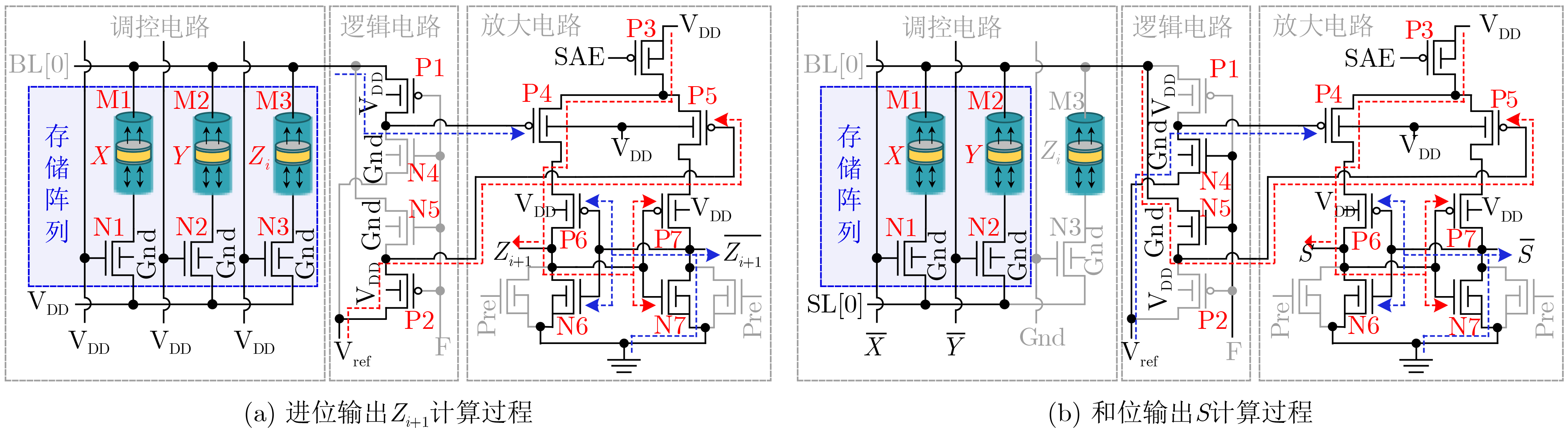
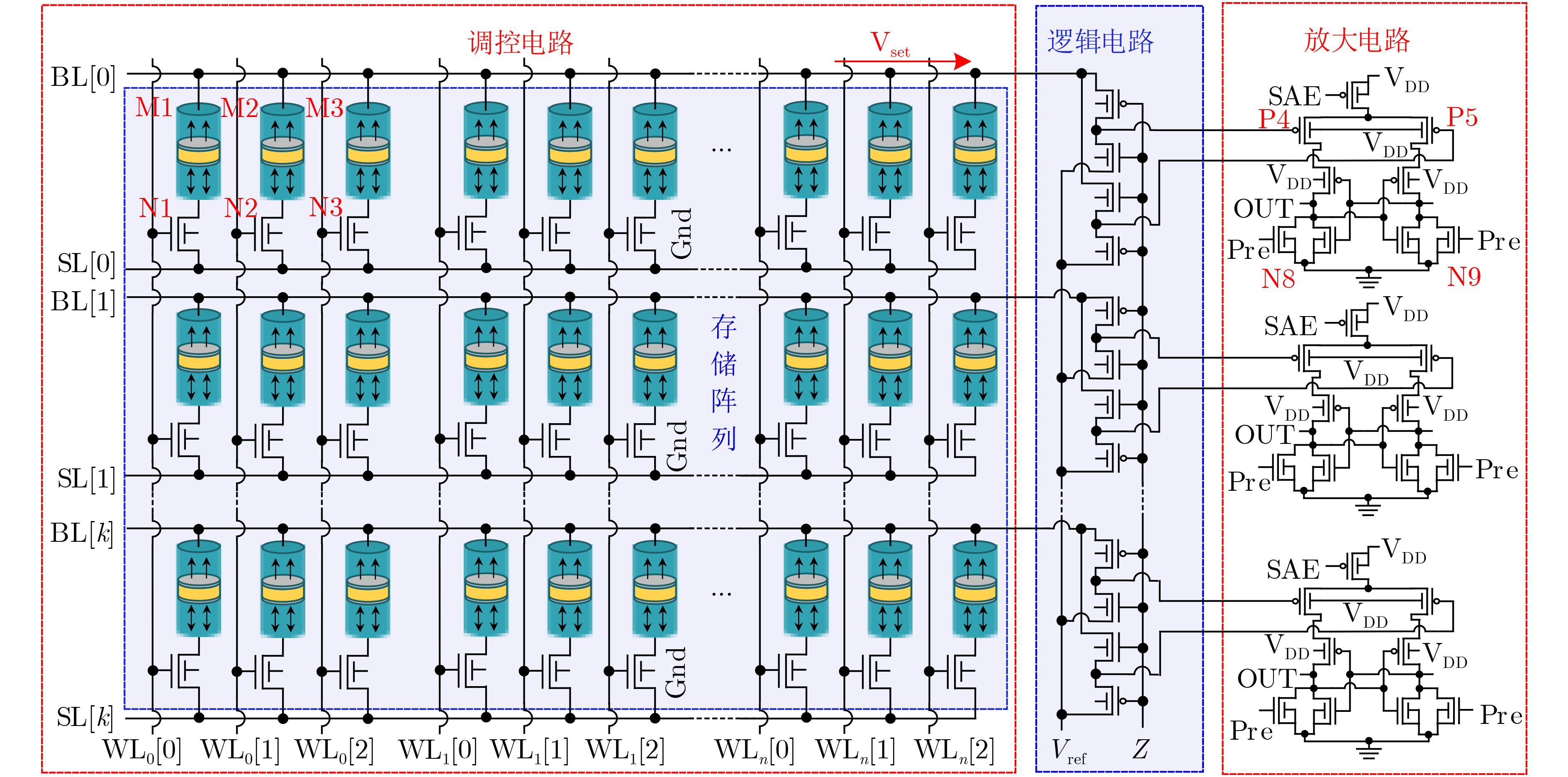
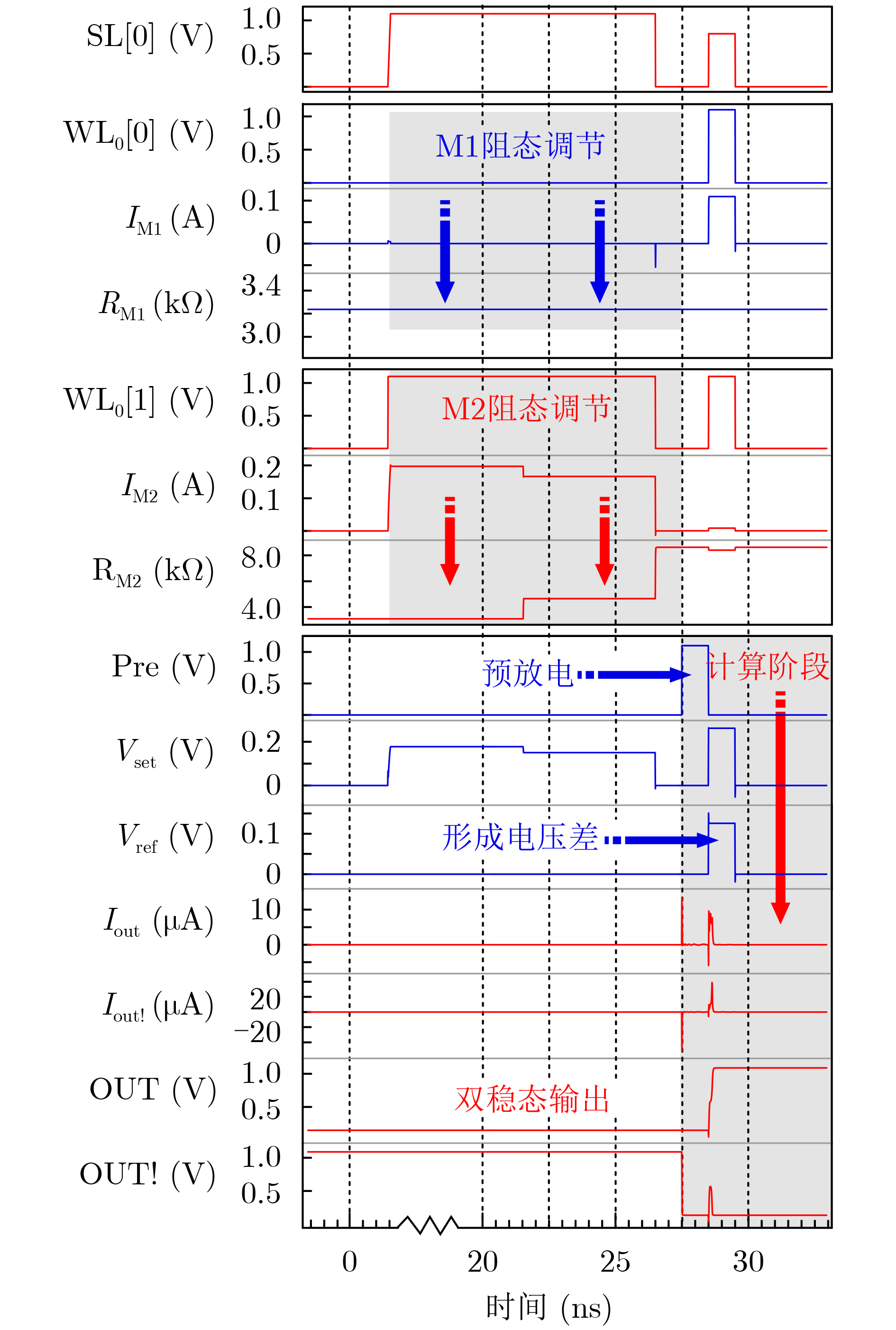
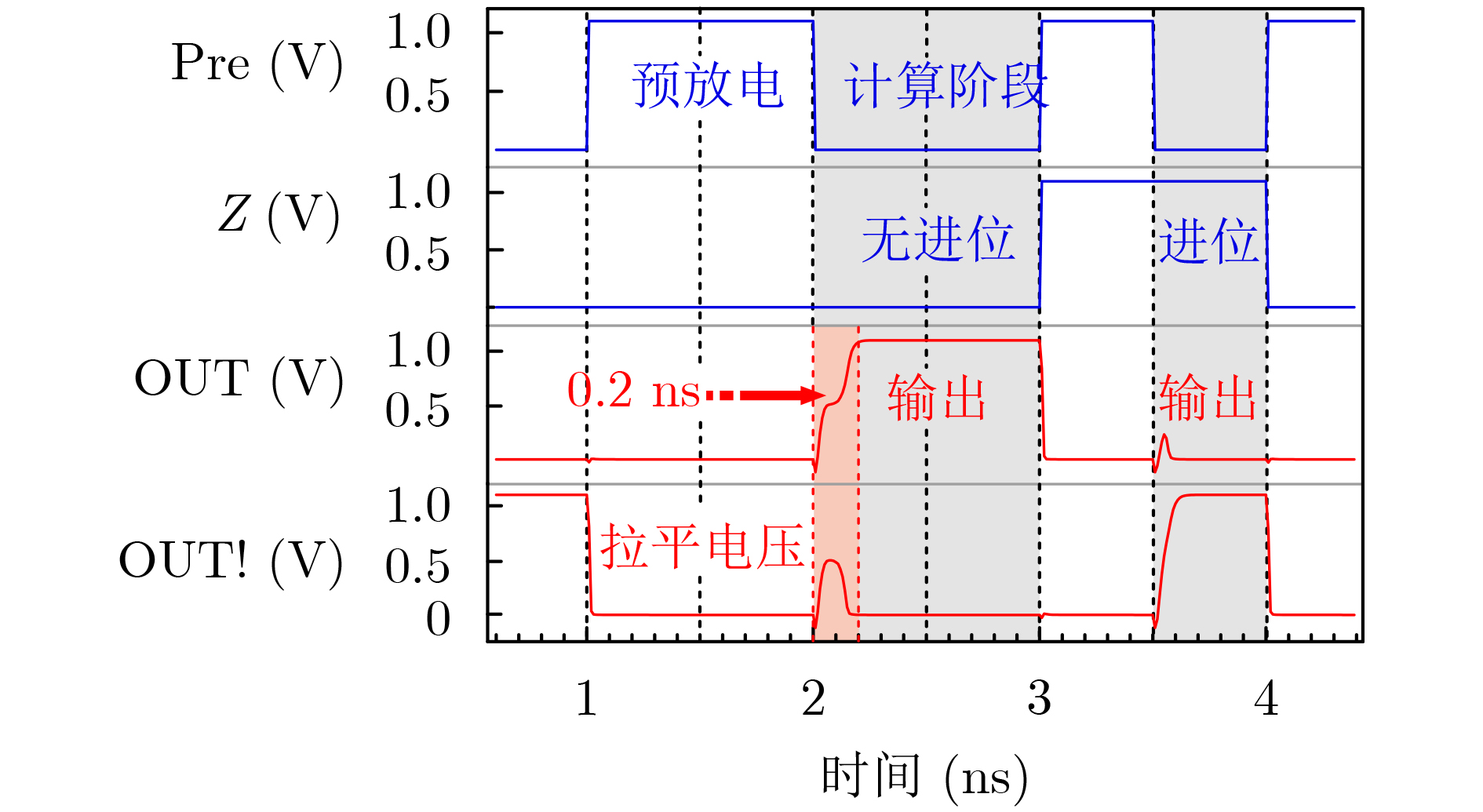
| Citation: | WANG Lixun, ZHANG Yuejun, LI Qikang, ZHANG Huihong, WEN Liang. Lightweight AdderNet Circuit Enabled by STT-MRAM In-Memory Absolute Difference Computation[J]. Journal of Electronics & Information Technology, 2025, 47(9): 3252-3261. doi: 10.11999/JEIT250627

|

| [1] |
QI Haoran, QIU Yuwei, LUO Xing, et al. An efficient latent style guided transformer-CNN framework for face super-resolution[J]. IEEE Transactions on Multimedia, 2024, 26: 1589–1599. doi: 10.1109/TMM.2023.3283856.
|
| [2] |
陈晓雷, 王兴, 张学功, 等. 面向360度全景图像显著目标检测的相邻协调网络[J]. 电子与信息学报, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502.
CHEN Xiaolei, WANG Xing, ZHANG Xuegong, et al. Adjacent coordination network for salient object detection in 360 degree omnidirectional images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502.
|
| [3] |
李沫谦, 杨陟卓, 李茹, 等. 基于多尺度卷积的阅读理解候选句抽取[J]. 中文信息学报, 2024, 38(8): 128–139,157. doi: 10.3969/j.issn.1003-0077.2024.08.015.
LI Moqian, YANG Zhizhuo, LI Ru, et al. Evidence sentence extraction for reading comprehension based on multi-scale convolution[J]. Journal of Chinese Information Processing, 2024, 38(8): 128–139,157. doi: 10.3969/j.issn.1003-0077.2024.08.015.
|
| [4] |
LU Ye, XIE Kunpeng, XU Guanbin, et al. MTFC: A multi-GPU training framework for cube-CNN-based hyperspectral image classification[J]. IEEE Transactions on Emerging Topics in Computing, 2021, 9(4): 1738–1752. doi: 10.1109/TETC.2020.3016978.
|
| [5] |
HONG H, CHOI D, KIM N, et al. Mobile-X: Dedicated FPGA implementation of the MobileNet accelerator optimizing depthwise separable convolution[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2024, 71(11): 4668–4672. doi: 10.1109/TCSII.2024.3440884.
|
| [6] |
MUN H G, MOON S, KIM B, et al. Bottleneck-stationary compact model accelerator with reduced requirement on memory bandwidth for edge applications[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023, 70(2): 772–782. doi: 10.1109/TCSI.2022.3222862.
|
| [7] |
WANG Tianyu, SHEN Zhaoyan, and SHAO Zili. CNN acceleration with joint optimization of practical PIM and GPU on embedded devices[C]. IEEE 40th International Conference on Computer Design (ICCD), Olympic Valley, CA, USA, 2022: 377–384. doi: 10.1109/ICCD56317.2022.00062.
|
| [8] |
BLOTT M, PREUßER T B, FRASER N J, et al. FINN-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks[J]. ACM Transactions on Reconfigurable Technology and Systems, 2018, 11(3): 16. doi: 10.1145/3242897.
|
| [9] |
CONTI F, PAULIN G, GAROFALO A, et al. Marsellus: A heterogeneous RISC-V AI-IoT end-node SoC with 2–8 b DNN acceleration and 30%-boost adaptive body biasing[J]. IEEE Journal of Solid-State Circuits, 2024, 59(1): 128–142. doi: 10.1109/JSSC.2023.3318301.
|
| [10] |
CHEN Hanting, WANG Yunhe, XU Chunjing, et al. AdderNet: Do we really need multiplications in deep learning?[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 1465–1474. doi: 10.1109/CVPR42600.2020.00154.
|
| [11] |
ZHANG Heng, HE Sunan, LU Xin, et al. SSM-CIM: An efficient CIM macro featuring single-step multi-bit MAC computation for CNN edge inference[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023, 70(11): 4357–4368. doi: 10.1109/TCSI.2023.3301814.
|
| [12] |
永若雪, 姜岩峰. 关于3D堆叠MRAM热学分析方法的研究[J]. 电子学报, 2023, 51(10): 2775–2782. doi: 10.12263/DZXB.20220275.
YONG Ruoxue and JIANG Yanfeng. Research on thermal analysis method of 3D-stacked MRAM[J]. Acta Electronica Sinica, 2023, 51(10): 2775–2782. doi: 10.12263/DZXB.20220275.
|
| [13] |
LUO Lichuan, DENG Erya, LIU Dijun, et al. CiTST-AdderNets: Computing in toggle spin torques MRAM for energy-efficient AdderNets[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2024, 71(3): 1130–1143. doi: 10.1109/TCSI.2023.3343081.
|
| [14] |
OpenVINO. OpenVINO 2025.3[EB/OL]. https://docs.openvino.ai/2025/index.html, 2025.
|
| [15] |
ZHANG Yunxiang, SUN Biao, JIANG Weixiong, et al. WSQ-AdderNet: Efficient weight standardization based quantized AdderNet FPGA accelerator design with high-density INT8 DSP-LUT co-packing optimization[C]. IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Diego, USA, 2022: 1–9.
|
| [16] |
ZHANG Yunxiang, AL KAILANI O, ZHOU Bin, et al. AdderNet 2.0: Optimal addernet accelerator designs with activation-oriented quantization and fused bias removal-based memory optimization[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2025. doi: 10.1109/TCSI.2025.3539912.
|
Figures(11) / Tables(2)


 DownLoad:
DownLoad: