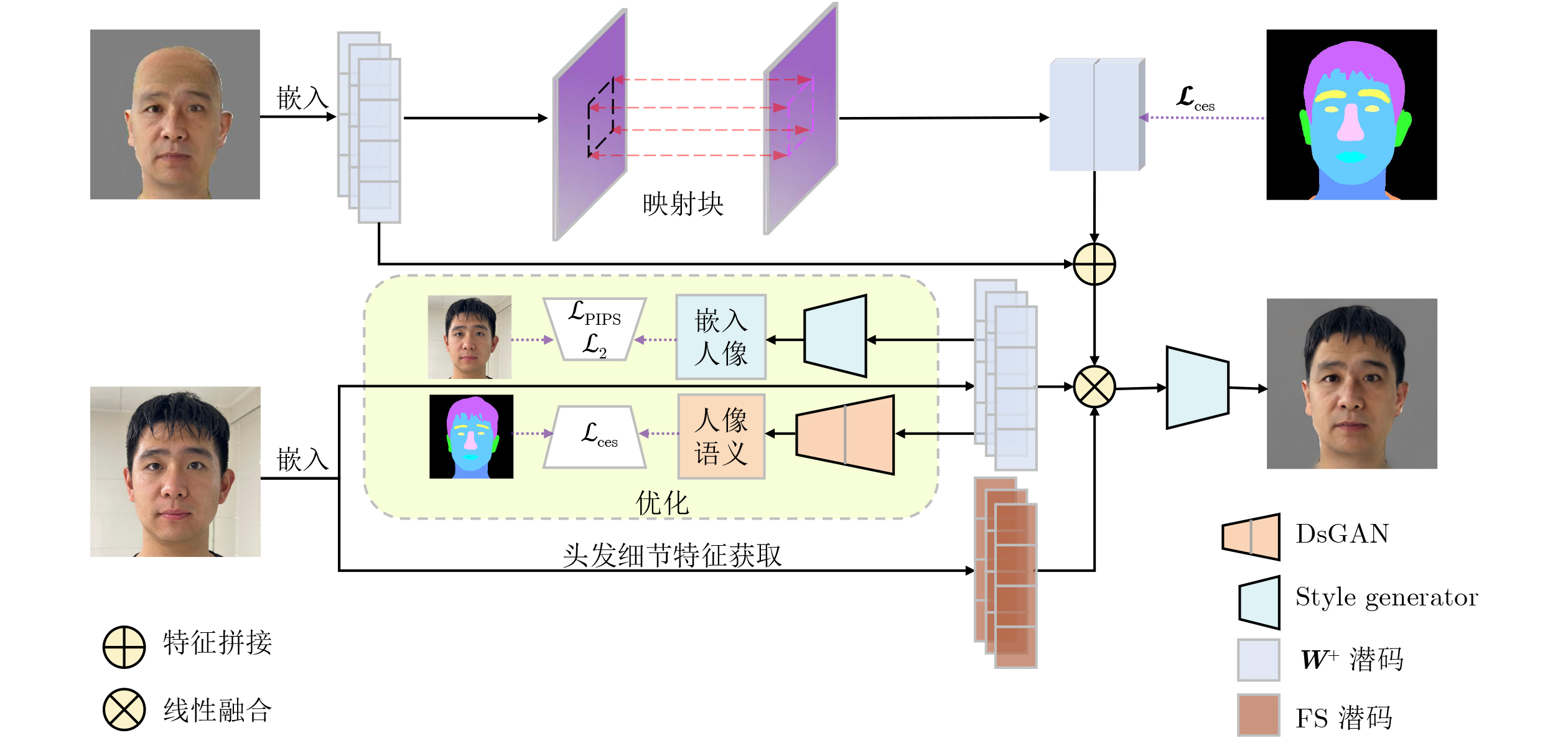
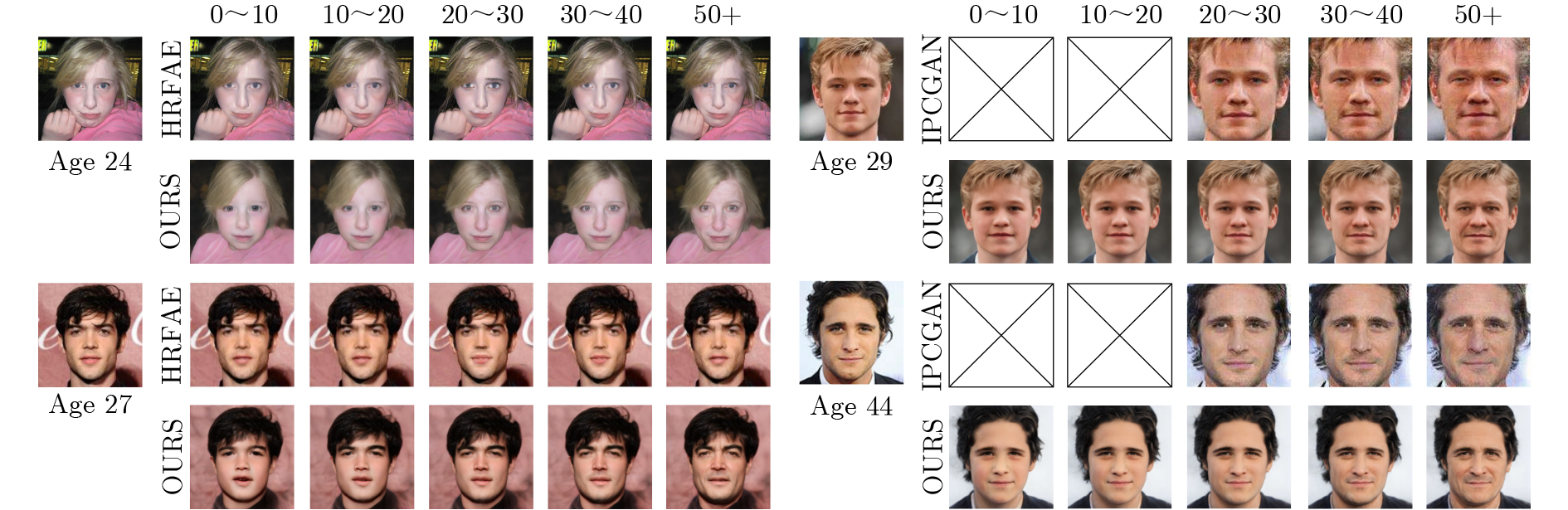
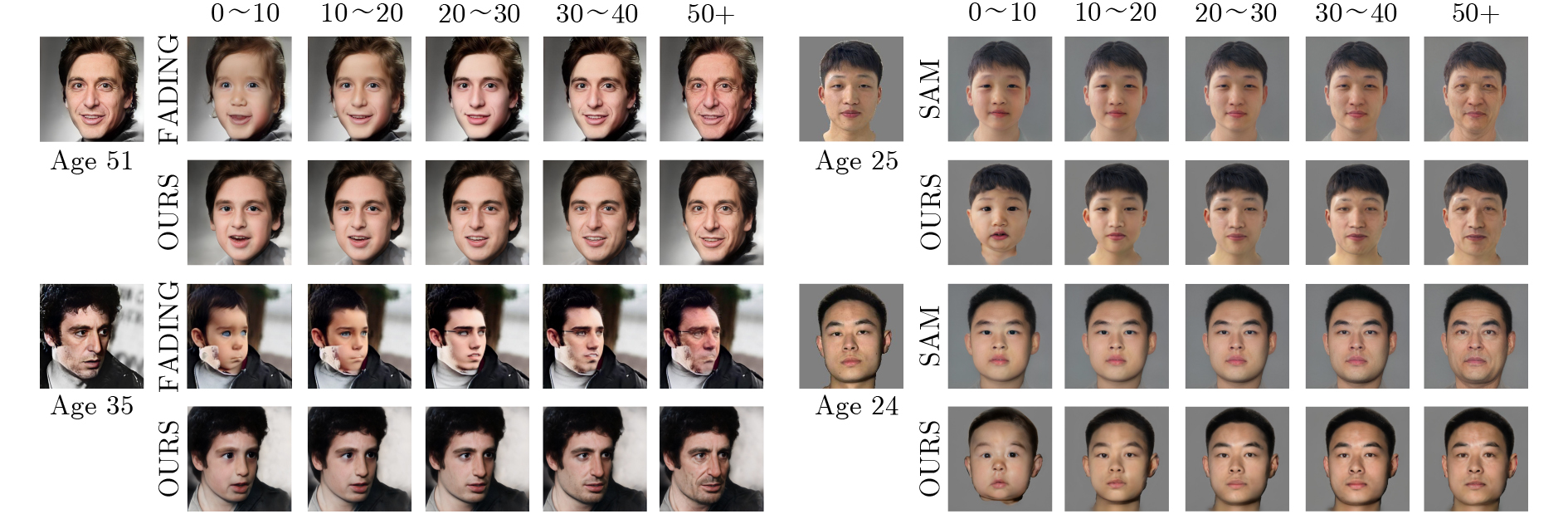
| Citation: | LIU Yaohui, LIU Jiaxin, SUN Peng, SHEN Zhe, LANG Yubo. Global-local Co-embedding and Semantic Mask-driven Aging Approach[J]. Journal of Electronics & Information Technology, 2025, 47(11): 4535-4548. doi: 10.11999/JEIT250430

|

| [1] |
ZHANG Zikang, YIN Songfeng, and CAO Liangcai. Age-invariant face recognition based on identity-age shared features[J]. The Visual Computer, 2024, 40(8): 5465–5474. doi: 10.1007/s00371-023-03116-1.
|
| [2] |
刘耀晖, 孙鹏, 郎宇博, 等. 复合因素影响下嫌疑人发型变化的深度模拟[J]. 计算机应用研究, 2025, 42(3): 955–960. doi: 10.19734/j.issn.1001-3695.2024.04.0215.
LIU Yaohui, SUN Peng, LANG Yubo, et al. Deep simulation of suspect hairstyles under influence of multiple factors[J]. Application Research of Computers, 2025, 42(3): 955–960. doi: 10.19734/j.issn.1001-3695.2024.04.0215.
|
| [3] |
SUO Jinli, CHEN Xilin, SHAN Shiguang, et al. A concatenational graph evolution aging model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2083–2096. doi: 10.1109/TPAMI.2012.22.
|
| [4] |
ROWLAND D A and PERRETT D I. Manipulating facial appearance through shape and color[J]. IEEE Computer Graphics and Applications, 1995, 15(5): 70–76. doi: 10.1109/38.403830.
|
| [5] |
KEMELMACHER-SHLIZERMAN I, SUWAJANAKORN S, and SEITZ S M. Illumination-aware age progression[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 3334–3341. doi: 10.1109/CVPR.2014.426.
|
| [6] |
ALALUF Y, PATASHNIK O, and COHEN-OR D. Only a matter of style: Age transformation using a style-based regression model[J]. ACM Transactions on Graphics (TOG), 2021, 40(4): 1–12. doi: 10.1145/3450626.3459805.
|
| [7] |
OR-EL R, SENGUPTA S, FRIED O, et al. Lifespan age transformation synthesis[C]. The 16th European Conference on Computer Vision – ECCV 2020, Glasgow, UK, 2020: 739–755. doi: 10.1007/978-3-030-58539-6_44.
|
| [8] |
HE Zhenliang, ZUO Wangmeng, KAN M, et al. AttGAN: Facial attribute editing by only changing what you want[J]. IEEE Transactions on Image Processing, 2019, 28(11): 5464–5478. doi: 10.1109/TIP.2019.2916751.
|
| [9] |
LIU Kanglin, CAO Gaofeng, ZHOU Fei, et al. Towards disentangling latent space for unsupervised semantic face editing[J]. IEEE Transactions on Image Processing, 2022, 31: 1475–1489. doi: 10.1109/TIP.2022.3142527.
|
| [10] |
ABDAL R, ZHU Peihao, MITRA N J, et al. StyleFlow: Attribute-conditioned exploration of styleGAN-generated images using conditional continuous normalizing flows[J]. ACM Transactions on Graphics (ToG), 2021, 40(3): 1–21. doi: 10.1145/3447648.
|
| [11] |
WANG Haoyi, SANCHEZ V, and LI C T. Cross-age contrastive learning for age-invariant face recognition[C]. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, South Korea, 2024: 4600–4604. doi: 10.1109/ICASSP48485.2024.10445859.
|
| [12] |
WANG Haoyi, SANCHEZ V, LI C T, et al. From age estimation to age-invariant face recognition: Generalized age feature extraction using order-enhanced contrastive learning[J]. IEEE Transactions on Information Forensics and Security, 2025, 20: 8525–8540. doi: 10.1109/TIFS.2025.3597187.
|
| [13] |
毛亮, 薛月菊, 魏颖慧, 等. 一种用于细粒度人脸识别的眼镜去除方法[J]. 电子与信息学报, 2021, 43(5): 1448–1456. doi: 10.11999/JEIT200176.
MAO Liang, XUE Yueju, WEI Yinghui, et al. An eyeglasses removal method for fine-grained face recognition[J]. Journal of Electronics & Information Technology, 2021, 43(5): 1448–1456. doi: 10.11999/JEIT200176.
|
| [14] |
夏垚铮, 郝蕾, 郑宛露, 等. 基于语义分离和特征融合的人脸编辑方法[J]. 计算机辅助设计与图形学学报, 2025, 37(3): 414–426. doi: 10.3724/SP.J.1089.2024-00305.
XIA Yaozheng, HAO Lei, ZHENG Wanlu, et al. An independent semantic and fused latent model for local face editing[J]. Journal of Computer-Aided Design & Computer Graphics, 2025, 37(3): 414–426. doi: 10.3724/SP.J.1089.2024-00305.
|
| [15] |
JIN Shiwei, WANG Zhen, WANG Lei, et al. ReDirTrans: Latent-to-latent translation for gaze and head redirection[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 5547–5556. doi: 10.1109/CVPR52729.2023.00537.
|
| [16] |
LI Qi, LIU Yunfan, SUN Zhenan. Age progression and regression with spatial attention modules[C]. Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 11378–11385. doi: 10.1609/aaai.v34i07.6800.
|
| [17] |
PARIHAR R, SACHIDANAND V S, MANI S, et al. PreciseControl: Enhancing text-to-image diffusion models with fine-grained attribute control[C]. The 18th European Conference on Computer Vision – ECCV 2024, Milan, Italy, 2025: 469–487. doi: 10.1007/978-3-031-73007-8_27.
|
| [18] |
CHANDALIYA P K and NAIN N. AW-GAN: Face aging and rejuvenation using attention with wavelet GAN[J]. Neural Computing and Applications, 2023, 35(3): 2811–2825. doi: 10.1007/s00521-022-07721-4.
|
| [19] |
HOU Chen, WEI Guoqiang, and CHEN Zhibo. High-fidelity diffusion-based image editing[C]. The Thirty-Eighth AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 2184–2192. doi: 10.1609/aaai.v38i3.27991.
|
| [20] |
桂列林, 黄山, 印月. 结合Pixel2style2Pixel的年龄转化方法[J]. 计算机工程与应用, 2024, 60(14): 162–174. doi: 10.3778/j.issn.1002-8331.2304-0007.
GUI Lielin, HUANG Shan, and YIN Yue. Age transformation method combined with Pixel2style2Pixel[J]. Computer Engineering and Applications, 2024, 60(14): 162–174. doi: 10.3778/j.issn.1002-8331.2304-0007.
|
| [21] |
SHU Xiangbo, TANG Jinhui, LAI Hanjiang, et al. Personalized age progression with aging dictionary[C]. 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2015: 3970–3978. doi: 10.1109/ICCV.2015.452.
|
| [22] |
张珂, 于婷婷, 石超君, 等. 融合通道位置注意力机制和并行空洞卷积的人脸年龄合成[J]. 中国图象图形学报, 2023, 28(12): 3870–3883. doi: 10.11834/jig.230007.
ZHANG Ke, YU Tingting, SHI Chaojun, et al. Face age synthesis fusing channel-coordinate attention mechanism and parallel dilated convolution[J]. Journal of Image and Graphics, 2023, 28(12): 3870–3883. doi: 10.11834/jig.230007.
|
| [23] |
YANG Shuai, JIANG Liming, LIU Ziwei, et al. GP-UNIT: Generative prior for versatile unsupervised image-to-image translation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 11869–11883. doi: 10.1109/TPAMI.2023.3284003.
|
| [24] |
任坤, 李峥瑱, 桂源泽, 等. 低分辨率随机遮挡人脸图像的超分辨率修复[J]. 电子与信息学报, 2024, 46(8): 3343–3352. doi: 10.11999/JEIT231262.
REN Kun, LI Zhengzhen, GUI Yuanze, et al. Super-resolution restoration of low-resolution randomly occluded face images[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3343–3352. doi: 10.11999/JEIT231262.
|
| [25] |
赵宏, 李文改. 基于扩散生成对抗网络的文本生成图像模型研究[J]. 电子与信息学报, 2023, 45(12): 4371–4381. doi: 10.11999/JEIT221400.
ZHAO Hong and LI Wengai. Text-to-image generation model based on diffusion wasserstein generative adversarial networks[J]. Journal of Electronics & Information Technology, 2023, 45(12): 4371–4381. doi: 10.11999/JEIT221400.
|
| [26] |
郭璠, 刘文韬, 杨佳男, 等. 基于半解析模型的夜间雾天图像生成算法[J]. 通信学报, 2025, 46(4): 129–143. doi: 10.11959/j.issn.1000-436x.2025061.
GUO Fan, LIU Wentao, YANG Jianan, et al. Nighttime foggy image generation algorithm based on semi-analytic model[J]. Journal on Communications, 2025, 46(4): 129–143. doi: 10.11959/j.issn.1000-436x.2025061.
|
| [27] |
KARRAS T, AITTALA M, HELLSTEN J, et al. Training generative adversarial networks with limited data[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 12104–12114.
|
| [28] |
KARRAS T, LAINE S, AITTALA M, et al. Analyzing and improving the image quality of styleGAN[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 8107–8116. doi: 10.1109/CVPR42600.2020.00813.
|
| [29] |
RICHARDSON E, ALALUF Y, PATASHNIK O, et al. Encoding in style: A styleGAN encoder for image-to-image translation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 2287–2296. doi: 10.1109/CVPR46437.2021.00232.
|
| [30] |
WEI Tianyi, CHEN Dongdong, ZHOU Wenbo, et al. E2Style: Improve the efficiency and effectiveness of StyleGAN inversion[J]. IEEE Transactions on Image Processing, 2022, 31: 3267–3280. doi: 10.1109/TIP.2022.3167305.
|
| [31] |
ABDAL R, QIN Yipeng, and WONKA P. Image2StyleGAN: How to embed images into the styleGAN latent space?[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 2019: 4431–4440. doi: 10.1109/ICCV.2019.00453.
|
| [32] |
TEWARI A, ELGHARIB M, R M B, et al. PIE: Portrait image embedding for semantic control[J]. ACM Transactions on Graphics (TOG), 2020, 39(6): 223 doi: 10.1145/3414685.3417803.
|
| [33] |
ZHU Peihao, ABDAL R, QIN Yipeng, et al. Improved StyleGAN embedding: Where are the good latents?[DB/OL]. arXiv preprint arXiv: 2012.09036, 2020. https://arxiv.org/abs/2012.09036?context=cs.
|
| [34] |
DENTON R, HUTCHINSON B, MITCHELL M, et al. Image counterfactual sensitivity analysis for detecting unintended bias[DB/OL]. arXiv preprint arXiv: 1906.06439, 2019. https://arxiv.org/abs/1906.06439v3.
|
| [35] |
GOETSCHALCKX L, ANDONIAN A, OLIVA A, et al. GANalyze: Toward visual definitions of cognitive image properties[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 2019: 5743–5752. doi: 10.1109/ICCV.2019.00584.
|
| [36] |
SHEN Yujun, GU Jinjin, TANG Xiaoou, et al. Interpreting the latent space of GANs for semantic face editing[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 9240–9249. doi: 10.1109/CVPR42600.2020.00926.
|
| [37] |
HÄRKÖNEN E, HERTZMANN A, LEHTINEN J, et al. GANSpace: Discovering interpretable GAN controls[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020, 33: 9841–9850.
|
| [38] |
VOYNOV A and BABENKO A. Unsupervised discovery of interpretable directions in the GAN latent space[C]. The 37th International Conference on Machine Learning, Vienna, Austria, 2020: 9786–9796.
|
| [39] |
WANG Binxu and PONCE C R. The geometry of deep generative image models and its applications[J]. arXiv preprint arXiv: 2101.06006, 2021. doi: 10.48550/arXiv.2101.06006.
|
| [40] |
TEWARI A, ELGHARIB M, BHARAJ G, et al. StyleRig: Rigging styleGAN for 3D control over portrait images[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 6141–6150. doi: 10.1109/CVPR42600.2020.00618.
|
| [41] |
YANG Hongyu, HUANG Di, WANG Yunhong, et al. Learning face age progression: A pyramid architecture of GANs[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 31–39. doi: 10.1109/CVPR.2018.00011.
|
| [42] |
LIU Yunfan, LI Qi, and SUN Zhenan. Attribute-aware face aging with wavelet-based generative adversarial networks[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 11869–11878. doi: 10.1109/CVPR.2019.01215.
|
| [43] |
HUANG Zhizhong, CHEN Shouzhen, ZHANG Junping, et al. PFA-GAN: Progressive face aging with generative adversarial network[J]. IEEE Transactions on Information Forensics and Security, 2021, 16: 2031–2045. doi: 10.1109/TIFS.2020.3047753.
|
| [44] |
SHEN Yujun, ZHOU Bolei, LUO Ping, et al. FaceFeat-GAN: A two-stage approach for identity-preserving face synthesis[J]. arXiv preprint arXiv: 1812.01288, 2018. doi: 10.48550/arXiv.1812.01288.
|
| [45] |
YU Changqian, WANG Jingbo, PENG Chao, et al. Bisenet: Bilateral segmentation network for real-time semantic segmentation[C]. The 15th European Conference on Computer Vision – ECCV 2018, Munich, Germany, 2018: 334–349. doi: 10.1007/978-3-030-01261-8_20.
|
| [46] |
TELEA A. An image inpainting technique based on the fast marching method[J]. Journal of Graphics Tools, 2004, 9(1): 23–34. doi: 10.1080/10867651.2004.10487596.
|
| [47] |
GOMEZ-TRENADO G, LATHUILIÈRE S, MESEJO P, et al. Custom structure preservation in face aging[C]. The 17th European Conference on Computer Vision – ECCV 2022, Tel Aviv, Israel, 2022: 565–580. doi: 10.1007/978-3-031-19787-1_32.
|
| [48] |
YAO Xu, PUY G, NEWSON A, et al. High resolution face age editing[C]. 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 2021: 8624–8631. doi: 10.1109/ICPR48806.2021.9412383.
|
| [49] |
CHEN Xiangyi and LATHUILIÈRE S. Face aging via diffusion-based editing[J]. arXiv preprint arXiv: 2309.11321, 2023. doi: 10.48550/arXiv.2309.11321.
|

Figures(6) / Tables(3)



 DownLoad:
DownLoad: