

On Anti-outlier Localization for Integrated Long Baseline/Ultra-short Baseline Systems
-
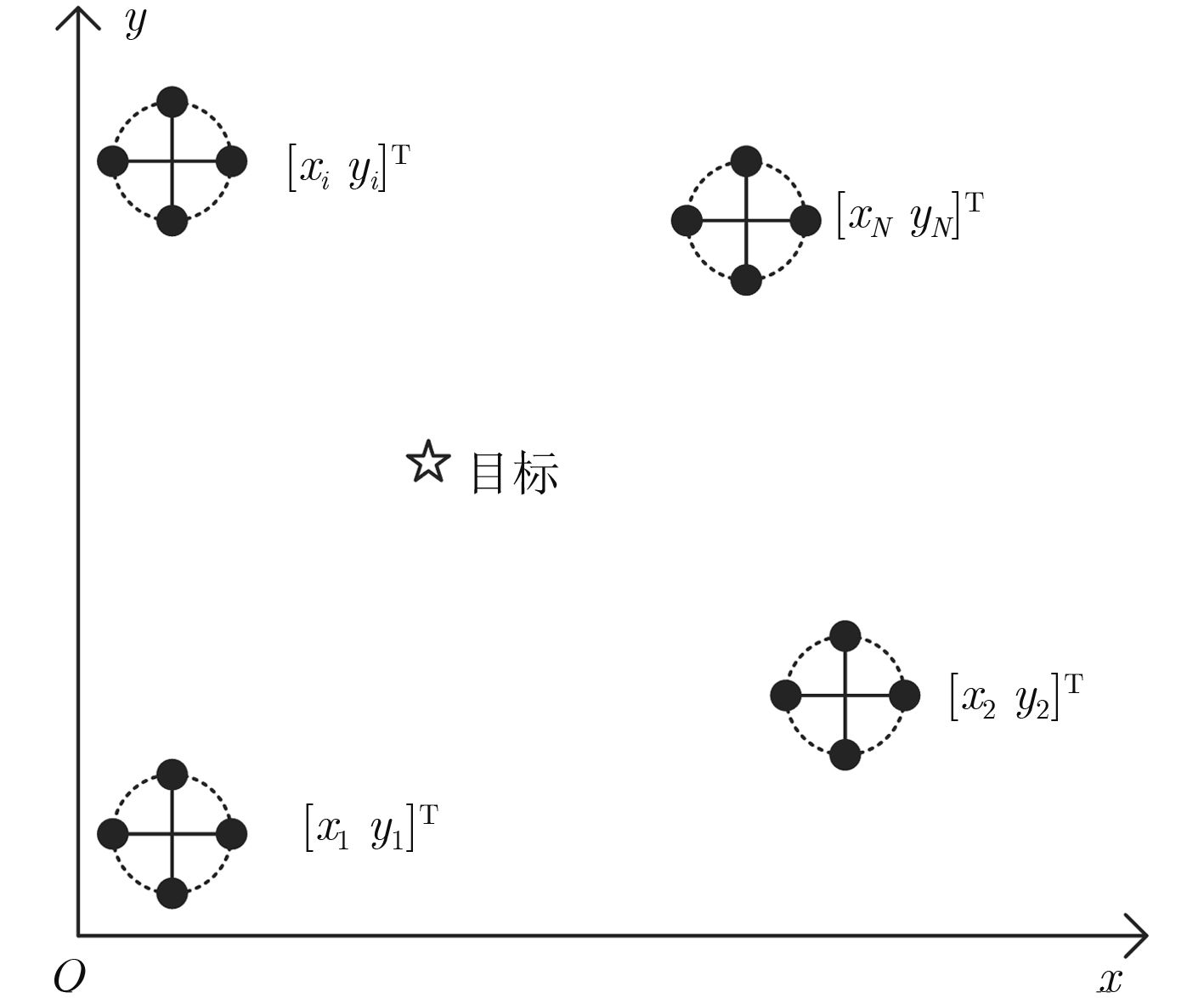
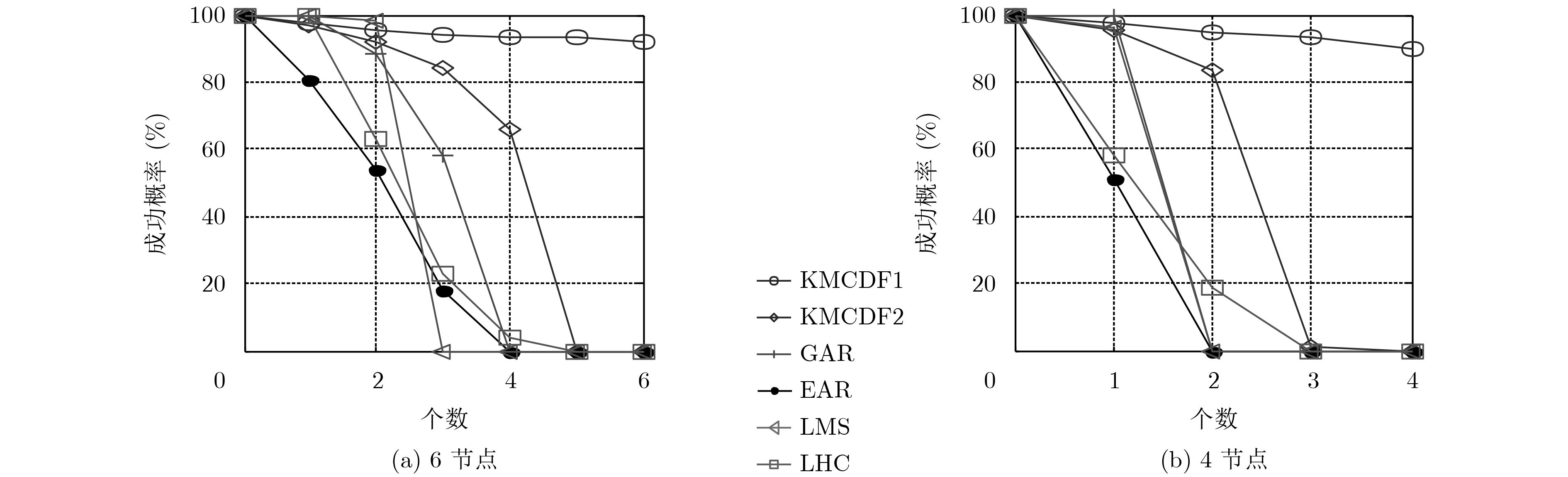
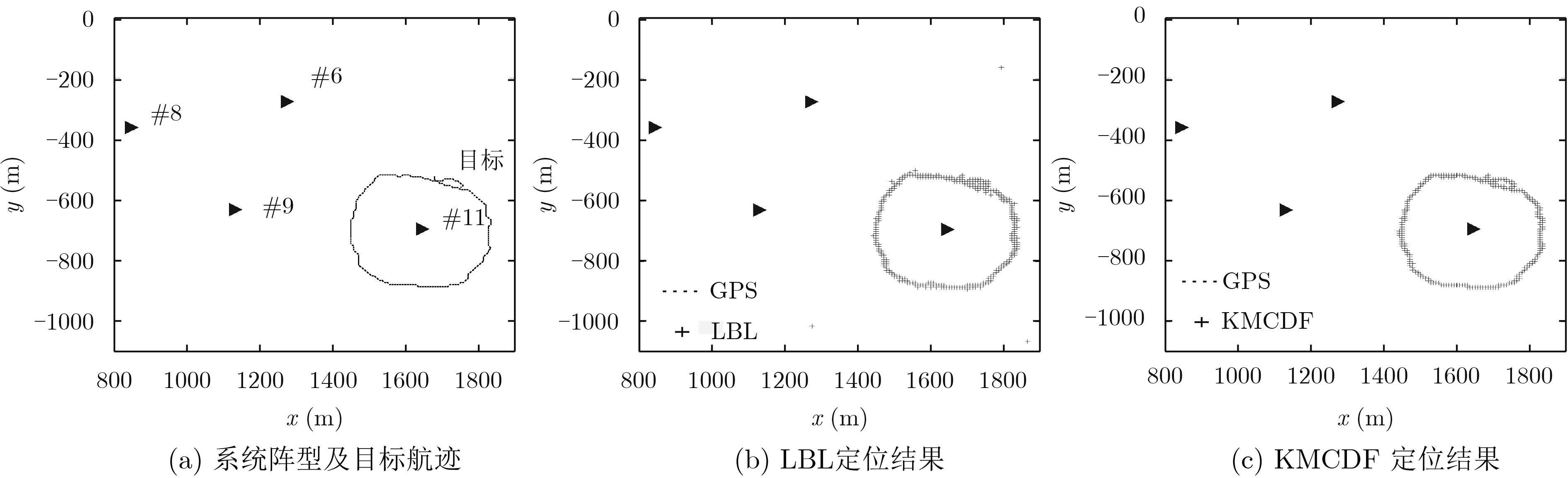
摘要: 复杂的水下环境对水声定位系统的容错性及可靠性提出较高要求,对于长基线/超短基线组合水声定位系统,该文提出基于k-means聚类和决策融合的抗异常参量定位方法(KMCDF)。该方法首先通过组合定位系统测量的多参量冗余信息对目标位置进行初步测量,再利用k-means聚类对初测值的聚集度进行分析,根据异常参量与正常参量间的不相容性,采用决策融合方法对异常参量进行识别,进而消除异常值对定位结果的影响。仿真分析表明,与现有的基于时延参量的抗异常值方法相比,提出的抗异常值定位方法充分融合了多参量观测信息,对异常值的容忍度较高。湖试结果进一步验证了该方法的有效性。Abstract: Complicated underwater environment puts forward high requirements on the fault-tolerant and reliability of underwater acoustic localization systems. An anti-outlier localization method based on K-Means Clustering and Decision Fusion (KMCDF) is proposed for integrated Long baseline/Ultra-Short BaseLine (L/USBL) systems. Firstly, the target position is preliminarily estimated by the multi-parameter redundant information measured by the integrated system. Then, the clustering degree of the preliminary coordinates is analyzed by k-means clustering. According to the incompatibility between outliers and normal parameters, the outliers are identified by the decision fusion method. Furthermore, the impact of outliers on positioning is eliminated. Simulation analysis shows that the proposed method fully incorporates the multi-parameter information, and the tolerance of outliers is better than the existing anti-outlier positioning methods based on the time-delay parameter. Lake trial results demonstrate further the effectiveness of the proposed method.
-
Key words:
- Reliable localization /
- Integrated baseline /
- Outlier /
- Clustering /
- Decision fusion
-
BAYAT M, CRASTA N, AGUIAR A P, et al. Range-based underwater vehicle localization in the presence of unknown ocean currents: theory and experiments[J]. IEEE Transactions on Control Systems Technology, 2016, 24(1): 122–139 doi: 10.1109/TCST.2015.2420636 RAMEZANI H, FAZEL F, STOJANOVIC M, et al. Collision tolerant and collision free packet scheduling for underwater acoustic localization[J]. IEEE Transactions on Wireless Communications, 2015, 14(5): 2584–2595 doi: 10.1109/TWC.2015.2389220 汝小虎, 柳征, 姜文利, 等. 带虚警抑制的基于归一化残差的野值检测方法[J]. 电子与信息学报, 2015, 37(12): 2898–2905 doi: 10.11999/JEIT150469RU Xiaohu, LIU Zheng, JIANG Wenli, et al. Normalized residual-based outlier detection with false-alarm probability controlling[J].Journal of Electronics&Information Technology, 2015, 37(12): 2898–2905 doi: 10.11999/JEIT150469 庞菲菲, 张群飞, 史文涛, 等. 基于Parzen窗的水下无线传感器网络目标定位方法[J]. 电子与信息学报, 2017, 39(1): 45–50 doi: 10.11999/JEIT160246PANG Feifei, ZHANG Qunfei, SHI Wentao, et al. Target localization method based on Parzen window in underwater wireless sensor network[J]. Journal of Electronics&Information Technology, 2017, 39(1): 45–50 doi: 10.11999/JEIT160246 LIU Donggang, NING Peng, and DU Wenliang Kevin. Attack-resistant location estimation in sensor networks[C]. Proceedings of the 4th International Symposium on Information Processing in Sensor Networks, Los Angeles, USA, 2005: 99–106. LIU Donggang, NING Peng, LIU An, et al. Attack-resistant location estimation in wireless sensor networks[J]. ACM Transactions on Information and System Security, 2008, 11(4): 1–39 doi: 10.1145/1380564.1380570 LI Zang, TRAPPE W, ZHANG Yanyong, et al. Robust statistical methods for securing wireless localization in sensor networks[C]. Proceedings of the 4th International Symposium on Information Processing in Sensor Networks, Los Angeles, USA, 2005: 91–98. KORKMAZ S and VEEN A J V D. Robust localization in sensor networks with iterative majorization techniques[C]. Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, China, 2009: 2049–2052. 张天骐, 杨强, 宋玉龙, 等. 一种K-means改进算法的软扩频信号伪码序列盲估计[J]. 电子与信息学报, 2018, 40(1): 226–234 doi: 10.11999/JEIT170306ZHANG Tianqi, YANG Qiang, SONG Yulong, et al. Blind estimation PN sequence in soft spread spectrum signal of improved k-means algorithm[J]. Journal of Electronics&Information Technology, 2018, 40(1): 226–234 doi: 10.11999/JEIT170306 朱明. 数据挖掘[M]. 合肥: 中国科技大学出版社, 2002: 22, 139–157.ZHU Ming. Data Mining[M]. Hefei: University of Science and Technology of China Press, 2002: 22, 139–157. 韩云峰, 李昭, 郑翠娥, 等. 一种基于长基线交汇的超短基线定位系统精度评价方法[J]. 物理学报, 2015, 64(9): 094301 doi: 10.7498/aps.64.094301HAN Yunfeng, LI Zhao, ZHENG Cuie, et al. A precision evaluation method of USBL positioning systems based on LBL triangulation[J]. Acta Physica Sinica, 2015, 64(9): 094301 doi: 10.7498/aps.64.094301 王燕, 岳剑平, 冯海泓. 双基阵纯方位目标运动分析研究[J]. 声学学报, 2001, 26(5): 405–409 doi: 10.15949/j.cnki.0371-0025.2001.05.005WANG Yan, YUE Jianping, and FENG Haihong. Study on bearings-only target motion analysis based on association of dual arrays[J]. Acta Acustica, 2001, 26(5): 405–409 doi: 10.15949/j.cnki.0371-0025.2001.05.005 付进. 长基线定位信号处理若干关键技术研究[D]. [博士论文], 哈尔滨工程大学, 2007.FU Jin. Research on several key techniques of the signal processing for long baseline location[D]. [Ph.D. dissertation], Harbin Engineering University, 2007. 张捍东, 孙成慧, 岑豫皖. 分布式多传感器结构中的数据融合方法[J]. 华中科技大学学报, 2008, 36(6): 37–39 doi: 10.13245/j.hust.2008.06.036ZHANG Handong, SUN Chenghui, and CEN Yuwan. Data fusion method for the configuration of distributed multi-sensor[J]. Journal of Huazhong University of Science and Technology, 2008, 36(6): 37–39 doi: 10.13245/j.hust.2008.06.036 蒋正新, 施国梁. 矩阵理论及其应用[M]. 北京: 北京航空学院出版社, 1988: 371–378.JIANG Zhengxin and SHI Guoliang. Matrix Theory and Application[M]. Beijing: Beihang University Press, 1988: 371–378. 梁继民. 多传感器决策融合方法研究[D]. [博士论文], 西安电子科技大学, 1999.LIANG Jimin. Study of multisensor decision fusion[D]. [Ph.D. dissertation], Xidian University, 1999. -

 下载:
下载:


图(3)
计量
- 文章访问数: 2016
- HTML全文浏览量: 1039
- PDF下载量: 63
- 被引次数: 0
