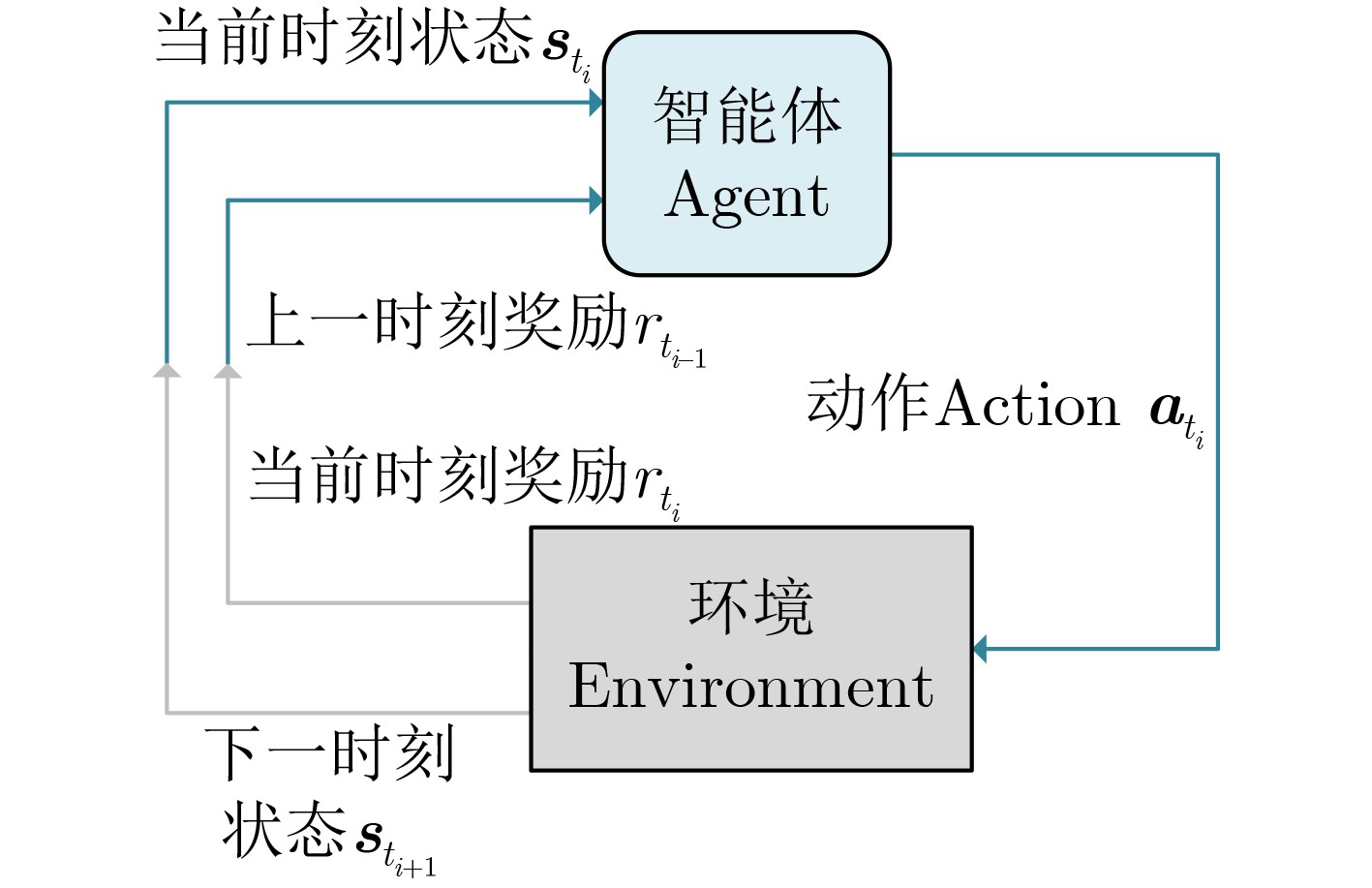
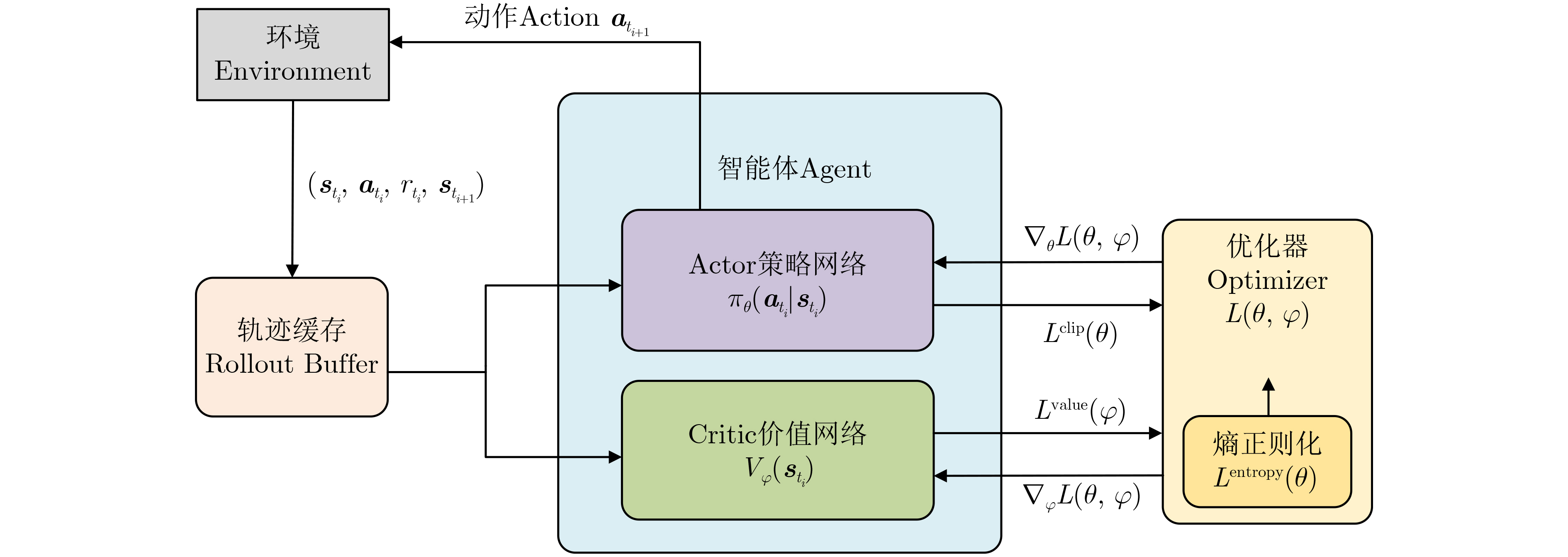
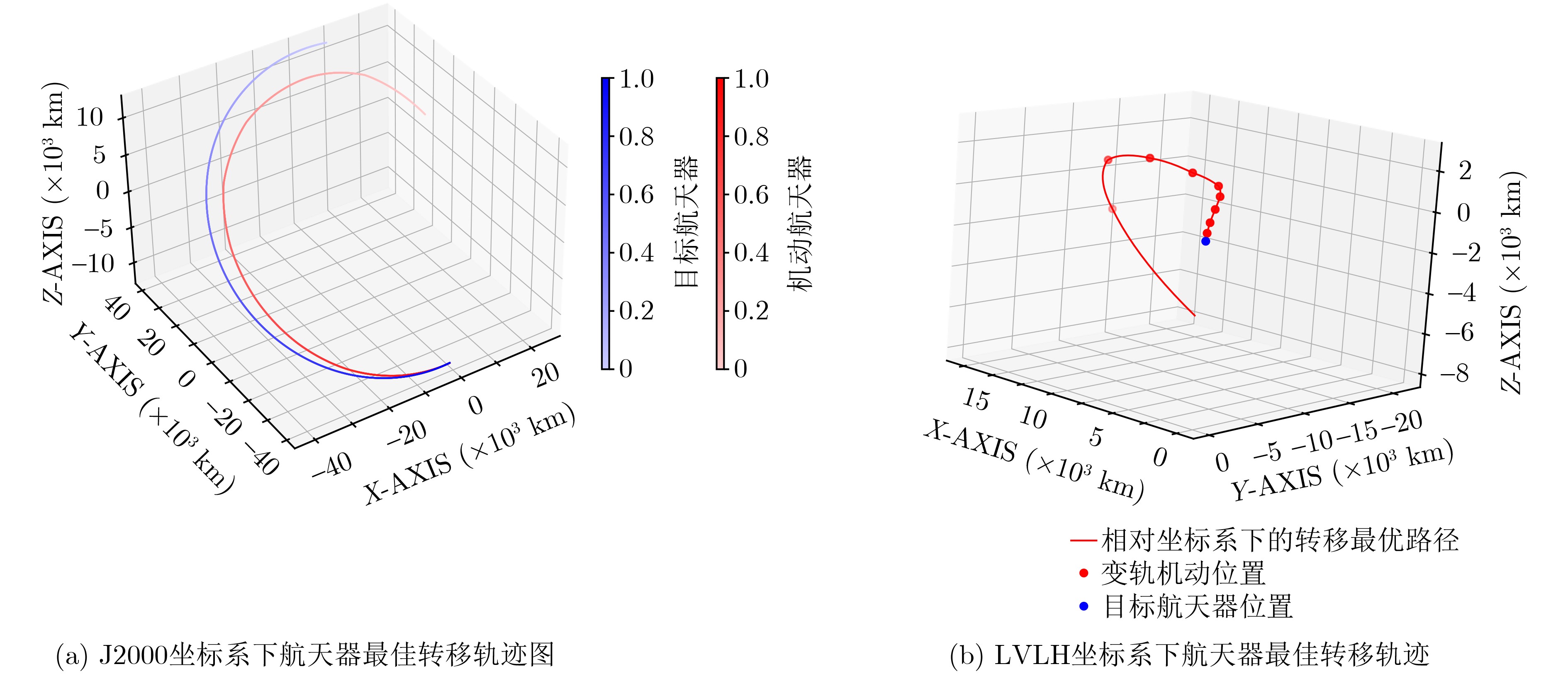
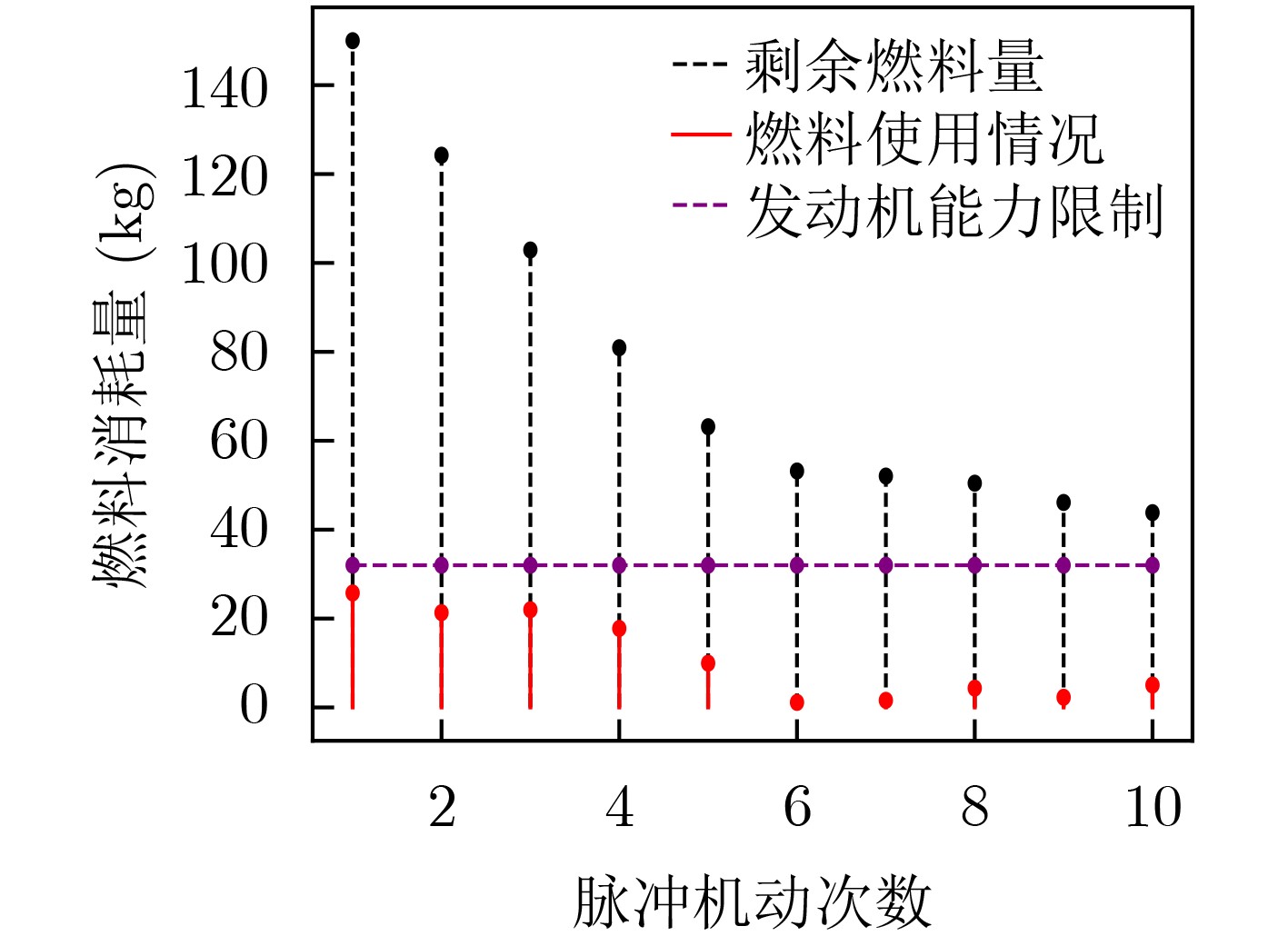
| Citation: | LIN Zheng, HU Haiying, DI Peng, ZHU Yongsheng, ZHOU Meijiang. Research on Proximal Policy Optimization for Autonomous Long-Distance Rapid Rendezvous of Spacecraft[J]. Journal of Electronics & Information Technology, 2026, 48(4): 1806-1819. doi: 10.11999/JEIT250844

|

| [1] |
LI Weijie, CHENG Dayi, LIU Xigang, et al. On-Orbit Service (OOS) of spacecraft: A review of engineering developments[J]. Progress in Aerospace Sciences, 2019, 108: 32–120. doi: 10.1016/j.paerosci.2019.01.004.
|
| [2] |
NALLAPU R T and THANGAVELAUTHAM J. Design and sensitivity analysis of spacecraft swarms for planetary moon reconnaissance through co-orbits[J]. Acta Astronautica, 2021, 178: 854–896. doi: 10.1016/j.actaastro.2020.10.008.
|
| [3] |
NIU Shangwei, LI Dongxu, and JI Haoran. Research on mission time planning and autonomous interception guidance method for low-thrust spacecraft in long-distance interception[C]. 2020 5th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 2020: 117–123. doi: 10.1109/CACRE50138.2020.9230051.
|
| [4] |
LEDKOV A and ASLANOV V. Review of contact and contactless active space debris removal approaches[J]. Progress in Aerospace Sciences, 2022, 134: 100858. doi: 10.1016/j.paerosci.2022.100858.
|
| [5] |
陈宏宇, 吴会英, 周美江, 等. 微小卫星轨道工程应用与STK仿真[M]. 北京: 科学出版社, 2016.
CHEN Hongyu, WU Huiying, ZHOU Meijiang, et al. Orbit Engineering Application and STK Simulation for Microsatellite[M]. Beijing: Science Press, 2016.
|
| [6] |
ABDELKHALIK O and MORTARI D. N-impulse orbit transfer using genetic algorithms[J]. Journal of Spacecraft and Rockets, 2007, 44(2): 456–460. doi: 10.2514/1.24701.
|
| [7] |
PONTANI M, GHOSH P, and CONWAY B A. Particle swarm optimization of multiple-burn rendezvous trajectories[J]. Journal of Guidance, Control, and Dynamics, 2012, 35(4): 1192–1207. doi: 10.2514/1.55592.
|
| [8] |
YU Jing, CHEN Xiaoqian, CHEN Lihu, et al. Optimal scheduling of GEO debris removing based on hybrid optimal control theory[J]. Acta Astronautica, 2014, 93: 400–409. doi: 10.1016/j.actaastro.2013.07.015.
|
| [9] |
MNIH V, KAVUKKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. https://arxiv.org/abs/1312.5602, 2013.
|
| [10] |
DONG Zhicai, ZHU Yiman, WANG Lu, et al. Motion planning of free-floating space robots for tracking tumbling targets by two-axis matching via reinforcement learning[J]. Aerospace Science and Technology, 2024, 155: 109540. doi: 10.1016/j.ast.2024.109540.
|
| [11] |
TIWARI M, PRAZENICA R, and HENDERSON T. Direct adaptive control of spacecraft near asteroids[J]. Acta Astronautica, 2023, 202: 197–213. doi: 10.1016/j.actaastro.2022.10.014.
|
| [12] |
SCORSOGLIO A, FURFARO R, LINARES R, et al. Relative motion guidance for near-rectilinear lunar orbits with path constraints via actor-critic reinforcement learning[J]. Advances in Space Research, 2023, 71(1): 316–335. doi: 10.1016/j.asr.2022.08.002.
|
| [13] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. https://arxiv.org/abs/1707.06347, 2017.
|
| [14] |
王禄丰, 李爽. J2摄动下非线性轨道不确定性传播方法[C]. 2024年中国航天大会论文集, 武汉, 2024: 59–64. doi: 10.26914/c.cnkihy.2024.081107.
WANG Lufeng and LI Shuang. Nonlinear orbit uncertainty propagation method under J2 perturbation[C]. 2024 China Aerospace Congress, Wuhan, 2024: 59–64. doi: 10.26914/c.cnkihy.2024.081107.
|
| [15] |
孙盼, 李爽. 连续方程与高斯和框架下轨道不确定性传播方法综述[J]. 中国科学: 物理学 力学 天文学, 2025, 55(9): 294501. doi: 10.1360/SSPMA-2024-0300.
SUN Pan and LI Shuang. A review of uncertainty propagation methods within continuity equation and Gaussian mixture model frameworks[J]. SCIENTIA SINICA Physica, Mechanica & Astronomica, 2025, 55(9): 294501. doi: 10.1360/SSPMA-2024-0300.
|
| [16] |
BAILLIEUL J and SAMAD T. Encyclopedia of Systems and Control[M]. 2nd ed. Cham: Springer, 2021. doi: 10.1007/978-3-030-44184-5.
|
| [17] |
LANDERS M and DORYAB A. Deep reinforcement learning verification: A survey[J]. ACM Computing Surveys, 2023, 55(14s): 1–31. doi: 10.1145/3596444.
|
| [18] |
XU Haotian, XUAN Junyu, ZHANG Guangquan, et al. Trust region policy optimization via entropy regularization for Kullback-Leibler divergence constraint[J]. Neurocomputing, 2024, 589: 127716. doi: 10.1016/j.neucom.2024.127716.
|
| [19] |
IBRAHIM S, MOSTAFA M, JNADI A, et al. Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications[J]. IEEE Access, 2024, 12: 175473–175500. doi: 10.1109/access.2024.3504735.
|
| [20] |
PAOLO G, CONINX M, LAFLAQUIÈRE A, et al. Discovering and exploiting sparse rewards in a learned behavior space[J]. Evolutionary Computation, 2024, 32(3): 275–305. doi: 10.1162/evco_a_00343.
|
| [21] |
NG A Y, HARADA D, and RUSSELL S. Policy invariance under reward transformations: Theory and application to reward shaping[R]. 2016.
|
| [22] |
MONTENBRUCK O and GILL E. Satellite Orbits: Models, Methods and Applications[M]. Berlin: Springer, 2000. doi: 10.1007/978-3-642-58351-3.
|
| [23] |
ZAVOLI A and FEDERICI L. Reinforcement learning for robust trajectory design of interplanetary missions[J]. Journal of Guidance, Control, and Dynamics, 2021, 44(8): 1440–1453. doi: 10.2514/1.G005794.
|
Figures(10) / Tables(6)



 DownLoad:
DownLoad: