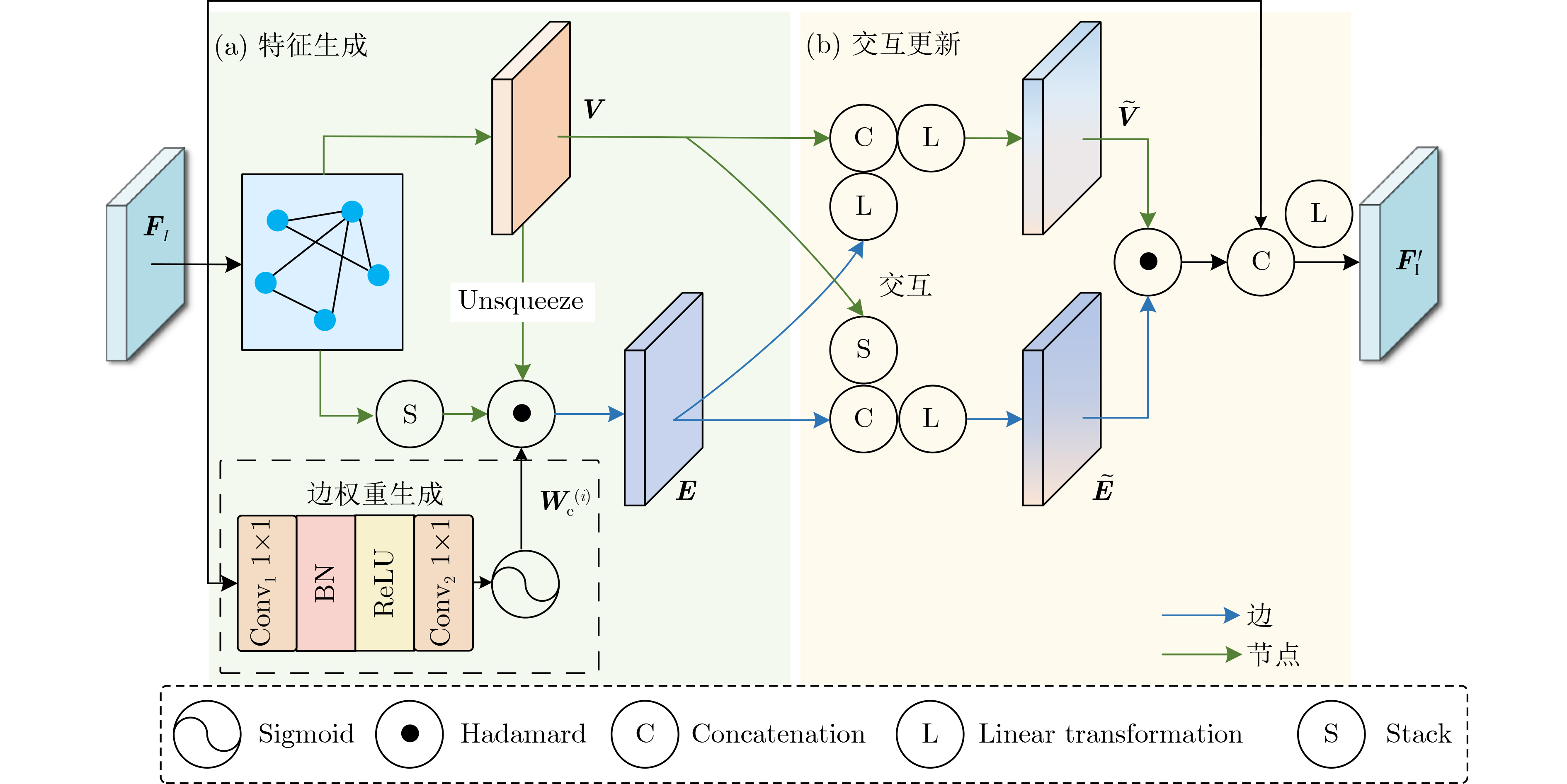
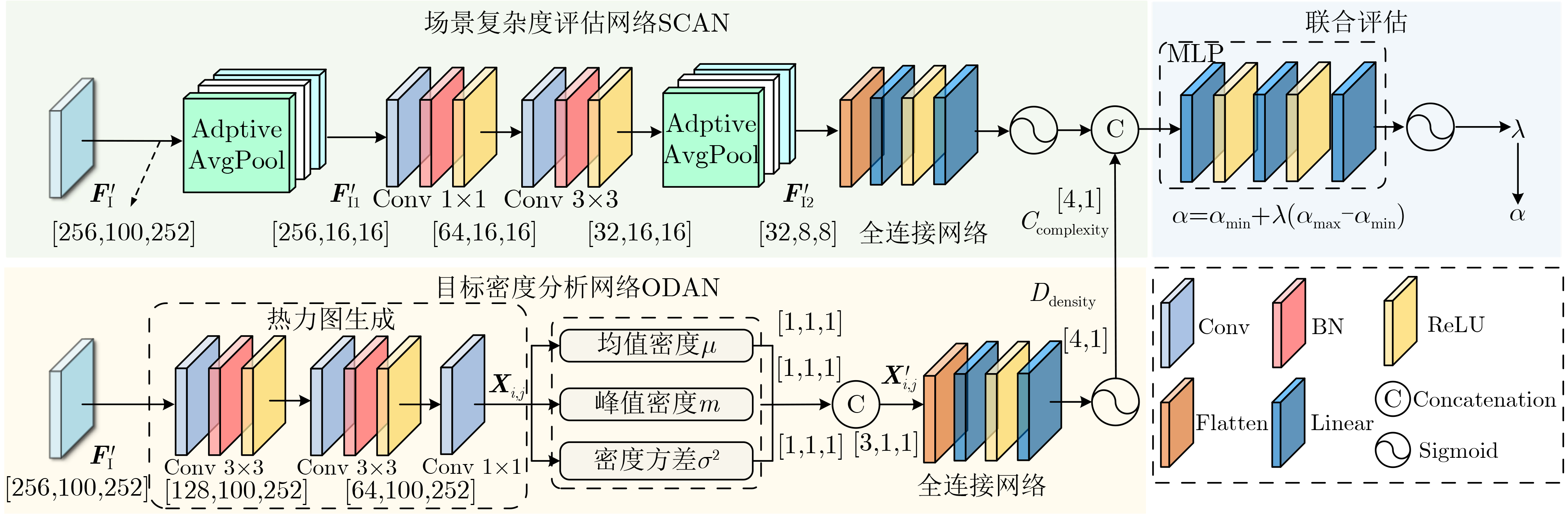
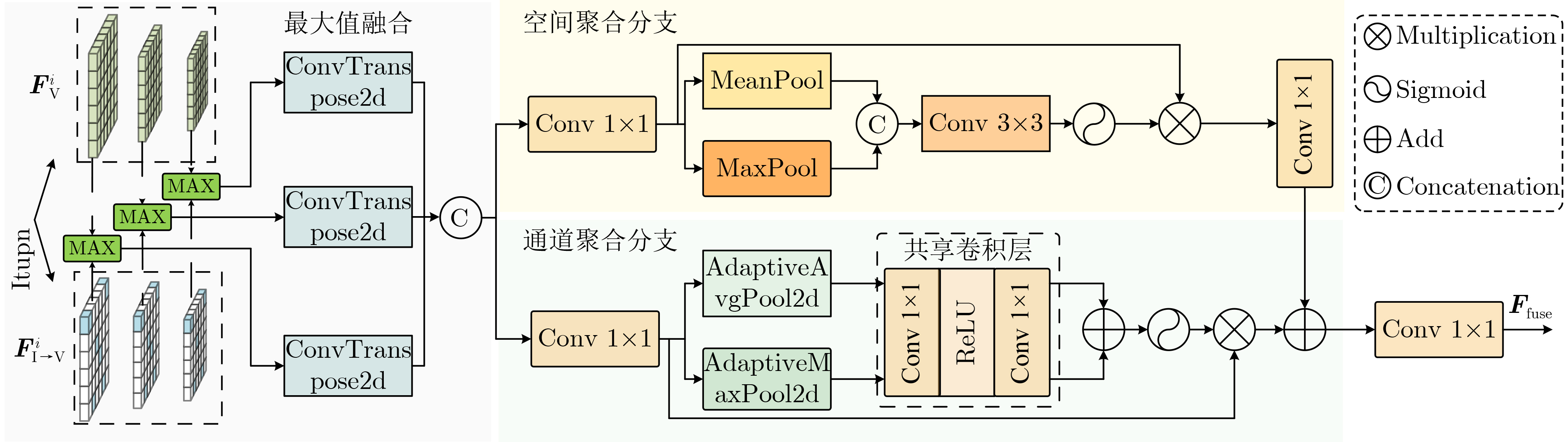
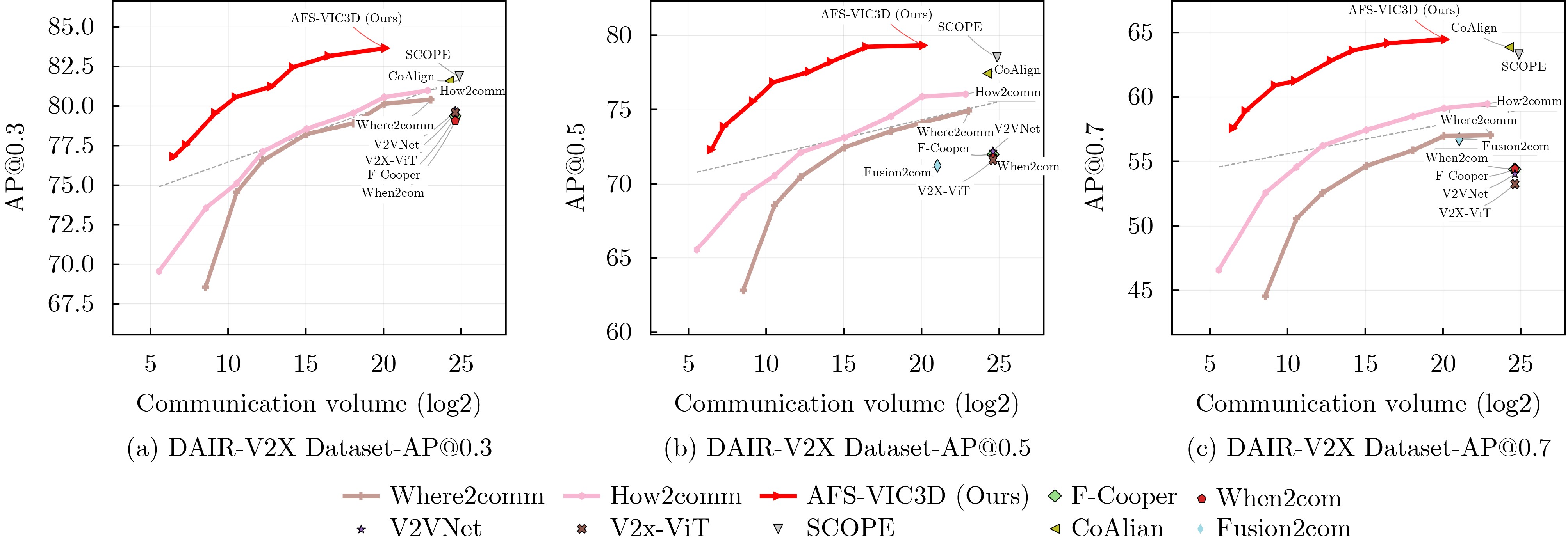
| Citation: | LIANG Yan, YANG Huilin, SHAO Kai. A Vehicle-Infrastructure Cooperative 3D Object Detection Scheme Based on Adaptive Feature Selection[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5214-5225. doi: 10.11999/JEIT250601

|

| [1] |
SHAO Shilin, ZHOU Yang, LI Zhenglin, et al. Frustum PointVoxel-RCNN: A high-performance framework for accurate 3D object detection in point clouds and images[C]. The 2024 4th International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 2024: 56–60. doi: 10.1109/ICCCR61138.2024.10585339.
|
| [2] |
邵凯, 吴广, 梁燕, 等. 基于局部特征编解码的自动驾驶3D目标检测[J]. 系统工程与电子技术, 2025, 47(10): 3168–3178. doi: 10.12305/j.issn.1001-506X.2025.10.05.
SHAO Kai, WU Guang, LIANG Yan, et al. Local feature encode-decoding based 3D target detection of autonomous driving[J]. Systems Engineering and Electronics, 2025, 47(10): 3168–3178. doi: 10.12305/j.issn.1001-506X.2025.10.05.
|
| [3] |
ZHANG Yezheng, FAN Zhijie, HOU Jiawei, et al. Incentivizing point cloud-based accurate cooperative perception for connected vehicles[J]. IEEE Transactions on Vehicular Technology, 2025, 74(4): 5637–5648. doi: 10.1109/TVT.2024.3519626.
|
| [4] |
HU Senkang, FANG Zhengru, DENG Yiqin, et al. Collaborative perception for connected and autonomous driving: Challenges, possible solutions and opportunities[J]. IEEE Wireless Communications, 2025, 32(5): 228–234. doi: 10.1109/MWC.002.2400348.
|
| [5] |
LI Jing, NIU Yong, WU Hao, et al. Effective joint scheduling and power allocation for URLLC-oriented V2I communications[J]. IEEE Transactions on Vehicular Technology, 2024, 73(8): 11694–11705. doi: 10.1109/TVT.2024.3381924.
|
| [6] |
LIU Gang, HU Jiewen, MA Zheng, et al. Joint optimization of communication latency and platoon control based on uplink RSMA for future V2X networks[J]. IEEE Transactions on Vehicular Technology, 2025, 74(9): 13458–13470. doi: 10.1109/TVT.2025.3560709.
|
| [7] |
CHEN Qi, MA Xu, TANG Sihai, et al. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds[C]. The 4th ACM/IEEE Symposium on Edge Computing, Arlington, USA, 2019: 88–100. doi: 10.1145/3318216.3363300.
|
| [8] |
WANG T H, MANIVASAGAM S, LIANG Ming, et al. V2VNet: Vehicle-to-vehicle communication for joint perception and prediction[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 605–621. doi: 10.1007/978-3-030-58536-5_36.
|
| [9] |
XU Runsheng, XIANG Hao, TU Zhengzhong, et al. V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 107–124. doi: 10.1007/978-3-031-19842-7_7.
|
| [10] |
LIU Y C, TIAN Junjiao, GLASER N, et al. When2com: Multi-agent perception via communication graph grouping[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 4105–4114. doi: 10.1109/CVPR42600.2020.00416.
|
| [11] |
HU Yue, FANG Shaoheng, LEI Zixing, et al. Where2comm: Communication-efficient collaborative perception via spatial confidence maps[C]. The 36th International Conference on Neural Information Processing System, New Orleans, USA, 2022: 352. doi: 10.5555/3600270.3600622.
|
| [12] |
YANG Dingkang, YANG Kun, WANG Yuzheng, et al. How2comm: Communication-efficient and collaboration-pragmatic multi-agent perception[J]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1093.
|
| [13] |
CHU Huazhen, LIU Haizhuang, ZHUO Junbao, et al. Occlusion-guided multi-modal fusion for vehicle-infrastructure cooperative 3D object detection[J]. Pattern Recognition, 2025, 157: 110939. doi: 10.1016/j.patcog.2024.110939.
|
| [14] |
LIU Haizhuang, CHU Huazhen, ZHUO Junbao, et al. SparseComm: An efficient sparse communication framework for vehicle-infrastructure cooperative 3D detection[J]. Pattern Recognition, 2025, 158: 110961. doi: 10.1016/j.patcog.2024.110961.
|
| [15] |
YANG Kun, YANG Dingkang, ZHANG Jingyu, et al. Spatio-temporal domain awareness for multi-agent collaborative perception[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 23383–23392. doi: 10.1109/ICCV51070.2023.02137.
|
| [16] |
LU Yifan, LI Quanhao, LIU Baoan, et al. Robust collaborative 3D object detection in presence of pose errors[C]. The 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023: 4812–4818. doi: 10.1109/ICRA48891.2023.10160546.
|
| [17] |
LANG A H, VORA S, CAESAR H, et al. PointPillars: Fast encoders for object detection from point clouds[C]. The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 12689–12697. doi: 10.1109/CVPR.2019.01298.
|
| [18] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.
|
| [19] |
XUE Yuanliang, JIN Guodong, SHEN Tao, et al. SmallTrack: Wavelet pooling and graph enhanced classification for UAV small object tracking[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5618815. doi: 10.1109/TGRS.2023.3305728.
|
| [20] |
ZHANG Jingyu, YANG Kun, WANG Yilei, et al. ERMVP: Communication-efficient and collaboration-robust multi-vehicle perception in challenging environments[C]. The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 12575–12584. doi: 10.1109/CVPR52733.2024.01195.
|
| [21] |
陶新民, 李俊轩, 郭心悦, 等. 基于超球体密度聚类的自适应不均衡数据过采样算法[J]. 电子与信息学报, 2025, 47(7): 2347–2360. doi: 10.11999/JEIT241037.
TAO Xinmin, LI Junxuan, GUO Xinyue, et al. Density clustering hypersphere-based self-adaptively oversampling algorithm for imbalanced datasets[J]. Journal of Electronics & Information Technology, 2025, 47(7): 2347–2360. doi: 10.11999/JEIT241037.
|
| [22] |
LIU Haisong, TENG Yao, LU Tao, et al. SparseBEV: High-performance sparse 3D object detection from multi-camera videos[C]. The 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 18534–18544. doi: 10.1109/ICCV51070.2023.01703.
|
| [23] |
LIU Mushui, DAN Jun, LU Ziqian, et al. CM-UNet: Hybrid CNN-mamba UNet for remote sensing image semantic segmentation[J]. arXiv preprint arXiv: 2405.10530, 2024. doi. org/10.48550/arXiv. 2405.10530.
|
| [24] |
YU Haibao, LUO Yizhen, SHU Mao, et al. DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection[C]. The 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 21329–21338. doi: 10.1109/CVPR52688.2022.02067.
|
Figures(8) / Tables(3)



 DownLoad:
DownLoad: