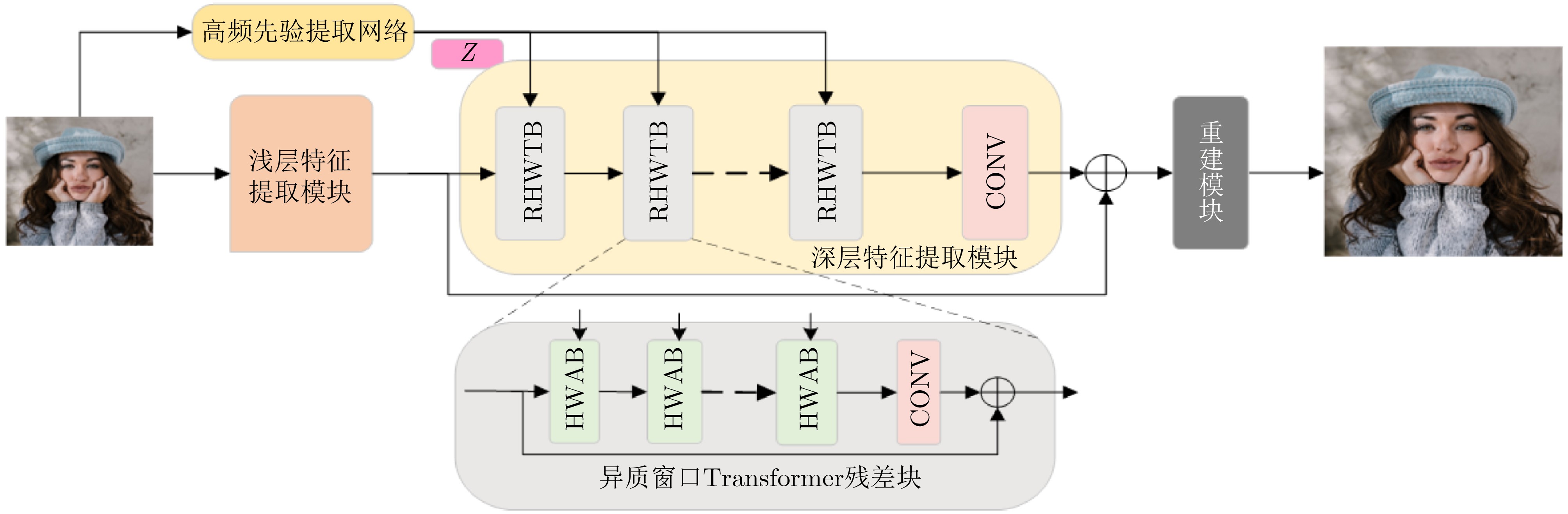
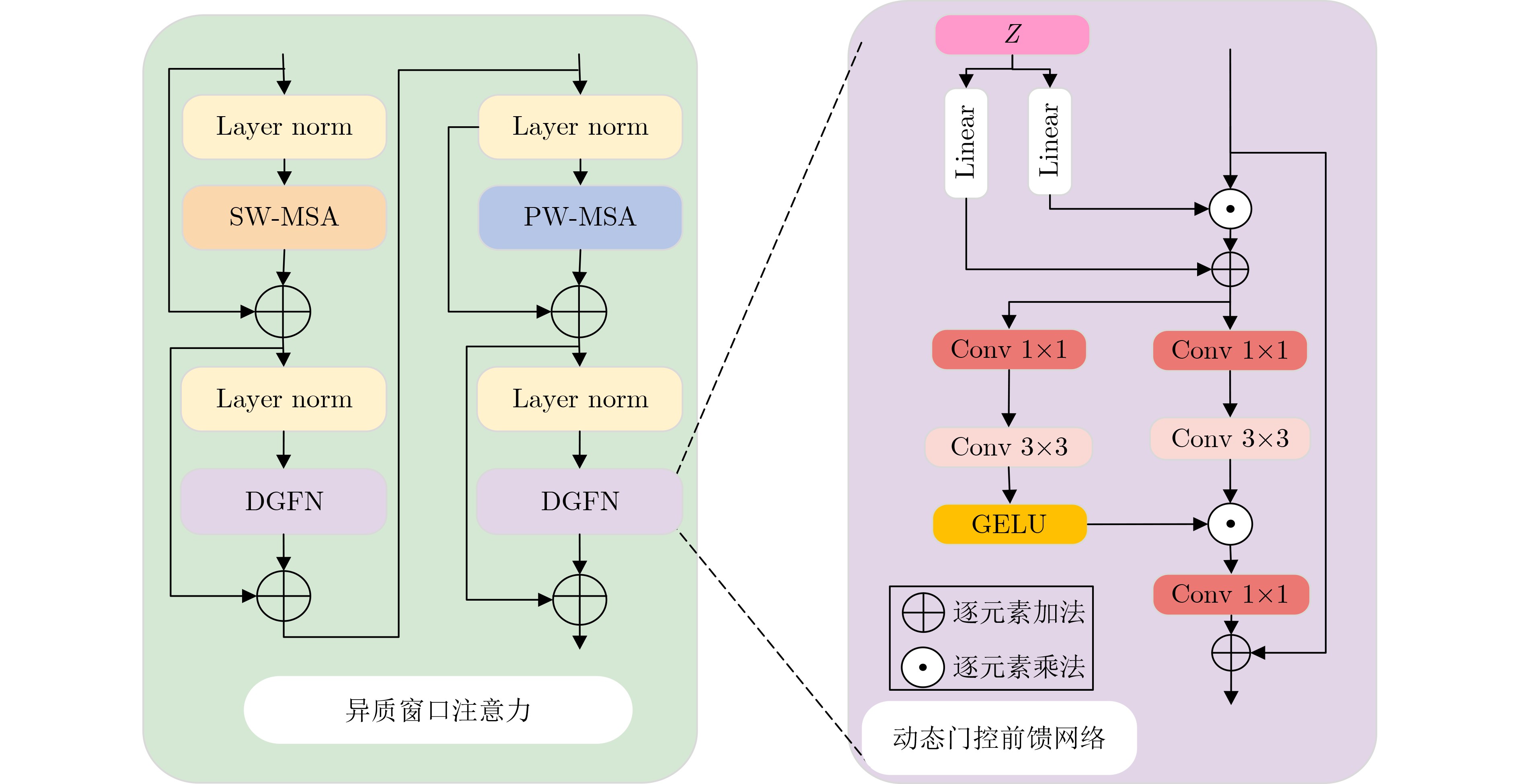
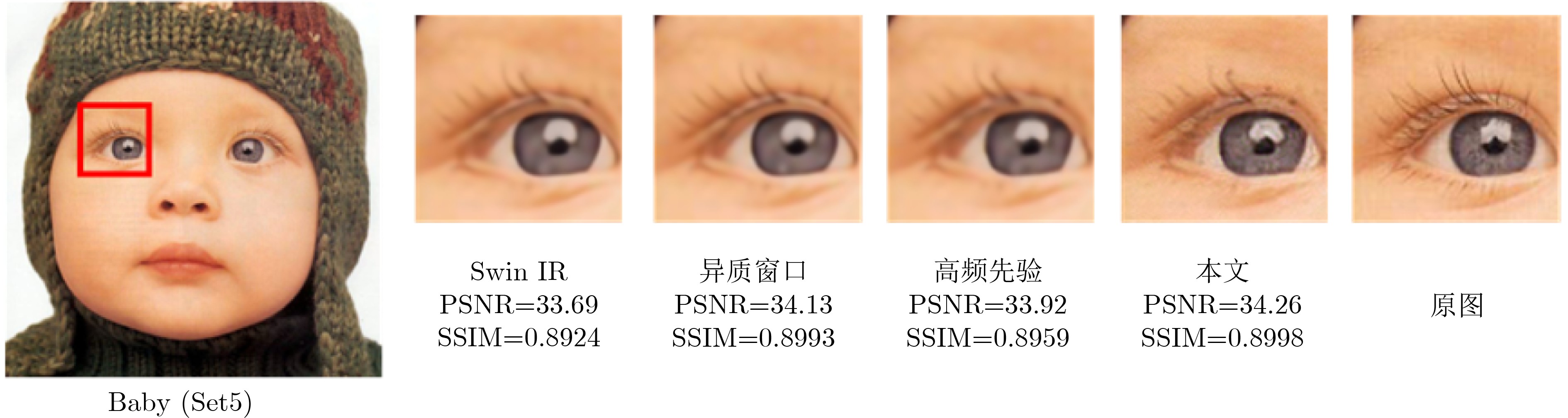
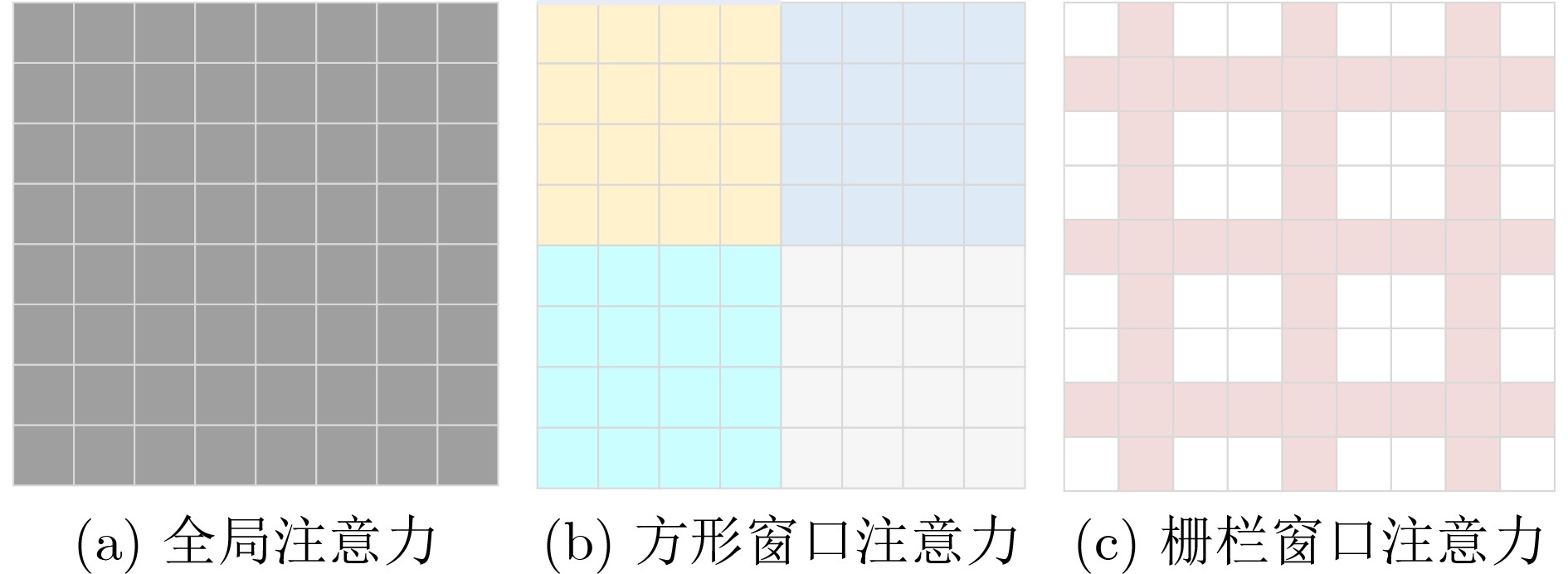
| Citation: | LU Di, DANG Anyuan. HWT-SRNet: Heterogeneous Windows Transformer Network for Image Super-Resolution[J]. Journal of Electronics & Information Technology. doi: 10.11999/JEIT250868

|

| [1] |
DONG Chao, LOY C C, HE Kaiming, et al. Learning a deep convolutional network for image super-resolution[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 184–199. doi: 10.1007/978-3-319-10593-2_13.
|
| [2] |
DONG Chao, LOY C C, and TANG Xiaoou. Accelerating the super-resolution convolutional neural network[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 391–407. doi: 10.1007/978-3-319-46475-6_25.
|
| [3] |
ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 294–310. doi: 10.1007/978-3-030-01234-2_18.
|
| [4] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, Vienna, Austria, 2021: 1–21.
|
| [5] |
LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. The 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 9992–10002. doi: 10.1109/ICCV48922.2021.00986.
|
| [6] |
LIANG Jingyun, CAO Jiezhang, SUN Guolei, et al. SwinIR: Image restoration using Swin transformer[C]. The 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, Canada, 2021: 1833–1844. doi: 10.1109/ICCVW54120.2021.00210.
|
| [7] |
CHEN Zheng, ZHANG Yulun, GU Jinjin, et al. Cross aggregation transformer for image restoration[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1847.
|
| [8] |
SHI Jinpeng, LI Hui, LIU Tianle, et al. Image super-resolution using efficient striped window transformer[EB/OL]. https://arxiv.org/abs/2301.09869, 2023.
|
| [9] |
WU Sitong, WU Tianyi, TAN Haoru, et al. Pale transformer: A general vision transformer backbone with pale-shaped attention[C]. The 36th AAAI Conference on Artificial Intelligence, Palo Alto, USA, 2022: 2731–2739. doi: 10.1609/aaai.v36i3.20176.
|
| [10] |
WU Gang, JIANG Junjun, JIANG Kui, et al. Content-aware transformer for all-in-one image restoration[EB/OL]. https://arxiv.org/abs/2504.04869v1, 2025.
|
| [11] |
ZHANG Jiale, ZHANG Yulun, GU Jinjin, et al. Accurate image restoration with attention retractable transformer[C]. The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 2023: 1–13.
|
| [12] |
CHEN Zheng, ZHANG Yulun, GU Jinjin, et al. Recursive generalization transformer for image super-resolution[C]. The Twelfth International Conference on Learning Representations, Vienna, Austria, 2024: 1–12.
|
| [13] |
CHU Shuchuan, DOU Zhichao, PAN J S, et al. HMANet: Hybrid multi-axis aggregation network for image super-resolution[C].The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, USA, 2024: 6257–6266. doi: 10.1109/CVPRW63382.2024.00629.
|
| [14] |
YOO J, KIM T, LEE S, et al. Enriched CNN-transformer feature aggregation networks for super-resolution[C]. The 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 4945–4954. doi: 10.1109/WACV56688.2023.00493.
|
| [15] |
SI Chenyang, YU Weihao, ZHOU Pan, et al. Inception transformer[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1707.
|
| [16] |
KORKMAZ C, TEKALP A M, and DOGAN Z. Training generative image super-resolution models by wavelet-domain losses enables better control of artifacts[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 5926–5936. doi: 10.1109/CVPR52733.2024.00566.
|
| [17] |
韩玉兰, 崔玉杰, 罗轶宏, 等. 基于密集残差和质量评估引导的频率分离生成对抗超分辨率重构网络[J]. 电子与信息学报, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388.
HAN Yulan, CUI Yujie, LUO Yihong, et al. Frequency separation generative adversarial super-resolution reconstruction network based on dense residual and quality assessment[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388.
|
| [18] |
LI Ao, ZHANG Le, LIU Yun, et al. Feature modulation transformer: Cross-refinement of global representation via high-frequency prior for image super-resolution[C]. The 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 12480–12490. doi: 10.1109/iccv51070.2023.01150.
|
| [19] |
YAO Hongdou, HAN Pengfei, WANG Xiaofen, et al. Super-resolution via hierarchical attention and detail enhancement transformer network[J]. Optics & Laser Technology, 2025, 188: 112836. doi: 10.1016/j.optlastec.2025.112836.
|
| [20] |
程德强, 袁航, 钱建生, 等. 基于深层特征差异性网络的图像超分辨率算法[J]. 电子与信息学报, 2024, 46(3): 1033–1042. doi: 10.11999/JEIT230179.
CHENG Deqiang, YUAN Hang, QIAN Jiansheng, et al. Image super-resolution algorithms based on deep feature differentiation network[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1033–1042. doi: 10.11999/JEIT230179.
|
| [21] |
寇旗旗, 刘规, 江鹤, 等. 基于多域信息增强的轻量级图像超分辨率网络[J]. 通信学报, 2025, 46(4): 144–159. doi: 10.11959/j.issn.1000-436x.2025059.
KOU Qiqi, LIU Gui, JIANG He, et al. Lightweight image super-resolution network based on muti-domain information enhancement[J]. Journal on Communications, 2025, 46(4): 144–159. doi: 10.11959/j.issn.1000-436x.2025059.
|
| [22] |
WANG Xintao, XIE Liangbin, DONG Chao, et al. Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data[C]. The 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, Canada, 2021: 1905–1914. doi: 10.1109/ICCVW54120.2021.00217.
|
| [23] |
WANG Yufei, YANG Wenhan, CHEN Xinyuan, et al. SinSR: Diffusion-based image super-resolution in a single step[C]. The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 25796–25805. doi: 10.1109/CVPR52733.2024.02437.
|
Figures(7) / Tables(5)


 DownLoad:
DownLoad: