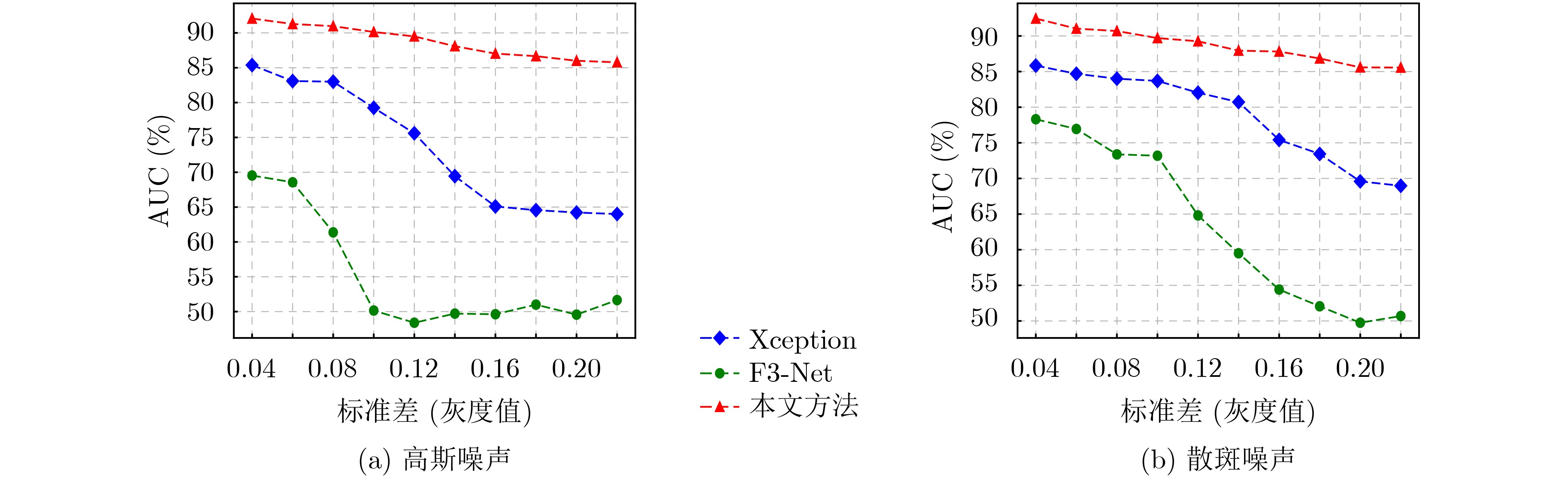
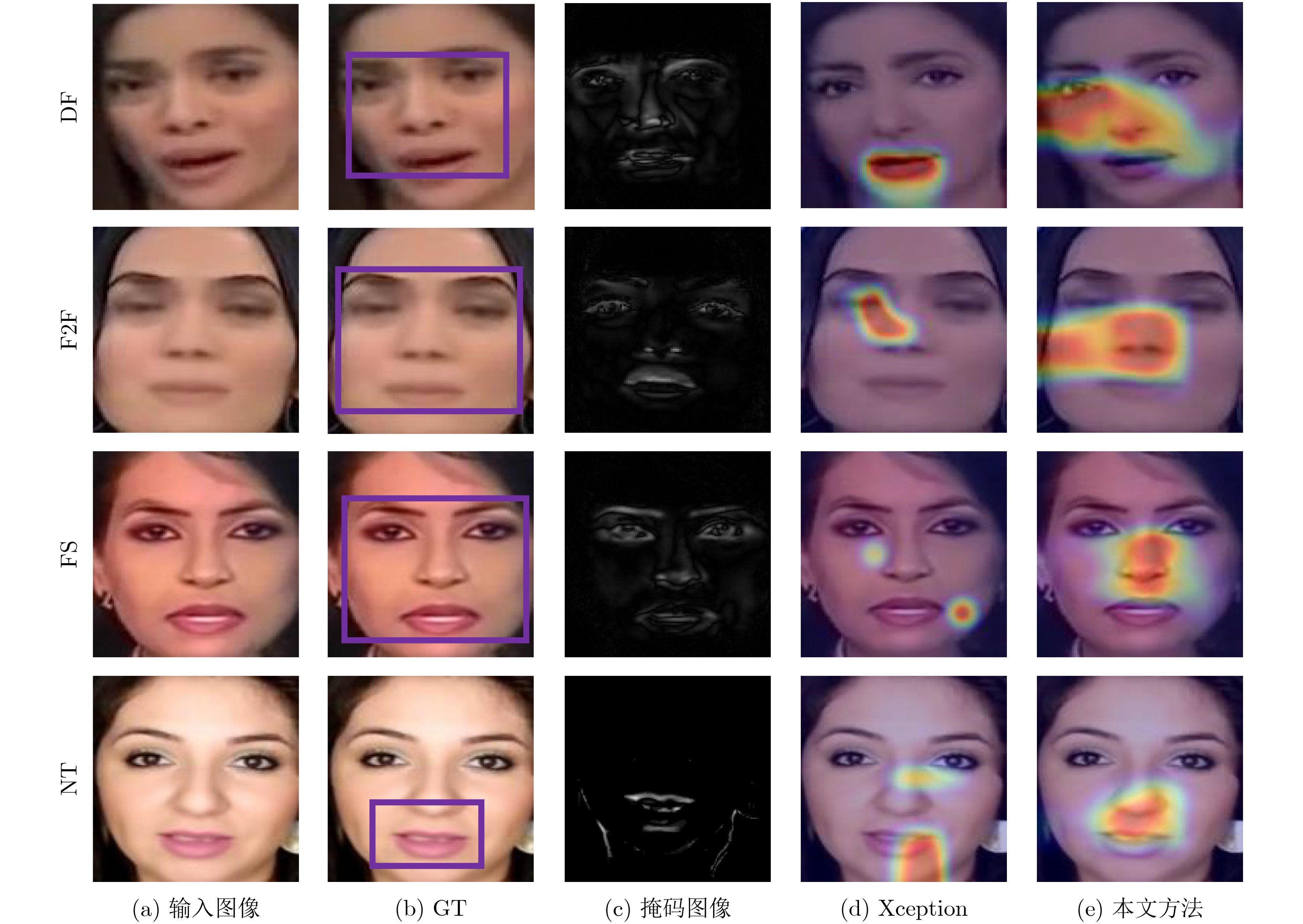
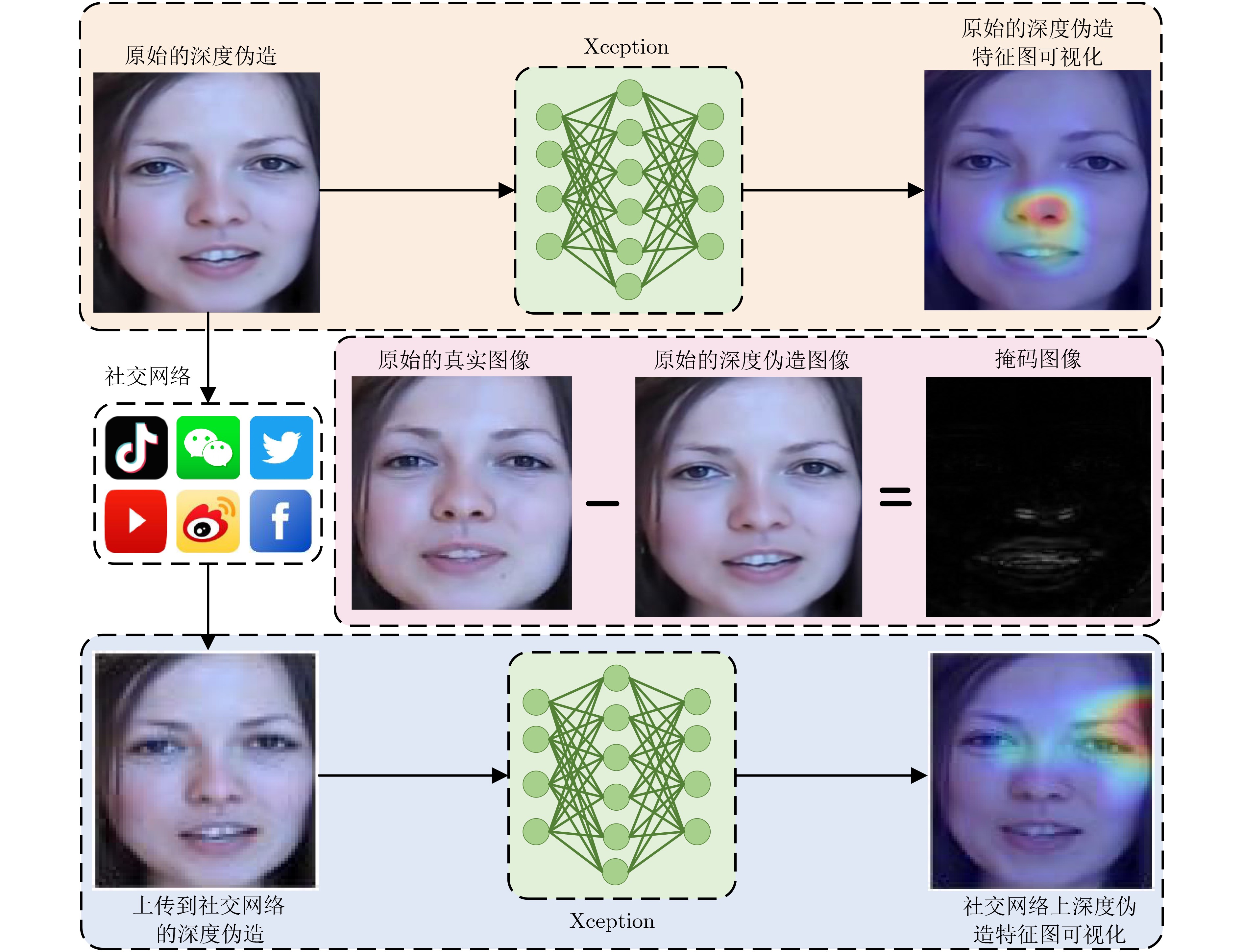
| Citation: | WANG Yan, SUN Qindong, RONG Dongzhu, WANG Xiaoxiong. Deepfake Video Detection on Social Networks Using Multi-domain Aware Driven by Common Mechanism Analysis Between Artifacts[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3713-3721. doi: 10.11999/JEIT240025

|

| [1] |
IGLESIAS G, TALAVERA E, and DÍAZ-ÁLVAREZ A. A survey on GANs for computer vision: Recent research, analysis and taxonomy[J]. Computer Science Review, 2023, 48: 100553. doi: 10.1016/j.cosrev.2023.100553.
|
| [2] |
ZANARDELLI M, GUERRINI F, LEONARDI R, et al. Image forgery detection: A survey of recent deep-learning approaches[J]. Multimedia Tools and Applications, 2023, 82(12): 17521–17566. doi: 10.1007/s11042-022-13797-w.
|
| [3] |
牛淑芬, 戈鹏, 宋蜜, 等. 移动社交网络中基于属性加密的隐私保护方案[J]. 电子与信息学报, 2023, 45(3): 847–855. doi: 10.11999/JEIT221174.
NIU Shufen, GE Peng, SONG Mi, et al. A privacy protection scheme based on attribute encryption in mobile social networks[J]. Journal of Electronics & Information Technology, 2023, 45(3): 847–855. doi: 10.11999/JEIT221174.
|
| [4] |
KINGRA S, AGGARWAL N, and KAUR N. Emergence of deepfakes and video tampering detection approaches: A survey[J]. Multimedia Tools and Applications, 2023, 82(7): 10165–10209. doi: 10.1007/s11042-022-13100-x.
|
| [5] |
CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 1800–1807. doi: 10.1109/CVPR.2017.195.
|
| [6] |
BINH L M and WOO S. ADD: Frequency attention and multi-view based knowledge distillation to detect low-quality compressed deepfake images[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 122–130. doi: 10.1609/aaai.v36i1.19886.
|
| [7] |
LEE S, AN J, and WOO S S. BZNet: Unsupervised multi-scale branch zooming network for detecting low-quality deepfake videos[C]. The ACM Web Conference 2022, Lyon, France, 2022: 3500–3510. doi: 10.1145/3485447.3512245.
|
| [8] |
LIN Liqun, ZHENG Yang, CHEN Weiling, et al. Saliency-aware spatio-temporal artifact detection for compressed video quality assessment[J]. IEEE Signal Processing Letters, 2023, 30: 693–697. doi: 10.1109/LSP.2023.3283541.
|
| [9] |
FRANK J, EISENHOFER T, SCHÖNHERR L, et al. Leveraging frequency analysis for deep fake image recognition[C]. The 37th International Conference on Machine Learning, 2020: 3247–3258.
|
| [10] |
LI Yuezun, CHANG M C, and LYU Siwei. In ictu oculi: Exposing AI created fake videos by detecting eye blinking[C]. 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 2018: 1–7. doi: 10.1109/WIFS.2018.8630787.
|
| [11] |
CIFTCI U A, DEMIR I, and YIN Lijun. Fakecatcher: Detection of synthetic portrait videos using biological signals[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020: 1. doi: 10.1109/TPAMI.2020.3009287.
|
| [12] |
COZZOLINO D, THIES J, RÖSSLER A, et al. ForensicTransfer: Weakly-supervised domain adaptation for forgery detection[EB/OL]. https://arxiv.org/abs/1812.02510, 2018.
|
| [13] |
AFCHAR D, NOZICK V, YAMAGISHI J, et al. MesoNet: A compact facial video forgery detection network[C]. 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 2018: 1–7. doi: 10.1109/WIFS.2018.8630761.
|
| [14] |
QIAN Yuyang, YIN Guojun, SHENG Lu, et al. Thinking in frequency: Face forgery detection by mining frequency-aware clues[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 86–103. doi: 10.1007/978-3-030-58610-2_6.
|
| [15] |
LIU Honggu, LI Xiaodan, ZHOU Wenbo, et al. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 772–781. doi: 10.1109/CVPR46437.2021.00083.
|
| [16] |
LI Ying, BIAN Shan, WANG Chuntao, et al. Exposing low-quality deepfake videos of social network service using spatial restored detection framework[J]. Expert Systems with Applications, 2023, 231: 120646. doi: 10.1016/j.eswa.2023.120646.
|
| [17] |
ZHANG Yun, ZHU Linwei, JIANG Gangyi, et al. A survey on perceptually optimized video coding[J]. ACM Computing Surveys, 2023, 55(12): 245. doi: 10.1145/3571727.
|
| [18] |
WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1.
|
| [19] |
RÖSSLER A, COZZOLINO D, VERDOLIVA L, et al. FaceForensics++: Learning to detect manipulated facial images[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 2019: 1–11. doi: 10.1109/ICCV.2019.00009.
|
| [20] |
ZHANG Kaipeng, ZHANG Zhanpeng, LI Zhifeng, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499–1503. doi: 10.1109/LSP.2016.2603342.
|
| [21] |
NGUYEN H H, YAMAGISHI J, and ECHIZEN I. Capsule-forensics: Using capsule networks to detect forged images and videos[C]. 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 2019: 2307–2311. doi: 10.1109/ICASSP.2019.8682602.
|
| [22] |
WANG Chengrui and DENG Weihong. Representative forgery mining for fake face detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 14918–14927. doi: 10.1109/CVPR46437.2021.01468.
|
| [23] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 618–626. doi: 10.1109/ICCV.2017.74.
|
Figures(4) / Tables(5)



 DownLoad:
DownLoad: