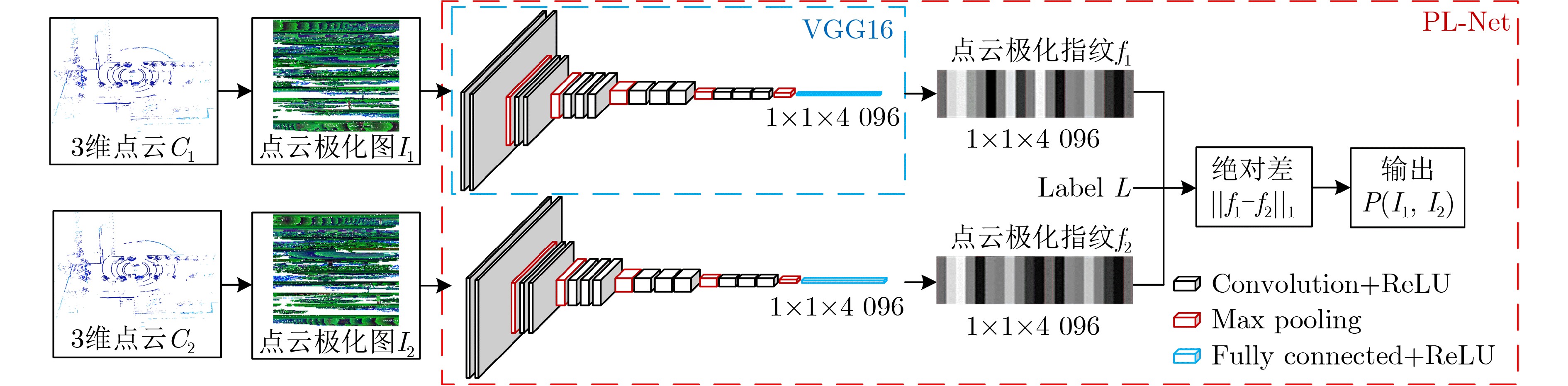
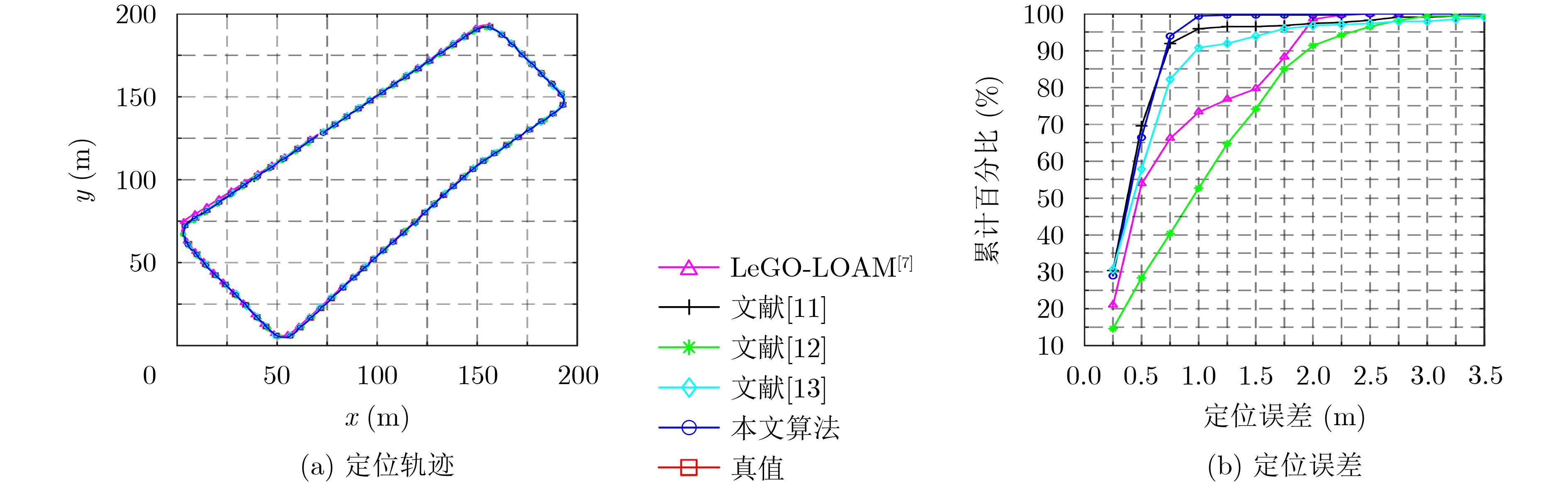
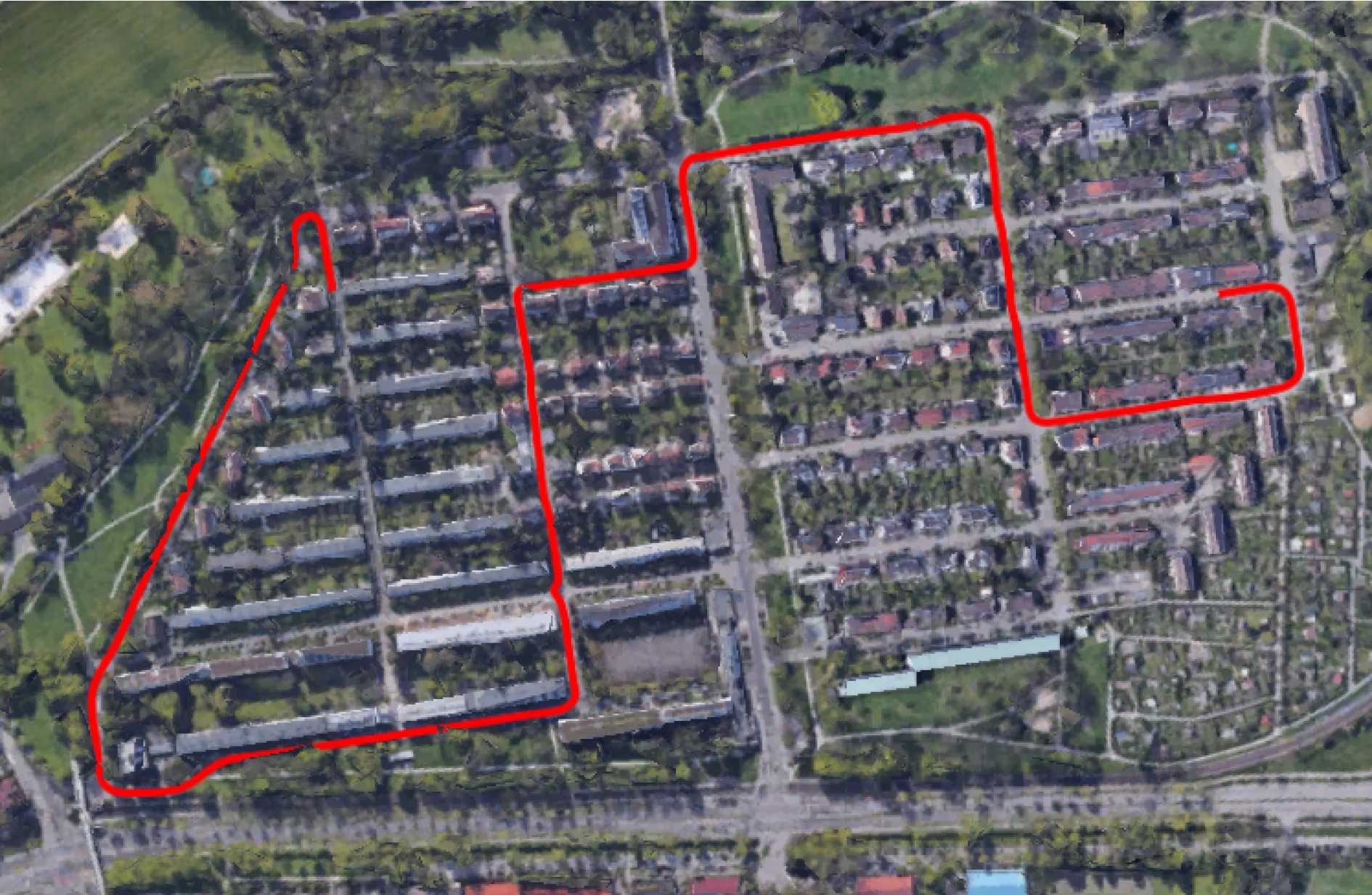
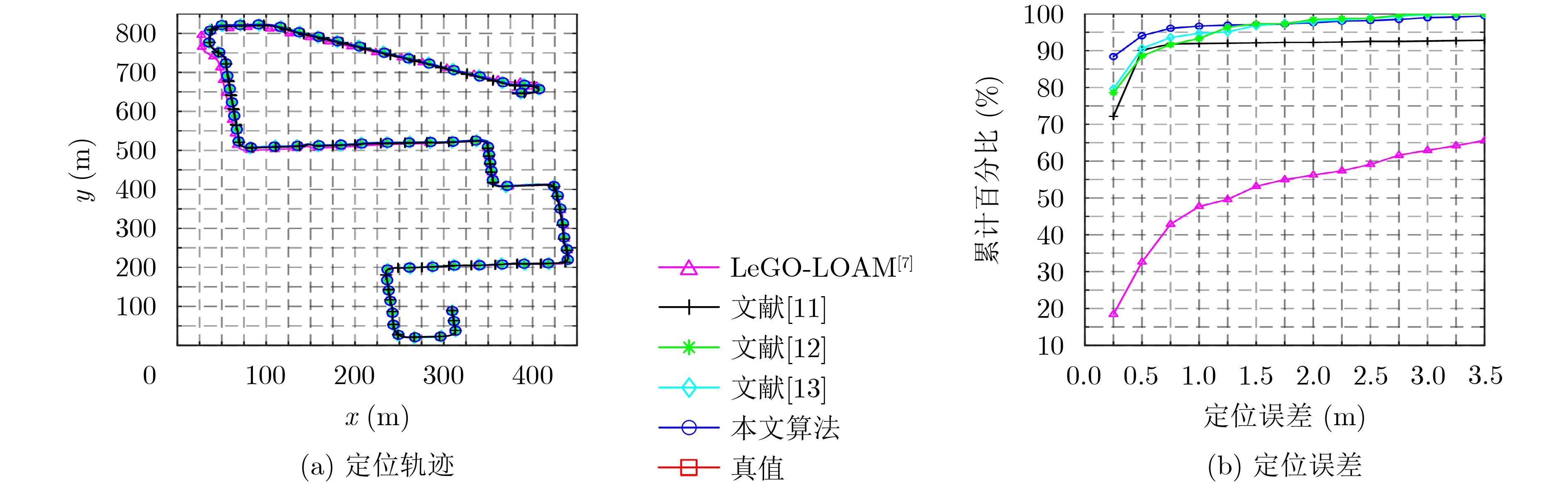
| Citation: | TAO Qianwen, HU Zhaozheng, WAN Jinjie, HU Huahua, ZHANG Ming. Intelligent Vehicle Localization Based on Polarized LiDAR Representation and Siamese Network[J]. Journal of Electronics & Information Technology, 2023, 45(4): 1163-1172. doi: 10.11999/JEIT220140

|

| [1] |
XIAO Zhu, CHEN Yanxun, ALAZAB M, et al. Trajectory data acquisition via private car positioning based on tightly-coupled GPS/OBD integration in urban environments[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(7): 9680–9691. doi: 10.1109/TITS.2021.3105550
|
| [2] |
中国科学技术协会. 中国科协发布2020重大科学问题和工程技术难题[EB/OL]. https://www.cast.org.cn/art/2020/8/16/art_90_130822.html, 2020.
|
| [3] |
GUO Xiansheng, ANSARI N, HU Fangzi, et al. A survey on fusion-based indoor positioning[J]. IEEE Communications Surveys & Tutorials, 2020, 22(1): 566–594. doi: 10.1109/COMST.2019.2951036
|
| [4] |
刘国忠, 胡钊政. 基于SURF和ORB全局特征的快速闭环检测[J]. 机器人, 2017, 39(1): 36–45. doi: 10.13973/j.cnki.robot.2017.0036
LIU Guozhong and HU Zhaozheng. Fast loop closure detection based on holistic features from SURF and ORB[J]. Robot, 2017, 39(1): 36–45. doi: 10.13973/j.cnki.robot.2017.0036
|
| [5] |
李祎承, 胡钊政, 王相龙, 等. 面向智能车定位的道路环境视觉地图构建[J]. 中国公路学报, 2018, 31(11): 138–146,213. doi: 10.3969/j.issn.1001-7372.2018.11.015
LI Yicheng, HU Zhaozheng, WANG Xianglong, et al. Construction of a visual map based on road scenarios for intelligent vehicle localization[J]. China Journal of Highway and Transport, 2018, 31(11): 138–146,213. doi: 10.3969/j.issn.1001-7372.2018.11.015
|
| [6] |
姚萌, 贾克斌, 萧允治. 基于单目视频和无监督学习的轻轨定位方法[J]. 电子与信息学报, 2018, 40(9): 2127–2134. doi: 10.11999/JEIT171017
YAO Meng, JIA Kebin, and SIU Wanchi. Learning-based localization with monocular camera for light-rail system[J]. Journal of Electronics &Information Technology, 2018, 40(9): 2127–2134. doi: 10.11999/JEIT171017
|
| [7] |
SHAN Tixiao and ENGLOT B. LeGO-LOAM: Lightweight and ground-optimized LiDAR odometry and mapping on variable terrain[C]. Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 2018: 4758–4765.
|
| [8] |
KOIDE K, MIURA J, and MENEGATTI E. A portable three-dimensional LiDAR-based system for long-term and wide-area people behavior measurement[J]. International Journal of Advanced Robotic Systems, 2019, 16(2): 72988141984153. doi: 10.1177/1729881419841532
|
| [9] |
WAN Guowei, YANG Xiaolong, CAI Renlan, et al. Robust and precise vehicle localization based on multi-sensor fusion in diverse city scenes[C]. Proceedings of 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 2018: 4670–4677.
|
| [10] |
胡钊政, 刘佳蕙, 黄刚, 等. 融合WiFi、激光雷达与地图的机器人室内定位[J]. 电子与信息学报, 2021, 43(8): 2308–2316. doi: 10.11999/JEIT200671
HU Zhaozheng, LIU Jiahui, HUANG Gang, et al. Integration of WiFi, laser, and map for robot indoor localization[J]. Journal of Electronics &Information Technology, 2021, 43(8): 2308–2316. doi: 10.11999/JEIT200671
|
| [11] |
YIN Huan, WANG Yue, DING Xiaqing, et al. 3D LiDAR-based global localization using Siamese neural network[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(4): 1380–1392. doi: 10.1109/TITS.2019.2905046
|
| [12] |
KIM G, CHOI S, and KIM A. Scan context++: Structural place recognition robust to rotation and lateral variations in urban environments[J]. IEEE Transactions on Robotics, 2022, 38(3): 1856–1874. doi: 10.1109/TRO.2021.3116424
|
| [13] |
CHEN Xieyuanli, LÄBE T, MILIOTO A, et al. OverlapNet: A siamese network for computing LiDAR scan similarity with applications to loop closing and localization[J]. Autonomous Robots, 2022, 46(1): 61–81. doi: 10.1007/s10514-021-09999-0
|
| [14] |
BROMLEY J, GUYON I, LECUN Y, et al. Signature verification using a “Siamese” time delay neural network[C]. Proceedings of the 6th International Conference on Neural Information Processing Systems (NIPS), Denver, USA, 1993: 737–744.
|
| [15] |
BAY H, ESS A, TUYTELAARS T, et al. Speeded–up robust features (SURF)[J]. Computer Vision and Image Understanding, 2008, 110(3): 346–359. doi: 10.1016/j.cviu.2007.09.014
|
| [16] |
FISCHLER M A and BOLLES R C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography[J]. Communications of the ACM, 1981, 24(6): 381–395. doi: 10.1145/358669.358692
|
| [17] |
SERVOS J and WASLANDER S L. Multi-channel generalized-ICP: A robust framework for multi-channel scan registration[J]. Robotics and Autonomous Systems, 2017, 87: 247–257. doi: 10.1016/j.robot.2016.10.016
|
| [18] |
GEIGER A, LENZ P, and URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]. Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, USA, 2012: 3354–3361.
|
Figures(11) / Tables(8)



 DownLoad:
DownLoad: