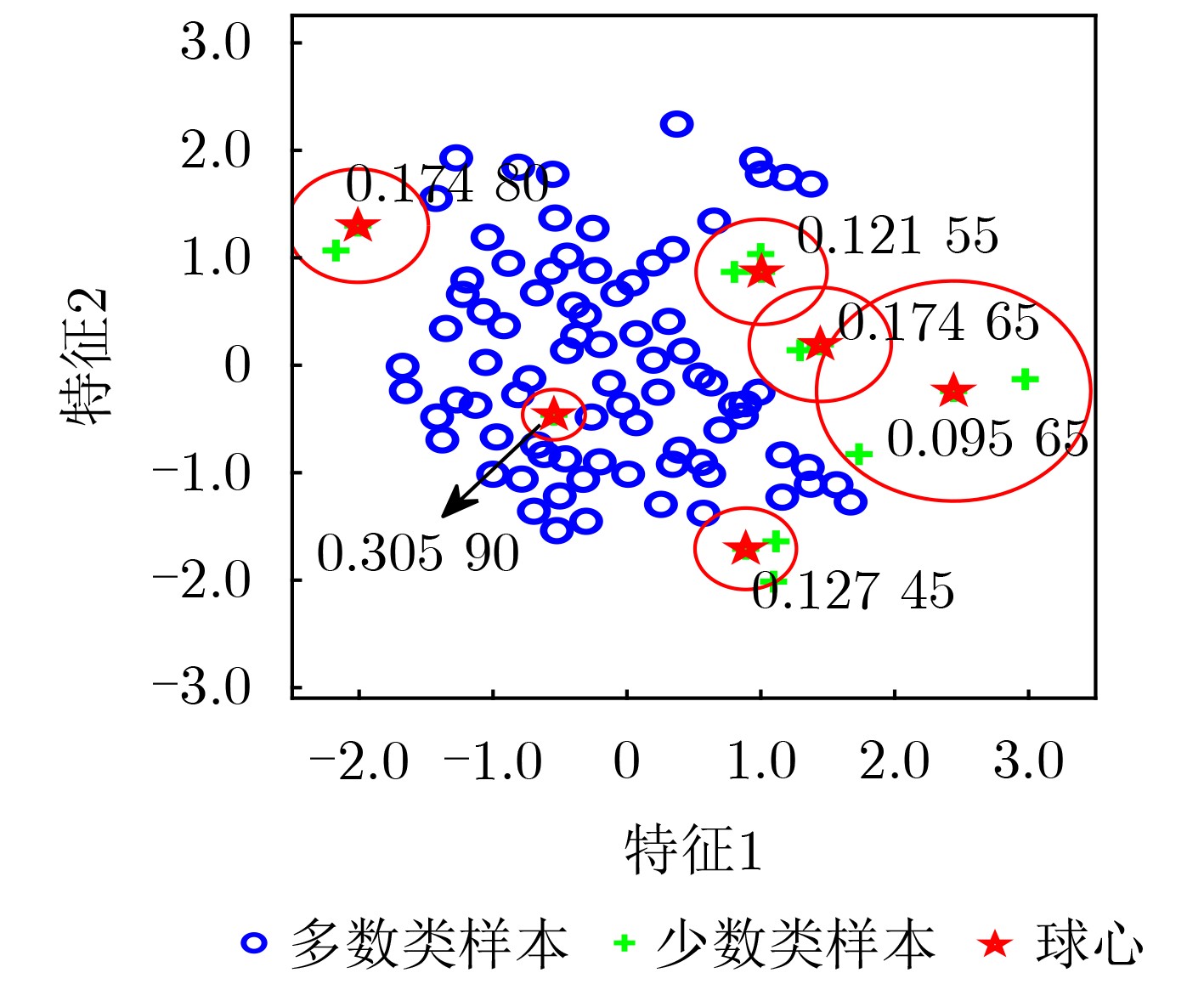
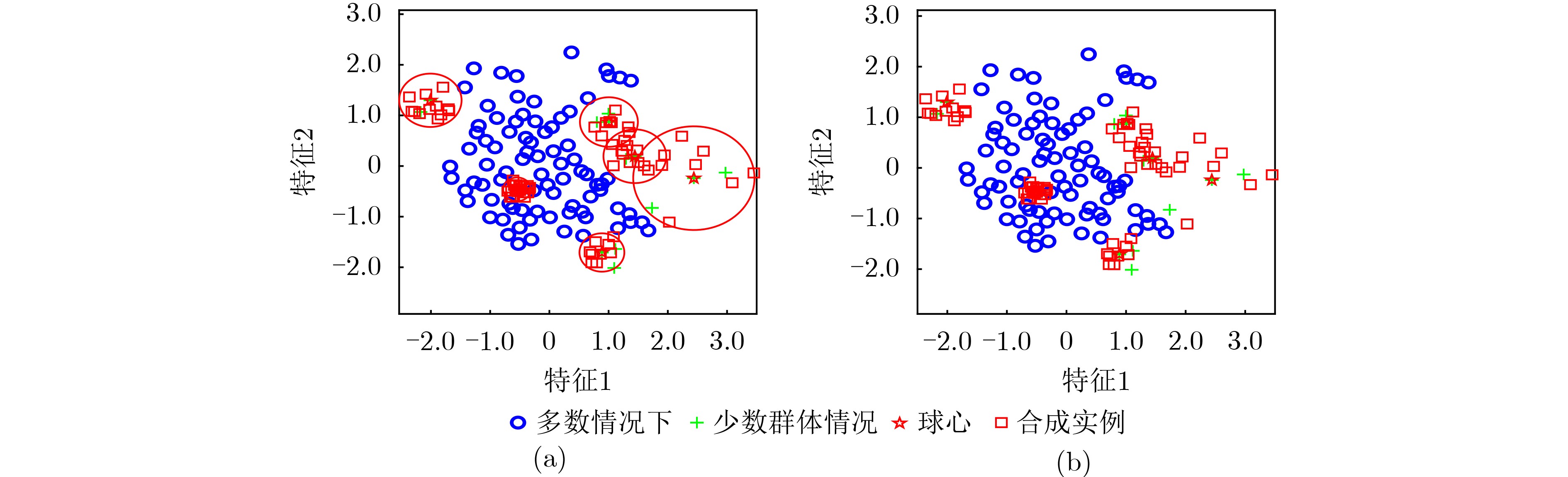
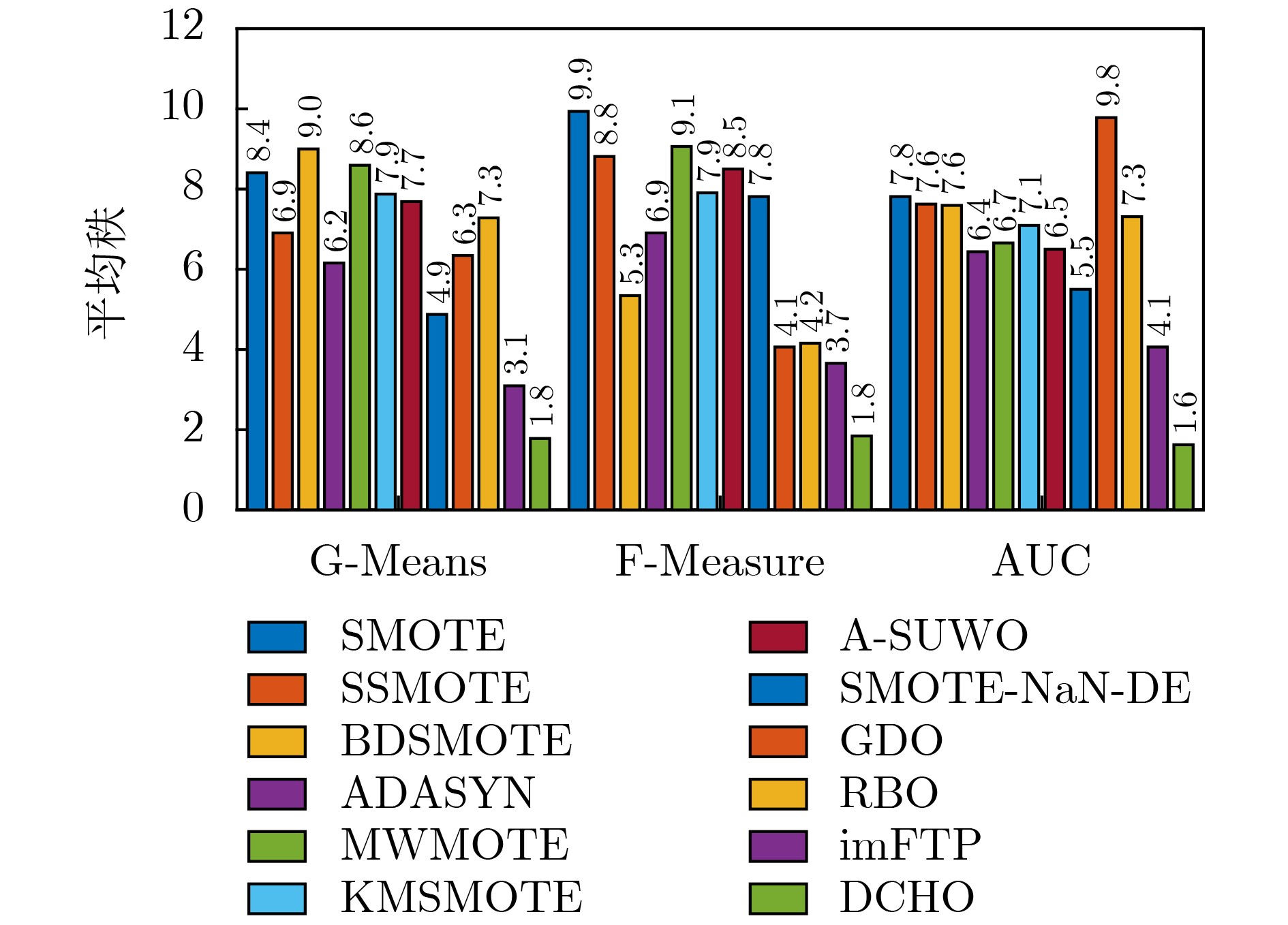
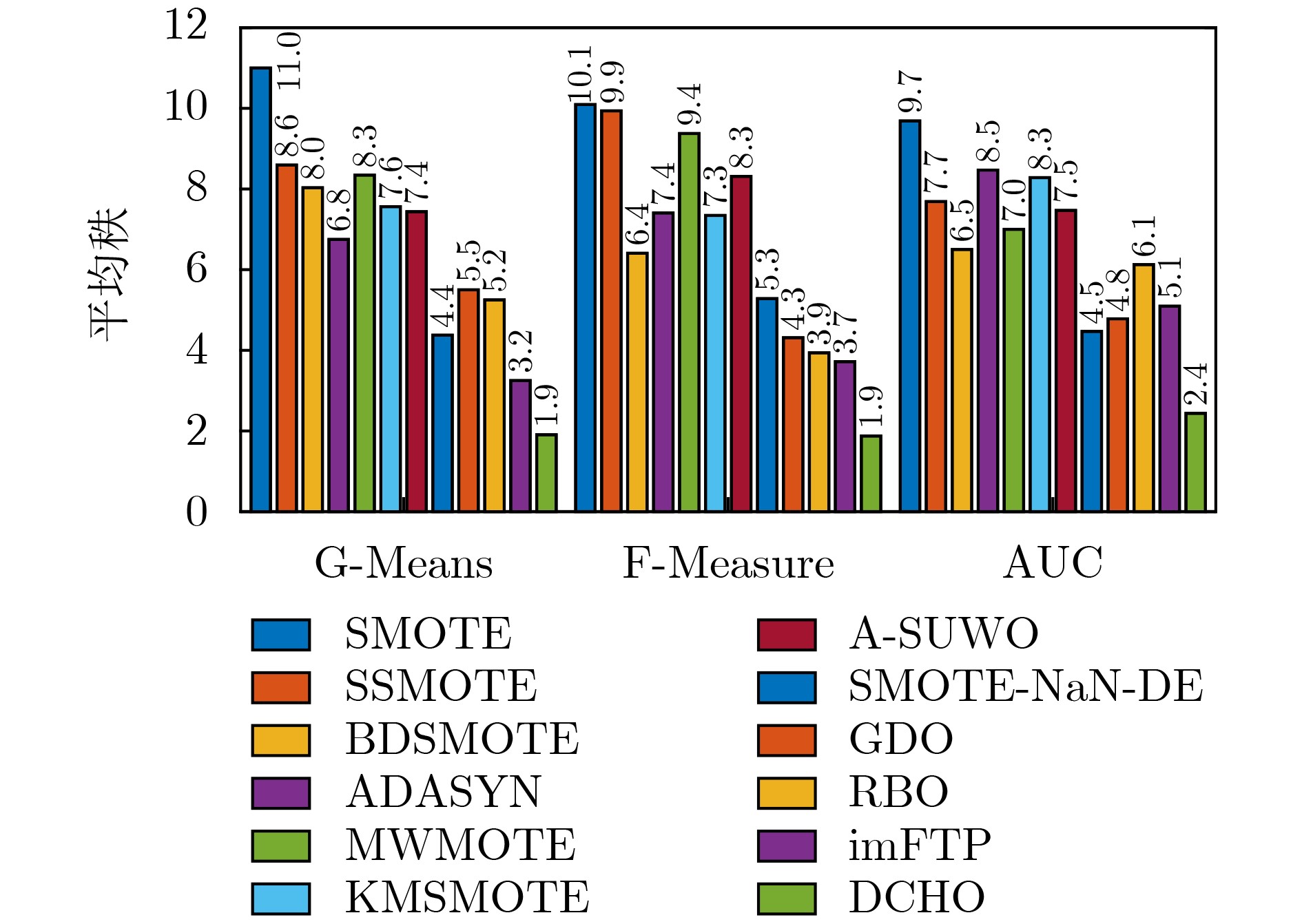
| Citation: | TAO Xinmin, LI Junxuan, GUO Xinyue, SHI Lihang, XU Annan, ZHANG Yanping. Density Clustering Hypersphere-based Self-adaptively Oversampling Algorithm for Imbalanced Datasets[J]. Journal of Electronics & Information Technology, 2025, 47(7): 2347-2360. doi: 10.11999/JEIT241037

|

| [1] |
CHEN Zhuohang, CHEN Jinglong, FENG Yong, et al. Imbalance fault diagnosis under long-tailed distribution: Challenges, solutions and prospects[J]. Knowledge-Based Systems, 2022, 258: 110008. doi: 10.1016/J.KNOSYS.2022.110008.
|
| [2] |
CHEN Zheng, YANG Chen, ZHU Meilu, et al. Personalized retrogress-resilient federated learning toward imbalanced medical data[J]. IEEE Transactions on Medical Imaging, 2022, 41(12): 3663–3674. doi: 10.1109/TMI.2022.3192483.
|
| [3] |
TENG Hu, WANG Cheng, YANG Qing, et al. Leveraging adversarial augmentation on imbalance data for online trading fraud detection[J]. IEEE Transactions on Computational Social Systems, 2024, 11(2): 1602–1614. doi: 10.1109/TCSS.2023.3240968.
|
| [4] |
BLANCHARD A E, GAO Shang, YOON H J, et al. A keyword-enhanced approach to handle class imbalance in clinical text classification[J]. IEEE Journal of Biomedical and Health Informatics, 2022, 26(6): 2796–2803. doi: 10.1109/JBHI.2022.3141976.
|
| [5] |
CHEN M F, NACHMAN B, and SALA F. Resonant anomaly detection with multiple reference datasets[J]. Journal of High Energy Physics, 2023, 2023(7): 188. doi: 10.1007/JHEP07(2023)188.
|
| [6] |
高雷阜, 张梦瑶, 赵世杰. 融合簇边界移动与自适应合成的混合采样算法[J]. 电子学报, 2022, 50(10): 2517–2529. doi: 10.12263/DZXB.20210265.
GAO Leifu, ZHANG Mengyao, and ZHAO Shijie. Mixed-sampling algorithm combining cluster boundary movement and adaptive synthesis[J]. Acta Electronica Sinica, 2022, 50(10): 2517–2529. doi: 10.12263/DZXB.20210265.
|
| [7] |
职为梅, 常智, 卢俊华, 等. 面向不平衡图像数据的对抗自编码器过采样算法[J]. 电子与信息学报, 2024, 46(11): 4208–4218. doi: 10.11999/JEIT240330.
ZHI Weimei, CHANG Zhi, LU Junhua, et al. Adversarial autoencoders oversampling algorithm for imbalanced image data[J]. Journal of Electronics & Information Technology, 2024, 46(11): 4208–4218. doi: 10.11999/JEIT240330.
|
| [8] |
DU Guodong, ZHANG Jia, JIANG Min, et al. Graph-based class-imbalance learning with label enhancement[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(9): 6081–6095. doi: 10.1109/TNNLS.2021.3133262.
|
| [9] |
JIN Xiaoyu, XIAO Fu, ZHANG Chong, et al. GEIN: An interpretable benchmarking framework towards all building types based on machine learning[J]. Energy and Buildings, 2022, 260: 111909. doi: 10.1016/J.ENBUILD.2022.111909.
|
| [10] |
李帆, 张小恒, 李勇明, 等. 基于包络学习和分级结构一致性机制的不平衡集成算法[J]. 电子学报, 2024, 52(3): 751–761. doi: 10.12263/DZXB.20220712.
LI Fan, ZHANG Xiaoheng, LI Yongming, et al. Imbalanced ensemble algorithm based on envelope learning and hierarchical structure consistency mechanism[J]. Acta Electronica Sinica, 2024, 52(3): 751–761. doi: 10.12263/DZXB.20220712.
|
| [11] |
LI Yanjiao, ZHANG Jie, ZHANG Sen, et al. Multi-objective optimization-based adaptive class-specific cost extreme learning machine for imbalanced classification[J]. Neurocomputing, 2022, 496: 107–120. doi: 10.1016/J.NEUCOM.2022.05.008.
|
| [12] |
孙中彬, 刁宇轩, 马苏洋. 基于安全欠采样的不均衡多标签数据集成学习方法[J]. 电子学报, 2024, 52(10): 3392–3408. doi: 10.12263/DZXB.20240210.
SUN Zhongbin, DIAO Yuxuan, and MA Suyang. An imbalanced multi-label data ensemble learning method based on safe under-sampling[J]. Acta Electronica Sinica, 2024, 52(10): 3392–3408. doi: 10.12263/DZXB.20240210.
|
| [13] |
TAO Xinmin, CHEN Wei, ZHANG Xiaohan, et al. SVDD boundary and DPC clustering technique-based oversampling approach for handling imbalanced and overlapped data[J]. Knowledge-Based Systems, 2021, 234: 107588. doi: 10.1016/J.KNOSYS.2021.107588.
|
| [14] |
SUN Zhongqiang, YING Wenhao, ZHANG Wenjin, et al. Undersampling method based on minority class density for imbalanced data[J]. Expert Systems with Applications, 2024, 249: 123328. doi: 10.1016/J.ESWA.2024.123328.
|
| [15] |
MA Tingting, LU Shuxia, and JIANG Chen. A membership-based resampling and cleaning algorithm for multi-class imbalanced overlapping data[J]. Expert Systems with Applications, 2024, 240: 122565. doi: 10.1016/J.ESWA.2023.122565.
|
| [16] |
TAO Xinmin, GUO Xinyue, ZHENG Yujia, et al. Self-adaptive oversampling method based on the complexity of minority data in imbalanced datasets classification[J]. Knowledge-Based Systems, 2023, 277: 110795. doi: 10.1016/J.KNOSYS.2023.110795.
|
| [17] |
LÓPEZ V ,FERNÁNDEZ A ,GARCÍA S, et al. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics[J]. Information Sciences, 2013, 250: doi: 10.1016/j.ins.2013.07.007113-141. 2.
|
| [18] |
TAO Xinmin, ZHANG Xiaohan, ZHENG Yujia, et al. A MeanShift-guided oversampling with self-adaptive sizes for imbalanced data classification[J]. Information Sciences, 2024, 672: 120699. doi: 10.1016/J.INS.2024.120699.
|
| [19] |
JIANG Zhen, ZHAO Lingyun, LU Yu, et al. A semi-supervised resampling method for class-imbalanced learning[J]. Expert Systems with Applications, 2023, 221: 119733. doi: 10.1016/J.ESWA.2023.119733.
|
| [20] |
BUNKHUMPORNPAT C, SINAPIROMSARAN K, and LURSINSAP C. Safe-Level-SMOTE: Safe-level-synthetic minority over-sampling TEchnique for handling the class imbalanced problem[C]. The 13th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, Bangkok, Thailand, 2009. doi: 10.1007/978-3-642-01307-2_43.
|
| [21] |
LI Min, ZHOU Hao, LIU Qun, et al. WRND: A weighted oversampling framework with relative neighborhood density for imbalanced noisy classification[J]. Expert Systems with Applications, 2024, 241: 122593. doi: 10.1016/j.eswa.2023.122593.
|
| [22] |
PAN Tingting, ZHAO Junhong, WU Wei, et al. Learning imbalanced datasets based on SMOTE and Gaussian distribution[J]. Information Sciences, 2020, 512: 1214–1233. doi: 10.1016/j.ins.2019.10.048.
|
| [23] |
HAN Hui, WANG Wenyuan, and MAO Binghua. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning[C]. The International Conference on Intelligent Computing Advances in Intelligent Computing, Hefei, China, 2005: 878–887. doi: 10.1007/11538059_91.
|
| [24] |
HE Haibo, BAI Yang, GARCIA E A, et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning[C]. 2008 IEEE International Joint Conference on Neural Networks, Hong Kong, China, 2008: 1322–1328. doi: 10.1109/IJCNN.2008.4633969.
|
| [25] |
BARUA S, ISLAM M, YAO Xin, et al. MWMOTE--majority weighted minority oversampling technique for imbalanced data set learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(2): 405–425. doi: 10.1109/TKDE.2012.232.
|
| [26] |
MATHARAARACHCHI S, DOMARATZKI M, and MUTHUKUMARANA S. Enhancing SMOTE for imbalanced data with abnormal minority instances[J]. Machine Learning with Applications, 2024, 18: 100597. doi: 10.1016/J.MLWA.2024.100597.
|
| [27] |
KOZIARSKI M, KRAWCZYK B, and WOŹNIAK M. Radial-Based oversampling for noisy imbalanced data classification[J]. Neurocomputing, 2019, 343: 19–33. doi: 10.1016/j.neucom.2018.04.089.
|
| [28] |
DOUZAS G and BACAO F. Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE[J]. Information Sciences, 2019, 501: 118–135. doi: 10.1016/j.ins.2019.06.007.
|
| [29] |
XIE Yuxi, QIU Min, ZHANG Haibo, et al. Gaussian distribution based oversampling for imbalanced data classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(2): 667–679. doi: 10.1109/tkde.2020.2985965.
|
| [30] |
HOU Yaxin, DING Weiping, and ZHANG Chongsheng. imFTP: Deep imbalance learning via fuzzy transition and prototypical learning[J]. Information Sciences, 2024, 679: 121071. doi: 10.1016/J.INS.2024.121071.
|
| [31] |
LI Chuang, MAO Zhizhong, and JIA Mingxing. A real-valued label noise cleaning method based on ensemble iterative filtering with noise score[J]. International Journal of Machine Learning and Cybernetics, 2024, 15(9): 4093–4118. doi: 10.1007/S13042-024-02137-Z.
|
| [32] |
LAURIKKALA J. Improving identification of difficult small classes by balancing class distribution[C]. The 8th Conference on Artificial Intelligence in Medicine in Europe Artificial Intelligence in Medicine, Cascais, Portugal, 2001: 63–66. doi: 10.1007/3-540-48229-6_9.
|
| [33] |
NAPIERAŁA K, STEFANOWSKI J, and WILK S. Learning from imbalanced data in presence of noisy and borderline examples[C]. The 7th International Conference on Rough Sets and Current Trends in Computing, Warsaw, Poland, 2010: 158–167. doi: 10.1007/978-3-642-13529-3_18.
|
| [34] |
SÁEZ J A, LUENGO J, STEFANOWSKI J, et al. SMOTE-IPF: Addressing the noisy and borderline examples problem in imbalanced classification by a re-sampling method with filtering[J]. Information Sciences, 2015, 291: 184–203. doi: 10.1016/j.ins.2014.08.051.
|
| [35] |
LI Junnan, ZHU Qingsheng, WU Quanwang, et al. SMOTE-NaN-DE: Addressing the noisy and borderline examples problem in imbalanced classification by natural neighbors and differential evolution[J]. Knowledge-Based Systems, 2021, 223: 107056. doi: 10.1016/J.KNOSYS.2021.107056.
|
| [36] |
SHI Hua, WU Chenjin, BAI Tao, et al. Identify essential genes based on clustering based synthetic minority oversampling technique[J]. Computers in Biology and Medicine, 2023, 153: 106523. doi: 10.1016/J.COMPBIOMED.2022.106523.
|
| [37] |
DOUZAS G, BACAO F, and LAST F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE[J]. Information Sciences, 2018, 465: 1–20. doi: 10.1016/j.ins.2018.06.056.
|
| [38] |
SONG Jia, HUANG Xianglin, QIN Sijun, et al. A bi-directional sampling based on K-means method for imbalance text classification[C]. 2016 IEEE/ACIS 15th International Conference on Computer and Information Science, Okayama, Japan, 2016: 1–5. doi: 10.1109/ICIS.2016.7550920.
|
| [39] |
NEKOOEIMEHR I and LAI-YUEN S K. Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets[J]. Expert Systems with Applications, 2016, 46: 405–416. doi: 10.1016/j.eswa.2015.10.031.
|
| [40] |
WEI Jianan, HUANG Haisong, YAO Liguo, et al. IA-SUWO: An improving adaptive semi-unsupervised weighted oversampling for imbalanced classification problems[J]. Knowledge-Based Systems, 2020, 203: 106116. doi: 10.1016/j.knosys.2020.106116.
|
| [41] |
RODRIGUEZ A and LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492–1496. doi: 10.1126/science.1242072.
|
| [42] |
Machine learning repository UCI[EB/OL]. http://archive.ics.uci.edu/ml/datasets.html.
|

Figures(11) / Tables(5)



 DownLoad:
DownLoad: