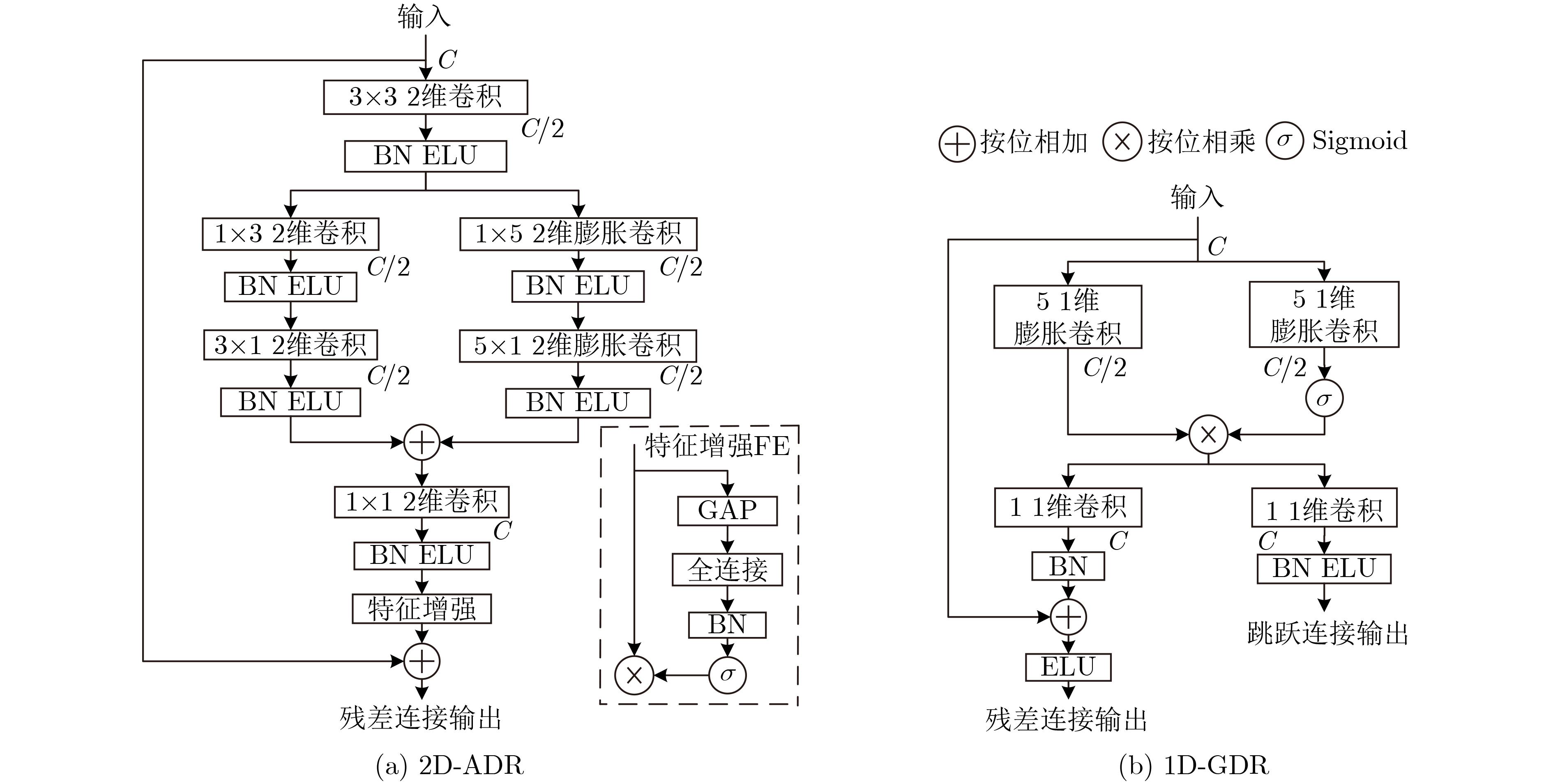
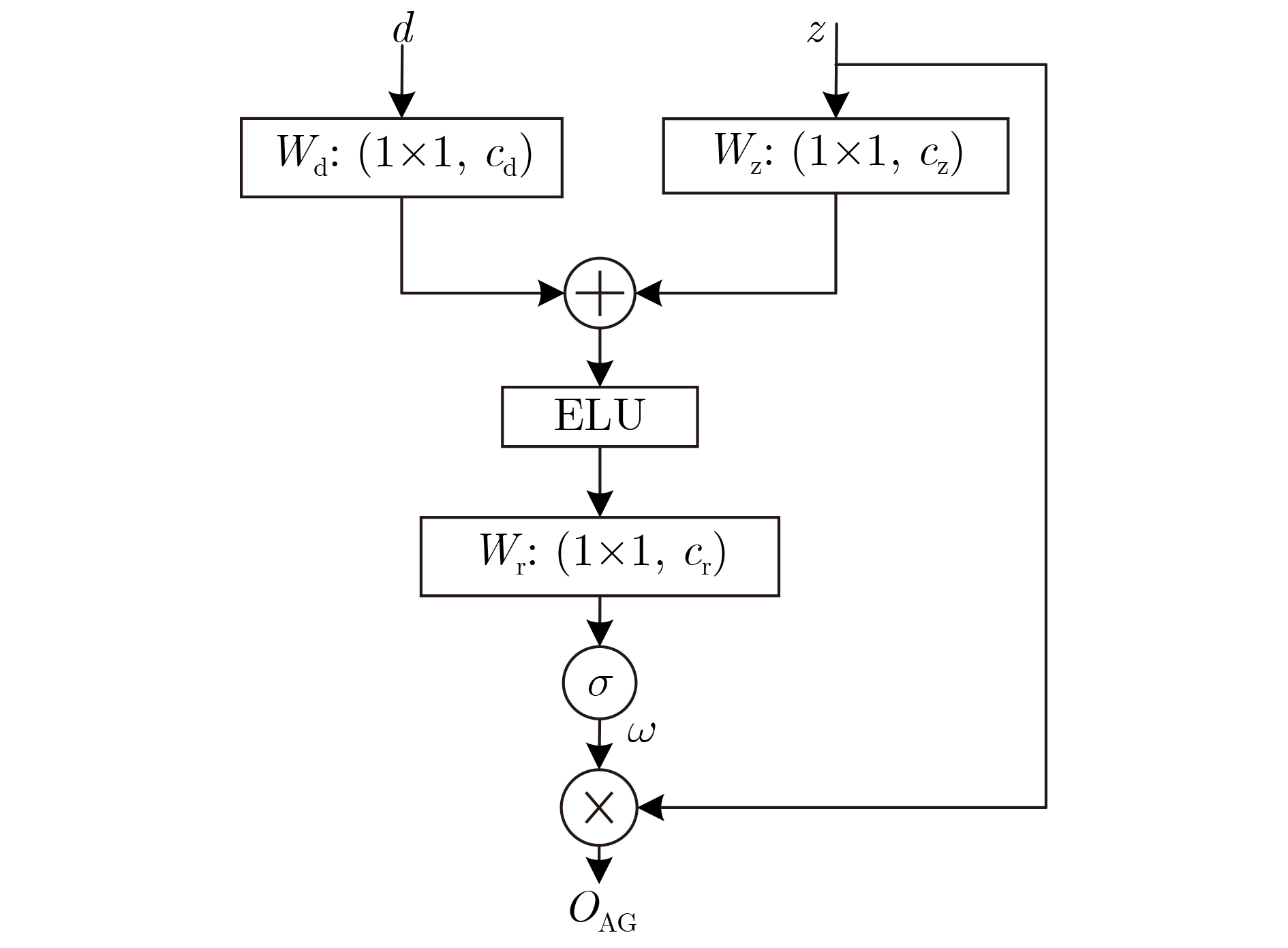
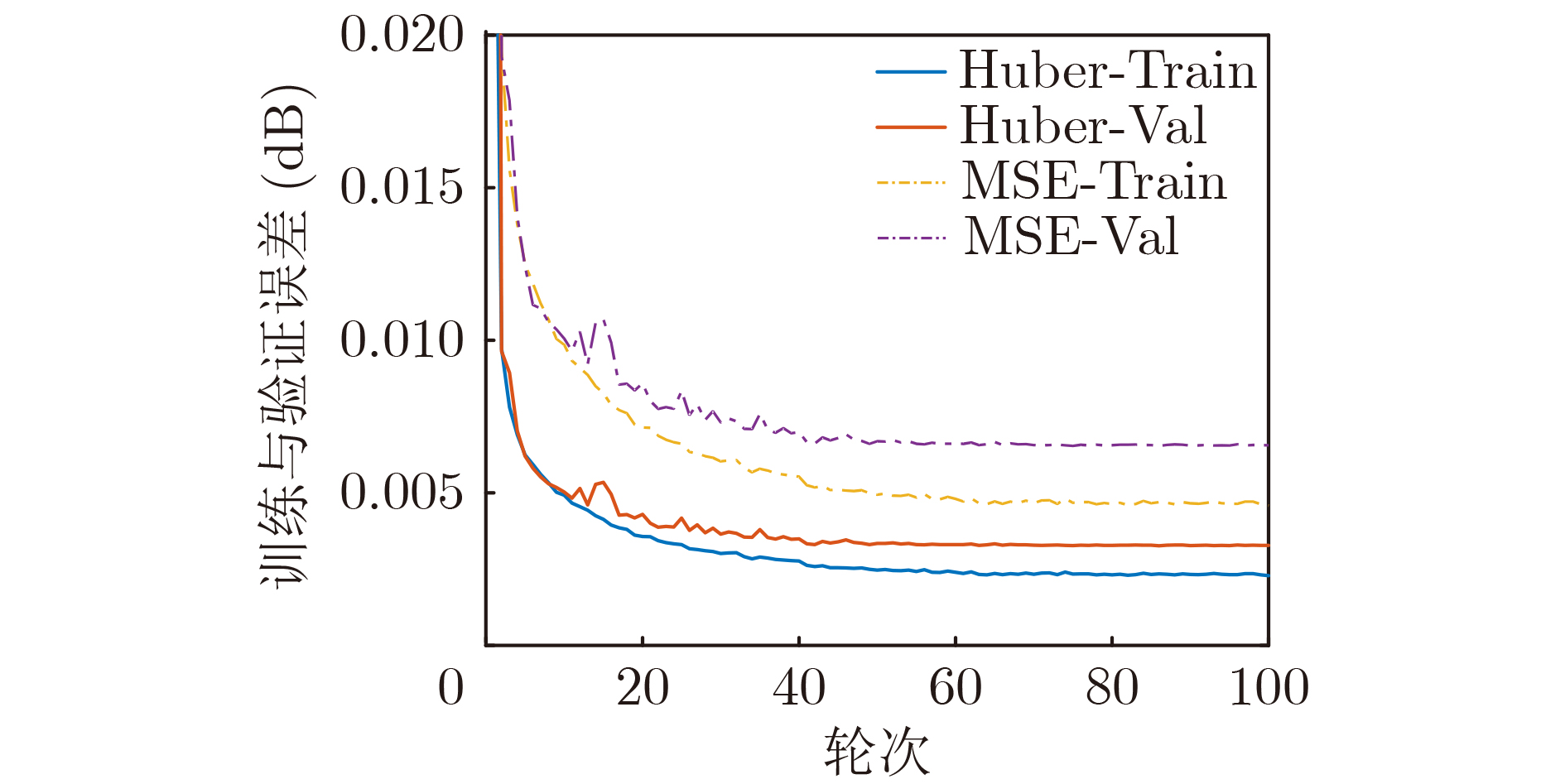
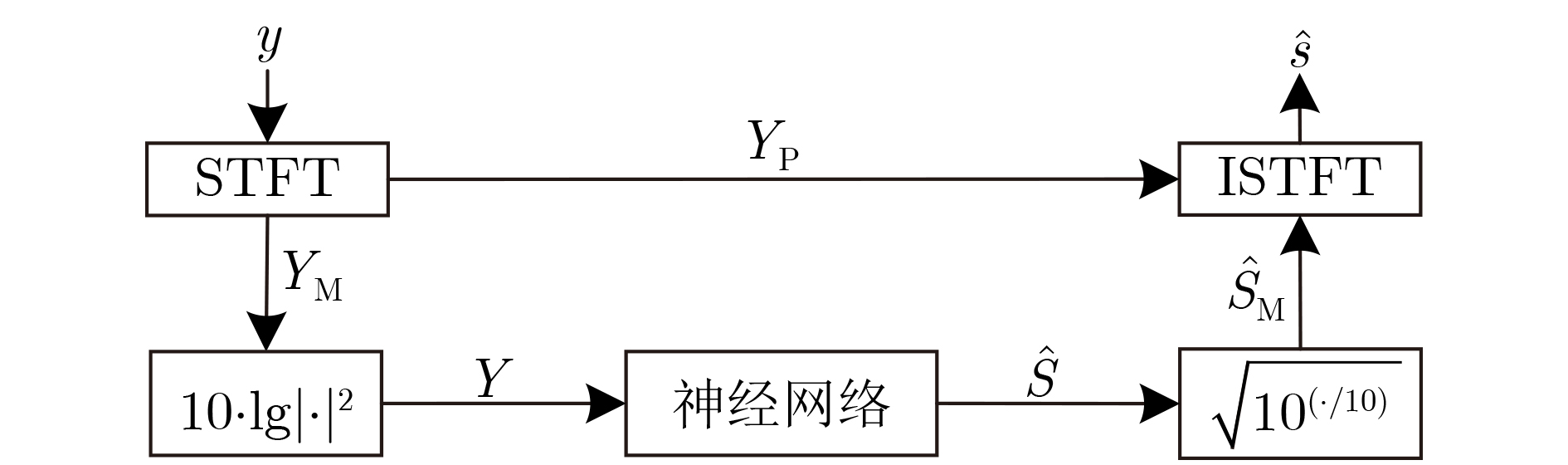
| Citation: | ZHANG Tianqi, BAI Haojun, YE Shaopeng, LIU Jianxing. Monaural Speech Enhancement Based on Attention-Gate Dilated Convolution Network[J]. Journal of Electronics & Information Technology, 2022, 44(9): 3277-3288. doi: 10.11999/JEIT210654

|

| [1] |
YELWANDE A, KANSAL S, and DIXIT A. Adaptive wiener filter for speech enhancement[C]. International Conference on Information, Communication, Instrumentation and Control, Indore, India, 2017: 1–4.
|
| [2] |
MIYAZAKI R, SARUWATARI H, INOUE T, et al. Musical-noise-free speech enhancement based on optimized iterative spectral subtraction[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(7): 2080–2094. doi: 10.1109/TASL.2012.2196513
|
| [3] |
HENDRIKS R C, HEUSDENS R, and JENSEN J. An MMSE estimator for speech enhancement under a combined stochastic–deterministic speech model[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(2): 406–415. doi: 10.1109/TASL.2006.881666
|
| [4] |
XU Yong, DU Jun, DAI Lirong, et al. An experimental study on speech enhancement based on deep neural networks[J]. IEEE Signal Processing Letters, 2014, 21(1): 65–68. doi: 10.1109/LSP.2013.2291240
|
| [5] |
WANG Qing, DU Jun, DAI Lirong, et al. Joint noise and mask aware training for DNN-based speech enhancement with SUB-band features[C]. 2017 Hands-free Speech Communications and Microphone Arrays, San Francisco, USA, 2017: 101–105.
|
| [6] |
SALEEM N, KHATTAK M I, AL-HASAN M, et al. On learning spectral masking for single channel speech enhancement using feedforward and recurrent neural networks[J]. IEEE Access, 2020, 8: 160581–160595. doi: 10.1109/ACCESS.2020.3021061
|
| [7] |
GERS F A, SCHMIDHUBER J, and CUMMINS F. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451–2471. doi: 10.1162/089976600300015015
|
| [8] |
LI Xiaoqi, LI Yaxing, DONG Yuanjie, et al. Bidirectional LSTM network with ordered neurons for speech enhancement[C]. Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 2020: 2702–2706.
|
| [9] |
YOUSEFI M and HANSEN J H L. Block-based high performance CNN architectures for frame-level overlapping speech detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 28–40. doi: 10.1109/TASLP.2020.3036237
|
| [10] |
CHOI H, PARK S, PARK J, et al. Multi-speaker emotional acoustic modeling for CNN-based speech synthesis[C]. 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 2019: 6950–6954.
|
| [11] |
PARK S R and LEE J W. A fully convolutional neural network for speech enhancement[C]. Proceedings of the Interspeech 2017, Stockholm, Sweden, 2017: 1993–1997.
|
| [12] |
TAN Ke and WANG Deliang. A convolutional recurrent neural network for real-time speech enhancement[C]. Proceedings of the Interspeech 2018, Hyderabad, India, 2018: 3229–3233.
|
| [13] |
TAN Ke, CHEN Jitong, and WANG Deliang. Gated residual networks with dilated convolutions for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(1): 189–198. doi: 10.1109/TASLP.2018.2876171
|
| [14] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778.
|
| [15] |
RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241.
|
| [16] |
DENG Feng, JIANG Tao, WANG Xiaorui, et al. NAAGN: Noise-aware attention-gated network for speech enhancement[C]. Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 2020: 2457–2461.
|
| [17] |
OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention U-Net: Learning where to look for the pancreas[J]. arXiv: 1804.03999, 2018.
|
| [18] |
WANG Yu, ZHOU Quan, LIU Jie, et al. Lednet: A lightweight encoder-decoder network for real-time semantic segmentation[C]. 2019 IEEE International Conference on Image Processing, Taipei, China, 2019: 1860–1864.
|
| [19] |
HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2261–2269.
|
| [20] |
SUBAKAN C, RAVANELLI M, CORNELL S, et al. Attention is all you need in speech separation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 21–25.
|
| [21] |
DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks[C]. Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 2017: 933–941.
|
| [22] |
HU Jie, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011–2023. doi: 10.1109/TPAMI.2019.2913372
|
| [23] |
KANEKO T, KAMEOKA H, TANAKA K, et al. Cyclegan-VC2: Improved cyclegan-based non-parallel voice conversion[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 2019: 6820–6824.
|
| [24] |
GAROFOLO J S, LAMEL L F, FISHER W M, et al. Darpa Timit acoustic-phonetic continuous speech corpus CD-ROM {TIMIT}[R]. NIST Interagency/Internal Report (NISTIR)-4930, 1993.
|
| [25] |
ITU-T. P. 862 Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs[S]. International Telecommunications Union (ITU-T) Recommendation, 2001: 862.
|
| [26] |
TAAL C H, HENDRIKS R C, HEUSDENS R, et al. An algorithm for intelligibility prediction of time–frequency weighted noisy speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(7): 2125–2136. doi: 10.1109/TASL.2011.2114881
|
Figures(9) / Tables(7)



 DownLoad:
DownLoad: