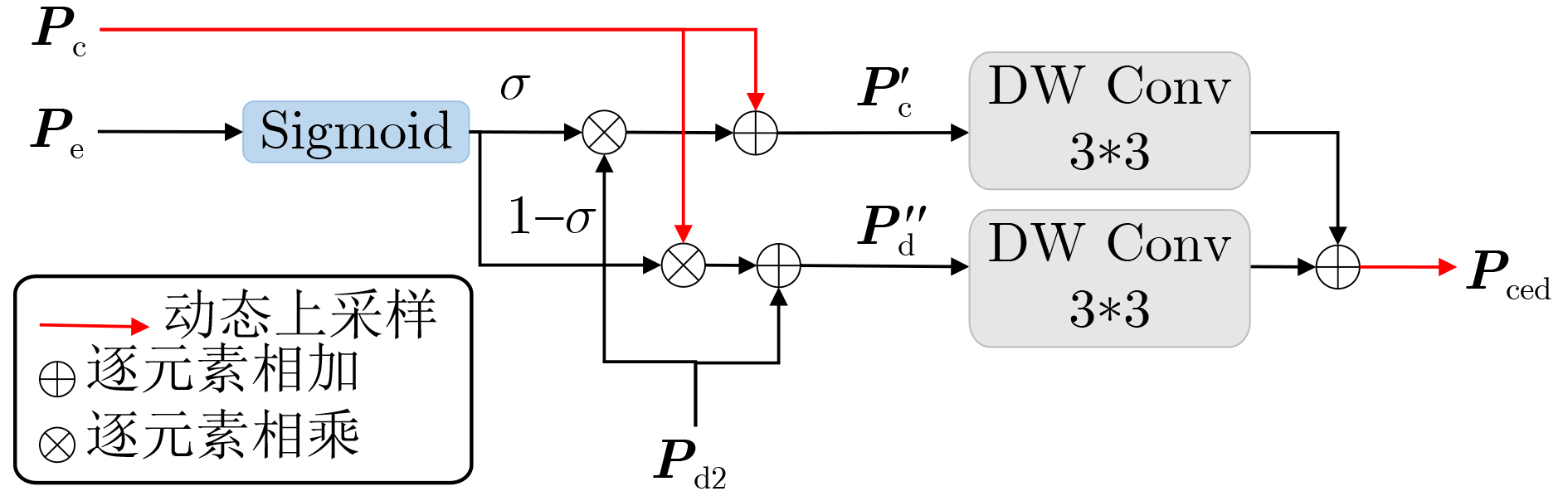
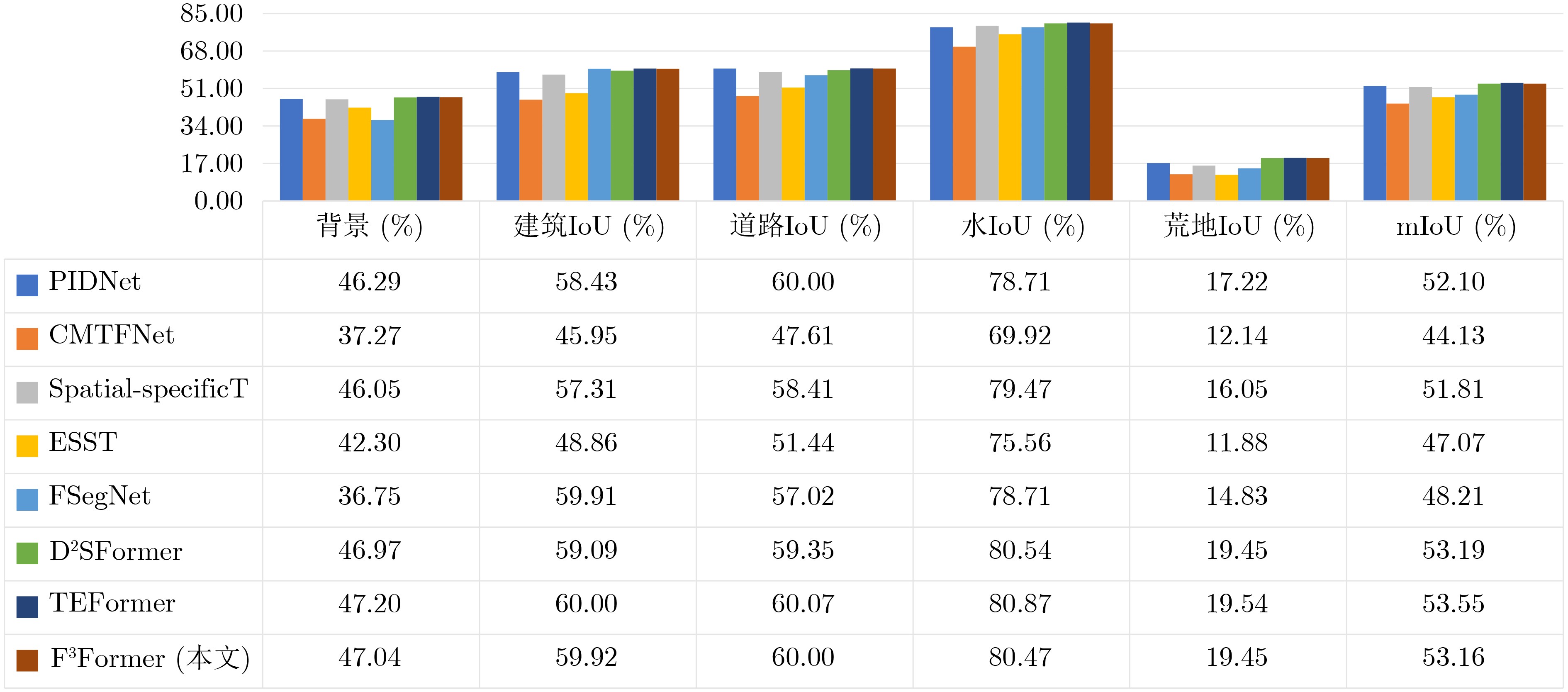
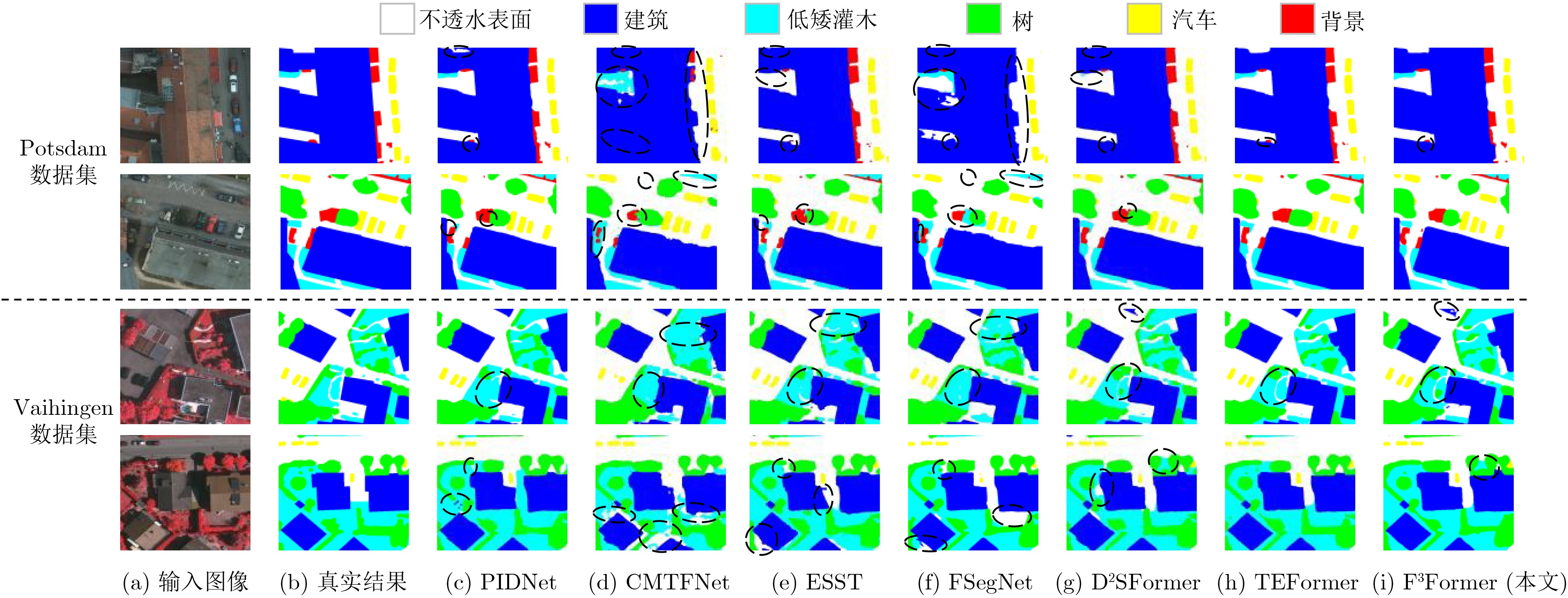
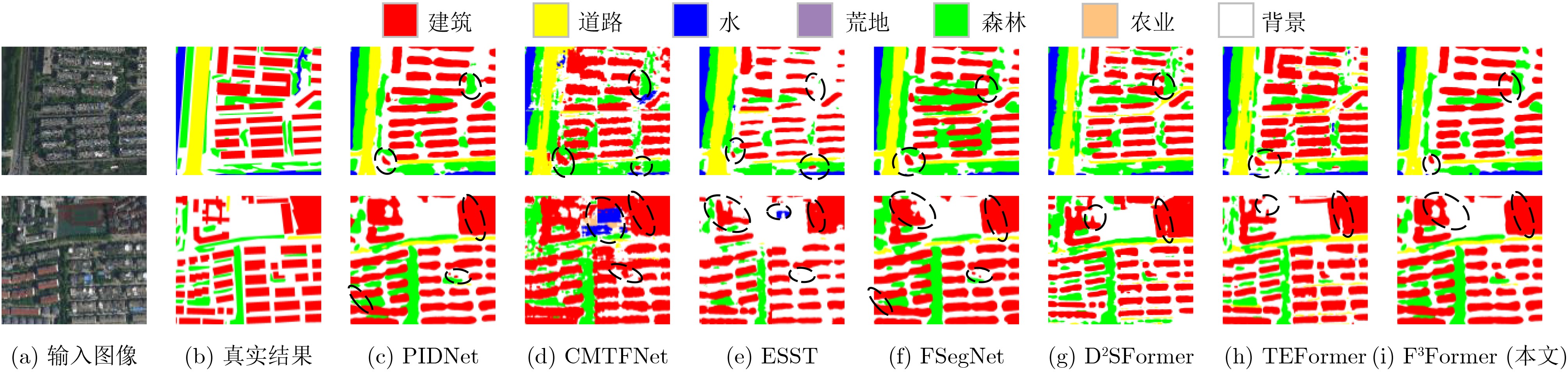
| Citation: | ZHOU Guoyu, ZHANG Jing, YAN Yi, ZHUO Li. A Focused Attention and Feature Compact Fusion Transformer for Semantic Segmentation of Urban Remote Sensing Images[J]. Journal of Electronics & Information Technology, 2025, 47(12): 4790-4800. doi: 10.11999/JEIT250812

|

| [1] |
北京市大数据工作推进小组. 北京市“十四五”时期智慧城市发展行动纲要[EB/OL]. https://www.beijing.gov.cn/zhengce/zhengcefagui/202103/t20210323_2317136.html, 2021.
Beijing Municipal Leading Group for Big Data. Action plan for the development of smart cities in beijing during the 14th five-year plan period[EB/OL]. https://www.beijing.gov.cn/zhengce/zhengcefagui/202103/t20210323_2317136.html, 2021.
|
| [2] |
KHAND K and SENAY G B. A web-based application for exploring potential changes in design peak flow of US urban areas driven by land cover change[J]. Journal of Remote Sensing, 2023, 3: 0037. doi: 10.34133/remotesensing.0037.
|
| [3] |
李彦胜, 武康, 欧阳松, 等. 地学知识图谱引导的遥感影像语义分割[J]. 遥感学报, 2024, 28(2): 455–469. doi: 10.11834/jrs.20231110.
LI Yansheng, WU Kang, OUYANG Song, et al. Geographic knowledge graph-guided remote sensing image semantic segmentation[J]. National Remote Sensing Bulletin, 2024, 28(2): 455–469. doi: 10.11834/jrs.20231110.
|
| [4] |
TIAN Jiaqi, ZHU Xiaolin, SHEN Miaogen, et al. Effectiveness of spatiotemporal data fusion in fine-scale land surface phenology monitoring: A simulation study[J]. Journal of Remote Sensing, 2024, 4: 0118. doi: 10.34133/remotesensing.0118.
|
| [5] |
WANG Haoyu and LI Xiaofeng. Expanding horizons: U-Net enhancements for semantic segmentation, forecasting, and super-resolution in ocean remote sensing[J]. Journal of Remote Sensing, 2024, 4: 0196. doi: 10.34133/remotesensing.0196.
|
| [6] |
HAN Kai, WANG Yunhe, CHEN Hanting, et al. A survey on vision transformer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 87–110. doi: 10.1109/TPAMI.2022.3152247.
|
| [7] |
WU Honglin, HUANG Peng, ZHANG Min, et al. CMTFNet: CNN and multiscale transformer fusion network for remote-sensing image semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 2004612. doi: 10.1109/TGRS.2023.3314641.
|
| [8] |
LUO Wen, DENG Fei, JIANG Peifan, et al. FSegNet: A semantic segmentation network for high-resolution remote sensing images that balances efficiency and performance[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 4501005. doi: 10.1109/LGRS.2024.3398804.
|
| [9] |
HATAMIZADEH A, HEINRICH G, YIN Hongxu, et al. FasterViT: Fast vision transformers with hierarchical attention[C]. The Twelfth International Conference on Learning Representations, Vienna, Austria, 2024.
|
| [10] |
FAN Lili, ZHOU Yu, LIU Hongmei, et al. Combining swin transformer with UNet for remote sensing image semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5530111. doi: 10.1109/TGRS.2023.3329152.
|
| [11] |
LI Xin, XU Feng, LI Linyang, et al. AAFormer: Attention-attended Transformer for semantic segmentation of remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 5002805. doi: 10.1109/LGRS.2024.3397851.
|
| [12] |
WU Xinjia, ZHANG Jing, LI Wensheng, et al. Spatial-specific transformer with involution for semantic segmentation of high-resolution remote sensing images[J]. International Journal of Remote Sensing, 2023, 44(4): 1280–1307. doi: 10.1080/01431161.2023.2179897.
|
| [13] |
YAN Yi, LI Jiafeng, ZHANG Jing, et al. D2SFormer: Dual attention-dynamic bidirectional transformer for semantic segmentation of urban remote sensing images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 12248–12262. doi: 10.1109/JSTARS.2025.3566159.
|
| [14] |
ZHOU Guoyu, ZHANG Jing, YAN Yi, et al. TEFormer: Texture-aware and edge-guided Transformer for semantic segmentation of urban remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2026, 23: 8000605. doi: 10.1109/LGRS.2025.3639147.
|
| [15] |
PAN Zizheng, ZHUANG Bohan, HE Haoyu, et al. Less is more: Pay less attention in vision transformers[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 2035–2043. doi: 10.1609/aaai.v36i2.20099.
|
| [16] |
FENG Zhanzhou and ZHANG Shiliang. Efficient vision transformer via token merger[J]. IEEE Transactions on Image Processing, 2023, 32: 4156–4169. doi: 10.1109/TIP.2023.3293763.
|
| [17] |
金极栋, 卢宛萱, 孙显, 等. 分布采样对齐的遥感半监督要素提取框架及轻量化方法[J]. 电子与信息学报, 2024, 46(5): 2187–2197. doi: 10.11999/JEIT240220.
JIN Jidong, LU Wanxuan, SUN Xian, et al. Remote sensing semi-supervised feature extraction framework and lightweight method integrated with distribution-aligned sampling[J]. Journal of Electronics & Information Technology, 2024, 46(5): 2187–2197. doi: 10.11999/JEIT240220.
|
| [18] |
YU Weihao, LUO Mi, ZHOU Pan, et al. MetaFormer is actually what you need for vision[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 10819–10829. doi: 10.1109/CVPR52688.2022.01055.
|
| [19] |
HAN Dongchen, YE Tianzhu, HAN Yizeng, et al. Agent attention: On the integration of softmax and linear attention[C]. 18th European Conference on Computer Vision, Milan, Italy, 2024: 124–140. doi: 10.1007/978-3-031-72973-7_8.
|
| [20] |
YUN Seokju and RO Y. SHViT: Single-head vision transformer with memory efficient macro design[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 5756–5767. doi: 10.1109/CVPR52733.2024.00550.
|
| [21] |
LIANG Youwei, GE Chongjian, TONG Zhan, et al. Not all patches are what you need: Expediting vision transformers via token reorganizations[EB/OL]. https://arxiv.org/abs/2202.07800, 2022.
|
| [22] |
WU Xinjian, ZENG Fanhu, WANG Xiudong, et al. PPT: Token pruning and pooling for efficient vision transformers[J]. arXiv preprint arXiv: 2310.01812, 2023. doi: 10.48550/arXiv.2310.01812.
|
| [23] |
YAN Yi, ZHANG Jing, WU Xinjia, et al. When zero-padding position encoding encounters linear space reduction attention: An efficient semantic segmentation transformer of remote sensing images[J]. International Journal of Remote Sensing, 2024, 45(2): 609–633. doi: 10.1080/01431161.2023.2299276.
|
| [24] |
HAN Dongchen, PAN Xuran, HAN Yizeng, et al. FLatten transformer: Vision transformer using focused linear attention[C]. The IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 5938–5948. doi: 10.1109/ICCV51070.2023.00548.
|
| [25] |
HOU Jianlong, GUO Zhi, WU Youming, et al. BSNet: Dynamic hybrid gradient convolution based boundary-sensitive network for remote sensing image segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5624022. doi: 10.1109/TGRS.2022.3176028.
|
| [26] |
XU Jiacong, XIONG Zixiang, and BHATTACHARYYA S P. PIDNet: A real-time semantic segmentation network inspired by PID controllers[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 19529–19539. doi: 10.1109/CVPR52729.2023.01871.
|
| [27] |
WANG Chi, ZHANG Yunke, CUI Miaomiao, et al. Active boundary loss for semantic segmentation[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 2397–2405. doi: 10.1609/aaai.v36i2.20139.
|
| [28] |
MA Xiaohu, WANG Wuli, LI Wei, et al. An ultralightweight hybrid CNN based on redundancy removal for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5506212. doi: 10.1109/TGRS.2024.3356524.
|
| [29] |
XU Guoan, LI Juncheng, GAO Guangwei, et al. Lightweight real-time semantic segmentation network with efficient transformer and CNN[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(12): 15897–15906. doi: 10.1109/TITS.2023.3248089.
|
| [30] |
HOSSEINPOUR H, SAMADZADEGAN F, and JAVAN F D. CMGFNet: A deep cross-modal gated fusion network for building extraction from very high-resolution remote sensing images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 184: 96–115. doi: 10.1016/j.isprsjprs.2021.12.007.
|
| [31] |
ROTTENSTEINER F, SOHN G, GERKE M, et al. ISPRS semantic labeling contest[J]. ISPRS: Leopoldshöhe, Germany, 2014, 1(4): 4.
|
| [32] |
WANG Junjue, ZHENG Zhuo, MA Ailong, et al. LoveDA: A remote sensing land-cover dataset for domain adaptation semantic segmentation[C]. The 35th Conference on Neural Information Processing Systems, 2021.
|
| [33] |
徐睿, 韩斌, 陈飞, 等. 基于环形卷积的遥感影像语义分割方法[J]. 计算机应用研究, 2025, 42(12): 3793–3798. doi: 10.19734/j.issn.1001-3695.2025.03.0099.
XU Rui, HAN Bin, CHEN Fei, et al. RingNet: Semantic segmentation of remote sensing images based on ring convolution[J]. Application Research of Computers, 2025, 42(12): 3793–3798. doi: 10.19734/j.issn.1001-3695.2025.03.0099.
|
| [34] |
王诗瑞, 杜康宁, 田澍, 等. 门限注意力引导的遥感图像语义分割网络[J]. 遥感信息, 2025, 40(3): 164–171. doi: 10.20091/j.cnki.1000-3177.2025.03.019.
WANG Shirui, DU Kangning, TIAN Shu, et al. Threshold attention guided network for semantic segmentation of remote sensing images[J]. Remote Sensing Information, 2025, 40(3): 164–171. doi: 10.20091/j.cnki.1000-3177.2025.03.019.
|
| [35] |
DONG Xiaoyi, BAO Jianmin, CHEN Dongdong, et al. CSWin transformer: A general vision transformer backbone with cross-shaped windows[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 12114–12124. doi: 10.1109/CVPR52688.2022.01181.
|

Figures(6) / Tables(5)



 DownLoad:
DownLoad: