hao, et al. Three-dimensional broadband radar imaging of space spinning targets based on micro-motion parameter correlation[J]. Journal of Electronics &Information Technology, 2013, 35(9): 2133–2140. doi: 10.3724/SP.J.1146.2012.01537 梁必帅, 张群, 娄昊, 等. 基于微动特征关联的空间非对称自旋目标雷达三维成像方法[J]. 电子与信息学报, 2014, 36(6): 1381–1388. doi: 10.3724/SP.J.1146.2013.01147LIANG Bishuai, ZHANG Qun, LOU Hao, et al. A method of three-dimensional imaging based on micro-motion feature association for spatial asymmetrical spinning targets[J]. Journal of Electronics &Information Technology, 2014, 36(6): 1381–1388. doi: 10.3724/SP.J.1146.2013.01147 -

 下载:
下载:







计量
- 文章访问数: 2539
- HTML全文浏览量: 901
- PDF下载量: 107
- 被引次数: 0
