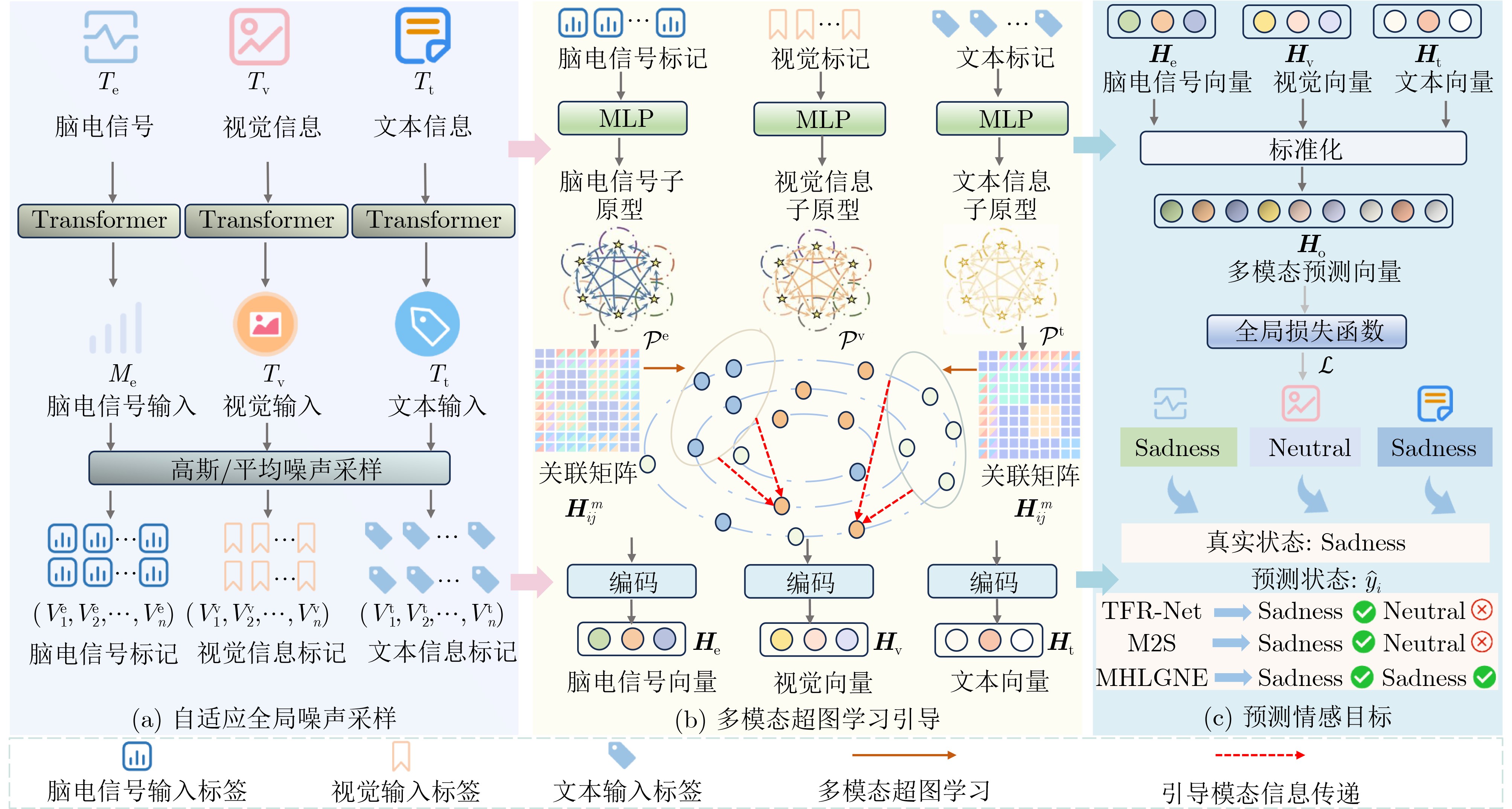
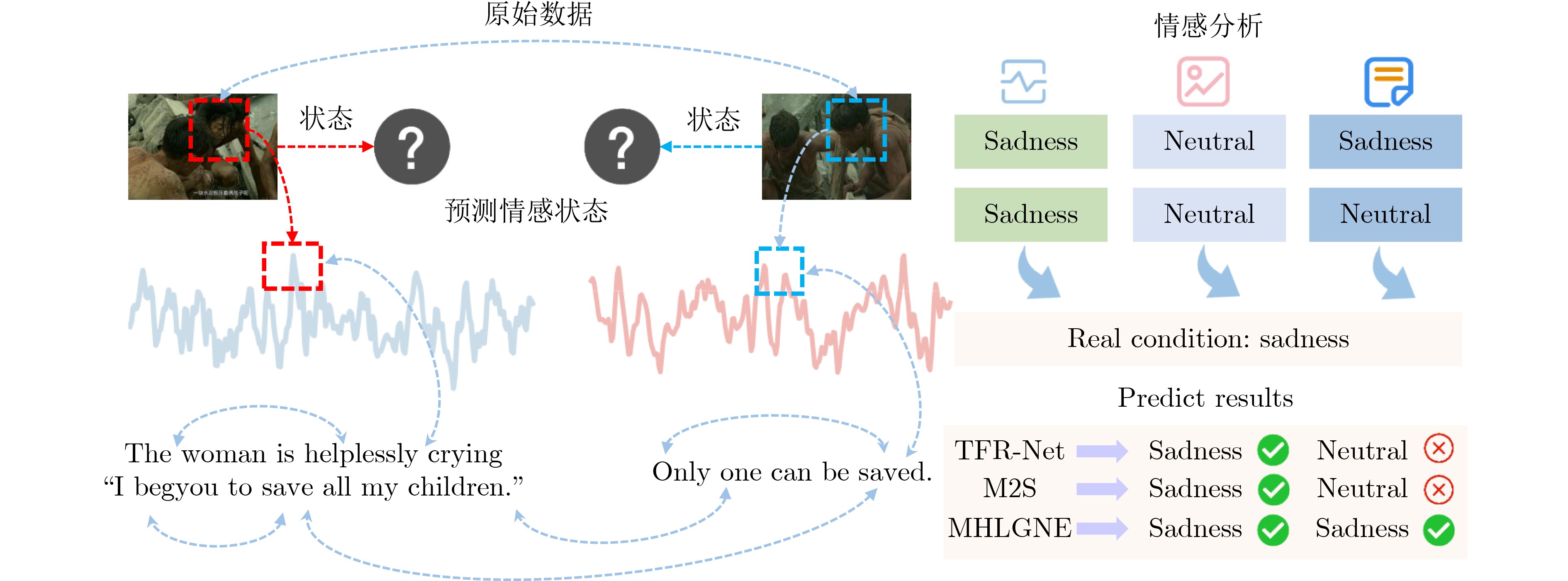
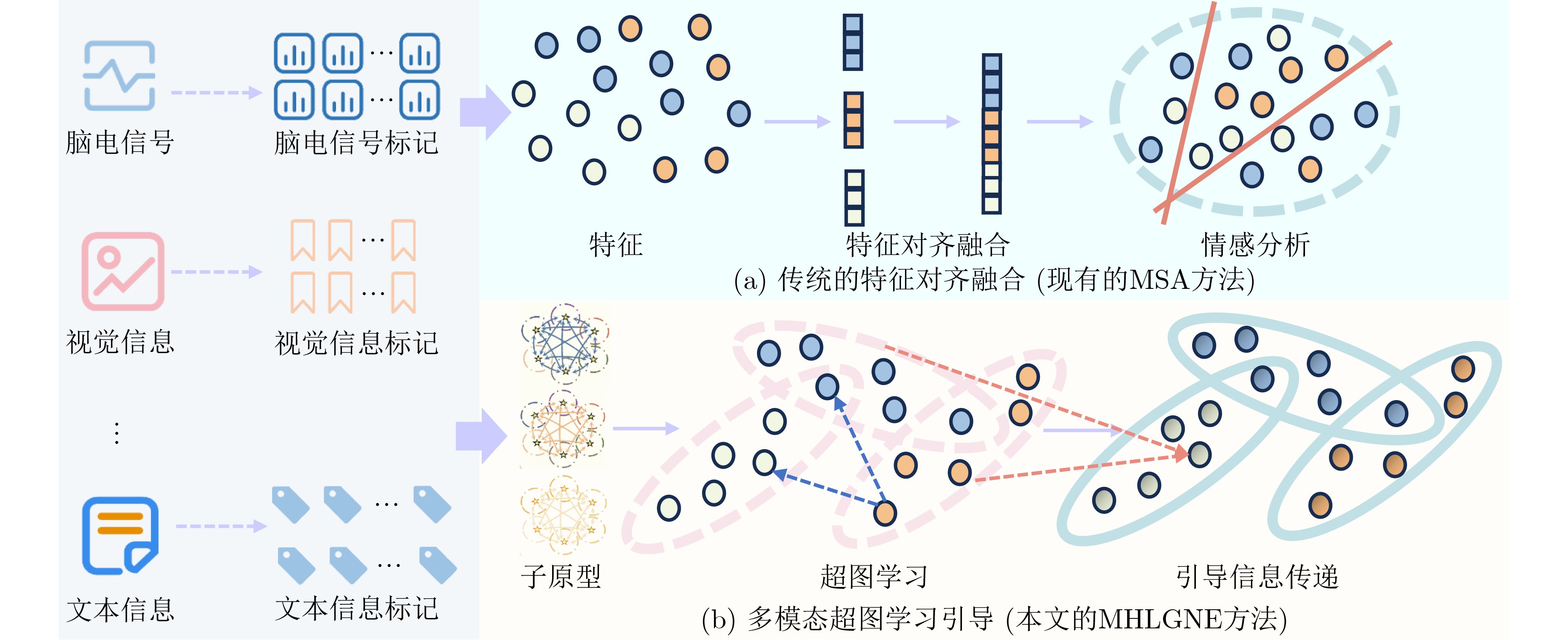
| Citation: | HUANG Chen, LIU Huijie, ZHANG Yan, YANG Chao, SONG Jianhua. Multimodal Hypergraph Learning Guidance with Global Noise Enhancement for Sentiment Analysis under Missing Modality Information[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5192-5202. doi: 10.11999/JEIT250649

|

| [1] |
刘佳, 宋泓, 陈大鹏, 等. 非语言信息增强和对比学习的多模态情感分析模型[J]. 电子与信息学报, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274.
LIU Jia, SONG Hong, CHEN Dapeng, et al. A multimodal sentiment analysis model enhanced with non-verbal information and contrastive learning[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274.
|
| [2] |
WANG Pan, ZHOU Qiang, WU Yawen, et al. DLF: Disentangled-language-focused multimodal sentiment analysis[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 21180–21188. doi: 10.1609/aaai.v39i20.35416.
|
| [3] |
XU Qinfu, WEI Yiwei, WU Chunlei, et al. Towards multimodal sentiment analysis via hierarchical correlation modeling with semantic distribution constraints[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 21788–21796. doi: 10.1609/aaai.v39i20.35484.
|
| [4] |
XU Xi, LI Jianqiang, ZHU Zhichao, et al. A comprehensive review on synergy of multi-modal data and AI technologies in medical diagnosis[J]. Bioengineering, 2024, 11(3): 219. doi: 10.3390/bioengineering11030219.
|
| [5] |
LIU Huan, LOU Tianyu, ZHANG Yuzhe, et al. EEG-based multimodal emotion recognition: A machine learning perspective[J]. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 4003729. doi: 10.1109/TIM.2024.3369130.
|
| [6] |
ZHAO Xuefeng, WANG Yuxiang, ZHONG Zhaoman. Text-in-image enhanced self-supervised alignment model for aspect-based multimodal sentiment analysis on social media[J]. Sensors, 2025, 25(8): 2553. doi: 10.3390/s25082553.
|
| [7] |
SUN Hao, NIU Ziwei, WANG Hongyi, et al. Multimodal sentiment analysis with mutual information-based disentangled representation learning[J]. IEEE Transactions on Affective Computing, 2025, 16(3): 1606–1617. doi: 10.1109/TAFFC.2025.3529732.
|
| [8] |
ZHAO Sicheng, YANG Zhenhua, SHI Henglin, et al. SDRS: Sentiment-aware disentangled representation shifting for multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2025, 16(3): 1802–1813. doi: 10.1109/TAFFC.2025.3539225.
|
| [9] |
LUO Yuanyi, LIU Wei, SUN Qiang, et al. TriagedMSA: Triaging sentimental disagreement in multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2025, 16(3): 1557–1569. doi: 10.1109/TAFFC.2024.3524789.
|
| [10] |
WANG Yuhao, LIU Yang, ZHENG Aihua, et al. Decoupled feature-based mixture of experts for multi-modal object re-identification[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 8141–8149. doi: 10.1609/aaai.v39i8.32878.
|
| [11] |
WU Sheng, HE Dongxiao, WANG Xiaobao, et al. Enriching multimodal sentiment analysis through textual emotional descriptions of visual-audio content[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 1601–1609. doi: 10.1609/aaai.v39i2.32152.
|
| [12] |
SUN Xin, REN Xiangyu, and XIE Xiaohao. A novel multimodal sentiment analysis model based on gated fusion and multi-task learning[C]. The ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, South Korea, 2024: 8336–8340. doi: 10.1109/ICASSP48485.2024.10446040.
|
| [13] |
LI Meng, ZHU Zhenfang, LI Kefeng, et al. Diversity and balance: Multimodal sentiment analysis using multimodal-prefixed and cross-modal attention[J]. IEEE Transactions on Affective Computing, 2025, 16(1): 250–263. doi: 10.1109/TAFFC.2024.3430045.
|
| [14] |
LIU Zhicheng, BRAYTEE A, ANAISSI A, et al. Ensemble pretrained models for multimodal sentiment analysis using textual and video data fusion[C]. The ACM Web Conference 2024, Singapore, Singapore, 2024: 1841–1848. doi: 10.1145/3589335.3651971.
|
| [15] |
TANG Jiajia, LI Kang, JIN Xuanyu, et al. CTFN: Hierarchical learning for multimodal sentiment analysis using coupled-translation fusion network[C]. The 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (volume 1: Long Papers), 2021: 5301–5311. doi: 10.18653/v1/2021.acl-long.412.
|
| [16] |
ZENG Jiandian, ZHOU Jiantao, and LIU Tianyi. Mitigating inconsistencies in multimodal sentiment analysis under uncertain missing modalities[C]. 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 2022: 2924–2934. doi: 10.18653/v1/2022.emnlp-main.189.
|
| [17] |
LIU Yankai, CAI Jinyu, LU Baoliang, et al. Multi-to-single: Reducing multimodal dependency in emotion recognition through contrastive learning[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 1438–1446. doi: 10.1609/aaai.v39i2.32134.
|
| [18] |
TAO Chuanqi, LI Jiaming, ZANG Tianzi, et al. A multi-focus-driven multi-branch network for robust multimodal sentiment analysis[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 1547–1555. doi: 10.1609/aaai.v39i2.32146.
|
| [19] |
BALTRUŠAITIS T, ROBINSON P, and MORENCY L P. OpenFace: An open source facial behavior analysis toolkit[C]. 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, USA, IEEE, 2016: 1–10. doi: 10.1109/WACV.2016.7477553.
|
| [20] |
LIU Yinhan, OTT M, GOYAL N, et al. RoBERTa: A robustly optimized BERT pretraining approach[EB/OL]. https://arxiv.org/abs/1907.11692, 2019.
|
| [21] |
FANG Feiteng, BAI Yuelin, NI Shiwen, et al. Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training[C]. The 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 2024: 10028–10039. doi: 10.18653/v1/2024.acl-long.540.
|
| [22] |
CHEN Zhuo, GUO Lingbing, FANG Yin, et al. Rethinking uncertainly missing and ambiguous visual modality in multi-modal entity alignment[C]. The 22nd International Semantic Web Conference on the Semantic Web, Athens, Greece, 2023: 121–139. doi: 10.1007/978-3-031-47240-4_7.
|
| [23] |
GAO Min, ZHENG Haifeng, FENG Xinxin, et al. Multimodal fusion using multi-view domains for data heterogeneity in federated learning[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 16736–16744. doi: 10.1609/aaai.v39i16.33839.
|
| [24] |
ZHOU Yan, FANG Qingkai, and FENG Yang. CMOT: Cross-modal Mixup via optimal transport for speech translation[C]. The 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada, 2023: 7873–7887. doi: 10.18653/v1/2023.acl-long.436.
|
| [25] |
ZHENG Weilong, LIU Wei, LU Yifei, et al. EmotionMeter: A multimodal framework for recognizing human emotions[J]. IEEE Transactions on Cybernetics, 2019, 49(3): 1110–1122. doi: 10.1109/TCYB.2018.2797176.
|
| [26] |
LIU Wei, QIU Jielin, ZHENG Weilong, et al. Comparing recognition performance and robustness of multimodal deep learning models for multimodal emotion recognition[J]. IEEE Transactions on Cognitive and Developmental Systems, 2022, 14(2): 715–729. doi: 10.1109/TCDS.2021.3071170.
|
| [27] |
KATSIGIANNIS S and RAMZAN N. DREAMER: A database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices[J]. IEEE Journal of Biomedical and Health Informatics, 2018, 22(1): 98–107. doi: 10.1109/JBHI.2017.2688239.
|
| [28] |
JIANG Huangfei, GUAN Xiya, ZHAO Weiye, et al. Generating multimodal features for emotion classification from eye movement signals[J]. Australian Journal of Intelligent Information Processing Systems, 2019, 15(3): 59–66.
|
| [29] |
YAN Xu, ZHAO Liming, and LU Baoliang. Simplifying multimodal emotion recognition with single eye movement modality[C]. The 29th ACM International Conference on Multimedia, 2021: 1057–1063. doi: 10.1145/3474085.3475701.
|
| [30] |
XIA Yan, HUANG Hai, ZHU Jieming, et al. Achieving cross modal generalization with multimodal unified representation[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2021: 2774.
|
| [31] |
JIANG Weibang, LI Ziyi, ZHENG Weilong, et al. Functional emotion transformer for EEG-assisted cross-modal emotion recognition[C]. The ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024: 1841–1845. doi: 10.1109/ICASSP48485.2024.10446937.
|
| [32] |
YUAN Ziqi, LI Wei, XU Hua, et al. Transformer-based feature reconstruction network for robust multimodal sentiment analysis[C]. The 29th ACM International Conference on Multimedia, 2021: 4400–4407. doi: 10.1145/3474085.3475585.
|
| [33] |
JIANG Weibang, LIU Xuanhao, ZHENG Weilong, et al. Multimodal adaptive emotion transformer with flexible modality inputs on a novel dataset with continuous labels[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 5975–5984. doi: 10.1145/3581783.3613797.
|
| [34] |
LI Jiabao, LIU Ruyi, MIAO Qiguang, et al. CAETFN: Context adaptively enhanced text-guided fusion network for multimodal sentiment analysis[J]. IEEE Transactions on Affective Computing, 2025. doi: 10.1109/TAFFC.2025.3590246.
|
| [35] |
HUANG Jiayang, VONG C M, LI Chen, et al. HSA-former: Hierarchical spatial aggregation transformer for EEG-based emotion recognition[J]. IEEE Transactions on Computational Social Systems, 2025. doi: 10.1109/TCSS.2025.3567298.
|
| [36] |
DENG Jiawen and REN Fuji. Multi-label emotion detection via emotion-specified feature extraction and emotion correlation learning[J]. IEEE Transactions on Affective Computing, 2023, 14(1): 475–486. doi: 10.1109/TAFFC.2020.3034215.
|
Figures(3) / Tables(5)



 DownLoad:
DownLoad: