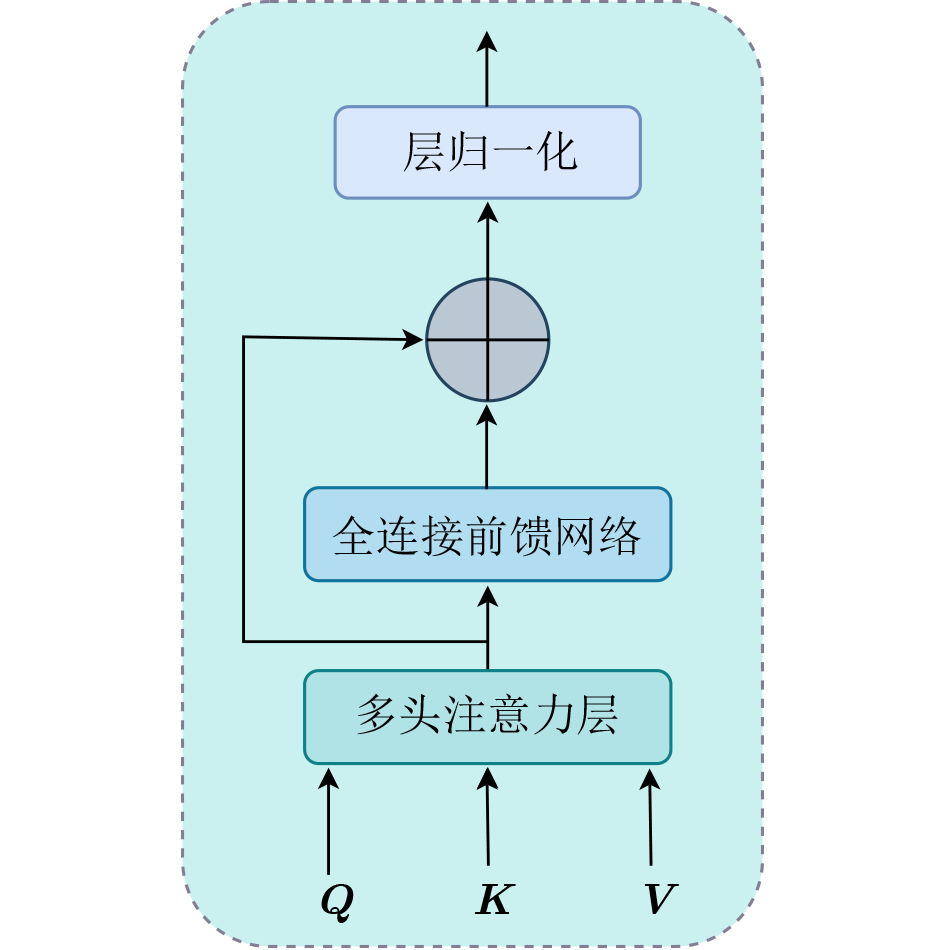
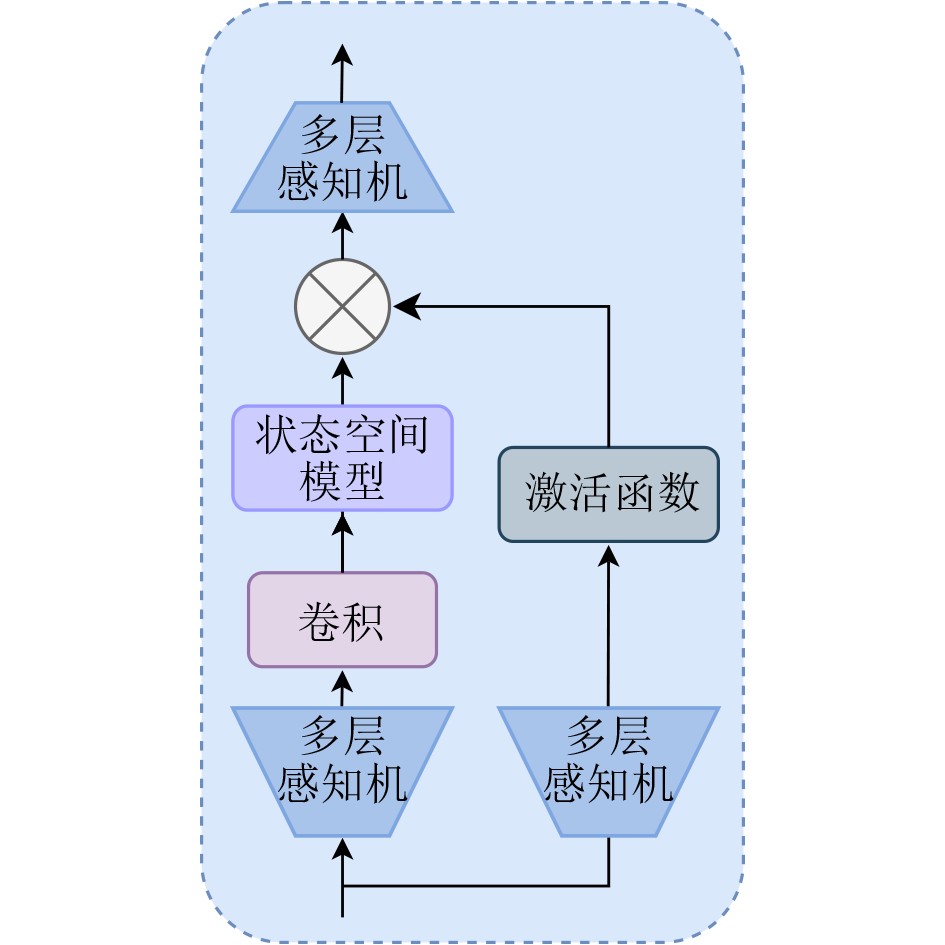
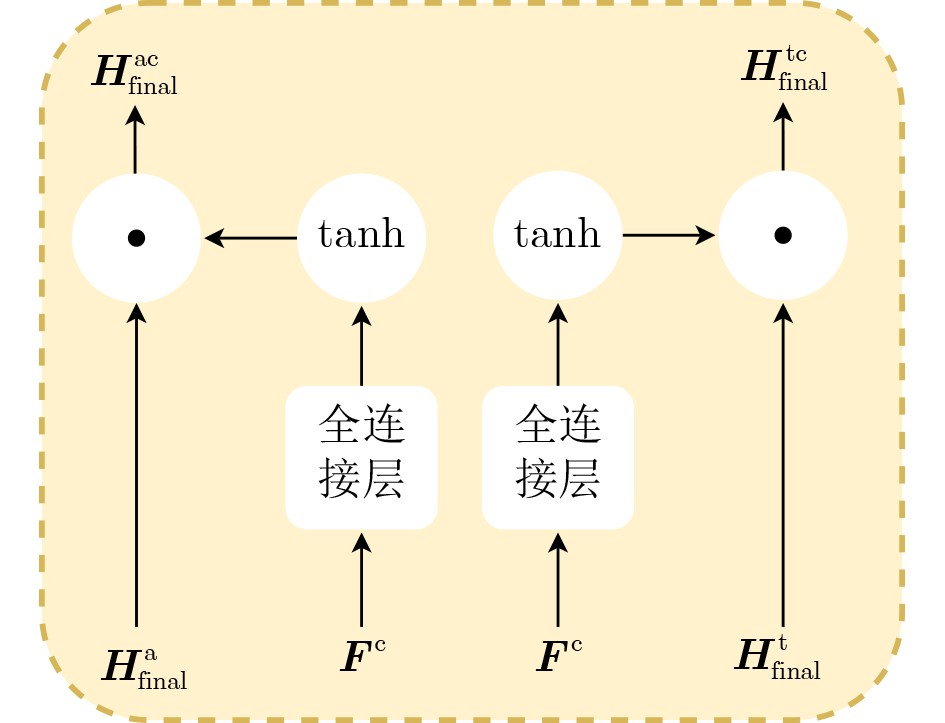
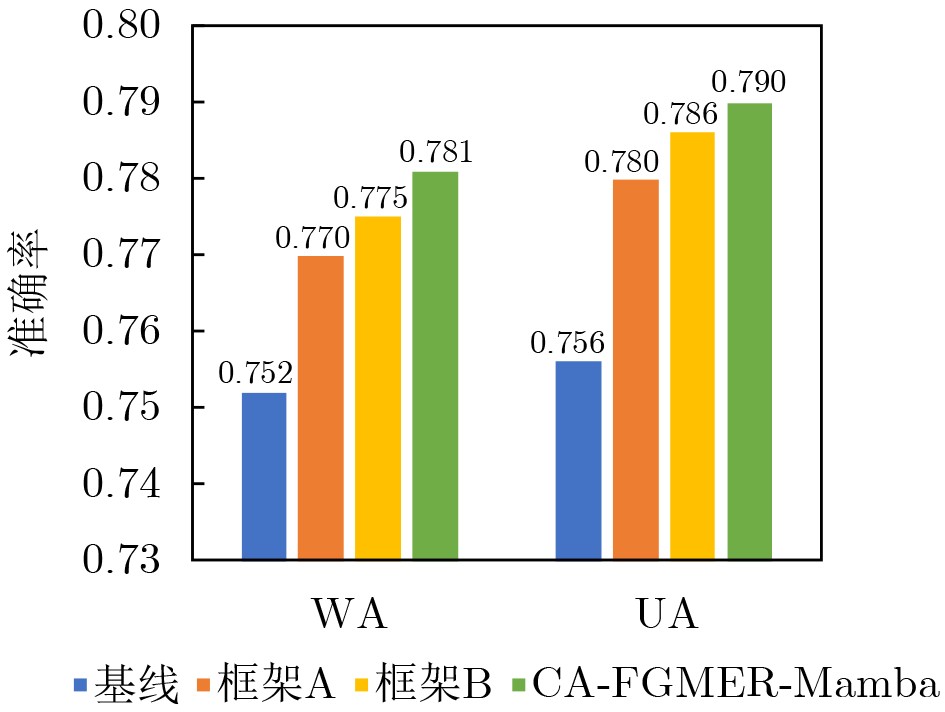
| Citation: | SUN Linhui, CHENG Leyang, YANG Xinyue, CHEN Shuaitong, LI Pingan, SHAO Xi. Context-Aware Fine-Grained Multimodal Emotion Recognition Based on Mamba[J]. Journal of Electronics & Information Technology, 2026, 48(5): 1948-1959. doi: 10.11999/JEIT251307

|

| [1] |
孙强, 王姝玉. 结合时间注意力机制和单模态标签自动生成策略的自监督多模态情感识别[J]. 电子与信息学报, 2024, 46(2): 588–601. doi: 10.11999/JEIT231107.
SUN Qiang and WANG Shuyu. Self-supervised multimodal emotion recognition combining temporal attention mechanism and unimodal label automatic generation strategy[J]. Journal of Electronics & Information Technology, 2024, 46(2): 588–601. doi: 10.11999/JEIT231107.
|
| [2] |
刘佳, 宋泓, 陈大鹏, 等. 非语言信息增强和对比学习的多模态情感分析模型[J]. 电子与信息学报, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274.
LIU Jia, SONG Hong, CHEN Dapeng, et al. A multimodal sentiment analysis model enhanced with non-verbal information and contrastive learning[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274.
|
| [3] |
薛珮芸, 戴书涛, 白静, 等. 借助语音和面部图像的双模态情感识别[J]. 电子与信息学报, 2024, 46(12): 4542–4552. doi: 10.11999/JEIT240087.
XUE Peiyun, DAI Shutao, BAI Jing, et al. Emotion recognition with speech and facial images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4542–4552. doi: 10.11999/JEIT240087.
|
| [4] |
LIU Yuanyuan, WEI Lin, LIU Kejun, et al. Leveraging eye movement for instructing robust video-based facial expression recognition[J]. IEEE Transactions on Affective Computing, 2025, 16(4): 3404–3420. doi: 10.1109/TAFFC.2025.3599859.
|
| [5] |
LIU Yuanyuan, ZHANG Haoyu, ZHAN Yibing, et al. Noise-resistant multimodal Transformer for emotion recognition[J]. International Journal of Computer Vision, 2025, 133(5): 3020–3040. doi: 10.1007/s11263-024-02304-3.
|
| [6] |
LIU Yang, SUN Haoqin, GUAN Wenbo, et al. Multi-modal speech emotion recognition using self-attention mechanism and multi-scale fusion framework[J]. Speech Communication, 2022, 139: 1–9. doi: 10.1016/j.specom.2022.02.006.
|
| [7] |
SHANG Yanan and FU Tianqi. Multimodal fusion: A study on speech-text emotion recognition with the integration of deep learning[J]. Intelligent Systems with Applications, 2024, 24: 200436. doi: 10.1016/j.iswa.2024.200436.
|
| [8] |
QIAN Fan and HAN J. Contrastive regularization for multimodal emotion recognition using audio and text[EB/OL]. (2022-11-20). https://doi.org/10.48550/arXiv.2211.10885, 2022.
|
| [9] |
SHI Tao and HUANG Shaolun. MultiEMO: An attention-based correlation-aware multimodal fusion framework for emotion recognition in conversations[C]. The 61st Annual Meeting of the Association for Computational Linguistics, Toronto, Canada, 2023: 14752–14766. doi: 10.18653/v1/2023.acl-long.824.
|
| [10] |
ZHAO Zihan, WANG Yu, and WANG Yanfeng. Knowledge-aware Bayesian co-attention for multimodal emotion recognition[C]. The ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10095798.
|
| [11] |
LIN Binghuai and WANG Liyuan. Robust multi-modal speech emotion recognition with ASR error adaptation[C]. ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10094839.
|
| [12] |
GUO Lili, SONG Yikang, and DING Shifei. Speaker-aware cognitive network with cross-modal attention for multimodal emotion recognition in conversation[J]. Knowledge-Based Systems, 2024, 296: 111969. doi: 10.1016/j.knosys.2024.111969.
|
| [13] |
JOSHI A, BHAT A, JAIN A, et al. COGMEN: COntextualized GNN based multimodal emotion recognition[C]. The 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, USA, 2022: 4148–4164. doi: 10.18653/v1/2022.naacl-main.306.
|
| [14] |
GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[C]. The 1st Conference on Language Modeling, Philadelphia, USA, 2024.
|
| [15] |
CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]. The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 2014: 1724–1734. doi: 10.3115/v1/D14-1179.
|
| [16] |
PORJAZOVSKI D, GROSZ T, and KURIMO M. Improved spoken emotion recognition with combined segment-based processing and triplet loss[C]. The 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024), Trento, Italy, 2024: 47–54.
|
| [17] |
BUSSO C, BULUT M, LEE C C, et al. IEMOCAP: Interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42(4): 335–359. doi: 10.1007/s10579-008-9076-6.
|
| [18] |
PORIA S, HAZARIKA D, MAJUMDER N, et al. MELD: A multimodal multi-party dataset for emotion recognition in conversations[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 527–536. doi: 10.18653/v1/P19-1050.
|
| [19] |
WANG Yuhua, SHEN Guang, XU Yuezhu, et al. Learning mutual correlation in multimodal transformer for speech emotion recognition[C]. The Interspeech 2021, Brno, Czechia, 2021: 4518–4522. doi: 10.21437/Interspeech.2021-2004.
|
| [20] |
ZHANG Junfeng, XING Lining, TAN Zhen, et al. Multi-head attention fusion networks for multi-modal speech emotion recognition[J]. Computers & Industrial Engineering, 2022, 168: 108078. doi: 10.1016/j.cie.2022.108078.
|
| [21] |
HU Dou, HOU Xiaolong, WEI Lingwei, et al. MM-DFN: Multimodal dynamic fusion network for emotion recognition in conversations[C]. ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 2022: 7037–7041. doi: 10.1109/ICASSP43922.2022.9747397.
|
| [22] |
LI Jiang, WANG Xiaoping, LV Guoqing, et al. GraphCFC: A directed graph based cross-modal feature complementation approach for multimodal conversational emotion recognition[J]. IEEE Transactions on Multimedia, 2024, 26: 77–89. doi: 10.1109/TMM.2023.3260635.
|
| [23] |
AI Wei, SHOU Yuntao, MENG Tao, et al. DER-GCN: Dialog and event relation-aware graph convolutional neural network for multimodal dialog emotion recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(3): 4908–4921. doi: 10.1109/TNNLS.2024.3367940.
|
| [24] |
LI Zaijing, TANG Fengxiao, ZHAO Ming, et al. EmoCaps: Emotion capsule based model for conversational emotion recognition[C]. The Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 2022: 1610–1618. doi: 10.18653/v1/2022.findings-acl.126.
|
| [25] |
LIAN Zheng, LIU Bin, and TAO Jianhua. SMIN: Semi-supervised multi-modal interaction network for conversational emotion recognition[J]. IEEE Transactions on Affective Computing, 2023, 14(3): 2415–2429. doi: 10.1109/TAFFC.2022.3141237.
|
| [26] |
JEONG E, KIM G, and KANG S. Multimodal prompt learning in emotion recognition using context and audio information[J]. Mathematics, 2023, 11(13): 2908. doi: 10.3390/math11132908.
|
| [27] |
DUTTA S and GANAPATHY S. HCAM - hierarchical cross attention model for multi-modal emotion recognition[EB/OL]. (2023-04-14). https://doi.org/10.48550/arXiv.2304.06910, 2023.
|
| [28] |
SHOU Yuntao, MENG Tao, AI Wei, et al. Revisiting multi-modal emotion learning with broad state space models and probability-guidance fusion[C]. The European Conference on Machine Learning and Knowledge Discovery in Databases, Research Track, Porto, Portugal, 2025: 509–525. doi: 10.1007/978-3-032-06078-5_29.
|
| [29] |
WANG Ye, ZHANG Wei, LIU Ke, et al. Dynamic emotion-dependent network with relational subgraph interaction for multimodal emotion recognition[J]. IEEE Transactions on Affective Computing, 2025, 16(2): 712–725. doi: 10.1109/taffc.2024.3461148.
|
Figures(6) / Tables(4)



 DownLoad:
DownLoad: