
| 算法1 Saber PKE解密算法 |
| 输入:私钥s∈B∗ |
| 密文c=(cm,b′)∈B* |
| 输出:解密消息m′∈B32 |
| (1) v=b′T(smodp)∈Rp |
| (2) m′=((v+h2−2εp−εTcm)modp)>>(εp−1)∈R2 |
| (3) 返回m′ |
| Citation: | Deng Zi-li, Hao Gang. Self-tuning Distributed Measurement Fusion Kalman Filter[J]. Journal of Electronics & Information Technology, 2007, 29(8): 1850-1854. doi: 10.3724/SP.J.1146.2005.01471

|
为应对量子计算对传统公钥密码算法的威胁,全球的密码学者都在积极开展后量子密码算法(Post-Quantum Cryptography, PQC)的研究。2016年12月,美国国家标准与技术研究院(National Institute of Standards and Technology, NIST)启动了全球范围内的后量子公钥密码标准化项目,而基于格的后量子密码以其具有线性计算复杂度、扩展性较好和功能设计多样化等优势,被认为是最有力的竞争者[1]。征集的后量子密码在算法安全性和性能上都有一定的要求,其中特别强调了算法在具体实现和应用时的物理安全性,即抗侧信道攻击能力。
侧信道攻击首先由Kocher等人[2]提出,其中能量分析攻击以其攻击时间成本低、攻击原理简单、攻击成功率高等特点在该领域中得到广泛应用。能量分析攻击主要利用密码设备在运行时产生的能量泄露如功耗、电磁辐射等信息,并结合一定的分析手段来获取秘密信息[3]。随着后量子密码算法标准化的到来,迫切需要研究算法实现过程中的能量分析攻击和防护技术。
近年来,针对格密码的侧信道攻击分为两个方向:一是获取长期使用的私钥,二是恢复加密过程中的秘密消息与共享密钥。在第1个方向中,Primas等人[4]和Pessl等人[5]将攻击点选为数论变换(Number Theoretic Transforms, NTT),而Ravi等人[6]将攻击点选在纠错码和FO(Fujisaki-Okamoto)变换上;Aydin等人[7]利用横向攻击对Frodo算法软硬件实现中的矩阵乘法进行攻击;Xu等人[8]使用精心构建的密文对Kyber算法实施自适应电磁攻击,实现完全的密钥提取;在第2个方向中,Ravi等人[9]利用电磁泄露并结合聚类算法对1阶掩码保护的NewHope512算法进行攻击;Amiet等人[10]针对NewHope算法提出单能量轨迹消息恢复方法;Sim等人[11]提出一种基于机器学习的攻击方法,对部分格密码的编码过程进行攻击;Ngo等人[12,13]利用深度学习技术对融合掩码与洗牌技术的Saber算法进行安全性分析。
本文针对格密码解封装过程中的解码操作提出一种秘密消息恢复方法。主要完成以下4方面内容:
(1)深入分析文献[9]提出的单比特存储泄露,利用归一化类间方差(Normalized Inter-Class Variance, NICV)方法对目标字节中间值的汉明重量进行分类,减少预处理过程所需的能量迹;
(2)识别格密码中存在的密文循环特性,并利用该特性构造特定密文,使得攻击的比特宽度与之前的攻击中的比特宽度不同,减少攻击过程所需的能量迹;
(3)以Saber算法为例在ChipWhisperer平台验证适用性和有效性,证明所提模板攻击方法可以极大地减少预处理和攻击过程所需能量迹,并大幅提升攻击的成功率;
(4)对本文方法的扩展性进行简要定性分析。
Rq=Zq/φ(x)表示模多项式φ(x)的多项式环,在本文中φ(x)=xn+1为不可约多项式。Bk表示长度为k的字节数组,对于m∈Bk,第i个字节用m[i]表示,m[i, j]表示m的第i个字节在第j个循环结束后的中间值结果,mi表示m的第i个比特,m[i]j表示m[i]的第j个比特。
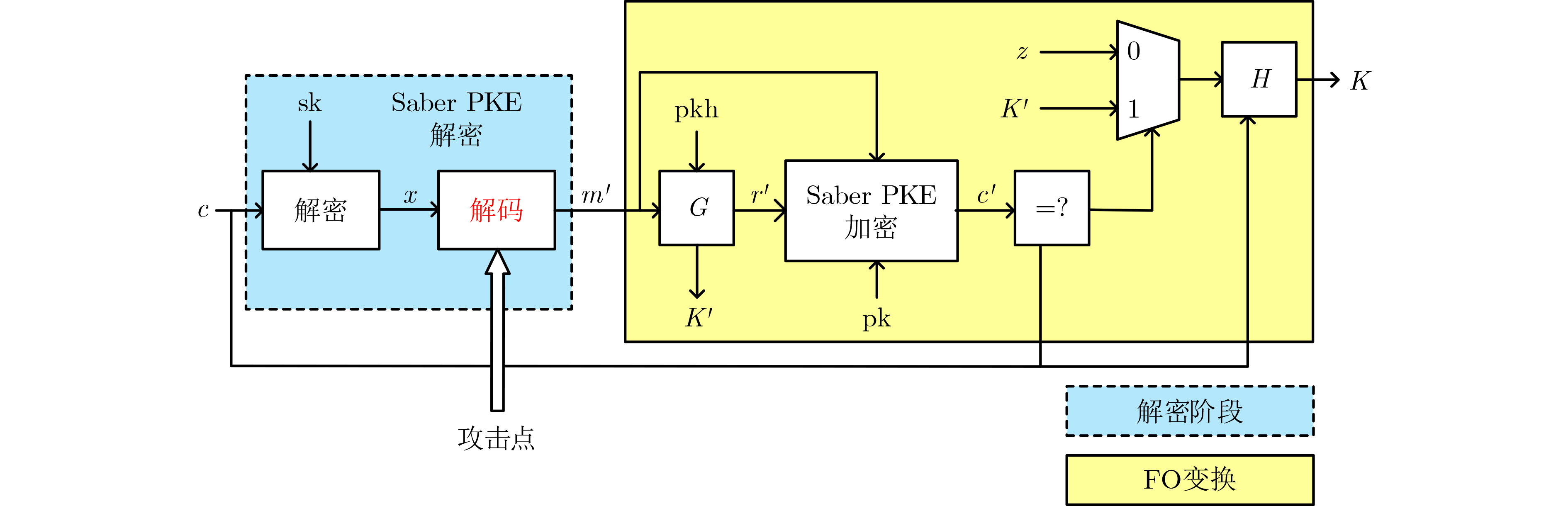
Saber算法[14]的安全性是基于模上舍入学习(Module-Learning With Rounding, M-LWR)困难问题,该问题是带错误学习(Learning With Errors, LWE)问题的一种变体。Saber算法以2的次幂作为模数,使用模块结构并通过舍入引入误差[15],使得Saber算法有更高的加密效率。Saber算法包括满足选择明文攻击下不可区分性(INDistinguishability under Chosen-Plaintext Attack, IND-CPA)的公钥加密算法(Public Key Encryption, PKE)和选择密文攻击下的不可区分性(INDistinguishability under Chosen-Ciphertext Attack, IND-CCA)的密钥封装机制(Key Encapsulation Mechanism, KEM)。由于Saber PKE在选择密文攻击下是不安全的,因此Saber KEM在Saber PKE的基础上,利用FO变换对解密出的消息进行重加密,并比对重加密密文c′和接收到的密文c,从而识别计算过程中是否存在选择密文攻击。算法1和算法2分别描述了Saber PKE解密算法和Saber KEM解封装算法,更多Saber算法的相关说明可参考文献[14]。
| 算法1 Saber PKE解密算法 |
| 输入:私钥s∈B∗ |
| 密文c=(cm,b′)∈B* |
| 输出:解密消息m′∈B32 |
| (1) v=b′T(smodp)∈Rp |
| (2) m′=((v+h2−2εp−εTcm)modp)>>(εp−1)∈R2 |
| (3) 返回m′ |
| 算法2 Saber KEM解封装算法 |
| 输入:私钥skKEM=(z,pkh,pk,s)∈B* |
| 密文c∈B* |
| 输出:共享密钥K∈B32 |
| (1) m′=SaberPKE.Dec(s,c) |
| (2) (K′,r′)=G(pkh,m′) |
| (3) c′=SaberPKE.Enc(pk,m′;r′) |
| (4) 若 c=c′ 则返回K=KDF(K′||H(c)) |
| (5) 否则返回K=KDF(z||H(c)) |
测试向量泄露评估(Test Vector Leakage Assessment, TVLA)是一种基于一致性的评估方法[16],通过假设检验来判断加密过程中的能量消耗是否存在显著性差异,其中Welch t检验评估方法[17]是使用最广泛、研究方案最完善的假设检验工具。假设两组能量测量值分别为Tr和Tf ,则这两组能量测量值之间的TVLA值可以表示为
| TVLA = Xr−Xf√σ2rNr + σ2fNf | (1) |
其中,Xr, σr和Nr分别代表测试集Tr的均值、标准差和基数,对Tf同理。Welch t检验通常将拒绝零假设的阈值设为4.5,当且仅当t检验结果的绝对值大于4.5时,才能以99.999 9%的置信度拒绝零假设,表示两组测量值之间存在明显差异,可能会导致秘密信息的泄露。
NICV[18]是一种单变量方差分析F检验,是以类别为条件的泄露均值方差与总泄露方差之间的比率。NICV与TVLA都可用作侧信道评估指标,但TVLA通常用于区分两个不同的类别,而NICV可以同时区分两个或以上的类别。假设C(X)为给变量X的类别,若测量到X的泄露表示为T,则以式(2)计算NICV
| NICV = Var[E[T|C(X)]]Var[T] | (2) |
其中,E[·]表示单变量均值,Var[·]表示标准差。虽然NICV没有确切的阈值,但是给定点的NICV值越大,每个类之间的泄露差异就越显著。
能量分析的攻击点通常选择与明文或者密钥有直接联系的关键操作。Ravi等人[9]提出了增量存储漏洞,称为Single_Bit_Update,该漏洞利用存储单比特信息时产生的泄露实现完整的秘密消息恢复。Saber算法的解封装过程如图1所示,图1的解码操作用于实现消息的多项式形式向字节形式的转换,其中存在Single_Bit_Update,下面进行简要分析。
Saber算法利用POLmsg2BS函数实现消息的解码过程,C代码片段可以参考算法3[19]。POLmsg2BS函数将一个具有256个系数的给定多项式a转换为消息数组m∈B32。该函数分为两个循环,外循环是以字节为单位进行运算,而内循环则是对目标字节按位进行运算。首先在外循环中将消息字节m[j]初始化为0 (见第(4)行),随后在内循环中将多项式a的每个系数a [8×j + i]通过计算转化为中间值t (a即为算法3中的data,见第(6)行),通过移位和按位或操作将t更新为m[j]i (其中i∈[0,7],见第(7)行),m[j]i的更新共重复256次。通过分析可以发现,对于m的每个消息比特mi,都只与多项式a的一个系数a[i]有关,因此秘密消息m从固定值0开始每次迭代更新1位。在相邻的两次迭代中,消息m只存在1 bit差异,这种处理消息单个比特的方式成为侧信道攻击的有效目标。
| 算法3 Saber POLmsg2BS |
| (1) void POLmsg2BS(uint8_t bytes[SABER_KEYBYTES], const poly *data) { |
| (2) size_t t, i, j; |
| (3) for (j = 0; j < SABER_KEYBYTES; j++) { |
| (4) bytes[j] = 0; |
| (5) for (i = 0; i < 8; i++) { |
| (6) t = (data->coeffs[j × 8 + i] & 0x01); |
| (7) bytes[j] |= t << i; |
| (8) } |
| (9) } |
| (10) } |
使用ARM工具链(arm-none-eabi-gcc)对上述C语言代码进行编译生成汇编,对应的汇编代码片段如图2所示。在经过按位与和移位操作后,寄存器r3中存储的值t通过strb指令存入地址为(fp-24)的内存单元中(见第(14)行),每一个消息字节m[j]在经过8次迭代后即可实现字节的完全转换。存储指令(strb)在执行过程中会产生能量消耗,这些能量消耗与存储中间值的汉明重量之间有一定关系,通过分析两次相邻迭代之间的中间值的汉明重量关系,可以推断出中间值,从而还原关键的秘密消息。
依据第3节对Single_Bit_Update的分析,消息字节m[i]在8次迭代后完成全部更新,且每个消息字节都是以相同的方式进行更新的,因此考虑以字节为单位进行秘密消息恢复。本节将介绍基于模板与密文循环特性的消息恢复方法并分析其实现可能性。
预处理阶段包括泄露检测和模板构建两个部分,通过对包含不同消息的密文进行解封装运算并采集相应的能量曲线,利用TVLA检测泄露并构建泄露点集合,利用NICV对不同消息中间值的汉明重量进行分类,从而针对消息的汉明重量分类建立相应的简化模板。
以第1个消息字节m[0]的泄露为例,并使用Welch t检验实现泄露检测。首先构建两组各包含l个随机密文的密文集CT0和CT1,其中CT0的第1个消息字节m[0] = 0,其余消息字节m[i]随机选择,CT1的第1个消息字节m[0] = 1,其余消息字节m[i]随机选择,i∈[1,31]。这保证了在解码过程中,对于∀j∈[0,7],CT0都有m[0, j]=0,而CT1则满足m[0, j]=1。这使得在8个中间值更新的循环中,始终有1 bit差别,而这个差别可以测量出来。泄露检测的具体过程为:
(1) 采集能量曲线。针对CT0和CT1,各采集了两组l条能量曲线,分别表示为T0和T1,并令T = T0∪T1;
(2) 能量曲线归一化。通过移除测量集中每条曲线ti自身的均值¯ti来减少环境因素的影响,即t′i=ti−¯ti,其中ti∈Tj, i∈[1, l–1], j∈{0,1};
(3) 识别测量集中的泄露点。利用式(1)计算两组测量集的TVLA值,当TVLA绝对值大于阈值Thsel时,代表在该点两组测量集有明显差异;
(4) 识别泄露窗口。根据计算出的TVLA值和m[0]的更新存储顺序可以区分每次泄露的时间窗口,记为Wj,其中j∈[0,7]。
基于第3节对Single_Bit_Update泄露机理的分析,本文采用汉明重量模型,以HW(m[i, j])为分类标准构建模板,通过恢复m[i, j]的汉明重量来推导出m[i]的值。由于m[i]在最开始被初始化为0,因此对于m[i]的第1个中间值m[i,0]有HW(m[i, 0]) = m[i]0,继而m[i]的其他比特m[i]j可以由式(3)的关系推导出来
| m[i]j={0, HW(m[i, j]) = HW(m[i, j−1])1, HW(m[i, j]) = HW(m[i, j−1]+1) | (3) |
当j = 0时,m[i, j]只可能为0或1,因此HW(m[i, 0])也只有两个可能值(0或1)。而在之后的每次迭代中,HW(m[i, j])的可能值数目随迭代次数增加1,在最后一次迭代中(j = 7),HW(m[i, j])有9个可能值,即HW(m[i, j])∈[0,8]。因此在每次迭代中,HW(m[i, j])有(j + 2)个可能值。
以HW(m[0, j])为例说明模板构建过程,其中j∈[0,7],具体步骤如下:
(1) 选择m[0]满足HW(m[0, j]) = k的密文集CTk(0,j)进行解封装操作,其中k∈[0, j+1]。这些密文集除m[0]外的其余字节均为随机选择,并采集能量曲线表示为Tk(0,j);
(2) 利用NICV区分不同的HW(m[0, j]),并选择泄露点。利用式(2)对Tk(0,j)计算NICV,并选择时间窗口Wj中NICV值大于阈值的点为泄露点P(0, j);
(3) 根据P(0, j)构建简化曲线集Tk′(0,j),计算Tk′(0,j)的平均值记为rtk(0,j),该平均值即为每一个分类的简化模板,因此在第j次迭代时会产生(j + 2)个模板。
首先利用密文循环特性构造特定的密文ct′,采集ct′的解封装能量曲线,并利用这些能量曲线与预处理阶段建立的模板进行匹配。这些特定密文虽然是无效的,即无法通过最后的多项式比较,但依旧会在设备上进行解封操作,给能量分析攻击创造了可能性。
大多数格基后量子密码算法都是基于LWE问题及其变体构造的。如Round5算法及其变体是在循环多项式Rq=Zq/(xn+1−1)上运算的,其中(xn+1−1)是可约多项式,因此对于这一类算法而言,多项式a∈Rq与环上多项式gp(x)=xp相乘满足:ap[i]=Rotr(a, p)[i],表示a的第i个系数循环旋转p个位置,其中Rotr(·)的定义如式(4)所示
| Rotr(a, p)[i]={a[n−p+i], 0≤i < pa[i−p], p≤i≤n−1 | (4) |
而Kyber, Saber等算法是在反循环多项式环Rq=Zq/(xn+1)上运算的,其中(xn+1)是不可约多项式,因此a∈Rq与gp(x)=xp的乘积为ap[i]=Anti_Rotr(a, p)[i],表示a的第i个系数以反循环的方式旋转p个位置,其中Anti_Rotr(·)的定义为
| Anti_Rotr(a, p)[i]={−a[n−p+i], 0≤i < pa[i−p], p≤i≤n−1 | (5) |
通过分析Saber的POLmsg2BS函数(见算法3)可以发现,秘密消息mi只与秘密消息多项式系数a[i]有关。多项式a是在解密阶段由密文c和私钥s运算产生的,而密文c由多项式向量b′和多项式cm级联而成。由于Saber算法是以2的次幂为模数,因此所有的模约操作均可通过简单的移位来实现。对m0的解码操作可具体表示为
| m0=F(a[0])=F(v[0] + h2−2εP−εT⋅cm[0])=F(b′[0]⋅s + h2−2εP−εT⋅cm[0]) | (6) |
其中,F(·)表示算法实现过程中的解码操作。因此可以构造密文ci=(cmi,b′i),其中cmi=Anti_Rotr(cm,i), b′i=Anti_Rotr(b′,i)。由此可以计算出利用反循环特性之后的m′0为
| m′0=F(ai[0])=F(vi[0]+h2−2εP−εT⋅cmi[0])=F(b′i[0]⋅s+h2−2εP−εT⋅cmi[0])=F(−b′[k]⋅s+h2+2εP−εT⋅cm[k])=F(−v[k]+h2+2εP−εT⋅cm[k])=F(a[k])=mk | (7) |
其中,k = (n – i) mod n。h2是一个常数多项式,用于实现运算舍入,每次运算中都会进行模约,从而保证每次运算后的系数均为正整数。因此在密文构建过程中,只需改变i即可完成密文的循环移位。
由于本文是对秘密消息的汉明重量可能值构建模板,因此在模板匹配阶段并不需要使用与预处理阶段相同的公私钥对。结合4.2.1节的密文循环特性构造密文,并利用4.1节构建的模板对秘密消息进行恢复,具体过程如下:
(1) 对于j∈[0,7],对给定密文ct进行解封装,并采集对应能量曲线tr,根据模板构建过程完成对tr的归一化,并根据P(0, j)建立简化曲线tr′j;
(2) 计算tr′j与各分类简化模板rtk(0,j)之间差值的平方和(Sum Of Squared Difference, SOSD),记为Γk
| Γk=(trj′−rtk(0,j))×(tr′j−rtk(0,j))T | (8) |
根据Γk的大小判断HW(m[0, j]),当Γk最小时,tr′j对应的分类即为HW(m[0, j]) = k,并根据式(3)推导出mj;
(3) 利用密文循环特性对给定的有效密文ct进行密文构造,得到不同的构造密文cti (i∈[1,31])。重复步骤(1)和步骤(2),得到HW(m[i, j])并推导出m[i]。
本文提出的秘密消息恢复方法完整过程如算法4所示,其中Recover(·)利用式(3)判断消息比特的值。在恢复秘密消息后,即可通过Saber KEM封装算法恢复共享密钥。
| 算法4 针对Saber算法的消息恢复方法 |
| 预处理阶段 |
| (1) for j from 0 by 1 to 7 do |
| (2) for k from 0 by 1 to j+1 do |
| (3) Tk(0,j)=SaberKEM.Dec(CTk(0,j)) |
| (4) end for |
| (5) Wj=TVLA(T0(0,1),T1(0,1)) |
| (6) P(0,j)=NICV(Wj,T0(0,j),⋯,Tj+1(0,j)) |
| (7) for k from 0 by 1 to j+1 do |
| (8) Tk′(0,j)=Tk(0,j)(P(0,j)) |
| (9) rkP=average(Tk′(0,j)) |
| (10) end for |
| (11) end for |
| 模板匹配阶段 |
| (12) for i from 0 by 1 to l –1 do |
| (13) cti = 构造密文(ct, i) |
| (14) tri =Saber KEM.Dec(cti) |
| (15) for j from 0 by 1 to 7 do |
| (16) tr′(i,j)=tri(P(0,j)) |
| (17) for k from 0 by 1 to j+1 do |
| (18) Γk(i,j)=SOSD(tr′(i,j),rkP) |
| (19) end for |
| (20) HW(m[i,j])=min(Γk(i,j)) |
| (21) m[i]j=Recover(HW(m[i,j]),HW(m[i,j]−1)) |
| (22) end for |
| (23) end for |
实验平台包括PC, LeCroy示波器和测试设备ChipWhisperer工具套件,其包括:一块搭载了ARM Cortex-M4微控制器的STM32F3目标板、CW308 UFO基板、ChipWhisperer-Lite采集板,如图3所示。PC发送和接收明密文,ChipWhisperer-Lite控制目标板与PC之间的通信,同时示波器采集目标板运行过程中产生的功耗曲线并保存。实验采用的是pqm4[19]中针对Cortex-M4微控制器进行优化后的算法,使用ARM工具链进行编译,并选择最高编译器优化级别-O3,因为在此优化级别下,编译后的算法最难通过侧信道手段进行破解。STM32F3目标板以7.39 MHz运行,采样率设置为44.34 MHz/s,并在目标操作前后增加触发信号来帮助对齐功耗曲线。
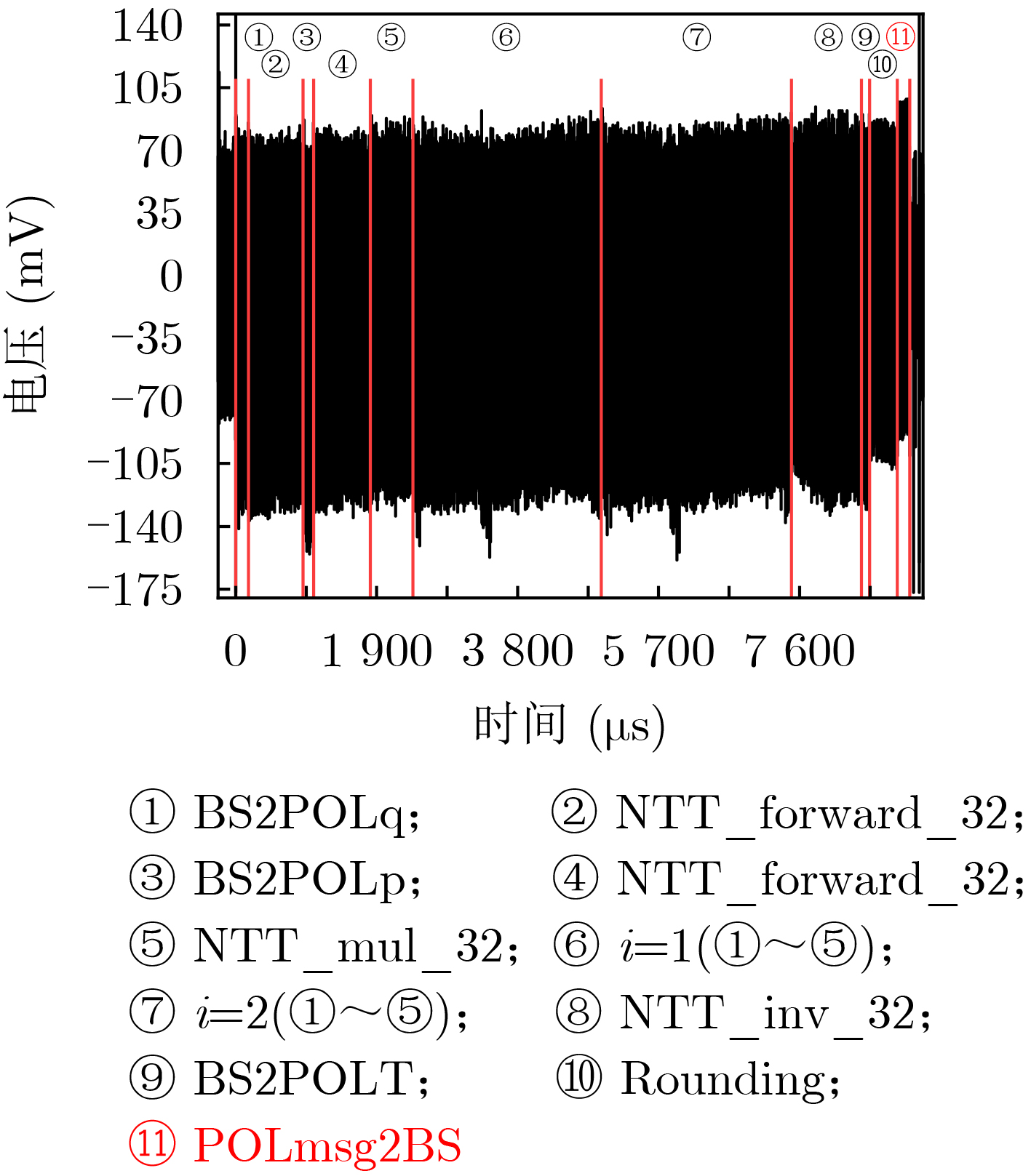
strb指令会泄露有关消息字节中间值的信息,因此消息恢复的第1步是识别与内存中消息字节更新相对应的能量迹特征。图4是Saber KEM解封装操作的部分能量迹,其中能量迹的⑪段为目标函数POLmsg2BS,其放大后的能量迹如图5所示。
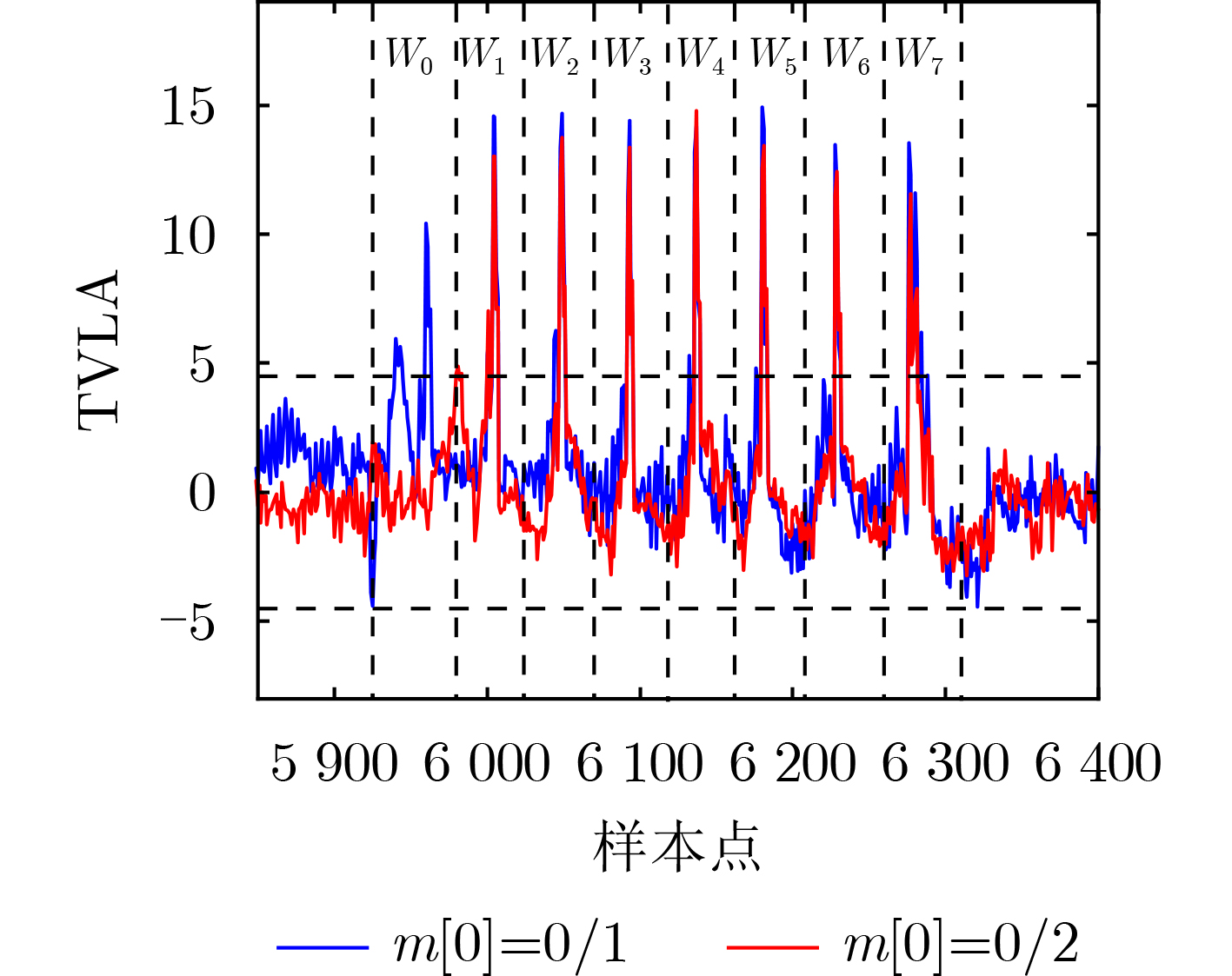
按照4.1.1节的泄露检测步骤对Saber KEM进行泄露点检测,计算的TVLA结果如图6蓝色曲线所示。可以看到计算出的TVLA曲线有8个明显的尖峰,根据上述分析可知这8个尖峰是由m[0]j的存储产生的,在此基础上识别出各中间值更新时的时间窗口Wj,其中j∈[0,7]。同时对CT0 (m[0] = 0)和CT2 (m[0] = 2)这两组密文集进行了相同的泄露检测,检测结果如图6红色曲线所示。可以看到这两组的TVLA结果有7个明显的尖峰,与蓝色曲线相比缺少W0中的尖峰,这是由于CT0和CT2这两组密文在解码的过程中都存在m[0, 0] = 0这个中间过程,因此在第1个循环中并不能找到两组密文解码时的显著差异。
在识别出每次迭代的时间窗口后,本文选择了9个密文集表示为CTk,分别满足HW(m[0, j])=k,其中j∈[0,7], k∈[0,8]。同时这些密文集对应的加密消息mk满足m0 = 0和mk = 2mk–1+1 (k∈[1,8]),在这种方式下可以用较少的能量迹完成模板构建。对于每个密文集分别采集了100条能量迹,共900条能量迹即可完成对恢复m[0]所需模板的构建。按照4.1.2节对HW(m[0, j])进行模板构建,图7为HW(m[0, j])各分类之间NICV值分布图,可以看到计算得到的各尖峰均分布在Wj中。选择NICV值高于0.2的点作为泄露点,并根据4.1.2节构建模板。接着利用密文循环特性构造密文,并根据4.2.2节进行模板匹配,得到最终结果。
在能量分析攻击中,信噪比(Signal-to-Noise Ratio, SNR)是影响攻击成功率的重要因素,提高SNR的方法众多,如使用高精度探头、模拟/数字滤波器等,本文采用多次测量取平均值的方式作为提高SNR的手段,实验结果如表1和表2所示。
| 实验 | 重复测量次数 | 成功率*(%) |
| 实验1 | 1 | 67.50/66.71/66.68 |
| 实验2 | 2 | 90.00/89.67/89.63 |
| 实验3 | 4 | 95.81/95.64/95.64 |
| 实验4 | 6 | 97.36/97.22/97.20 |
| 实验5 | 8 | 98.62/98.43/98.37 |
| 实验6 | 10 | 98.62/98.43/98.39 |
| 实验7 | 12 | 98.62/98.43/98.39 |
| *:成功率分别为LightSaber/Saber/FireSaber | ||
LightSaber算法、Saber算法和FireSaber算法通过增加模块维度k以达到更高的安全级别[14]。NewHope算法、Kyber算法与Saber算法所需要恢复的秘密消息均为32 Byte,因此考虑将文献[9]和文献[10]的中秘密消息恢复结果纳入对比分析。
在预处理阶段所需能量迹数量上,本文所提方法建模所需的能量迹为900条,与文献[9]中以字节为单位进行秘密消息恢复所需能量迹(12 800条)相比减少93%,与文献[11]训练神经网络所需的能量迹相比减少90%。虽然文献[9]中以比特为单位进行秘密消息恢复的方法仅需200条能量迹进行预处理,但由于预处理只需要进行一次,因此其在预处理上所带来的优势并不明显。
在攻击阶段所需能量迹数量上,本文提出的方法每次还原1个消息字节,因此需要32条能量迹,与文献[9]中以字节进行恢复所需能量迹数量相同,与文献[9]中以比特进行恢复相比减少87.5%。与文献[10]相比有所增加,这是因为文献[10]提出的方案通过将1条攻击能量迹划分为32个子片段并分别进行模板匹配。本文提出的方法同样可以利用1条攻击能量迹恢复完整秘密消息,只需同时对所有消息字节进行模板构建,但是会带来模板数量的增加。
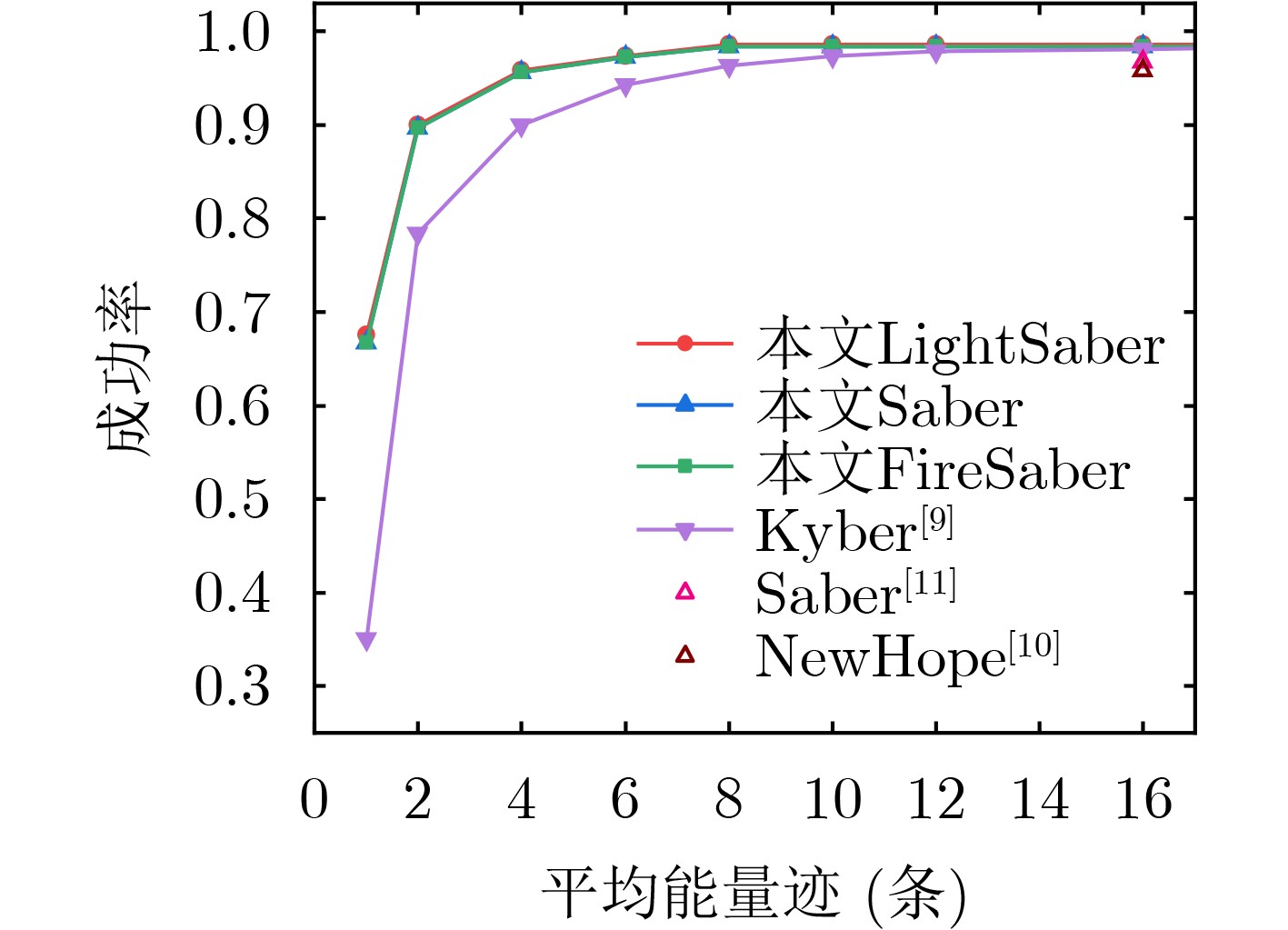
在秘密消息恢复成功率上,本文提出的方法有较高的成功率。文献[10]最终恢复秘密消息的成功率在96%左右,文献[11]在1 000次实验中的成功率最终达到96.71%。在未提高SNR的情况下,本方案恢复Saber算法中秘密消息的成功率达到66.71%,而在4次测量取平均值的情况下成功率即可达到95.64%,最终成功率在98.43%左右,如图8所示。对于恢复错误的秘密消息位,只需通过穷举搜索即可实现秘密消息的完全恢复,其穷举搜索复杂度为25(256×0.02≈5)。
本文虽然以Saber算法为例进行实验验证,但提出的方法适用于其他格密码算法及其变体的算法中,如NIST公布的KEM标准化算法CRYSTAL-Kyber算法、中国密码学会第2轮公钥竞赛入选算法LAC算法、AKCN算法、OKCN算法等。这是因为Single_Bit_Update是难以避免的,且绝大多数格密码算法均满足密文循环特性,可以通过循环密文实现特定密文的构造,从而还原秘密消息与共享密钥。
本文分析格密码中存在的Single_Bit_Update,提出一种基于密文循环特性的模板攻击方法,利用NICV方法对解码阶段的状态中间值的汉明重量可能值构建模板,并使用密文循环特性构造特定密文,以实现秘密消息与共享密钥的恢复,并在ChipWhisperer STM32F303平台上进行了验证。在对Saber算法的秘密消息恢复需要900条预处理能量迹和32条攻击能量迹,且在合适的SNR条件下,恢复秘密消息的成功率可以达到98.43%,在预处理数据量和成功率上都有较大优势。
|
邓自立,郝钢,吴孝慧. 两种加权观测融合方法的全局最优性和完全功能等价性. 科学技术与工程,2005, 5(13): 860-865.[2]邓自立. 自校正滤波理论及其应用现代时间序列分析方法. 哈尔滨:哈尔滨工业大学出版社,2003: 1-343.[3]Kailath T, Sayed A H, and Hassibi B. Linear Estimation. Upper Saddle River, New Jersey: Prentice-Hall, 2000: 78-116.[4]邓自立. 最优估计理论建模、滤波、信息融合估计. 哈尔滨:哈尔滨工业大学出版社,2005: 1-490.[5]邓自立,马建为,高媛. 两传感器自校正信息融合Kalman滤波器. 科学技术与工程,2003, 3(4): 321-324.[6]Sun Shuli and Deng Zili. Multi-sensor optimal information fusion Kalman filter[J].Automatica.2004, 40(6):1017-1023[7]Deng Zili, Gao Yuan, and Mao Lin, et al.. New approach to information fusion steady-state Kalman filtering[J].Automatica.2005, 41(10):1695-1707[8]郑大钟. 线性系统理论(第2版). 北京:清华大学出版社,2002: 441-466.
|

Lu Jiaguo . ASYMMETRIC RIDGE WAVEGUIDE SLOT LINEAR ARRAY FOR ONE DEMENSION IDE SCAN-ANGLE PHASED ARRAY[J]. Journal of Electronics & Information Technology, 2001, 23(2): 175-180.

| 算法1 Saber PKE解密算法 |
| 输入:私钥s∈B∗ |
| 密文c=(cm,b′)∈B* |
| 输出:解密消息m′∈B32 |
| (1) v=b′T(smodp)∈Rp |
| (2) m′=((v+h2−2εp−εTcm)modp)>>(εp−1)∈R2 |
| (3) 返回m′ |
| 算法2 Saber KEM解封装算法 |
| 输入:私钥skKEM=(z,pkh,pk,s)∈B* |
| 密文c∈B* |
| 输出:共享密钥K∈B32 |
| (1) m′=SaberPKE.Dec(s,c) |
| (2) (K′,r′)=G(pkh,m′) |
| (3) c′=SaberPKE.Enc(pk,m′;r′) |
| (4) 若 c=c′ 则返回K=KDF(K′||H(c)) |
| (5) 否则返回K=KDF(z||H(c)) |
| 算法3 Saber POLmsg2BS |
| (1) void POLmsg2BS(uint8_t bytes[SABER_KEYBYTES], const poly *data) { |
| (2) size_t t, i, j; |
| (3) for (j = 0; j < SABER_KEYBYTES; j++) { |
| (4) bytes[j] = 0; |
| (5) for (i = 0; i < 8; i++) { |
| (6) t = (data->coeffs[j × 8 + i] & 0x01); |
| (7) bytes[j] |= t << i; |
| (8) } |
| (9) } |
| (10) } |
| 算法4 针对Saber算法的消息恢复方法 |
| 预处理阶段 |
| (1) for j from 0 by 1 to 7 do |
| (2) for k from 0 by 1 to j+1 do |
| (3) Tk(0,j)=SaberKEM.Dec(CTk(0,j)) |
| (4) end for |
| (5) Wj=TVLA(T0(0,1),T1(0,1)) |
| (6) P(0,j)=NICV(Wj,T0(0,j),⋯,Tj+1(0,j)) |
| (7) for k from 0 by 1 to j+1 do |
| (8) Tk′(0,j)=Tk(0,j)(P(0,j)) |
| (9) rkP=average(Tk′(0,j)) |
| (10) end for |
| (11) end for |
| 模板匹配阶段 |
| (12) for i from 0 by 1 to l –1 do |
| (13) cti = 构造密文(ct, i) |
| (14) tri =Saber KEM.Dec(cti) |
| (15) for j from 0 by 1 to 7 do |
| (16) tr′(i,j)=tri(P(0,j)) |
| (17) for k from 0 by 1 to j+1 do |
| (18) Γk(i,j)=SOSD(tr′(i,j),rkP) |
| (19) end for |
| (20) HW(m[i,j])=min(Γk(i,j)) |
| (21) m[i]j=Recover(HW(m[i,j]),HW(m[i,j]−1)) |
| (22) end for |
| (23) end for |
| 实验 | 重复测量次数 | 成功率*(%) |
| 实验1 | 1 | 67.50/66.71/66.68 |
| 实验2 | 2 | 90.00/89.67/89.63 |
| 实验3 | 4 | 95.81/95.64/95.64 |
| 实验4 | 6 | 97.36/97.22/97.20 |
| 实验5 | 8 | 98.62/98.43/98.37 |
| 实验6 | 10 | 98.62/98.43/98.39 |
| 实验7 | 12 | 98.62/98.43/98.39 |
| *:成功率分别为LightSaber/Saber/FireSaber | ||
| 算法1 Saber PKE解密算法 |
| 输入:私钥s∈B∗ |
| 密文c=(cm,b′)∈B* |
| 输出:解密消息m′∈B32 |
| (1) v=b′T(smodp)∈Rp |
| (2) m′=((v+h2−2εp−εTcm)modp)>>(εp−1)∈R2 |
| (3) 返回m′ |
| 算法2 Saber KEM解封装算法 |
| 输入:私钥skKEM=(z,pkh,pk,s)∈B* |
| 密文c∈B* |
| 输出:共享密钥K∈B32 |
| (1) m′=SaberPKE.Dec(s,c) |
| (2) (K′,r′)=G(pkh,m′) |
| (3) c′=SaberPKE.Enc(pk,m′;r′) |
| (4) 若 c=c′ 则返回K=KDF(K′||H(c)) |
| (5) 否则返回K=KDF(z||H(c)) |
| 算法3 Saber POLmsg2BS |
| (1) void POLmsg2BS(uint8_t bytes[SABER_KEYBYTES], const poly *data) { |
| (2) size_t t, i, j; |
| (3) for (j = 0; j < SABER_KEYBYTES; j++) { |
| (4) bytes[j] = 0; |
| (5) for (i = 0; i < 8; i++) { |
| (6) t = (data->coeffs[j × 8 + i] & 0x01); |
| (7) bytes[j] |= t << i; |
| (8) } |
| (9) } |
| (10) } |
| 算法4 针对Saber算法的消息恢复方法 |
| 预处理阶段 |
| (1) for j from 0 by 1 to 7 do |
| (2) for k from 0 by 1 to j+1 do |
| (3) Tk(0,j)=SaberKEM.Dec(CTk(0,j)) |
| (4) end for |
| (5) Wj=TVLA(T0(0,1),T1(0,1)) |
| (6) P(0,j)=NICV(Wj,T0(0,j),⋯,Tj+1(0,j)) |
| (7) for k from 0 by 1 to j+1 do |
| (8) Tk′(0,j)=Tk(0,j)(P(0,j)) |
| (9) rkP=average(Tk′(0,j)) |
| (10) end for |
| (11) end for |
| 模板匹配阶段 |
| (12) for i from 0 by 1 to l –1 do |
| (13) cti = 构造密文(ct, i) |
| (14) tri =Saber KEM.Dec(cti) |
| (15) for j from 0 by 1 to 7 do |
| (16) tr′(i,j)=tri(P(0,j)) |
| (17) for k from 0 by 1 to j+1 do |
| (18) Γk(i,j)=SOSD(tr′(i,j),rkP) |
| (19) end for |
| (20) HW(m[i,j])=min(Γk(i,j)) |
| (21) m[i]j=Recover(HW(m[i,j]),HW(m[i,j]−1)) |
| (22) end for |
| (23) end for |
| 实验 | 重复测量次数 | 成功率*(%) |
| 实验1 | 1 | 67.50/66.71/66.68 |
| 实验2 | 2 | 90.00/89.67/89.63 |
| 实验3 | 4 | 95.81/95.64/95.64 |
| 实验4 | 6 | 97.36/97.22/97.20 |
| 实验5 | 8 | 98.62/98.43/98.37 |
| 实验6 | 10 | 98.62/98.43/98.39 |
| 实验7 | 12 | 98.62/98.43/98.39 |
| *:成功率分别为LightSaber/Saber/FireSaber | ||
 下载:
下载:




 DownLoad:
DownLoad: