| Citation: | MA Li, XIN Jiangbo, WANG Lu, DAI Xinguan, SONG Shuang. Mamba-YOWO: An Efficient Spatio-Temporal Representation Framework for Action Detection[J]. Journal of Electronics & Information Technology, 2026, 48(5): 1974-1984. doi: 10.11999/JEIT251124

|

| [1] |
王彩玲, 闫晶晶, 张智栋. 基于多模态数据的人体行为识别方法研究综述[J]. 计算机工程与应用, 2024, 60(9): 1–18. doi: 10.3778/j.issn.1002-8331.2310-0090.
WANG Cailing, YAN Jingjing, and ZHANG Zhidong. Review on human action recognition methods based on multimodal data[J]. Computer Engineering and Applications, 2024, 60(9): 1–18. doi: 10.3778/j.issn.1002-8331.2310-0090.
|
| [2] |
ZHEN Rui, SONG Wenchao, HE Qiang, et al. Human-computer interaction system: A survey of talking-head generation[J]. Electronics, 2023, 12(1): 218. doi: 10.3390/electronics12010218.
|
| [3] |
SIMONYAN K and ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]. The 28th International Conference on Neural Information Processing Systems - Volume 1, Montreal, Canada, 2014: 568–576.
|
| [4] |
WANG Limin, XIONG Yuanjun, WANG Zhe, et al. Temporal segment networks: Towards good practices for deep action recognition[C]. The 14th European Conference on Computer Vision – ECCV 2016, Amsterdam, The Netherlands, 2016: 20–36. doi: 10.1007/978-3-319-46484-8_2.
|
| [5] |
TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]. The IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4489–4497. doi: 10.1109/ICCV.2015.510.
|
| [6] |
CARREIRA J and ZISSERMAN A. Quo Vadis, action recognition? A new model and the kinetics dataset[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4724–4733. doi: 10.1109/CVPR.2017.502.
|
| [7] |
钱惠敏, 陈实, 皇甫晓瑛. 基于双流-非局部时空残差卷积神经网络的人体行为识别[J]. 电子与信息学报, 2024, 46(3): 1100–1108. doi: 10.11999/JEIT230168.
QIAN Huimin, CHEN Shi, and HUANGFU Xiaoying. Human activities recognition based on two-stream NonLocal spatial temporal residual convolution neural network[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1100–1108. doi: 10.11999/JEIT230168.
|
| [8] |
WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803. doi: 10.1109/CVPR.2018.00813.
|
| [9] |
DONAHUE J, ANNE HENDRICKS L, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 2625–2634. doi: 10.1109/CVPR.2015.7298878.
|
| [10] |
曹毅, 李杰, 叶培涛, 等. 利用可选择多尺度图卷积网络的骨架行为识别[J]. 电子与信息学报, 2025, 47(3): 839–849. doi: 10.11999/JEIT240702.
CAO Yi, LI Jie, YE Peitao, et al. Skeleton-based action recognition with selective multi-scale graph convolutional network[J]. Journal of Electronics & Information Technology, 2025, 47(3): 839–849. doi: 10.11999/JEIT240702.
|
| [11] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, Austria, 2021.
|
| [12] |
BERTASIUS G, WANG Heng, and TORRESANI L. Is space-time attention all you need for video understanding?[C]. The 38th International Conference on Machine Learning, 2021: 813–824.
|
| [13] |
ZHANG Chenlin, WU Jianxin, and LI Yin. ActionFormer: Localizing moments of actions with transformers[C]. The 17th European Conference on Computer Vision – ECCV 2022, Tel Aviv, Israel, 2022: 492–510. doi: 10.1007/978-3-031-19772-7_29.
|
| [14] |
韩宗旺, 杨涵, 吴世青, 等. 时空自适应图卷积与Transformer结合的动作识别网络[J]. 电子与信息学报, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.
HAN Zongwang, YANG Han, WU Shiqing, et al. Action recognition network combining spatio-temporal adaptive graph convolution and Transformer[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.
|
| [15] |
GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[C]. Conference on Language Modeling, Philadelphia, 2024.
|
| [16] |
ZHU Lianghui, LIAO Bencheng, ZHANG Qian, et al. Vision mamba: Efficient visual representation learning with bidirectional state space model[C]. Procedding of Forty-First International Conference on Machine Learning, Vienna, Austria, 2024.
|
| [17] |
LIU Yue, TIAN Yunjie, ZHAO Yuzhong, et al. VMamba: Visual state space model[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 3273.
|
| [18] |
LI Kunchang, LI Xinhao, WANG Yi, et al. VideoMamba: State space model for efficient video understanding[C]. The 18th European Conference on Computer Vision – ECCV 2024, Milan, Italy, 2025: 237–255. doi: 10.1007/978-3-031-73347-5_14.
|
| [19] |
LEE S H, SON T, SEO S W, et al. JARViS: Detecting actions in video using unified actor-scene context relation modeling[J]. Neurocomputing, 2024, 610: 128616. doi: 10.1016/j.neucom.2024.128616.
|
| [20] |
REKA A, BORZA D L, REILLY D, et al. Introducing gating and context into temporal action detection[C]. The Computer Vision – ECCV 2024 Workshops, Milan, Italy, 2025: 322–334. doi: 10.1007/978-3-031-91581-9_23.
|
| [21] |
KWON D, KIM I, and KWAK S. Boosting semi-supervised video action detection with temporal context[C]. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision, Tucson, USA, 2025: 847–858. doi: 10.1109/WACV61041.2025.00092.
|
| [22] |
ZHOU Xuyang, WANG Ye, TAO Fei, et al. Hierarchical chat-based strategies with MLLMs for Spatio-temporal action detection[J]. Information Processing & Management, 2025, 62(4): 104094. doi: 10.1016/j.ipm.2025.104094.
|
| [23] |
Köpüklü O, WEI Xiangyu, and RIGOLL G. You only watch once: A unified CNN architecture for real-time spatiotemporal action localization[J]. arXiv preprint arXiv: 1911.06644, 2019.
|
| [24] |
JIANG Zhiqiang, YANG Jianhua, JIANG Nan, et al. YOWOv2: A stronger yet efficient multi-level detection framework for real-time spatio-temporal action detection[C]. The 17th International Conference on Intelligent Robotics and Applications, Xi’an, China, 2025: 33–48. doi: 10.1007/978-981-96-0774-7_3.
|
| [25] |
NGUYEN D D M, NHAN B D, WANG J C, et al. YOWOv3: An efficient and generalized framework for spatiotemporal action detection[J]. IEEE Intelligent Systems, 2026, 41(1): 75–85. doi: 10.1109/MIS.2025.3581100.
|
| [26] |
VARGHESE R and M. S. YOLOv8: A novel object detection algorithm with enhanced performance and robustness[C]. 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 2024: 1–6. doi: 10.1109/ADICS58448.2024.10533619.
|
| [27] |
LIU Ze, NING Jia, CAO Yue, et al. Video swin transformer[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 3192–3201. doi: 10.1109/CVPR52688.2022.00320.
|
| [28] |
XIAO Haoke, TANG Lv, JIANG Pengtao, et al. Boosting vision state space model with fractal scanning[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 8646–8654. doi: 10.1609/aaai.v39i8.32934.
|
| [29] |
SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[J]. arXiv preprint arXiv: 1212.0402, 2012.
|
| [30] |
KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: A large video database for human motion recognition[C]. 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2556–2563. doi: 10.1109/ICCV.2011.6126543.
|
| [31] |
LI Yixuan, WANG Zixu, WANG Limin, et al. Actions as moving points[C]. The 16th European Conference on Computer Vision – ECCV 2020, Glasgow, UK, 2020: 68–84. doi: 10.1007/978-3-030-58517-4_5.
|
| [32] |
LI Yuxi, LIN Weiyao, WANG Tao, et al. Finding action tubes with a sparse-to-dense framework[C]. The 34th AAAI Conference on Artificial Intelligence, New York Hilton Midtown, USA, 2020: 11466–11473. doi: 10.1609/aaai.v34i07.6811.
|
| [33] |
MA Xurui, LUO Zhigang, ZHANG Xiang, et al. Spatio-temporal action detector with self-attention[C]. 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 2021: 1–8. doi: 10.1109/IJCNN52387.2021.9533300.
|
| [34] |
ZHAO Jiaojiao, ZHANG Yanyi, LI Xinyu, et al. TubeR: Tubelet transformer for video action detection[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 13588–13597. doi: 10.1109/CVPR52688.2022.01323.
|
| [35] |
FAURE G J, CHEN M H, and LAI Shanghong. Holistic interaction transformer network for action detection[C]. The IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 3329–3339. doi: 10.1109/WACV56688.2023.00334.
|
| [36] |
CHEN Lei, TONG Zhan, SONG Yibing, et al. Efficient video action detection with token dropout and context refinement[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 10354–10365. doi: 10.1109/ICCV51070.2023.00953.
|
| [37] |
WU Tao, CAO Mengqi, GAO Ziteng, et al. STMixer: A one-stage sparse action detector[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 14720–14729. doi: 10.1109/CVPR52729.2023.01414.
|
| [38] |
SU Shaowen and GAN Minggang. Online spatio-temporal action detection with adaptive sampling and hierarchical modulation[J]. Multimedia Systems, 2024, 30(6): 349. doi: 10.1007/s00530-024-01543-1.
|
| [39] |
QIN Yefeng, CHEN Lei, BEN Xianye, et al. You watch once more: A more effective CNN architecture for video spatio-temporal action localization[J]. Multimedia Systems, 2024, 30(1): 53. doi: 10.1007/s00530-023-01254-z.
|
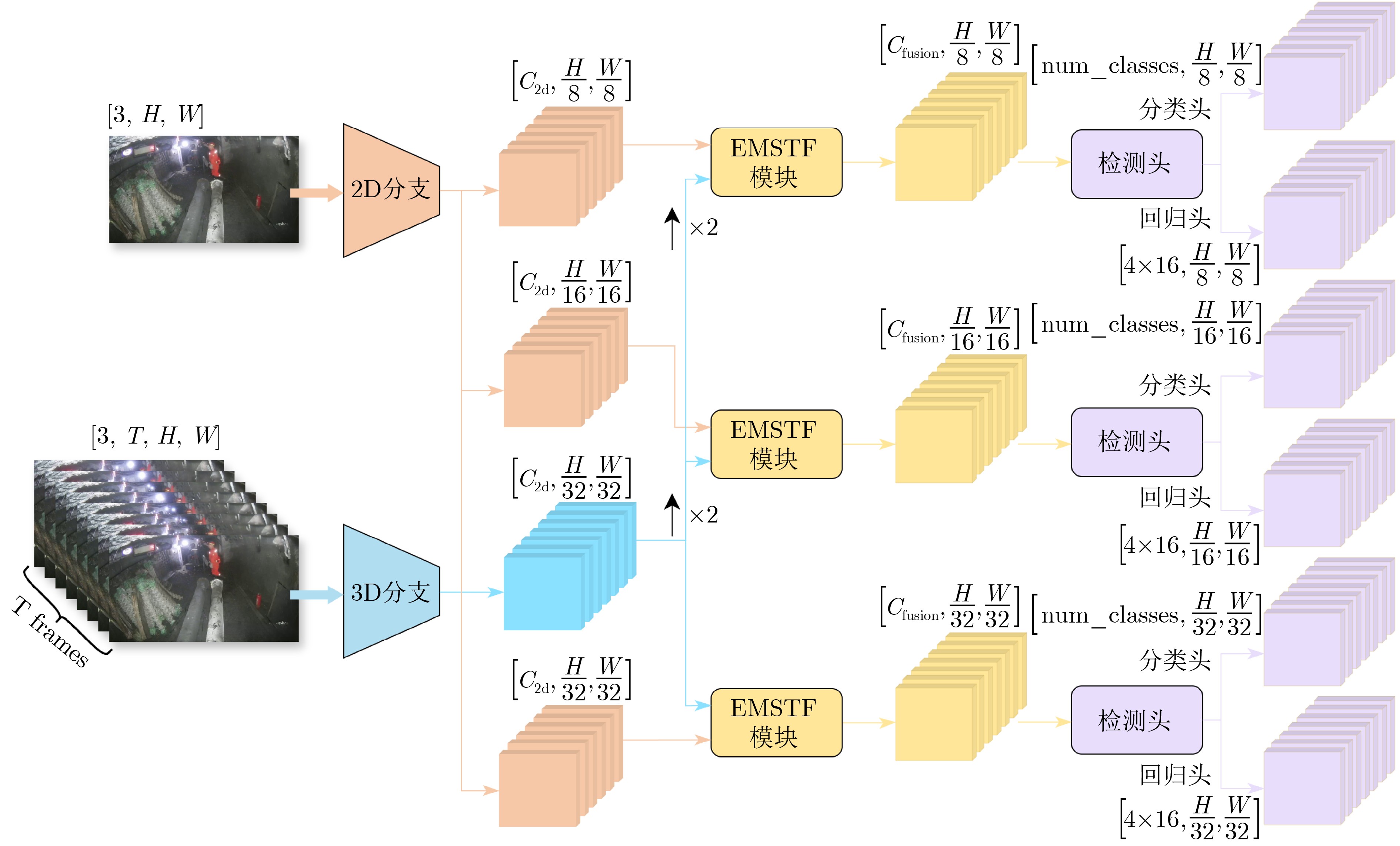
Figures(7) / Tables(3)



 DownLoad:
DownLoad: