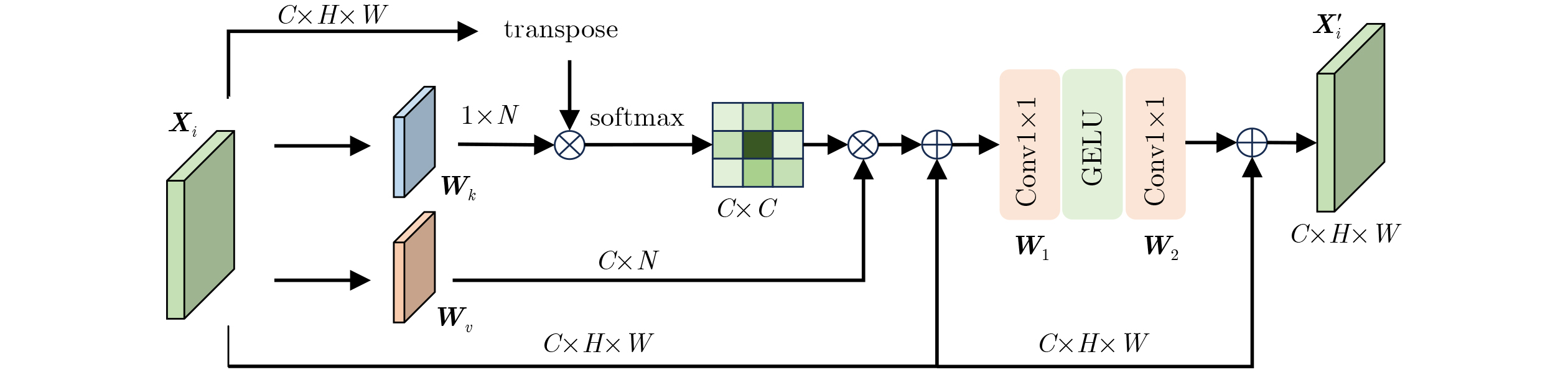
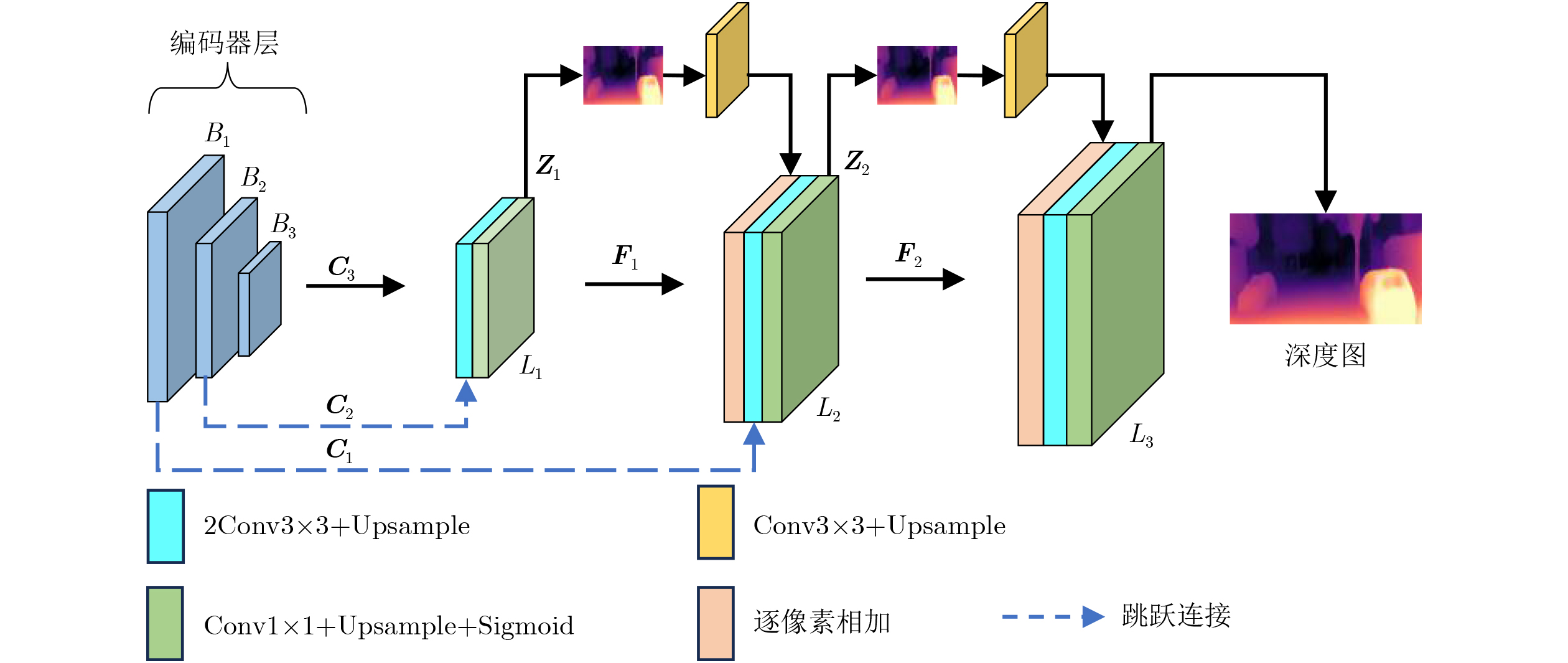
| Citation: | CHENG Deqiang, XU Shuai, LÜ Chen, HAN Chenggong, JIANG He, KOU Qiqi. Lightweight Self-supervised Monocular Depth Estimation Method with Enhanced Direction-aware[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3683-3692. doi: 10.11999/JEIT240189

|

| [1] |
邓慧萍, 盛志超, 向森, 等. 基于语义导向的光场图像深度估计[J]. 电子与信息学报, 2022, 44(8): 2940–2948. doi: 10.11999/JEIT210545.
DENG Huiping, SHENG Zhichao, XIANG Sen, et al. Depth estimation based on semantic guidance for light field image[J]. Journal of Electronics & Information Technology, 2022, 44(8): 2940–2948. doi: 10.11999/JEIT210545.
|
| [2] |
程德强, 张华强, 寇旗旗, 等. 基于层级特征融合的室内自监督单目深度估计[J]. 光学 精密工程, 2023, 31(20): 2993–3009. doi: 10.37188/OPE.20233120.2993.
CHENG Deqiang, ZHANG Huaqiang, and KOU Qiqi, et al. Indoor self-supervised monocular depth estimation based on level feature fusion[J]. Optics and Precision Engineering, 2023, 31(20): 2993–3009. doi: 10.37188/OPE.20233120.2993.
|
| [3] |
GODARD C, AODHA O M, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 3827–3837. doi: 10.1109/ICCV.2019.00393.
|
| [4] |
WANG Zhou, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600–612. doi: 10.1109/TIP.2003.819861.
|
| [5] |
LYU Xiaoyang, LIU Liang, WANG Mengmeng, et al. HR-Depth: High resolution self-supervised monocular depth estimation[C]. 35th AAAI Conference on Artificial Intelligence, Palo Alto, USA, 2021: 2294–2301. doi: 10.1609/aaai.v35i3.16329.
|
| [6] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. 9th International Conference on Learning Representations, Vienna, Austria, 2021.
|
| [7] |
BAE J, MOON S, and IM S. Deep digging into the generalization of self-supervised monocular depth estimation[C]. 36th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 187–196. doi: 10.1609/aaai.v37i1.25090.
|
| [8] |
VARMA A, CHAWLA H, ZONOOZ B, et al. Transformers in self-supervised monocular depth estimation with unknown camera intrinsics[C]. The 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, 2022: 758–769.
|
| [9] |
HAN Wencheng, YIN Junbo, and SHEN Jianbing. Self-supervised monocular depth estimation by direction-aware cumulative convolution network[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 8579–8589. doi: 10.1109/ICCV51070.2023.00791.
|
| [10] |
ZHANG Ning, NEX F, VOSSELMAN G, et al. Lite-Mono: A lightweight CNN and transformer architecture for self-supervised monocular depth estimation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 18537–18546. doi: 10.1109/CVPR52729.2023.01778.
|
| [11] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. https://arxiv.org/abs/1706.05587, 2017.
|
| [12] |
DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848.
|
| [13] |
GEIGER A, LENZ P, and URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 3354–3361. doi: 10.1109/CVPR.2012.6248074.
|
| [14] |
EIGEN D, PUHRSCH C, and FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2366–2374.
|
| [15] |
SAXENA A, SUN Min, and NG A Y. Make3D: Learning 3D scene structure from a single still image[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(5): 824–840. doi: 10.1109/TPAMI.2008.132.
|
| [16] |
ZHOU Zhongkai, FAN Xinnan, SHI Pengfei, et al. R-MSFM: Recurrent multi-scale feature modulation for monocular depth estimating[C]. 18th IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 12757–12766. doi: 10.1109/ICCV48922.2021.01254.
|
| [17] |
KLINGNER M, TERMÖHLEN J A, MIKOLAJCZYK J, et al. Self-supervised monocular depth estimation: Solving the dynamic object problem by semantic guidance[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 582–600. doi: 10.1007/978-3-030-58565-5_35.
|
| [18] |
YIN Zhichao and SHI Jianping. GeoNet: Unsupervised learning of dense depth, optical flow and camera pose[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1983–1992. doi: 10.1109/CVPR.2018.00212.
|
| [19] |
WANG Chaoyang, BUENAPOSADA J M, ZHU Rui, et al. Learning depth from monocular videos using direct methods[C]. 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2022–2030. doi: 10.1109/CVPR.2018.00216.
|
| [20] |
JOHNSTON A and CARNEIRO G. Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 4755–4764. doi: 10.1109/CVPR42600.2020.00481.
|
| [21] |
YAN Jiaxing, ZHAO Hong, BU Penghui, et al. Channel-wise attention-based network for self-supervised monocular depth estimation[C]. 9th International Conference on 3D Vision, London, USA, 2021: 464–473. doi: 10.1109/3DV53792.2021.00056.
|
| [22] |
HAN Chenggong, CHENG Deqiang, KOU Qiqi, et al. Self-supervised monocular Depth estimation with multi-scale structure similarity loss[J]. Multimedia Tools and Applications, 2022, 82(24): 38035–38050. doi: 10.1007/S11042-022-14012-6.
|

Figures(7) / Tables(6)



 DownLoad:
DownLoad: