

Region Proposal Generation for Object Detection Using Tree-DDQN by Action Attention
-
摘要:
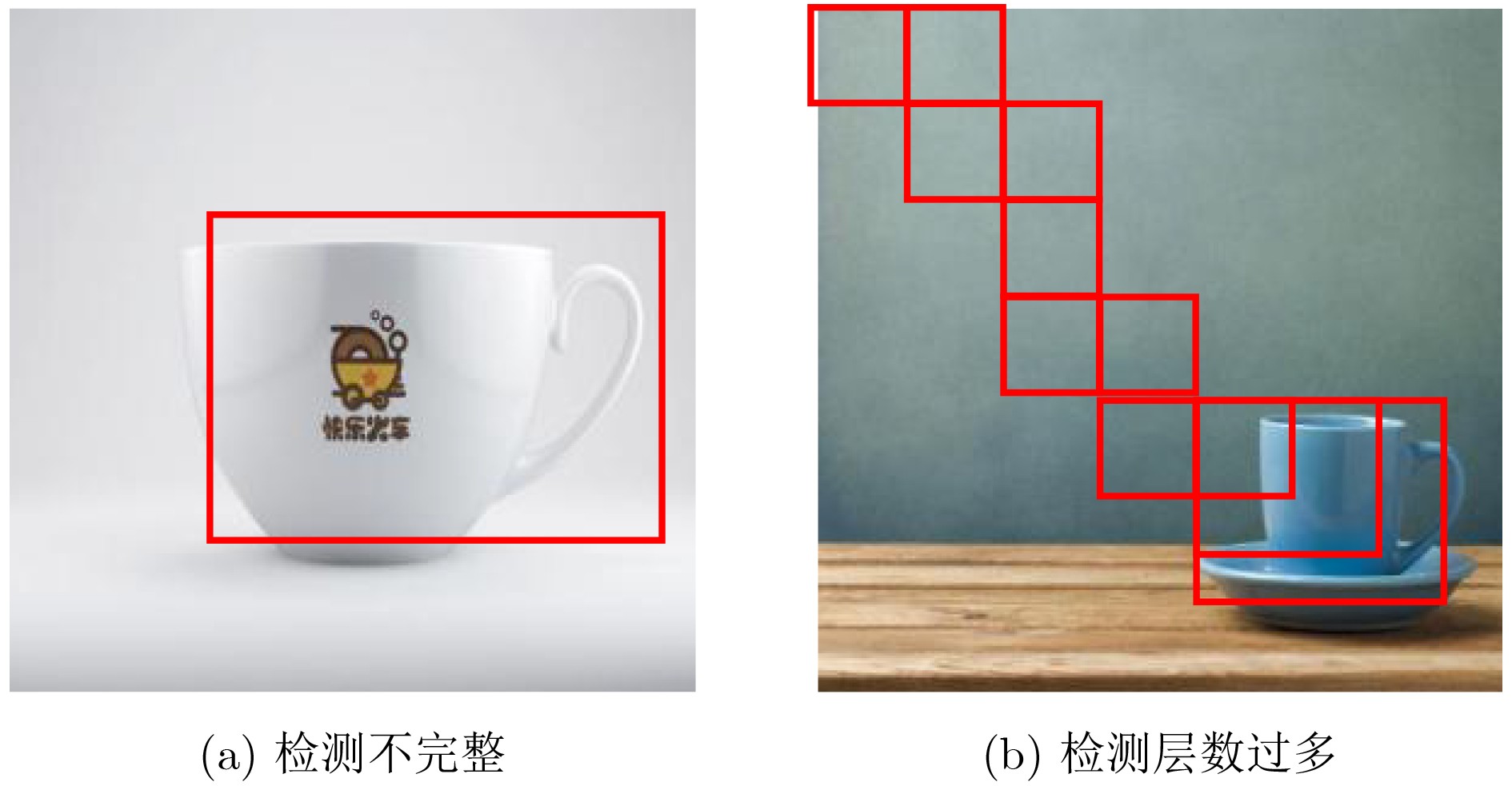
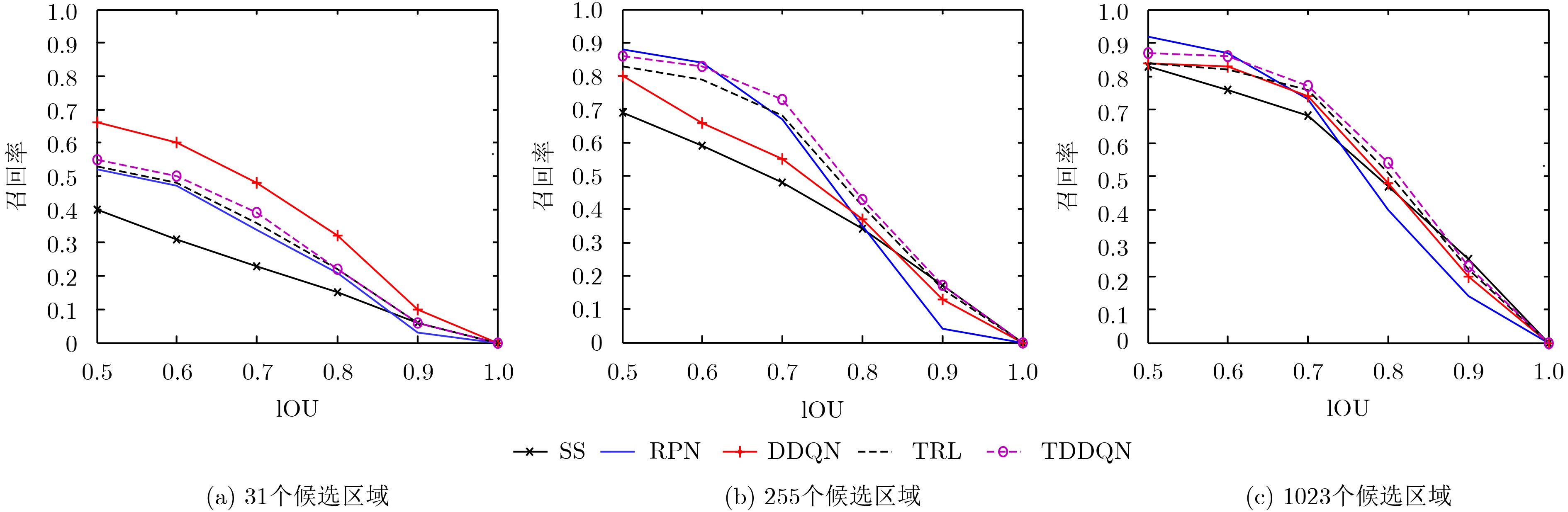
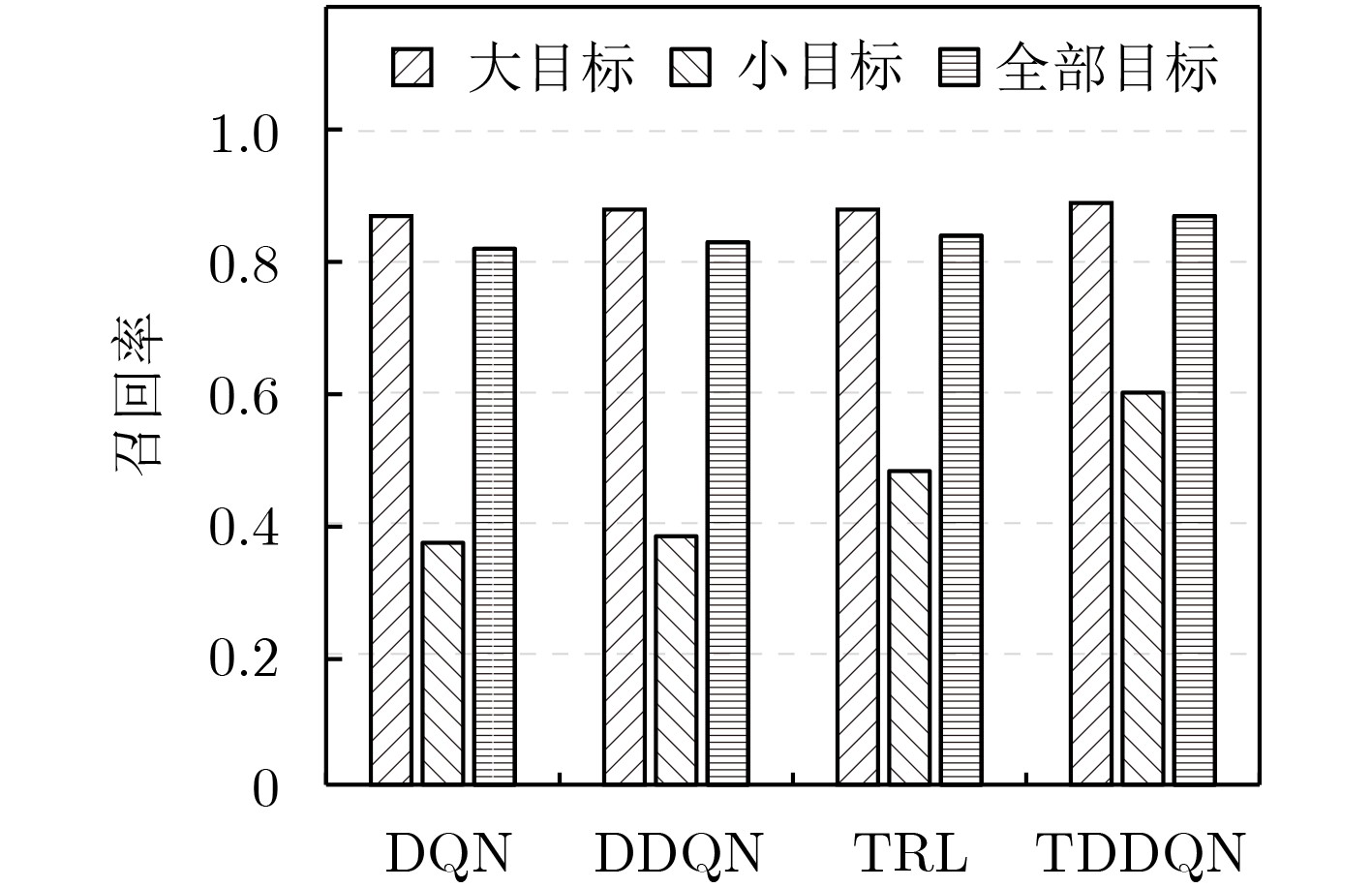
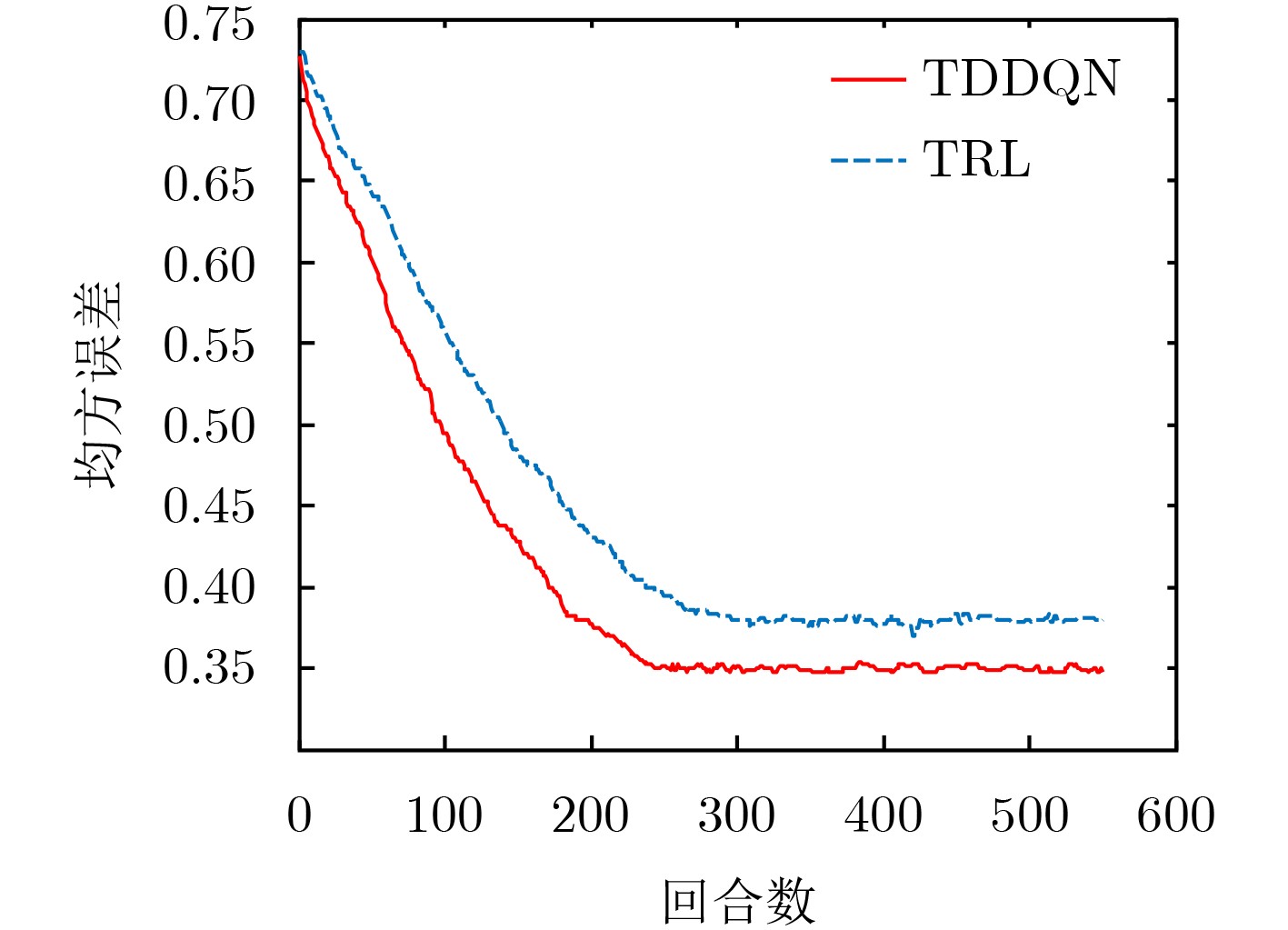
针对机器人在家庭环境下的目标检测问题,该文提出一种基于动作注意策略的树形双深度Q网络(TDDQN)目标候选区域提取的方法,该方法将双深度Q网络(DDQN)的方法与树结构的方法相结合,通过执行改变检测框的动作以使目标逐渐集中在检测框内。首先采用DDQN方法在执行较少的动作后选择出当前状态的最佳动作,获取符合条件的候选区域。然后根据执行所选择动作之后所得到的状态重复执行上述过程,以此构成树结构的多条“最佳”路径。最后采用非极大值抑制的方法从多个符合条件的候选区域选择出最佳候选区域。在Pascal VOC2007以及Pascal VOC2012上的实验结果表明,在不同数量的候选区域、不同阈值的IoU和不同大小以及不同种类对象的实验条件下,所提方法较其他方法都有着更好的检测性能,可以较好地实现目标检测。
Abstract:Considering the problem of object detection of robots in the home environments, a Tree-Double Deep Q Network (TDDQN) based on the attention action strategy is proposed to determine the locations of region proposals. It combines DDQN with hierarchical tree structure. First, DDQN is used to select the best action of current state and obtain the right region proposal with a few actions executed. According to the state obtained after executing the selected action, the above process is repeated to create multiple "best" paths of the hierarchical tree structure. The best region proposal is selected using non-maximum suppression on region proposals that meet the conditions. Experimental results on Pascal VOC2007 and Pascal VOC2012 show that the proposed method based on TDDQN has better detection performance than other methods for region proposals of different numbers, different Intersection-over-Union (IoU) values and objects of different sizes and kinds, respectively.
-
Key words:
- Object detection /
- Region proposal /
- Tree structure /
- Double Deep Q Network (DDQN) /
- Action attention
-
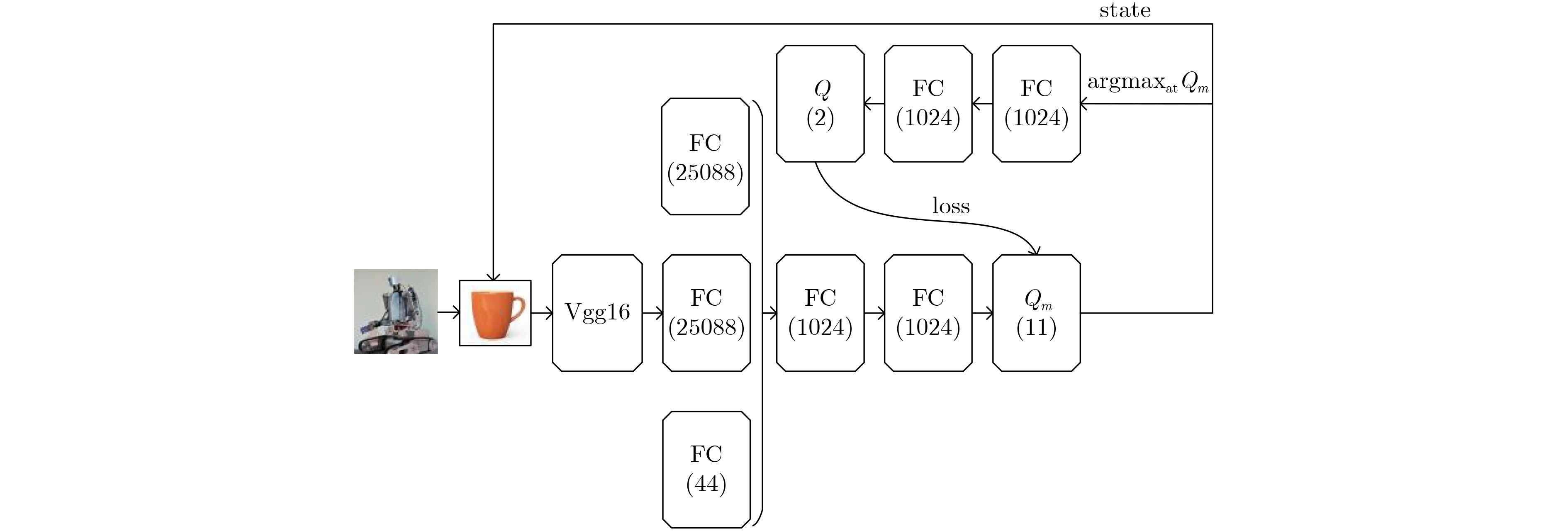
表 1 基于TDDQN的候选区域提取方法
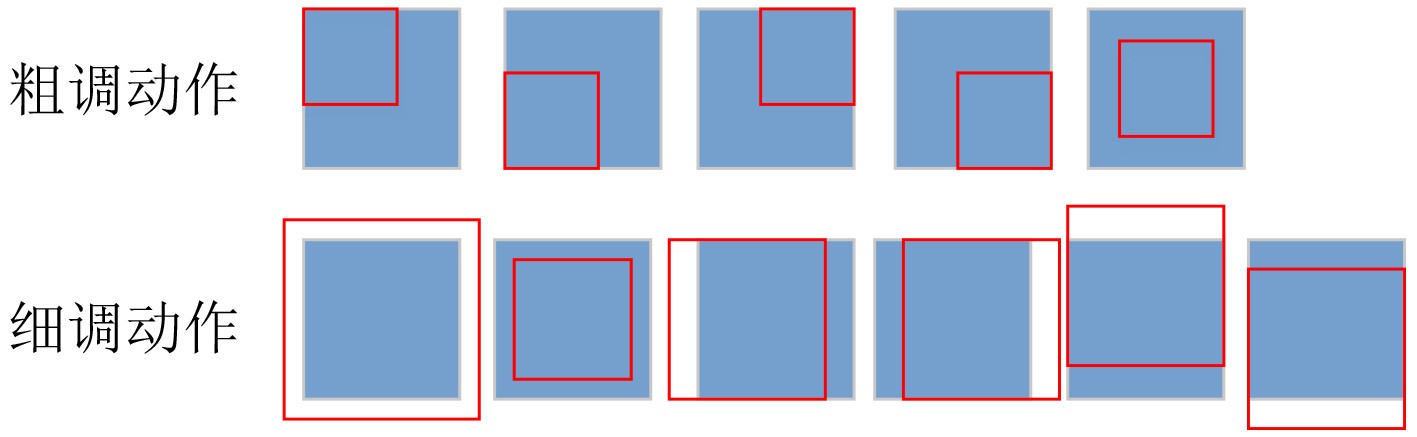
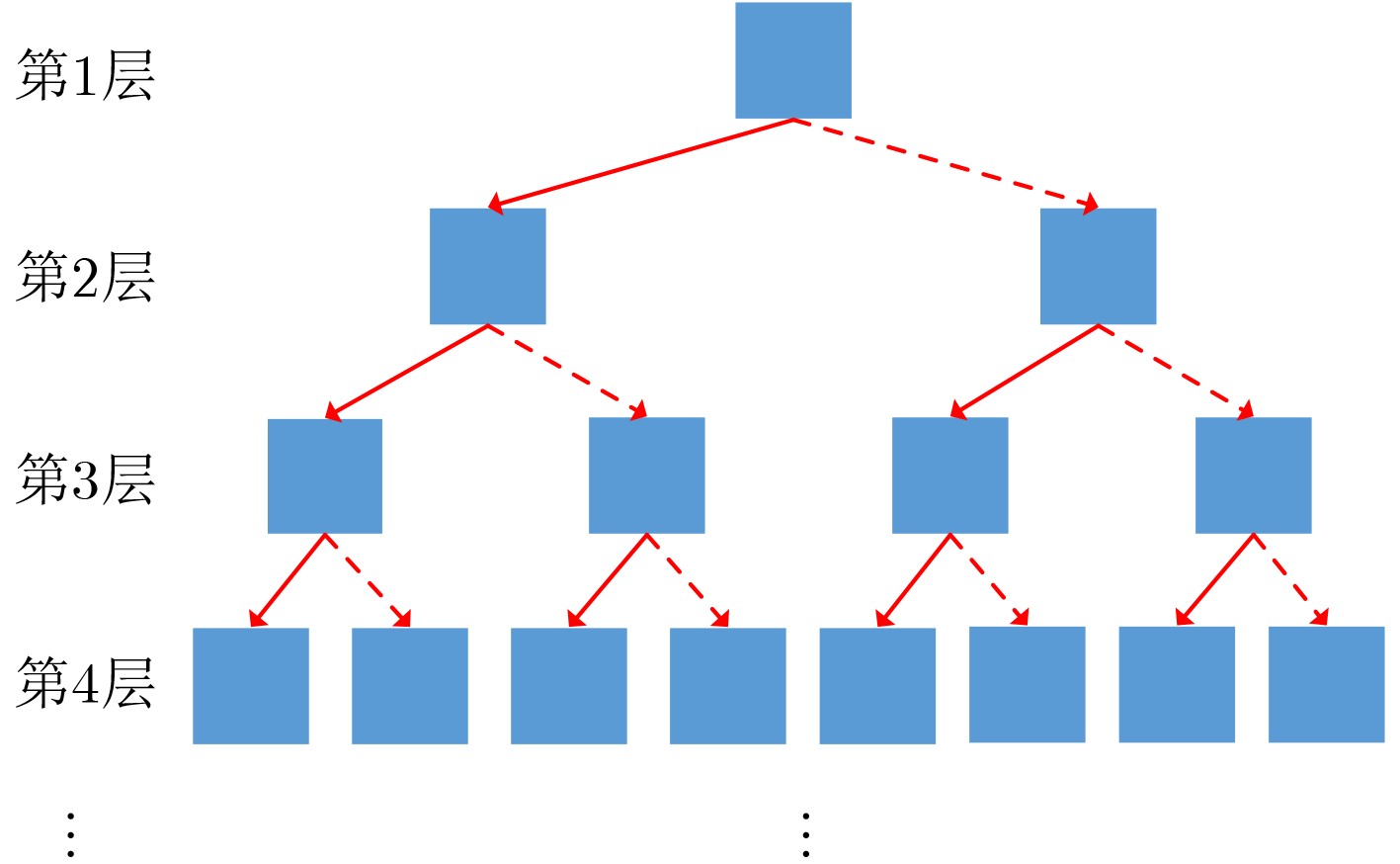
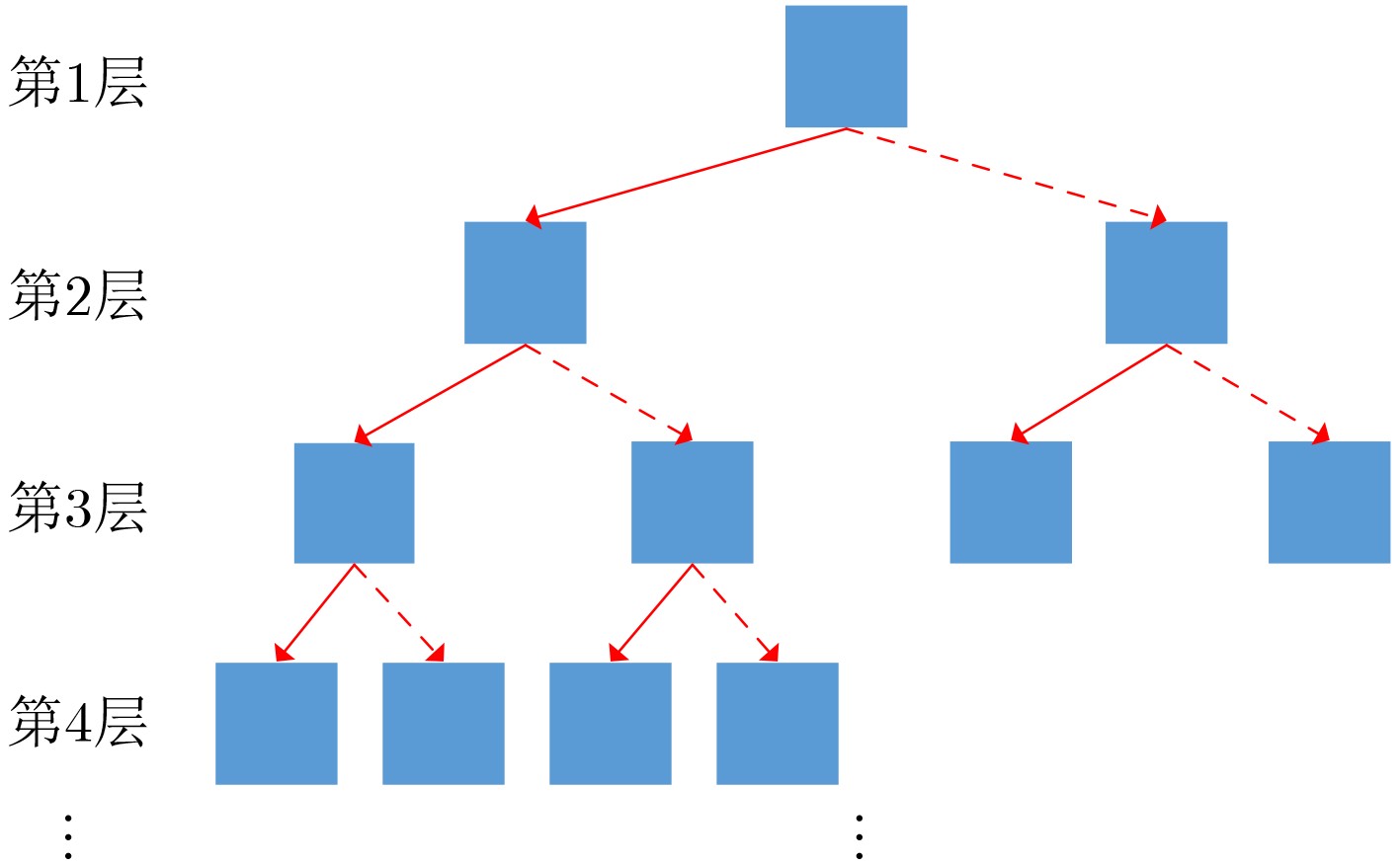
输入 当前状态(候选区域,树的根节点) 输出 下一状态(新候选区域,树的子节点) 步骤1 初始化IoU的阈值$\tau $和树的最大层次数n的值,并设树的
初始层次数为1;步骤2 根据当前状态,分别在粗调动作组和细调动作组中选择
出经过DDQN方法得到的预测值最高的两个动作;步骤3 执行粗调动作后得到的状态作为左节点,执行细调动作
后得到的状态作为右节点;步骤4 树的层次数加1; 步骤5 如果当前树的层次数小于n,并且仍有分支没有被截止,
则执行步骤6,否则执行步骤7;步骤6 如果左节点IoU大于$\tau $,则予以截止,否则将左节点作为
其所在路径的当前状态并执行步骤2;相应地,如果右节
点IoU大于$\tau $,则予以截止,否则将右节点作为其所在路
径的当前状态并执行步骤2;步骤7 对所有叶节点用非极大值抑制方法选取最优的候选区域。  下载: 导出CSV
下载: 导出CSV
表 2 不同方法下Pascal VOC2007数据集中各检测对象的平均检测精度(%)
方法 瓶子 椅子 桌子 狗 人 沙发 电视机 平均检测精度均值 RPN (vgg16)+Fast R-CNN (ResNet-101) 54.3 60.2 70.8 84.1 76.2 78.7 73.0 71.0 Faster R-CNN (ResNet-101) 55.6 56.4 69.1 88.0 77.8 79.5 71.7 71.2 DQN (vgg16)+Fast R-CNN (ResNet-101) 50.4 54.3 61.8 80.2 71.1 73.5 68.9 65.7 DDQN (vgg16)+Fast R-CNN (ResNet-101) 52.6 55.2 61.3 80.5 71.3 74.0 69.1 66.3 TRL (vgg16)+Fast R-CNN (ResNet-101) 55.0 60.1 73.3 84.5 76.3 79.6 73.4 71.7 TDDQN (vgg16)+Fast R-CNN (ResNet-101) 55.7 60.2 74.2 85.3 77.4 79.6 73.7 72.3
下载: 导出CSV
表 3 不同方法下Pascal VOC2012数据集中各检测对象的平均检测精度(%)
方法 瓶子 椅子 桌子 狗 人 沙发 电视机 平均检测精度均值 RPN (vgg16)+Fast R-CNN (ResNet-101) 50.5 48.6 57.1 90.0 79.0 66.1 65.9 65.3 Faster R-CNN (ResNet-101) 50.8 48.5 59.0 91.9 80.5 66.3 65.4 66.1 DQN (vgg16)+Fast R-CNN (ResNet-101) 49.3 45.7 50.8 82.8 73.9 59.9 63.6 60.9 DDQN (vgg16)+Fast R-CNN (ResNet-101) 51.5 47.6 52.3 82.9 75.2 61.1 63.8 62.1 TRL (vgg16)+Fast R-CNN (ResNet-101) 53.1 51.7 55.6 87.8 80.7 66.6 67.6 66.2 TDDQN (vgg16)+Fast R-CNN (ResNet-101) 53.4 51.9 58.7 88.0 80.9 66.8 67.9 66.8
下载: 导出CSV
表 4 不同数据集上检测单张图片消耗的平均时间(s)
数据集 TDDQN (vgg16)+Fast R-CNN (ResNet-101) TRL (vgg16)+Fast R-CNN (ResNet-101) Faster R-CNN (ResNet-101) VOC2007 0.9 1.6 0.4 VOC2012 1.0 1.8 0.5
下载: 导出CSV
-
TANG K, JOULIN A, LI L J, et al. Co-localization in real-world images[C]. Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1464–1471. 伍锡如, 黄国明, 孙立宁. 基于深度学习的工业分拣机器人快速视觉识别与定位算法[J]. 机器人, 2016, 38(6): 711–719. doi: 10.13973/j.cnki.robot.2016.0711WU Xiru, HUANG Guoming, and SUN Lining. Fast visual identification and location algorithm for industrial sorting robots based on deep learning[J]. Robot, 2016, 38(6): 711–719. doi: 10.13973/j.cnki.robot.2016.0711 DALAL N and TRIGGS B. Histograms of oriented gradients for human detection[C]. Computer Vision and Pattern Recognition, San Diego, USA, 2005: 886–893. SANDE K E A V D, UIJLINGS J R R, GEVERS T, et al. Segmentation as selective search for object recognition[C]. International Conference on Computer Vision, Barcelona, Spain, 2011, 1879–1886. ZITNICK C L and DOLLAR P. Edge boxes: Locating object proposals from edges[C]. European Conference on Computer Vision, Zurich, Switzerland, 2014, 391–405. GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Computer Vision and Pattern Recognition, Columbus, USA, 2014, 580–587. GONZALEZ-GARCIA A, Vezhnevets A, and FERRARI V. An active search strategy for efficient object class detection[C]. Computer Vision and Pattern Recognition, Boston, USA, 2015, 3022–3031. CAICEDO J C and LAZEBNIK S. Active object localization with deep reinforcement learning[C]. International Conference on Computer Vision, Santiago, Chile, 2015, 2488–2496. BELLVER M, GIROINIETO X, MARQUES F, et al. Hierarchical object detection with deep reinforcement learning[OL]. http://arxiv.org/abs/1611.03718v2, 2016. doi: 10.3233/978-1-61499-822-8-164. JIE Zequn, LIANG Xiaodan, FENG Jiashi, et al. Tree-structured reinforcement learning for sequential object localization[C]. International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016, 127–135. HASSELT H V. Double Q-learning[C]. International Conference on Neural Information Processing Systems, Whistler, Canada, 2010, 2613–2621. HASSELT H V, GUEZ A, and SILVER D. Deep reinforcement learning with double Q-learning[C]. Association for the Advancement of Artificial Intelligence, Phoenix, USA, 2016, 2094–2100. REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 NAJEMNIK J and GEISLER W S. Optimal eye movement strategies in visual search[J]. American Journal of Ophthalmology, 2005, 139(6): 1152–1153. doi: 10.1038/nature03390 -

 下载:
下载:



计量
- 文章访问数: 2067
- HTML全文浏览量: 1026
- PDF下载量: 60
- 被引次数: 0
