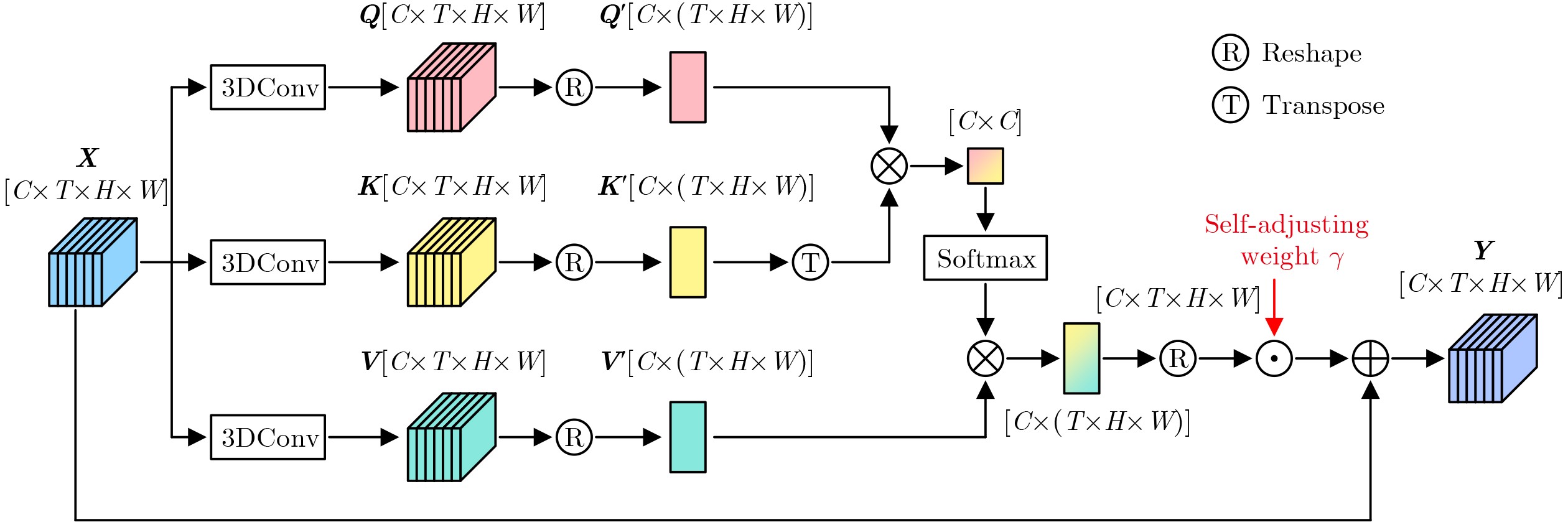
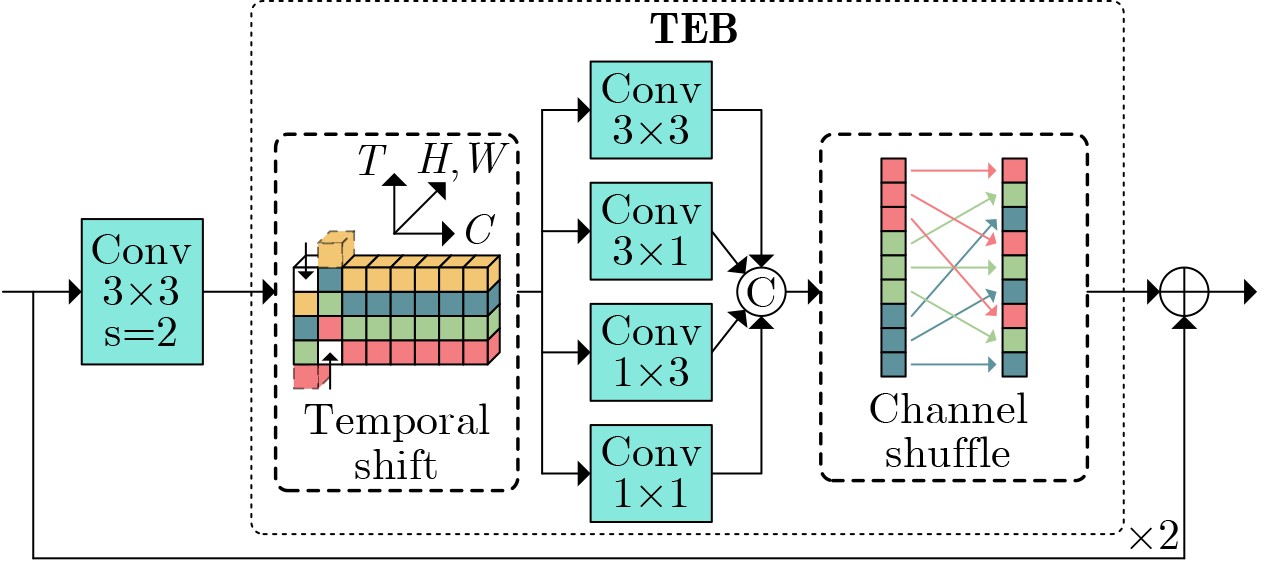
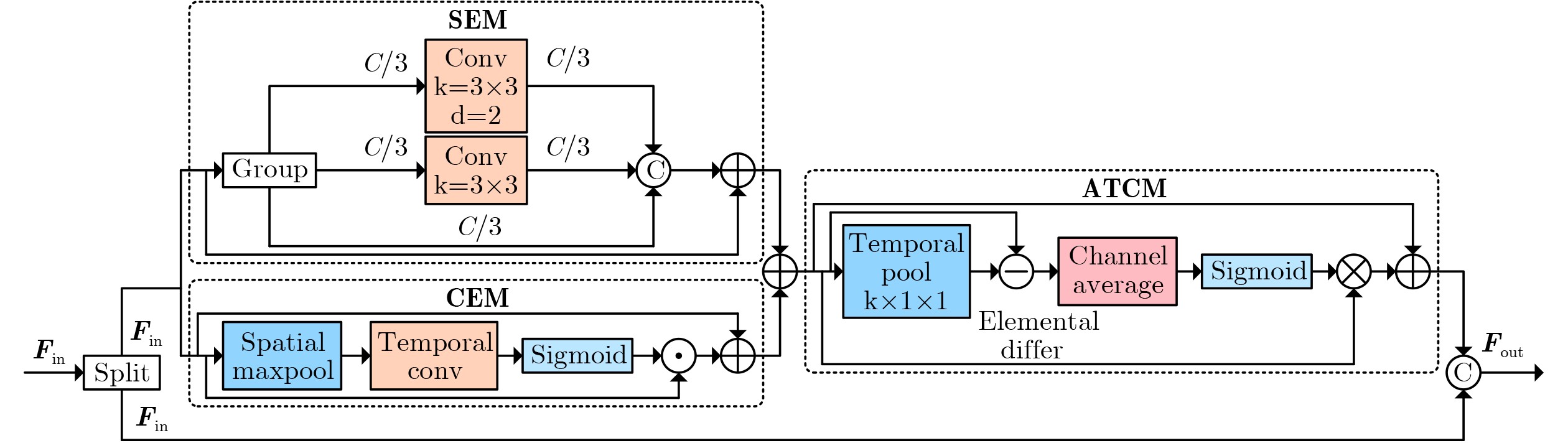
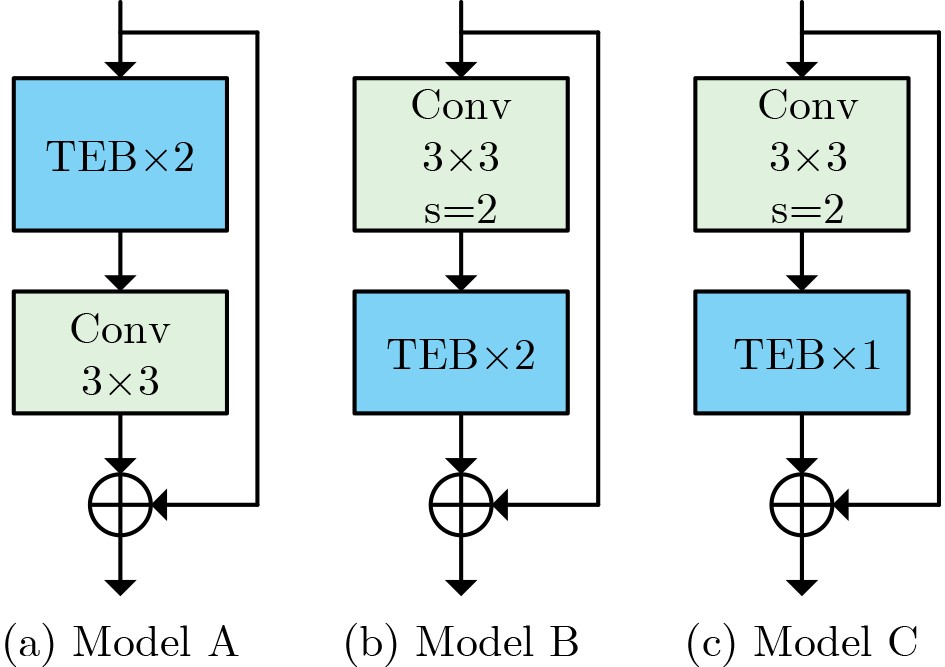
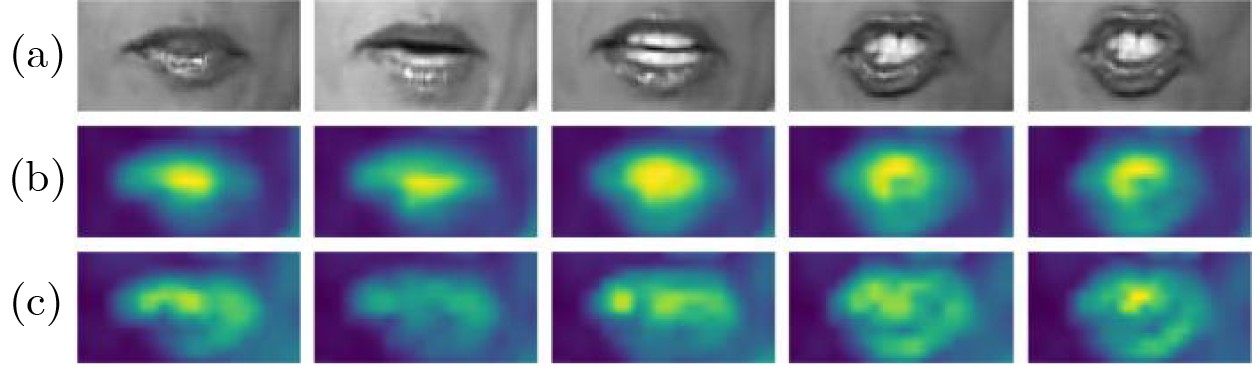
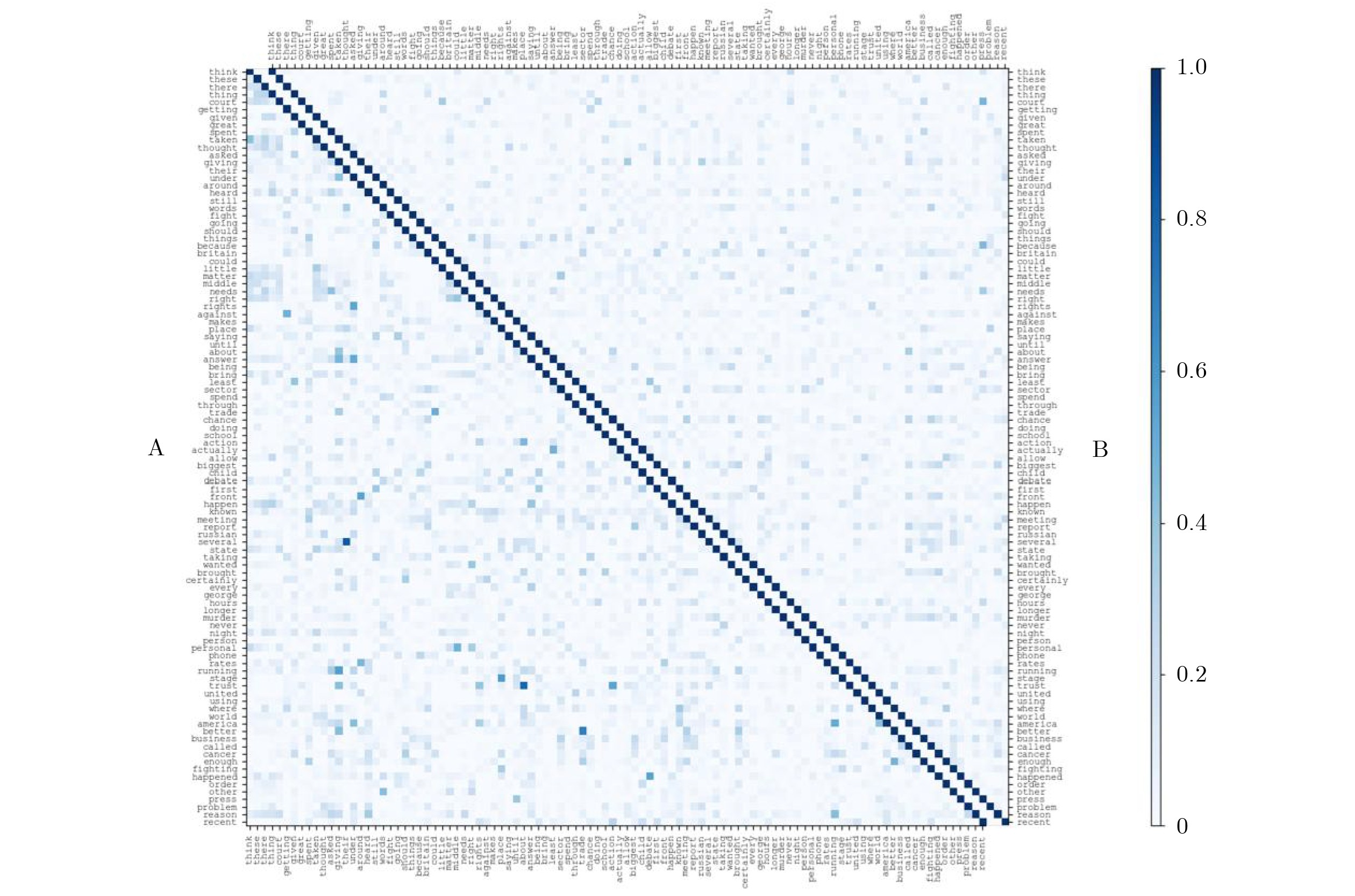
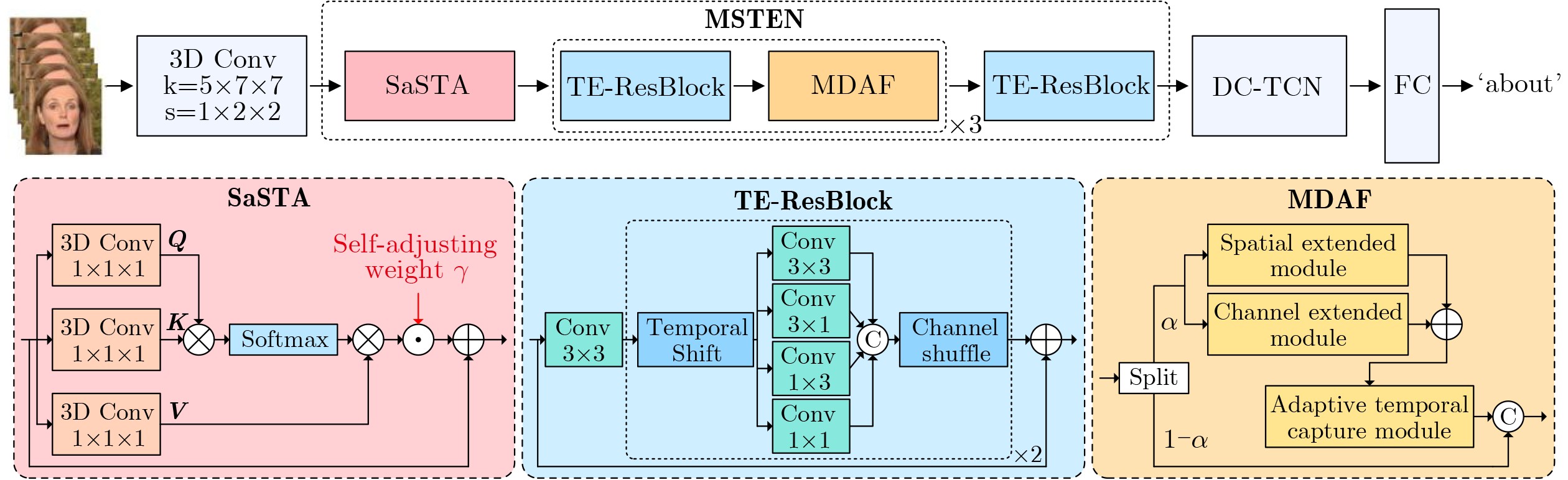
| Citation: | MA JinLin, ZHONG YaoWei, MA RuiShi. Multi-dimensional Spatio-temporal Features Enhancement for Lip reading[J]. Journal of Electronics & Information Technology. doi: 10.11999/JEIT251111

|

| [1] |
NODA K, YAMAGUCHI Y, NAKADAI K, et al. Lipreading using convolutional neural network[C]. 15th Annual Conference of the International Speech Communication Association, Singapore, Singapore, 2014: 1149–1153. doi: 10.21437/Interspeech.2014-293.
|
| [2] |
ASSAEL Y M, SHILLINGFORD B, WHITESON S, et al. LipNet: End-to-end sentence-level lipreading[EB/OL]. https://arxiv.org/abs/1611.01599, 2016.
|
| [3] |
JEON S, ELSHARKAWY A, and KIM M S. Lipreading architecture based on multiple convolutional neural networks for sentence-level visual speech recognition[J]. Sensors, 2021, 22(1): 72. doi: 10.3390/s22010072.
|
| [4] |
韩宗旺, 杨涵, 吴世青, 等. 时空自适应图卷积与Transformer结合的动作识别网络[J]. 电子与信息学报, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.
HAN Zongwang, YANG Han, WU Shiqing, et al. Action recognition network combining spatio-temporal adaptive graph convolution and Transformer[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.
|
| [5] |
STAFYLAKIS T and TZIMIROPOULOS G. Combining residual networks with LSTMs for lipreading[C]. 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 2017: 3652–3656. doi: 10.21437/Interspeech.2017-85.
|
| [6] |
MARTINEZ B, MA Pingchuan, PETRIDIS S, et al. Lipreading using temporal convolutional networks[C]. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 6319–6323. doi: 10.1109/ICASSP40776.2020.9053841.
|
| [7] |
CHUNG J S and ZISSERMAN A. Lip reading in the wild[C]. Proceedings of 13th Asian Conference on Computer Vision on Computer Vision – ACCV 2016, Taipei, China, 2017: 87–103. doi: 10.1007/978-3-319-54184-6_6.
|
| [8] |
MA Pingchuan, WANG Yujiang, SHEN Jie, et al. Lip-reading with densely connected temporal convolutional networks[C]. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2021: 2856–2865. doi: 10.1109/WACV48630.2021.00290.
|
| [9] |
XU Bo, LU Cheng, GUO Yandong, et al. Discriminative multi-modality speech recognition[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 14421–14430. doi: 10.1109/CVPR42600.2020.01444.
|
| [10] |
王春丽, 李金絮, 高玉鑫, 等. 一种基于时空频多维特征的短时窗口脑电听觉注意解码网络[J]. 电子与信息学报, 2025, 47(3): 814–824. doi: 10.11999/JEIT240867.
WANG Chunli, LI Jinxu, GAO Yuxin, et al. A short-time window electroencephalogram auditory attention decoding network based on multi-dimensional characteristics of temporal-spatial-frequency[J]. Journal of Electronics & Information Technology, 2025, 47(3): 814–824. doi: 10.11999/JEIT240867.
|
| [11] |
孙强, 陈远. 多层次时空特征自适应集成与特有-共享特征融合的双模态情感识别[J]. 电子与信息学报, 2024, 46(2): 574–587. doi: 10.11999/JEIT231110.
SUN Qiang and CHEN Yuan. Bimodal emotion recognition with adaptive integration of multi-level spatial-temporal features and specific-shared feature fusion[J]. Journal of Electronics & Information Technology, 2024, 46(2): 574–587. doi: 10.11999/JEIT231110.
|
| [12] |
马金林, 吕鑫, 马自萍, 等. 微运动激励与时间感知的唇语识别方法[J]. 电子学报, 2024, 52(11): 3657–3668. doi: 10.12263/DZXB.20230888.
MA Jinlin, LYU Xin, MA Ziping, et al. Micro-motion excitation and time perception for lip reading[J]. Acta Electronica Sinica, 2024, 52(11): 3657–3668. doi: 10.12263/DZXB.20230888.
|
| [13] |
丁建睿, 张听, 刘家栋, 等. 融合邻域注意力和状态空间模型的医学视频分割算法[J]. 电子与信息学报, 2025, 47(5): 1582–1595. doi: 10.11999/JEIT240755.
DING Jianrui, ZHANG Ting, LIU Jiadong, et al. A medical video segmentation algorithm integrating neighborhood attention and state space model[J]. Journal of Electronics & Information Technology, 2025, 47(5): 1582–1595. doi: 10.11999/JEIT240755.
|
| [14] |
WEI Dafeng, TIAN Ye, WEI Liqing, et al. Efficient dual attention slowfast networks for video action recognition[J]. Computer Vision and Image Understanding, 2022, 222: 103484. doi: 10.1016/j.cviu.2022.103484.
|
| [15] |
LIN Ji, GAN Chuang, and HAN Song. TSM: Temporal shift module for efficient video understanding[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 7082–7092. doi: 10.1109/ICCV.2019.00718.
|
| [16] |
ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6848–6856. doi: 10.1109/CVPR.2018.00716.
|
| [17] |
WANG Bin, CHANG Faliang, LIU Chunsheng, et al. An efficient motion visual learning method for video action recognition[J]. Expert Systems with Applications, 2024, 255: 124596. doi: 10.1016/j.eswa.2024.124596.
|
| [18] |
COOKE M, BARKER J, CUNNINGHAM S, et al. An audio-visual corpus for speech perception and automatic speech recognition[J]. The Journal of the Acoustical Society of America, 2006, 120(5): 2421–2424. doi: 10.1121/1.2229005.
|
| [19] |
KIM M, YEO J H, and RO Y M. Distinguishing homophenes using multi-head visual-audio memory for lip reading[C]. Proceedings of the 36th AAAI Conference on Artificial Intelligence, 2022: 1174–1182. doi: 10.1609/aaai.v36i1.20003. (查阅网上资料,未找到本条文献出版地信息,请确认).
|
| [20] |
XUE Junxiao, HUANG Shibo, SONG Huawei, et al. Fine-grained sequence-to-sequence lip reading based on self-attention and self-distillation[J]. Frontiers of Computer Science, 2023, 17(6): 176344. doi: 10.1007/s11704-023-2230-x.
|
| [21] |
马金林, 刘宇灏, 马自萍, 等. HSKDLR: 同类自知识蒸馏的轻量化唇语识别方法[J]. 计算机科学与探索, 2023, 17(11): 2689–2702. doi: 10.3778/j.issn.1673-9418.2208032.
MA Jinlin, LIU Yuhao, MA Ziping, et al. HSKDLR: Lightweight lip reading method based on homogeneous self-knowledge distillation[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(11): 2689–2702. doi: 10.3778/j.issn.1673-9418.2208032.
|
| [22] |
马金林, 刘宇灏, 马自萍, 等. 解耦同类自知识蒸馏的轻量化唇语识别方法[J]. 北京航空航天大学学报, 2024, 50(12): 3709–3719. doi: 10.13700/j.bh.1001-5965.2022.0931.
MA Jinlin, LIU Yuhao, MA Ziping, et al. Lightweight lip reading method based on decoupling homogeneous self-knowledge distillation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(12): 3709–3719. doi: 10.13700/j.bh.1001-5965.2022.0931.
|
| [23] |
SHENG Changchong, PIETIKÄINEN M, TIAN Qi, et al. Cross-modal self-supervised learning for lip reading: When contrastive learning meets adversarial training[C]. Proceedings of the 29th ACM International Conference on Multimedia, 2021: 2456–2464. doi: 10.1145/3474085.3475415. (查阅网上资料,未找到本条文献出版地信息,请确认).
|
| [24] |
MA Pingchuan, MIRA R, PETRIDIS S, et al. LiRA: Learning visual speech representations from audio through self-supervision[C]. 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 2021: 3011–3015. doi: 10.21437/Interspeech.2021-1360.
|
| [25] |
PAN Xichen, CHEN Peiyu, GONG Yichen, et al. Leveraging unimodal self-supervised learning for multimodal audio-visual speech recognition[EB/OL]. https://arxiv.org/abs/2203.07996, 2022.
|
| [26] |
JIANG Junxia, ZHAO Zhongqiu, YANG Yi, et al. GSLip: A global lip-reading framework with solid dilated convolutions[C]. 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 2024: 1–8. doi: 10.1109/IJCNN60899.2024.10651423.
|
| [27] |
CHEN Hang, WANG Qing, DU Jun, et al. Collaborative viseme subword and end-to-end modeling for word-level lip reading[J]. IEEE Transactions on Multimedia, 2024, 26: 9358–9371. doi: 10.1109/TMM.2024.3390148.
|
| [28] |
马金林, 郭兆伟, 马自萍, 等. 多尺度门控时空增强的唇语识别方法[J]. 计算机辅助设计与图形学学报, 2025, 37(7): 1228–1238. doi: 10.3724/SP.J.1089.2023-00478.
MA Jinlin, GUO Zhaowei, MA Ziping, et al. Multi-scale gated spatio-temporal enhancement for lip recognition[J]. Journal of Computer-Aided Design & Computer Graphics, 2025, 37(7): 1228–1238. doi: 10.3724/SP.J.1089.2023-00478.
|
| [29] |
KIM M, KIM H, and RO Y M. Speaker-adaptive lip reading with user-dependent padding[C]. Proceedings of 17th European Conference on Computer Vision – ECCV 2022, Tel Aviv, Israel, 2022: 576–593. doi: 10.1007/978-3-031-20059-5_33.
|
| [30] |
LIU Jinglin, REN Yi, ZHAO Zhou, et al. FastLR: Non-autoregressive lipreading model with integrate-and-fire[C]. Proceedings of the 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 4328–4336. doi: 10.1145/3394171.3413740.
|
| [31] |
XU Kai, LI Dawei, CASSIMATIS N, et al. LCANet: End-to-end lipreading with cascaded attention-CTC[C]. 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 2018: 548–555. doi: 10.1109/FG.2018.00088.
|
| [32] |
RASTOGI A, AGARWAL R, GUPTA V, et al. LRNeuNet: An attention based deep architecture for lipreading from multitudinous sized videos[C]. 2019 International Conference on Computing, Power and Communication Technologies (GUCON), New Delhi, India, 2019: 1001–1007.
|
| [33] |
JEEVAKUMARI S A A and DEY K. LipSyncNet: A novel deep learning approach for visual speech recognition in audio-challenged situations[J]. IEEE Access, 2024, 12: 110891–110904. doi: 10.1109/ACCESS.2024.3436931.
|
Figures(8) / Tables(6)


 DownLoad:
DownLoad: