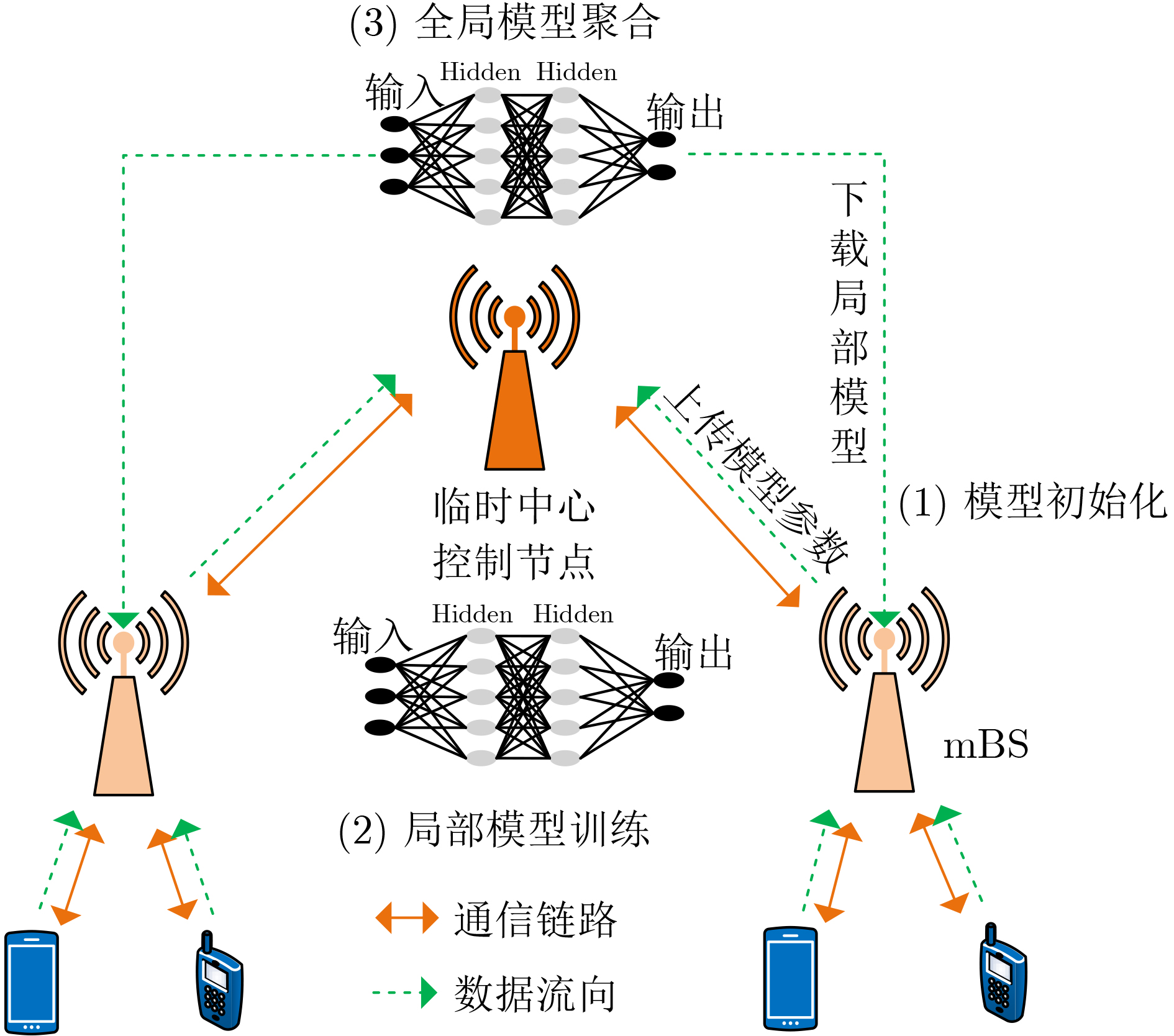
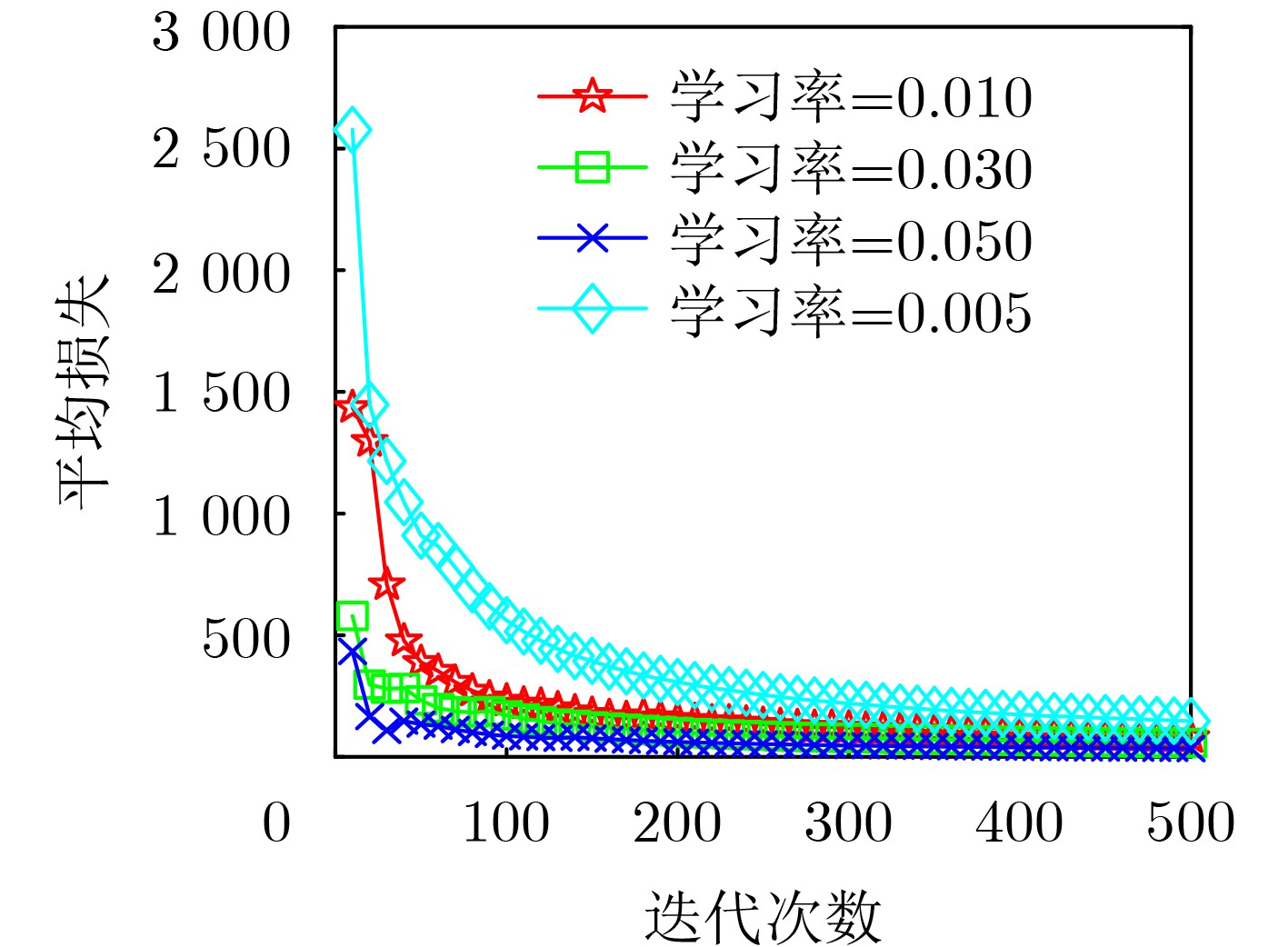
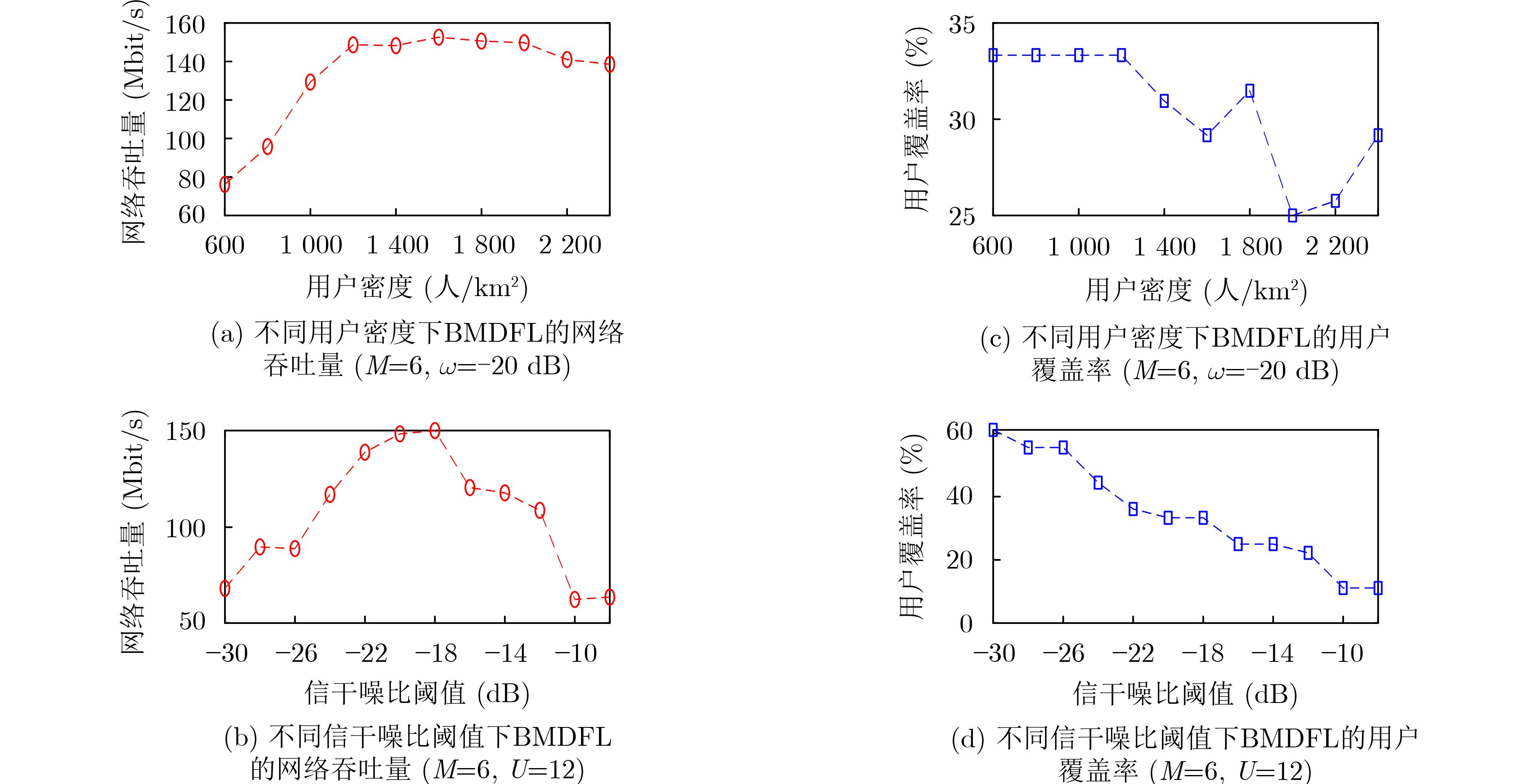
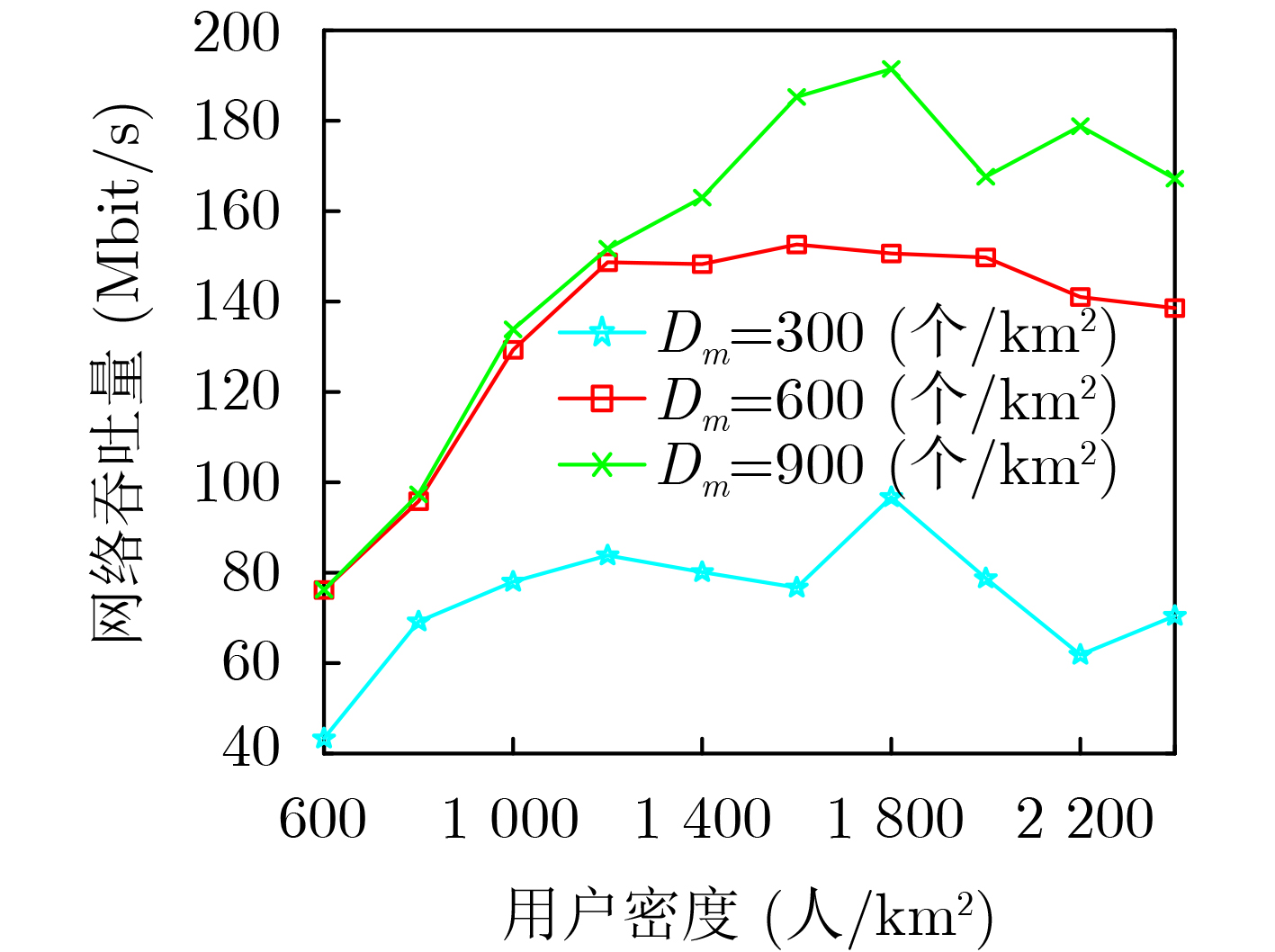
| Citation: | XUE Qing, LAI Dong, XU Yongjun, YAN Li. Beam Configuration for Millimeter Wave Communication Systems Based on Distributed Federated Learning[J]. Journal of Electronics & Information Technology, 2024, 46(1): 138-145. doi: 10.11999/JEIT221536

|

| [1] |
XU Yongjun, XIE Hao, WU Qingqing, et al. Robust max-min energy efficiency for RIS-aided HetNets with distortion noises[J]. IEEE Transactions on Communications, 2022, 70(2): 1457–1471. doi: 10.1109/TCOMM.2022.3141798
|
| [2] |
XUE Qing, FANG Xuming, XIAO Ming, et al. Beam management for millimeter-wave beamspace MU-MIMO systems[J]. IEEE Transactions on Communications, 2019, 67(1): 205–217. doi: 10.1109/TCOMM.2018.2867487
|
| [3] |
闫莉, 方旭明, 李毅, 等. 面向高铁毫米波通信智能资源管理研究综述[J]. 电子与信息学报, 2023, 45(8): 2806–2817.
YAN Li, FANG Xuming, LI Yi, et al. Overview on intelligent wireless resource management of millimeter wave communications under high-speed railway[J]. Journal of Electronics & Information Technology, 2023, 45(8): 2806–2817.
|
| [4] |
GIORDANI M, POLESE M, ROY A, et al. A tutorial on beam management for 3GPP NR at mmWave frequencies[J]. IEEE Communications Surveys & Tutorials, 2019, 21(1): 173–196. doi: 10.1109/COMST.2018.2869411
|
| [5] |
梁应敞, 谭俊杰, NIYATO D. 智能无线通信技术研究概况[J]. 通信学报, 2020, 41(7): 1–17. doi: 10.11959/j.issn.1000-436x.2020145
LIANG Yingchang, TAN Junjie, and NIYATO D. Overview on intelligent wireless communication technology[J]. Journal on Communications, 2020, 41(7): 1–17. doi: 10.11959/j.issn.1000-436x.2020145
|
| [6] |
XUE Qing, SUN Yao, WANG Jian, et al. User-centric association in ultra-dense mmWave networks via deep reinforcement learning[J]. IEEE Communications Letters, 2021, 25(11): 3594–3598. doi: 10.1109/LCOMM.2021.3108013
|
| [7] |
LI Lixin, REN Huan, CHENG Qianqian, et al. Millimeter-wave networking in the sky: A machine learning and mean field game approach for joint beamforming and beam-steering[J]. IEEE Transactions on Wireless Communications, 2020, 19(10): 6393–6408. doi: 10.1109/TWC.2020.3003284
|
| [8] |
ZHOU Yuhao, YE Qing, and LV Jiancheng. Communication-efficient federated learning with compensated overlap-FedAvg[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(1): 192–205. doi: 10.1109/TPDS.2021.3090331
|
| [9] |
XUE Qing, LIU Yijing, SUN Yao, et al. Beam management in ultra-dense mmWave network via federated reinforcement learning: An intelligent and secure approach[J]. IEEE Transactions on Cognitive Communications and Networking, 2023, 9(1): 185–197. doi: 10.1109/TCCN.2022.3215527
|
| [10] |
CHEN Mingzhe, POOR H V, SAAD W, et al. Wireless communications for collaborative federated learning[J]. IEEE Communications Magazine, 2020, 58(12): 48–54. doi: 10.1109/MCOM.001.2000397
|
| [11] |
KHAN L U, SAAD W, ZHU Han, et al. Dispersed federated learning: Vision, taxonomy, and future directions[J]. IEEE Wireless Communications, 2021, 28(5): 192–198. doi: 10.1109/MWC.011.2100003
|
| [12] |
LIAO Xiaomin, SHI Jia, LI Zan, et al. A model-driven deep reinforcement learning heuristic algorithm for resource allocation in ultra-dense cellular networks[J]. IEEE Transactions on Vehicular Technology, 2020, 69(1): 983–997. doi: 10.1109/TVT.2019.2954538
|
| [13] |
BUSARI S A, MUMTAZ S, HUQ K M S, et al. System-level performance evaluation for 5G mmWave cellular network[C]. GLOBECOM 2017 - 2017 IEEE Global Communications Conference, Singapore, 2017: 1–7.
|
Figures(7) / Tables(2)



 DownLoad:
DownLoad: