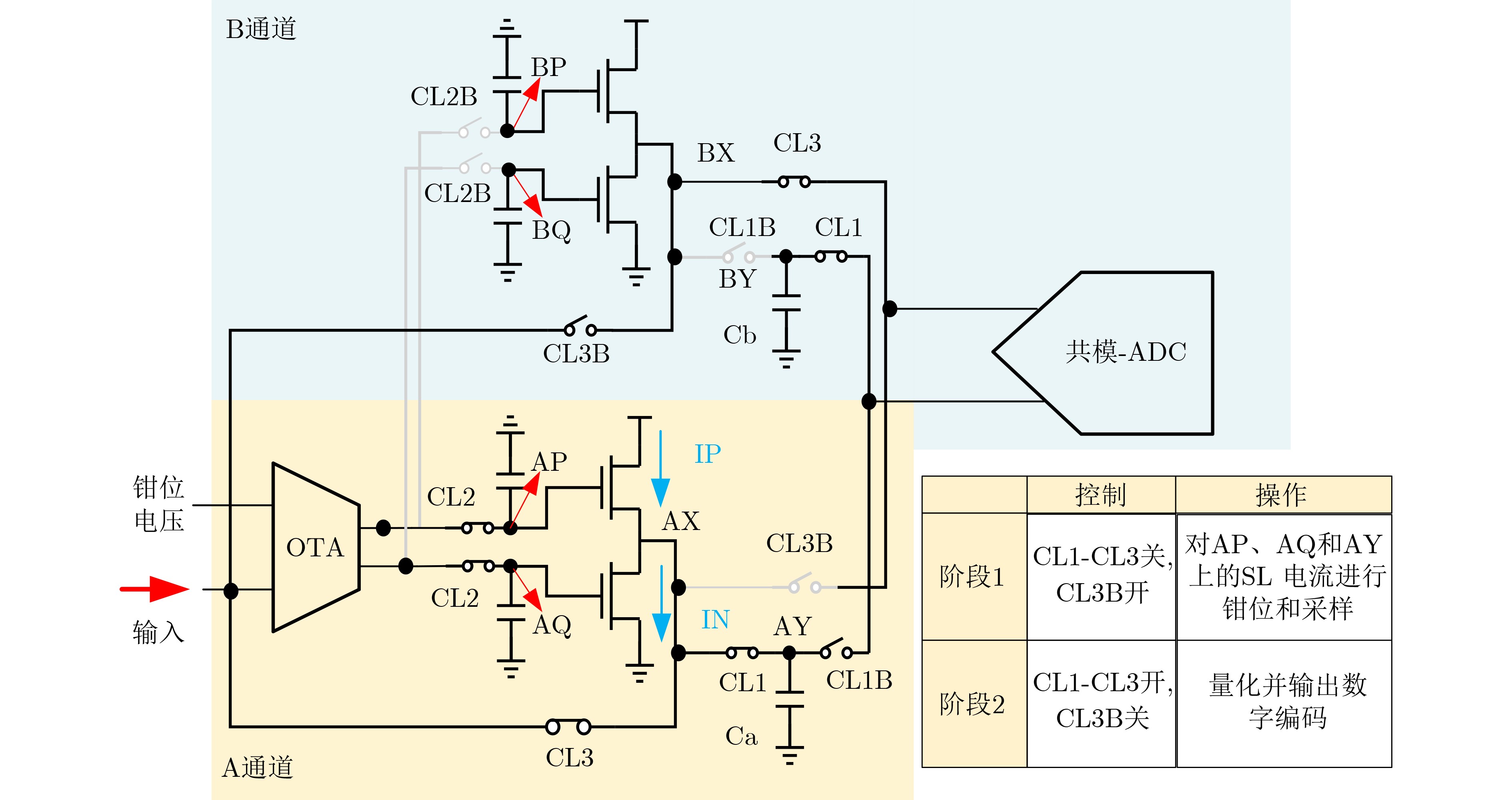
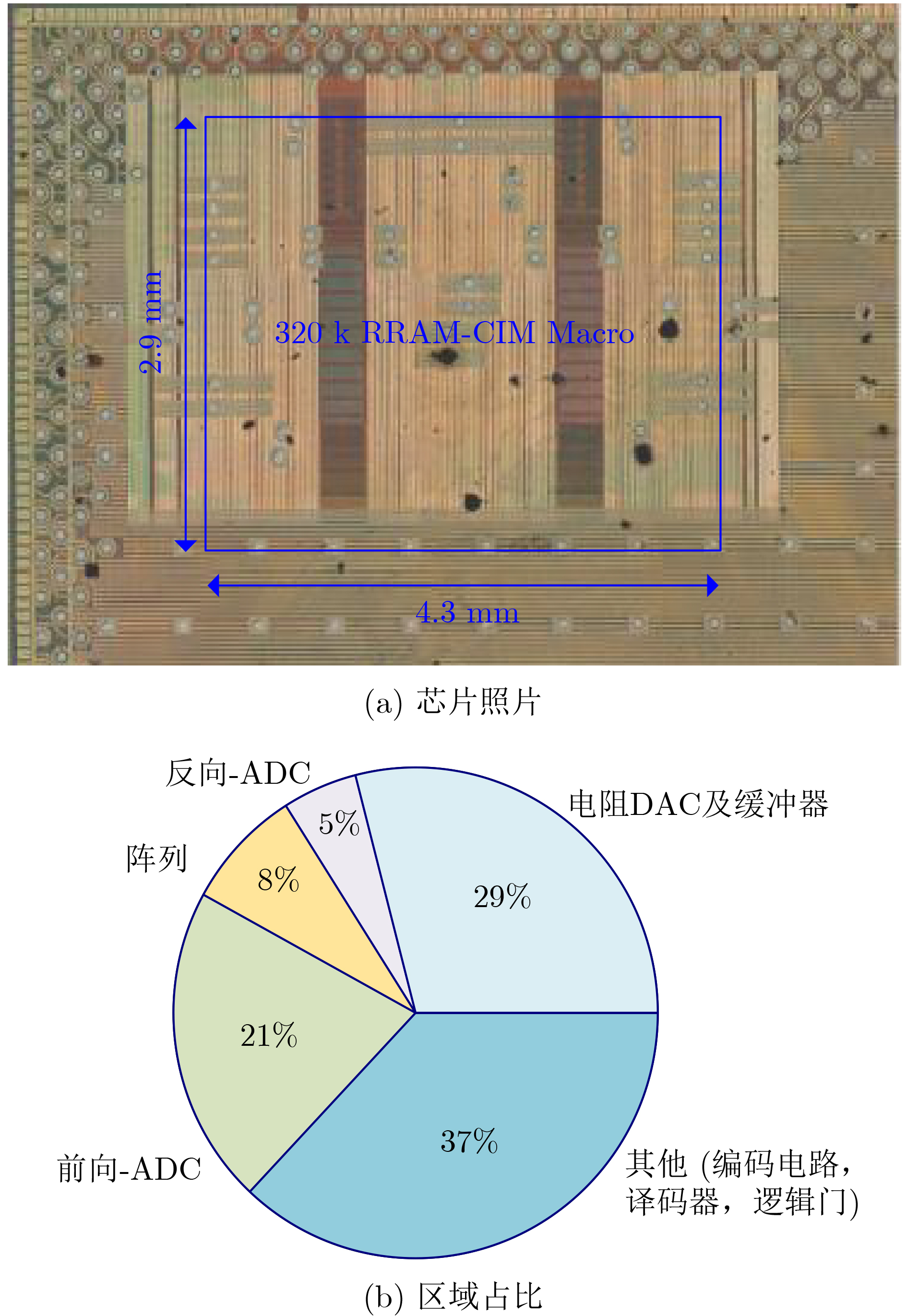
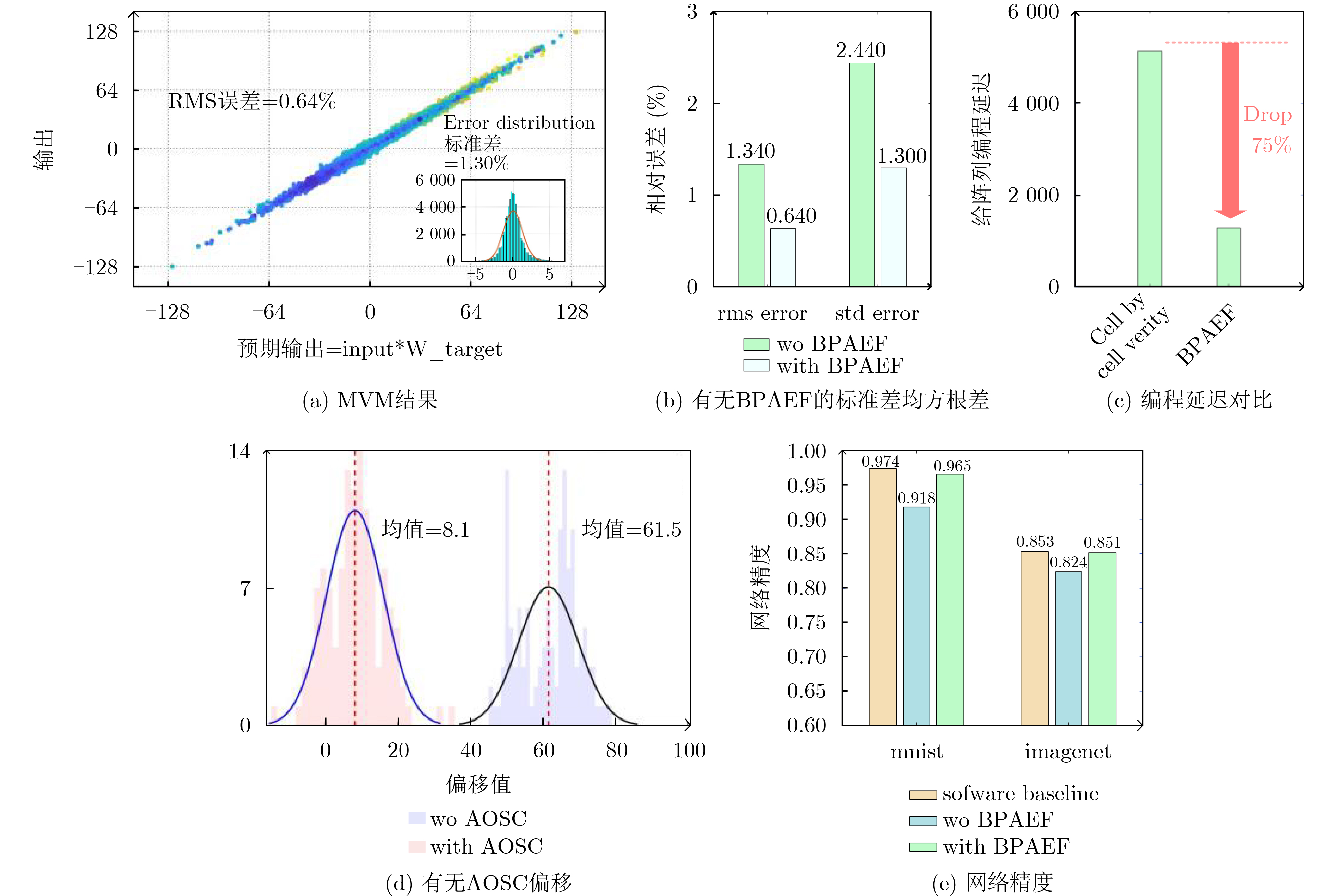
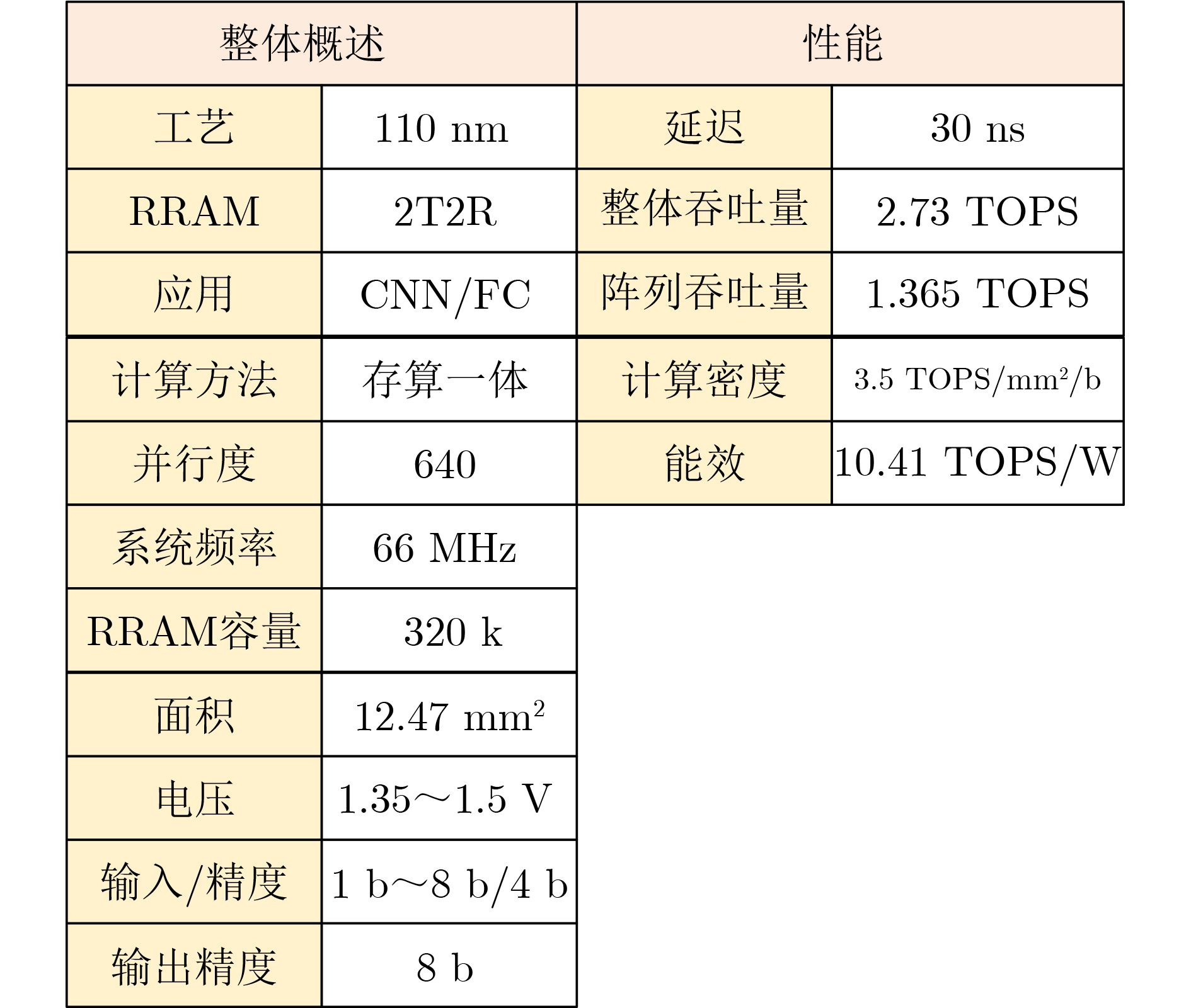
| Citation: | XIE Lifan, WEI Songtao, YAO Peng, WU Dong, TANG Jianshi, QIAN He, GAO Bin, WU Huaqiang. A Fast and Accurate Programming Strategy for Analog In-Memory Computing Validated With a Transposable RRAM Macro and 0.64% Fully-Parallel RMS Error[J]. Journal of Electronics & Information Technology, 2026, 48(5): 1875-1883. doi: 10.11999/JEIT251174

|

| [1] |
XU Xiaowei, DING Yukun, HU S X, et al. Scaling for edge inference of deep neural networks[J]. Nature Electronics, 2018, 1(4): 216–222. doi: 10.1038/s41928-018-0059-3.
|
| [2] |
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[J/OL]. Computer Science, Linguistics, 2019.
|
| [3] |
KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks [J]. Communications of the ACM, 2017, 60 (6):84–90.
|
| [4] |
FUJIWARA H, MORI H, ZHAO Weichang, et al. A 3nm, 32.5TOPS/W, 55.0TOPS/mm2 and 3.78Mb/mm2 fully-digital compute-in-memory macro supporting INT12 × INT12 with a parallel-MAC architecture and foundry 6T-SRAM bit cell[C]. 2024 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2024: 572–573. doi: 10.1109/ISSCC49657.2024.10454556.
|
| [5] |
GHOLAMI A, YAO Zhewei, KIM S, et al. AI and memory wall[J]. IEEE Micro, 2024, 44(3): 33–39. doi: 10.1109/MM.2024.3373763.
|
| [6] |
BÜCHEL J, VASILOPOULOS A, KERSTING B, et al. Gradient descent-based programming of analog in-memory computing cores[C]. 2022 International Electron Devices Meeting, San Francisco, USA, 2022: 779–782. doi: 10.1109/IEDM45625.2022.10019486.
|
| [7] |
JACOB B, KLIGYS S, CHEN Bo, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference[EB/OL]. https://doi.org/10.48550/arXiv.1712.05877, 2017.
|
| [8] |
RADHAKRISHNAN J, BELMONTE A, CLIMA S, et al. Improving post-cycling low resistance state retention in resistive RAM with combined oxygen vacancy and copper filament[J]. IEEE Electron Device Letters, 2019, 40(7): 1072–1075. doi: 10.1109/LED.2019.2917553.
|
| [9] |
SHIM W, MENG Jian, PENG Xiaochen, et al. Impact of multilevel retention characteristics on RRAM based DNN inference engine[C]. Proceedings of 2021 IEEE International Reliability Physics Symposium, Monterey, USA, 2021: 1–4. doi: 10.1109/IRPS46558.2021.9405210.
|
| [10] |
CHIU Y C, KHWA W S, LI C Y, et al. A 22nm 8Mb STT-MRAM near-memory-computing macro with 8b-precision and 46.4–160.1TOPS/W for edge-AI devices[C]. Proceedings of 2023 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2023: 496–497. doi: 10.1109/ISSCC42615.2023.10067563.
|
| [11] |
YOU Deqi, KHWA W S, WU J J, et al. A 22nm nonvolatile AI-edge processor with 21.4TFLOPS/W using 47.25Mb lossless-compressed-computing STT-MRAM near-memory-compute macro[C]. 2024 IEEE Symposium on VLSI Technology and Circuits, Honolulu, USA, 2024: 1–2. doi: 10.1109/VLSITechnologyandCir46783.2024.10631408.
|
| [12] |
WANG Yang, YANG Xiaolong, QIN Yubin, et al. A 28nm 83.23TFLOPS/W POSIT-based compute-in-memory macro for high-accuracy AI applications[C]. 2024 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2024: 566–567. doi: 10.1109/ISSCC49657.2024.10454567.
|
| [13] |
KHWA W S, WU Pingchun, WU J J, et al. A 16nm 96Kb integer/floating-point dual-mode-gain-cell-computing-in-memory macro achieving 73.3–163.3TOPS/W and 33.2–91.2TFLOPS/W for AI edge-devices[C]. 2024 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2024: 568–569. doi: 10.1109/ISSCC49657.2024.10454447.
|
| [14] |
MORI H, ZHAO Weichang, LEE C E, et al. A 4nm 6163-TOPS/W/b 4790-TOPS/mm2/b SRAM based digital-computing-in-memory macro supporting bit-width flexibility and simultaneous MAC and weight update[C]. 2023 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2023: 132–133. doi: 10.1109/ISSCC42615.2023.10067555.
|
| [15] |
KHADDAM-ALJAMEH R, STANISAVLJEVIC M, FORNT MAS J, et al. HERMES core – A 14nm CMOS and PCM-based in-memory compute core using an array of 300ps/LSB linearized CCO-based ADCs and local digital processing[C]. 2021 Symposium on VLSI Circuits, Kyoto, Japan, 2021: 1–2. doi: 10.23919/VLSICircuits52068.2021.9492362.
|
| [16] |
HUNG J M, HUANG Y H, HUANG S P, et al. An 8-Mb DC-current-free binary-to-8b precision ReRAM nonvolatile computing-in-memory macro using time-space-readout with 1286.4–21.6TOPS/W for edge-AI devices[C]. 2022 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2022: 1–3. doi: 10.1109/ISSCC42614.2022.9731715.
|
| [17] |
HUANG W H, WEN Taihao, HUNG J M, et al. A nonvolatile Al-edge processor with 4MB SLC-MLC hybrid-mode ReRAM compute-in-memory macro and 51.4–251TOPS/W[C]. 2023 IEEE International Solid-State Circuits Conference, San Francisco, USA, 2023: 15–17. doi: 10.1109/ISSCC42615.2023.10067610.
|
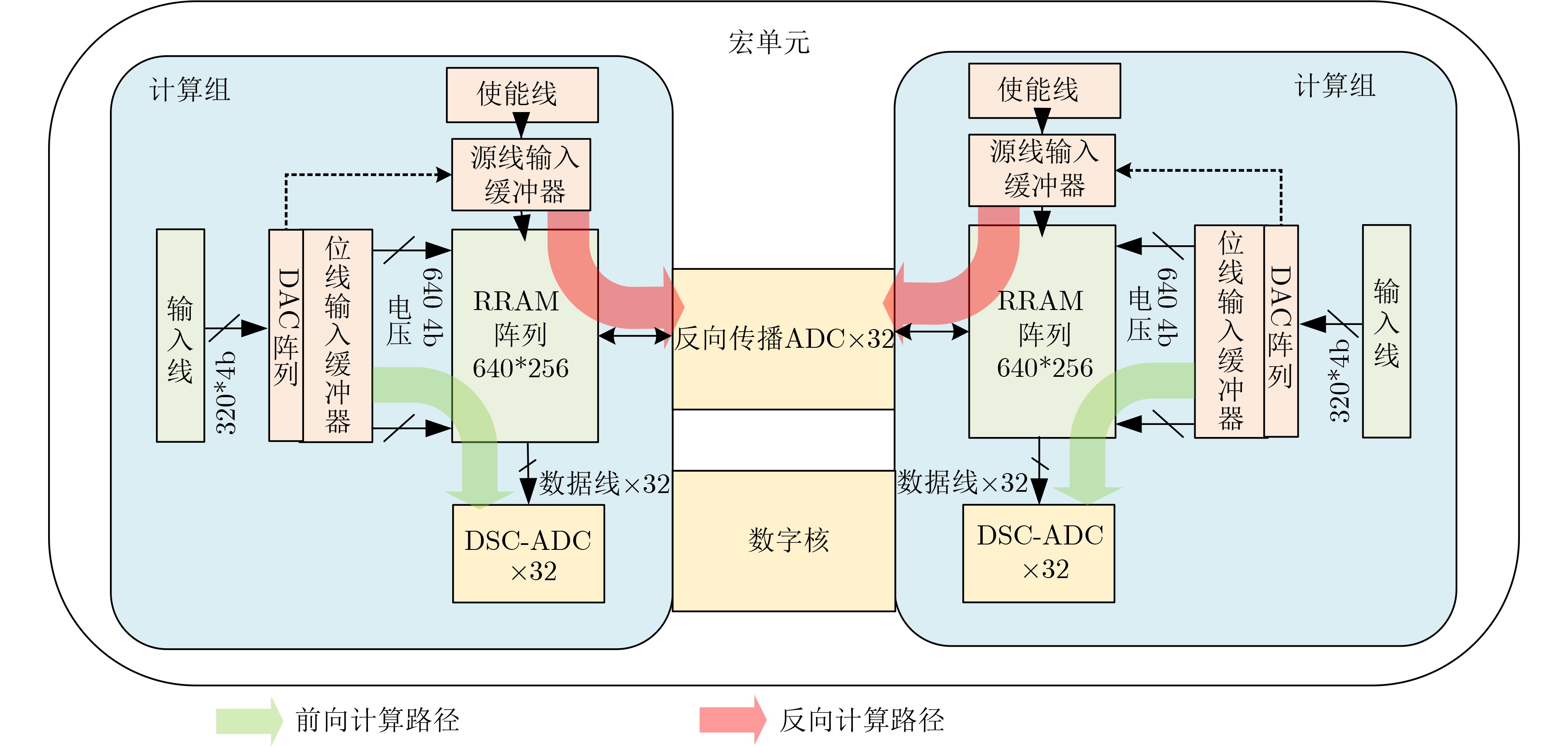
Figures(9) / Tables(1)



 DownLoad:
DownLoad: