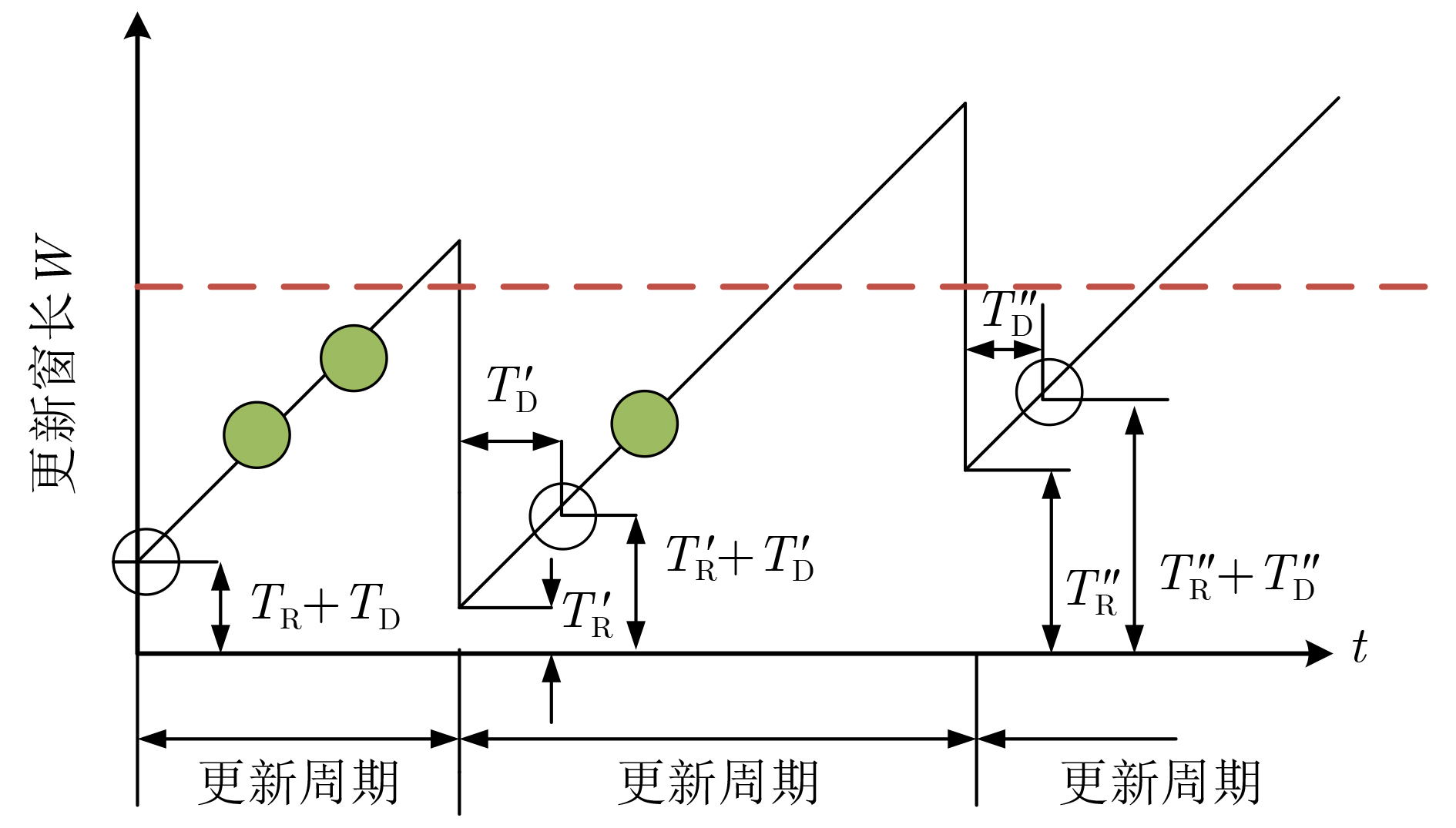
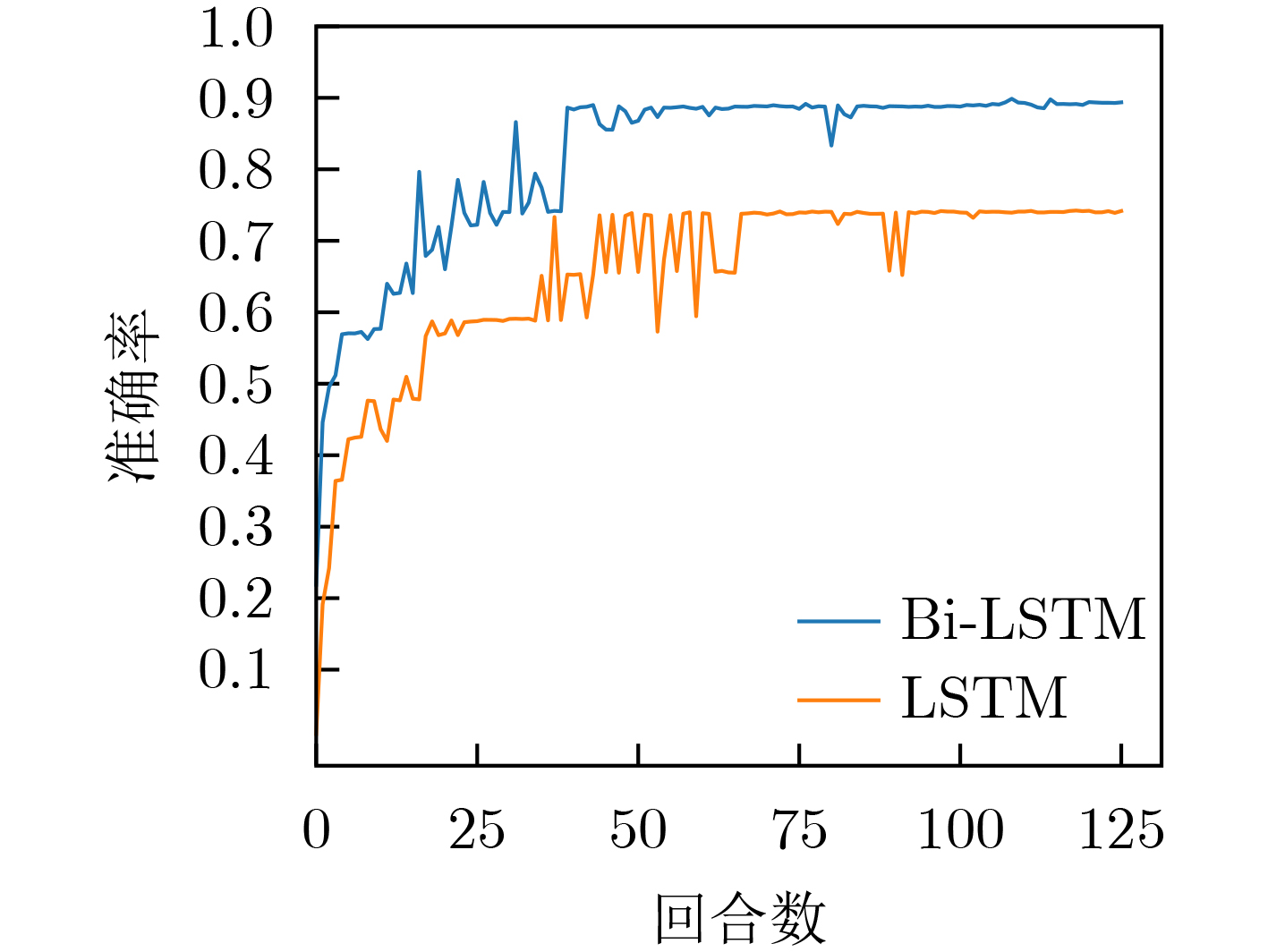
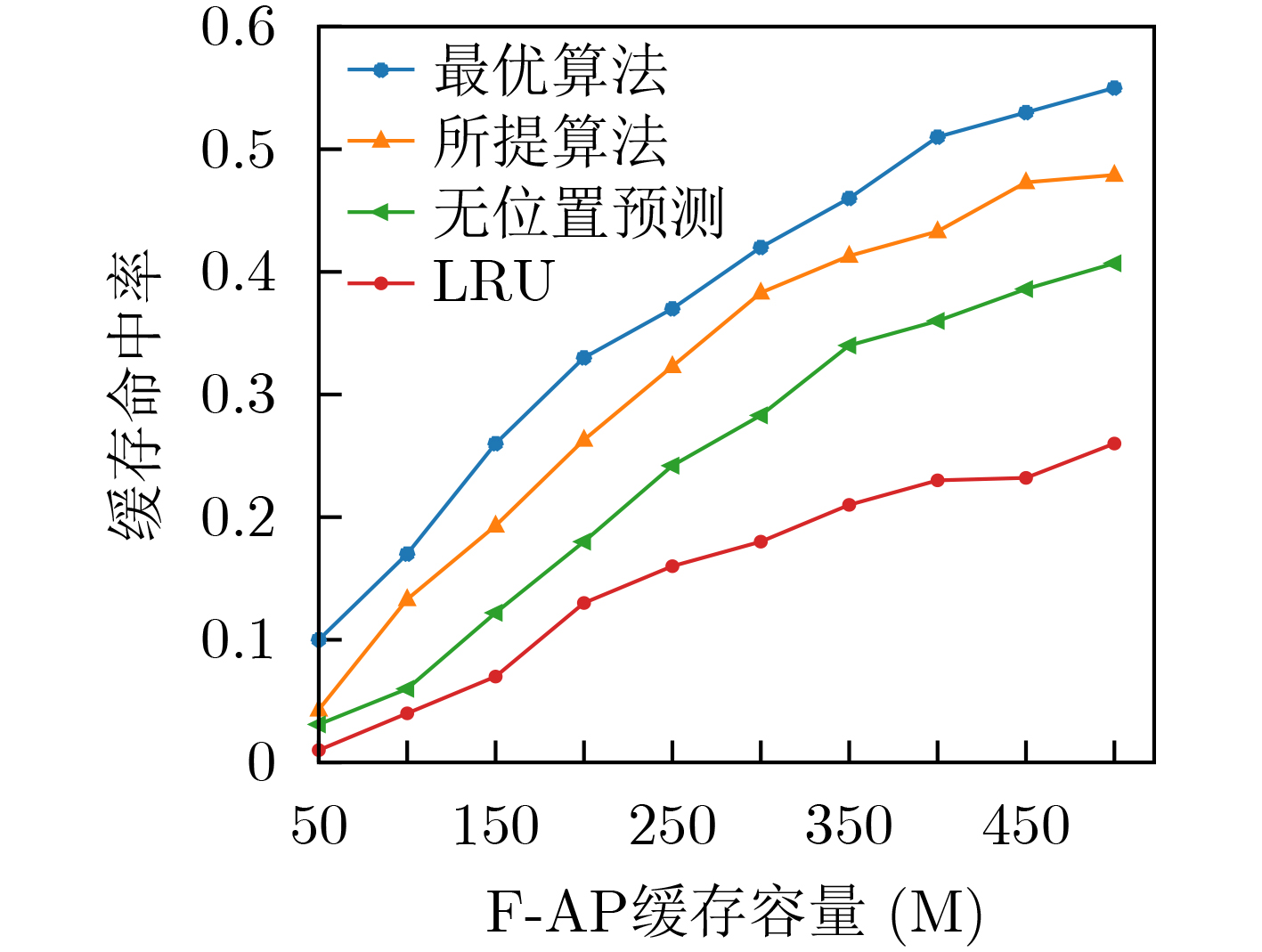
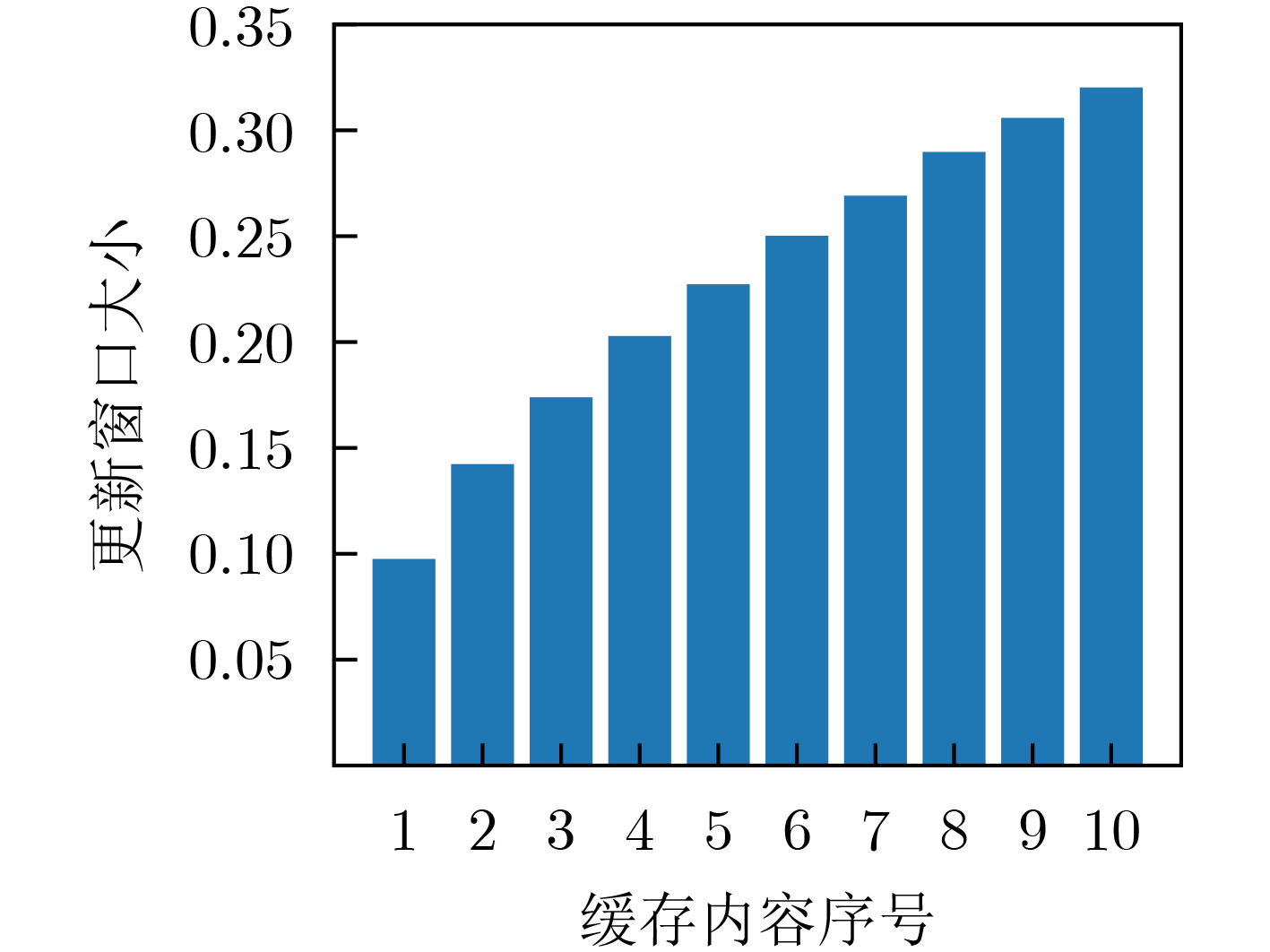
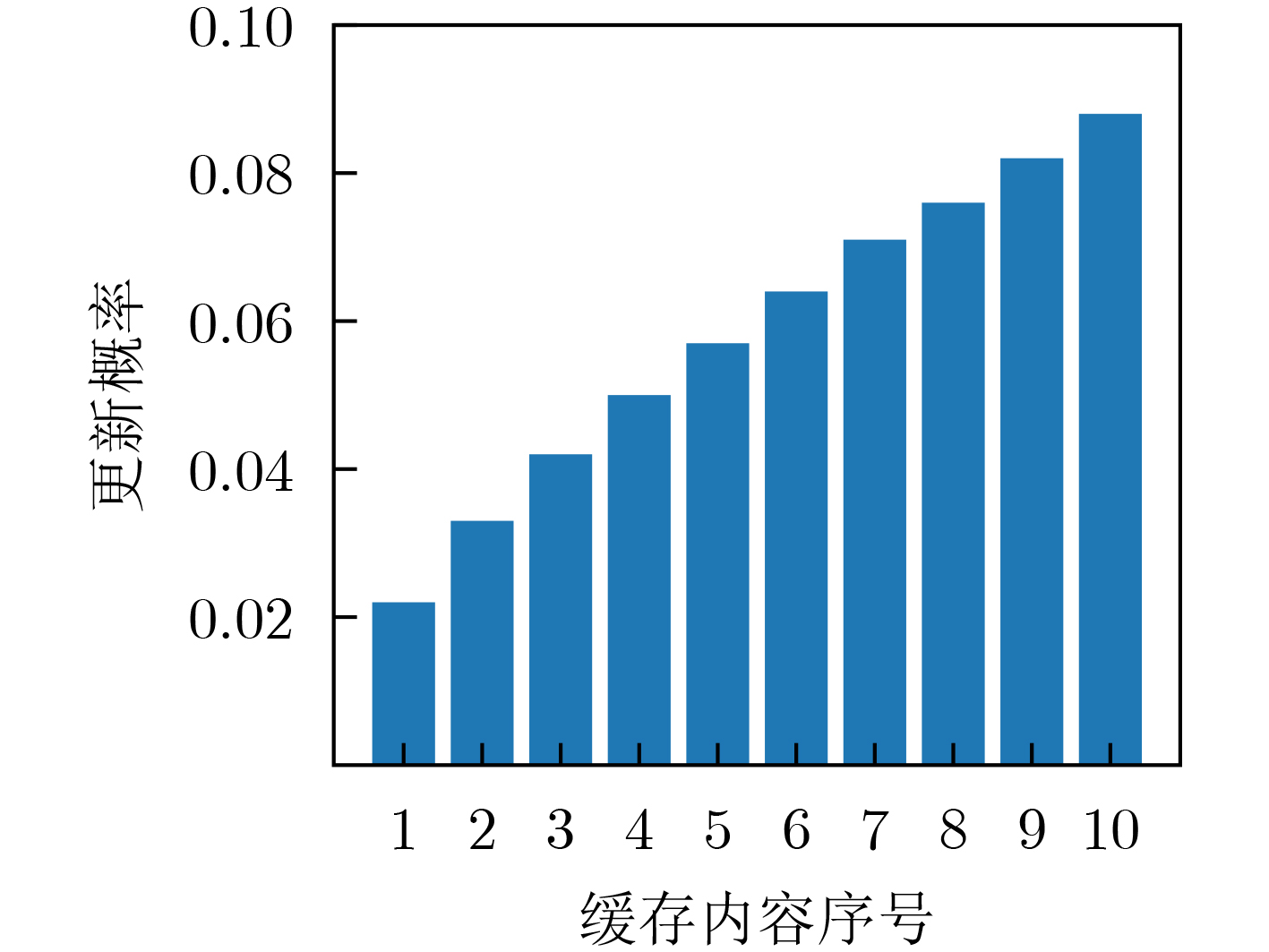
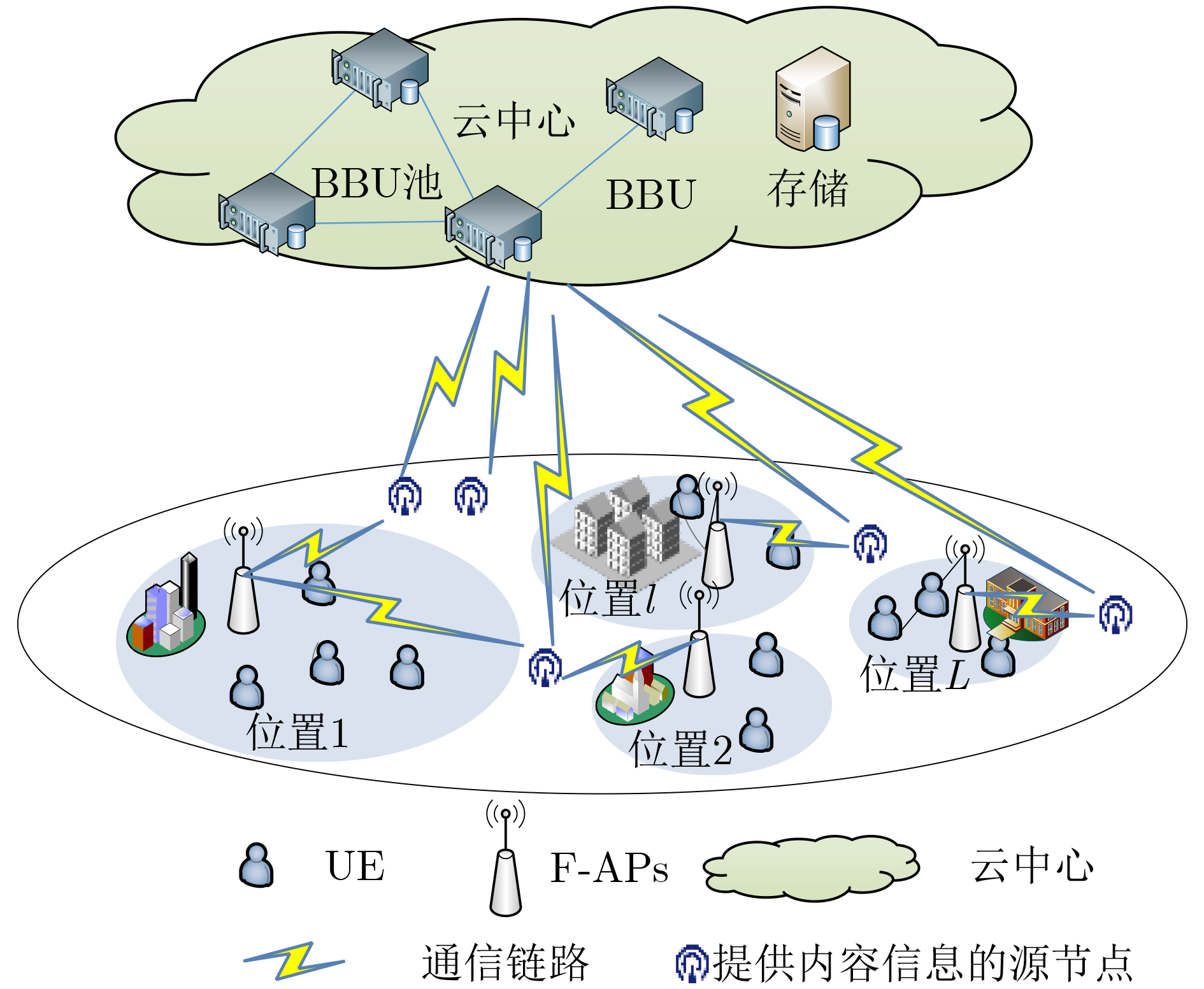
| Citation: | JIANG Fan, LIANG Xiao, SUN Changyin, WANG Junxuan. Caching and Update Strategy Based on Content Popularity and Information Freshness for Fog Radio Access Networks[J]. Journal of Electronics & Information Technology, 2022, 44(9): 3108-3116. doi: 10.11999/JEIT220373

|

| [1] |
ZENG Ming, LIN T H, CHEN Min, et al. Temporal-spatial mobile application usage understanding and popularity prediction for edge caching[J]. IEEE Wireless Communications, 2018, 25(3): 36–42. doi: 10.1109/MWC.2018.1700330
|
| [2] |
中华人民共和国工业和信息化部. 2021年通信业统计公报[R]. 2022.
Ministry of Industry and Information Technology. 2021 communications industry statistical bulletin[R]. 2022.
|
| [3] |
ZEYDAN E, BASTUG E, BENNIS M, et al. Big data caching for networking: Moving from cloud to edge[J]. IEEE Communications Magazine, 2016, 54(9): 36–42.
|
| [4] |
YATES R D, SUN Yin, BROWN D R, et al. Age of information: An introduction and survey[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(5): 1183–1210. doi: 10.1109/JSAC.2021.3065072
|
| [5] |
BASTOPCU M and ULUKUS S. Information freshness in cache updating systems[J]. IEEE Transactions on Wireless Communications, 2021, 20(3): 1861–1874. doi: 10.1109/TWC.2020.3037144
|
| [6] |
KAM C, KOMPELLA S, NGUYEN G D, et al. Information freshness and popularity in mobile caching[C]. 2017 IEEE International Symposium on Information Theory, Aachen, Germany, 2017: 136–140. doi: 10.1109/ISIT.2017.8006505.
|
| [7] |
WANG Xiaofei, CHEN Min, TALEB T, et al. Cache in the air: Exploiting content caching and delivery techniques for 5G systems[J]. IEEE Communications Magazine, 2014, 52(2): 131–139. doi: 10.1109/MCOM.2014.6736753
|
| [8] |
ZHANG Min, JIANG Yanxiang, ZHENG Fuchun, et al. Cooperative edge caching via federated deep reinforcement learning in fog-RANs[C]. 2021 IEEE International Conference on Communications Workshops, Montreal, Canada, 2021: 1–6. doi: 10.1109/ICCWorkshops50388.2021.9473609.
|
| [9] |
ZHANG Yuming, FENG Bohao, Quan Wei, et al. Cooperative edge caching: A multi-agent deep learning based approach[J]. IEEE Access, 2020, 8: 133212–133224. doi: 10.1109/ACCESS.2020.3010329
|
| [10] |
JIANG Yanxiang, FENG Haojie, ZHENG Fuchun, et al. Deep learning-based edge caching in fog radio access networks[J]. IEEE Transactions on Wireless Communications, 2020, 19(12): 8442–8454. doi: 10.1109/TWC.2020.3022907
|
| [11] |
GOODFELLOW L, BENGIO Y, and COURVILLE A. Deep Learning[M]. Cambridge: The MIT Press, 2016.
|
| [12] |
BARTLETT P L, HAZAN E, and RAKHLIN A. Adaptive online gradient descent[C]. The 20th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2007: 65–72.
|
| [13] |
JIANG Yanxiang, MA Miaoli, BENNIS M, et al. User preference learning-based edge caching for fog radio access network[J]. IEEE Transactions on Communications, 2019, 67(2): 1268–1283. doi: 10.1109/TCOMM.2018.2880482
|
| [14] |
JIANG Fan, ZHANG Xiaoli, and SUN Changyin. A D2D-enabled cooperative caching strategy for fog radio access networks[C]. The 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, London, UK, 2020: 1–6. doi: 10.1109/PIMRC48278.2020.9217190.
|
| [15] |
ANDREWS J G, BACCELLI F, and GANTI R K. A tractable approach to coverage and rate in cellular networks[J]. IEEE Transactions on Communications, 2011, 59(11): 3122–3134. doi: 10.1109/TCOMM.2011.100411.100541
|
| [16] |
ZHANG Shan, WANG Liudi, LUO Hongbin, et al. AoI-delay tradeoff in mobile edge caching with freshness-aware content refreshing[J]. IEEE Transactions on Wireless Communications, 2021, 20(8): 5329–5342. doi: 10.1109/TWC.2021.3067002
|
| [17] |
Stanford University. Stanford university mobile activity TRAces (SUMATRA)[EB/OL]. http://infolab.stanford.edu/pleiades/SUMATRA.html, 2022.
|
| [18] |
TRZCIŃSKI T and ROKITA P. Predicting popularity of online videos using support vector regression[J]. IEEE Transactions on Multimedia, 2017, 19(11): 2561–2570. doi: 10.1109/TMM.2017.2695439
|
Figures(9) / Tables(1)



 DownLoad:
DownLoad: