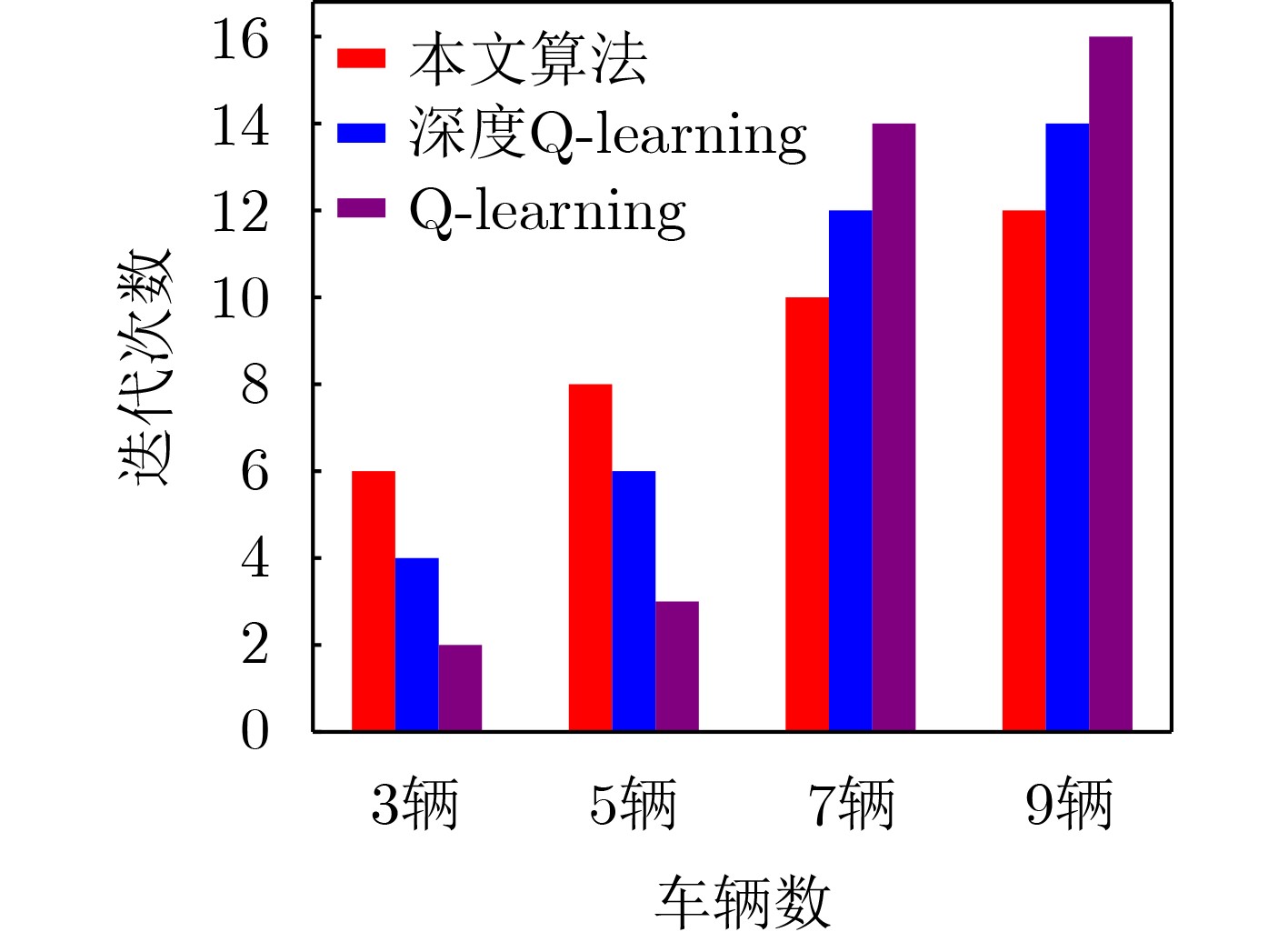
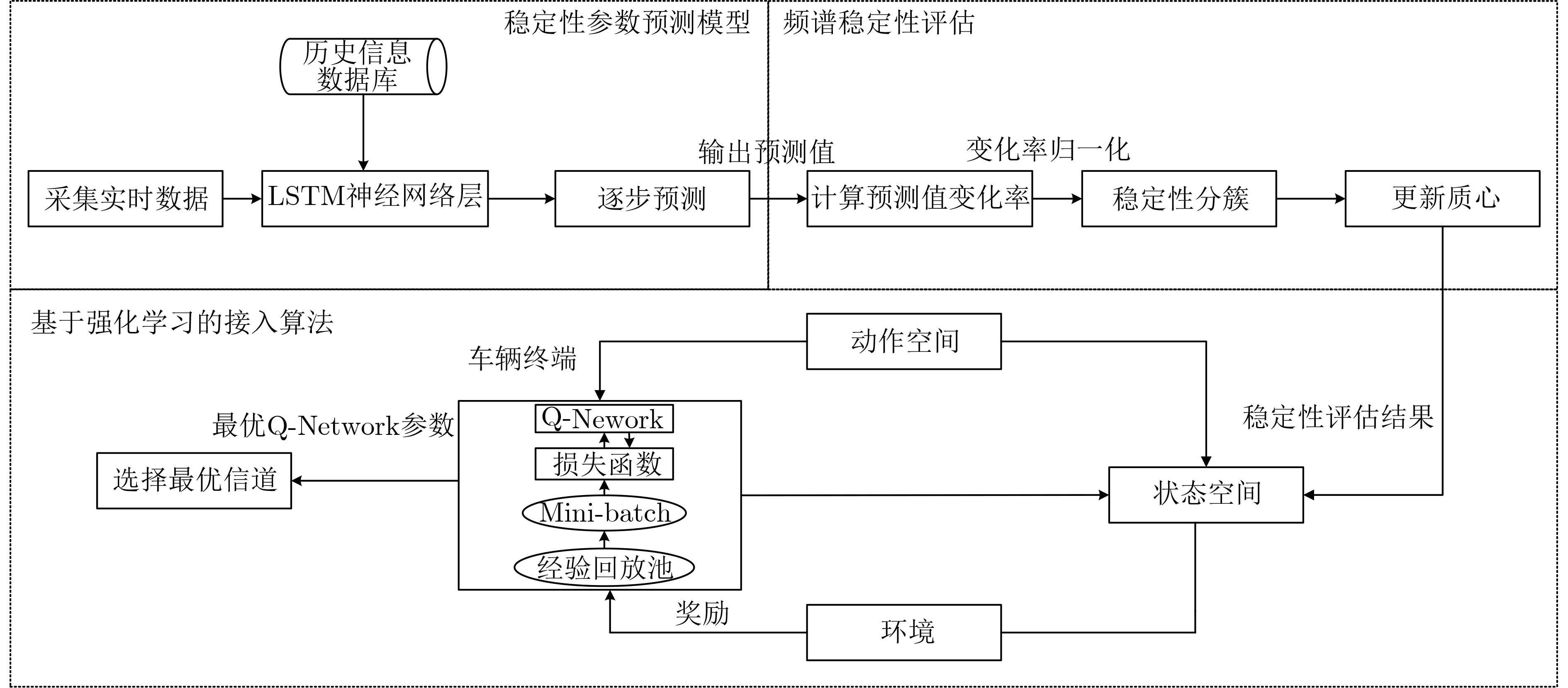
| Citation: | MA Bin, YANG Zumin, XIE Xianzhong. Dynamic Spectrum Access Algorithm for Evaluating Spectrum Stability in Cognitive Vehicular Networks.[J]. Journal of Electronics & Information Technology, 2025, 47(5): 1474-1485. doi: 10.11999/JEIT240927

|

| [1] |
CHUANG M C. Cooperation-assisted spectrum handover mechanism in vehicular Ad Hoc networks[J]. Electronics, 2021, 10(6): 742. doi: 10.3390/electronics10060742.
|
| [2] |
CHENG Nan, ZHANG Ning, LU Ning, et al. Opportunistic spectrum access for CR-VANETs: A game-theoretic approach[J]. IEEE Transactions on Vehicular Technology, 2014, 63(1): 237–251. doi: 10.1109/TVT.2013.2274201.
|
| [3] |
NIYATO D, HOSSAIN E, and WANG Ping. Optimal channel access management with QoS support for cognitive vehicular networks[J]. IEEE Transactions on Mobile Computing, 2011, 10(4): 573–591. doi: 10.1109/TMC.2010.191.
|
| [4] |
XIANG Ping, SHAN Hangguan, WANG Miao, et al. Multi-agent RL enables decentralized spectrum access in vehicular networks[J]. IEEE Transactions on Vehicular Technology, 2021, 70(10): 10750–10762. doi: 10.1109/TVT.2021.3103058.
|
| [5] |
SANGIORGIO M and DERCOLE F. Robustness of LSTM neural networks for multi-step forecasting of chaotic time series[J]. Chaos, Solitons & Fractals, 2020, 139: 110045.
|
| [6] |
BALDI P and SADOWSKI P. The dropout learning algorithm[J]. Artificial Intelligence, 2014, 210: 78–122. doi: 10.1016/j.artint.2014.02.004.
|
| [7] |
KODINARIYA T M and MAKWANA P R. Review on determining number of cluster in K-Means clustering[J]. International Journal of Advance Research in Computer Science and Management Studies, 2013, 1(6): 90–95.
|
| [8] |
ALI P J M. Investigating the Impact of min-max data normalization on the regression performance of K-nearest neighbor with different similarity measurements[J]. ARO-The Scientific Journal of Koya University, 2022, 10(1): 85–91. doi: 10.14500/aro.10955.
|
| [9] |
NEVES D E, ISHITANI L, and DO PATROCÍNIO JÚNIOR Z K G. Advances and challenges in learning from experience replay[J]. Artificial Intelligence Review, 2024, 58(2): 54. doi: 10.1007/s10462-024-11062-0.
|
| [10] |
MAHJOUB S, CHRIFI-ALAOUI L, MARHIC B, et al. Predicting energy consumption using LSTM, multi-layer GRU and drop-GRU neural networks[J]. Sensors, 2022, 22(11): 4062. doi: 10.3390/s22114062.
|
| [11] |
ZHOU Tianchen, YAKUWA Y, OKAMURA N, et al. Dueling network architecture for GNN in the deep reinforcement learning for the automated ICT system design[J]. IEEE Access, 2025, 13: 21870–21879. doi: 10.1109/ACCESS.2025.3534246.
|
| [12] |
CHANG H H, SONG Hao, YI Yang, et al. Distributive dynamic spectrum access through deep reinforcement learning: A reservoir computing based approach[J]. IEEE Internet of Things Journal, 2019, 6(2): 1938–1948. doi: 10.1109/JIOT.2018.2872441.
|
| [13] |
LE T D and KADDOUM G. A distributed channel access scheme for vehicles in multi-agent V2I systems[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(4): 1297–1307. doi: 10.1109/TCCN.2020.2966604.
|
| [14] |
CHEN Lingling, ZHAO Quanjun, FU Ke, et al. Multi-user reinforcement learning based multi-reward for spectrum access in cognitive vehicular networks[J]. Telecommunication Systems, 2023, 83(1): 51–65. doi: 10.1007/s11235-023-01004-6.
|
| [15] |
CHEN Lingling, WANG Ziwei, ZHAO Xiaohui, et al. A dynamic spectrum access algorithm based on deep reinforcement learning with novel multi-vehicle reward functions in cognitive vehicular networks[J]. Telecommunication Systems, 2024, 87(2): 359–383. doi: 10.1007/s11235-024-01188-5.
|
| [16] |
KAR K, SARKAR S, and TASSIULAS L. Achieving proportional fairness using local information in aloha networks[J]. IEEE Transactions on Automatic Control, 2004, 49(10): 1858–1863. doi: 10.1109/TAC.2004.835596.
|
| [17] |
LE T D and KADDOUM G. LSTM-based channel access scheme for vehicles in cognitive vehicular networks with multi-agent settings[J]. IEEE Transactions on Vehicular Technology, 2021, 70(9): 9132–9143. doi: 10.1109/TVT.2021.3100591.
|
| [18] |
WANG Lei, HU Jun, ZHANG Chudi, et al. Deep learning models for spectrum prediction: A review[J]. IEEE Sensors Journal, 2024, 24(18): 28553–28575. doi: 10.1109/JSEN.2024.3416738.
|
| [19] |
陈曦, 杨健. 动态频谱接入中基于最小贝叶斯风险的稳健频谱预测[J]. 电子与信息学报, 2018, 40(3): 734–742. doi: 10.11999/JEIT170519.
CHEN Xi and YANG Jian. Minimum Bayesian risk based robust spectrum prediction in dynamic spectrum access[J]. Journal of Electronics & Information Technology, 2018, 40(3): 734–742. doi: 10.11999/JEIT170519.
|
Figures(13) / Tables(4)



 DownLoad:
DownLoad: