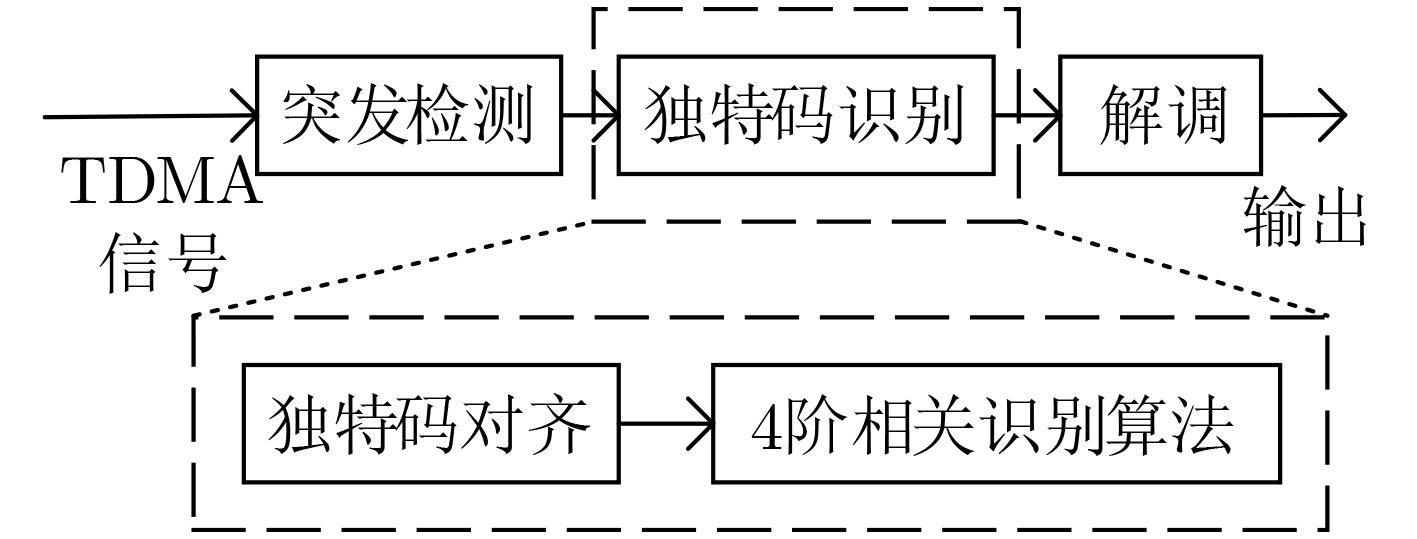
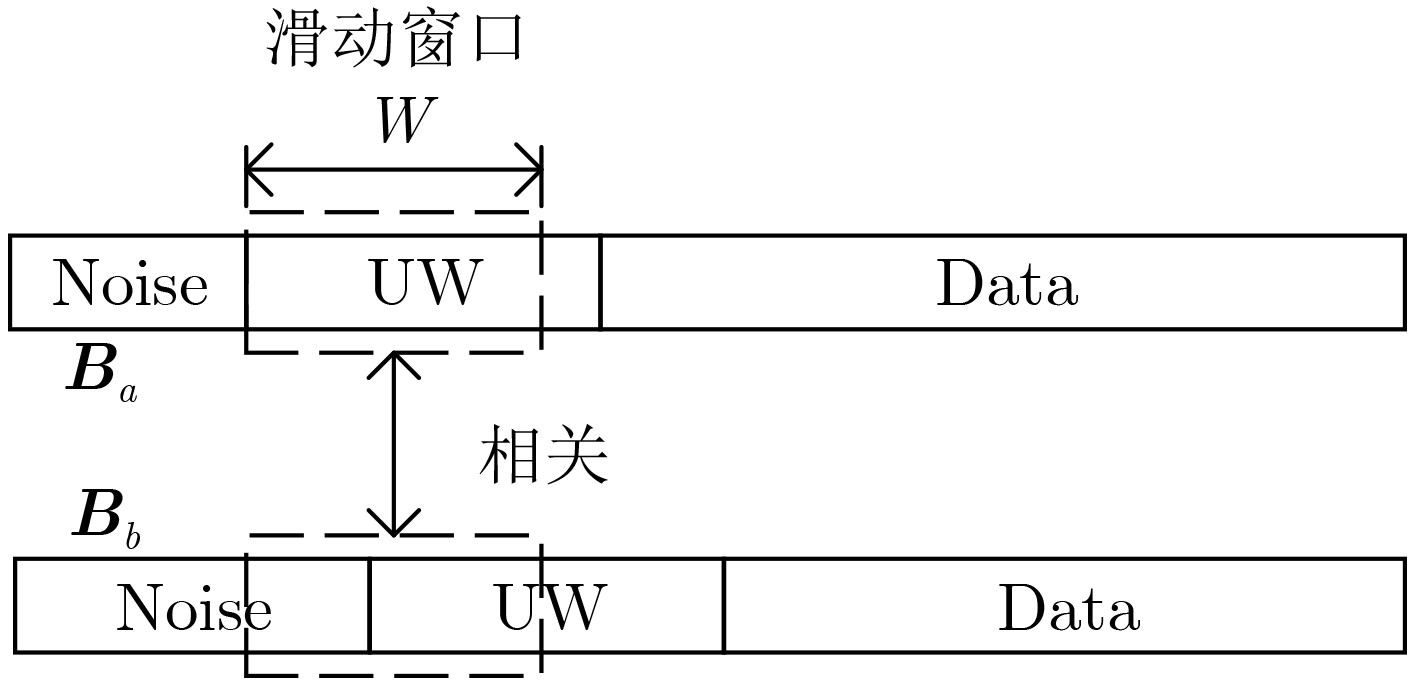
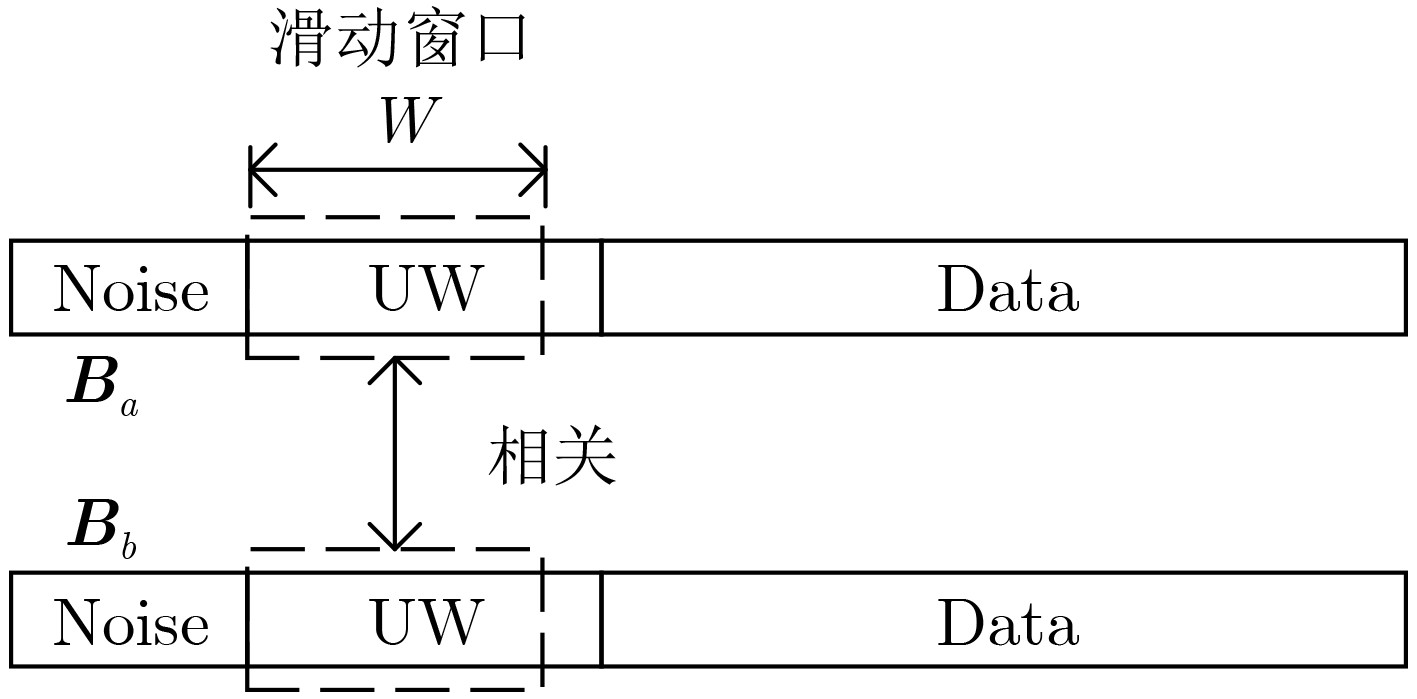
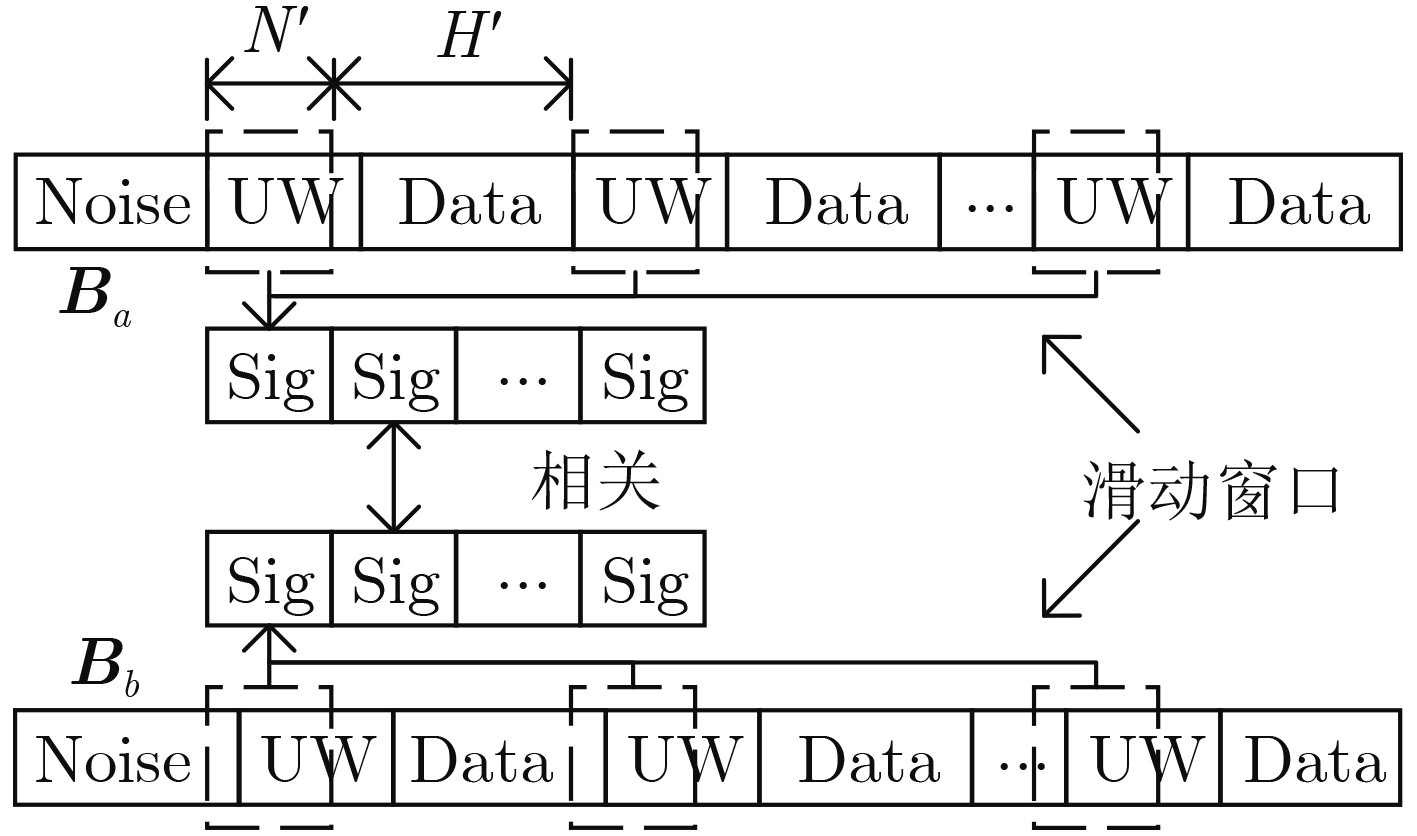
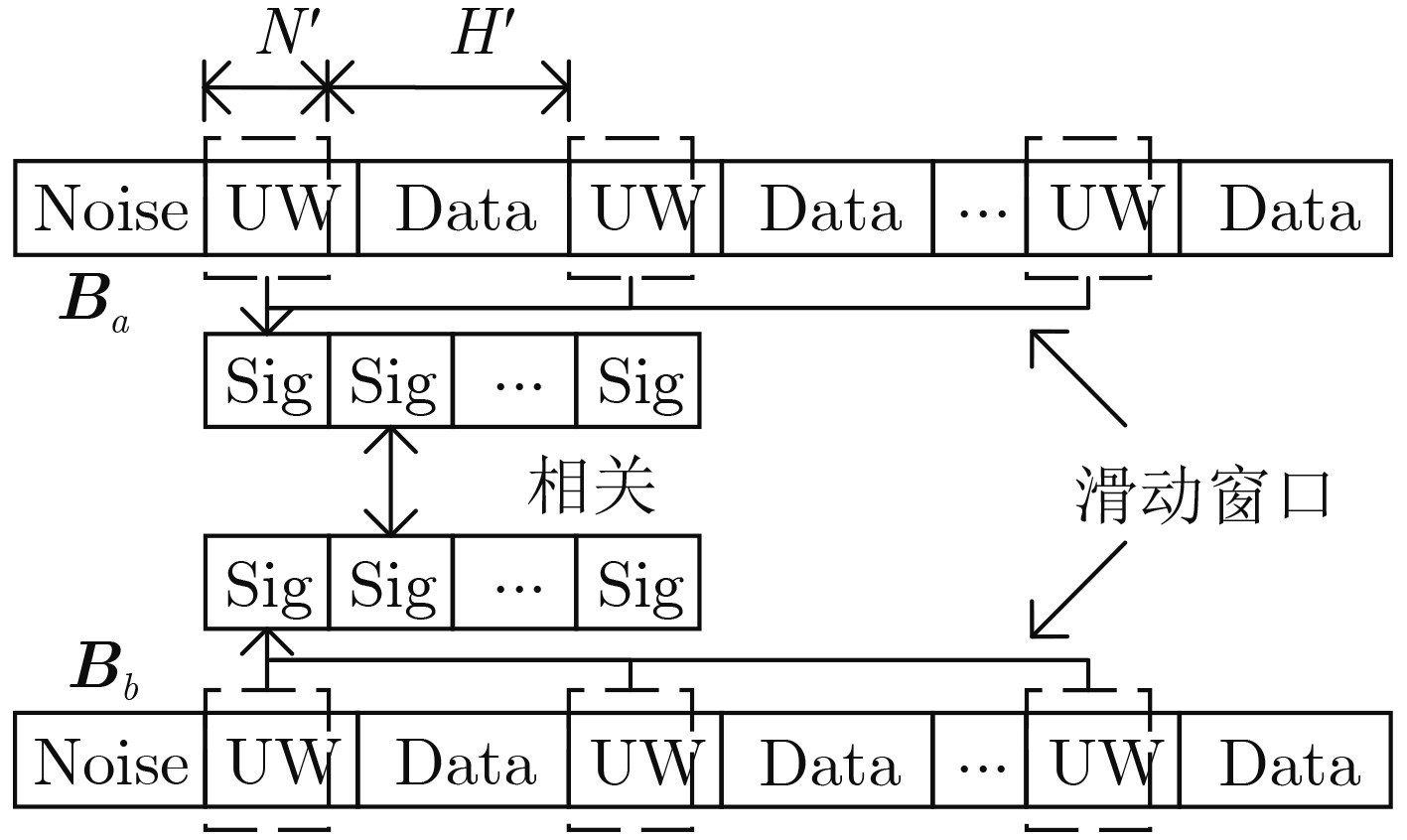
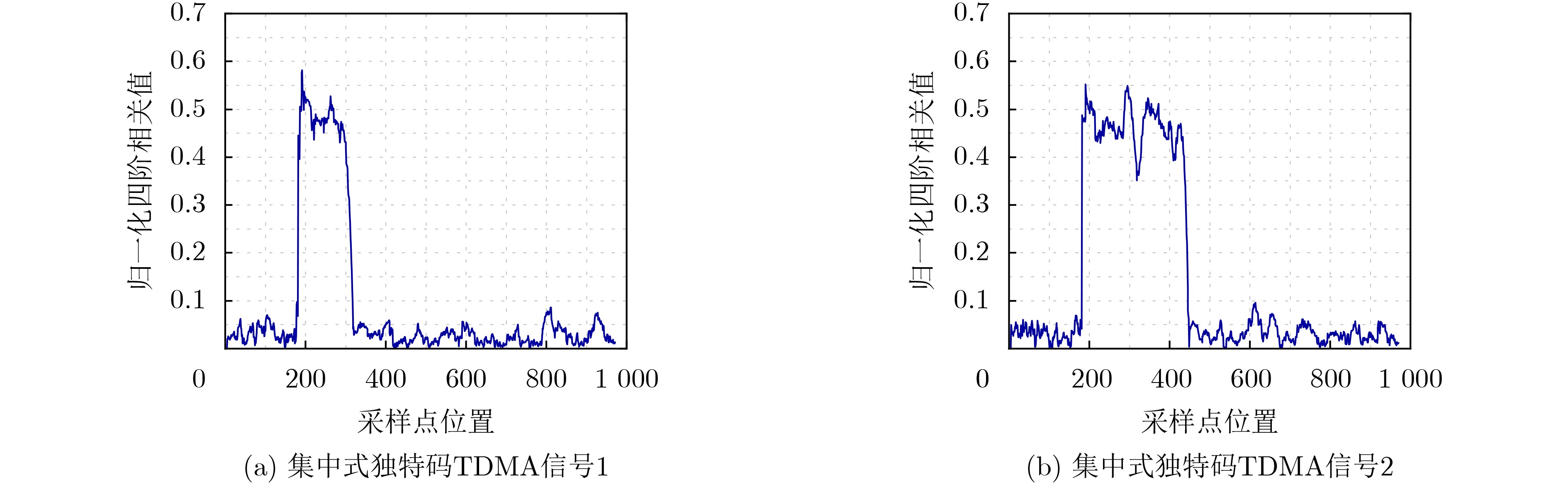
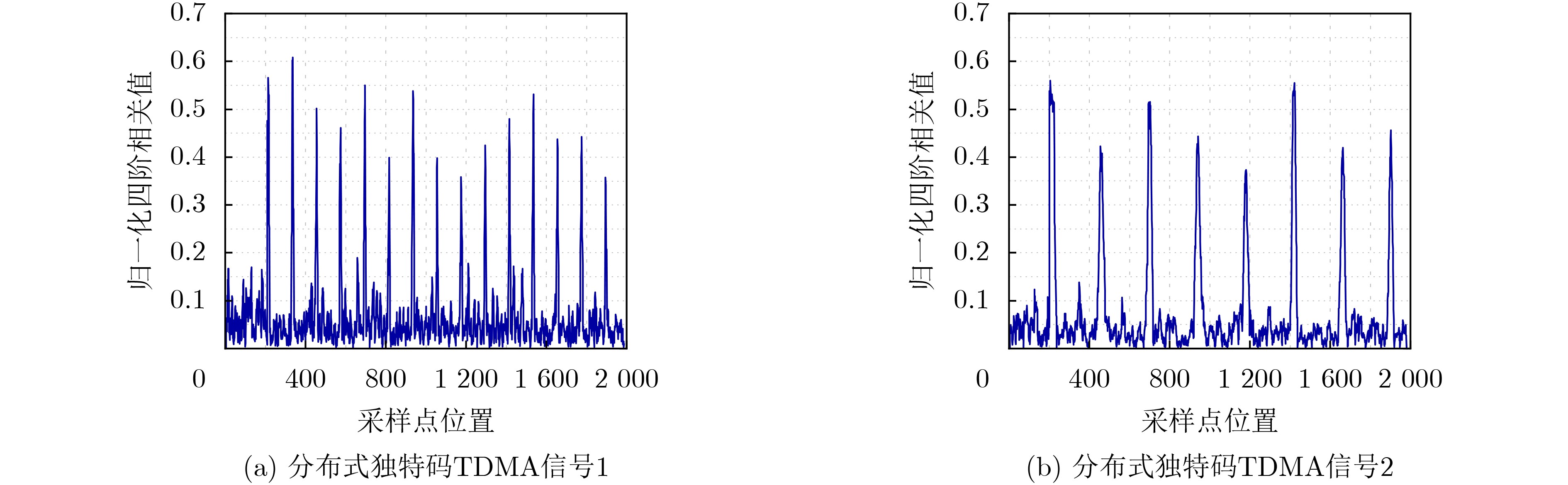
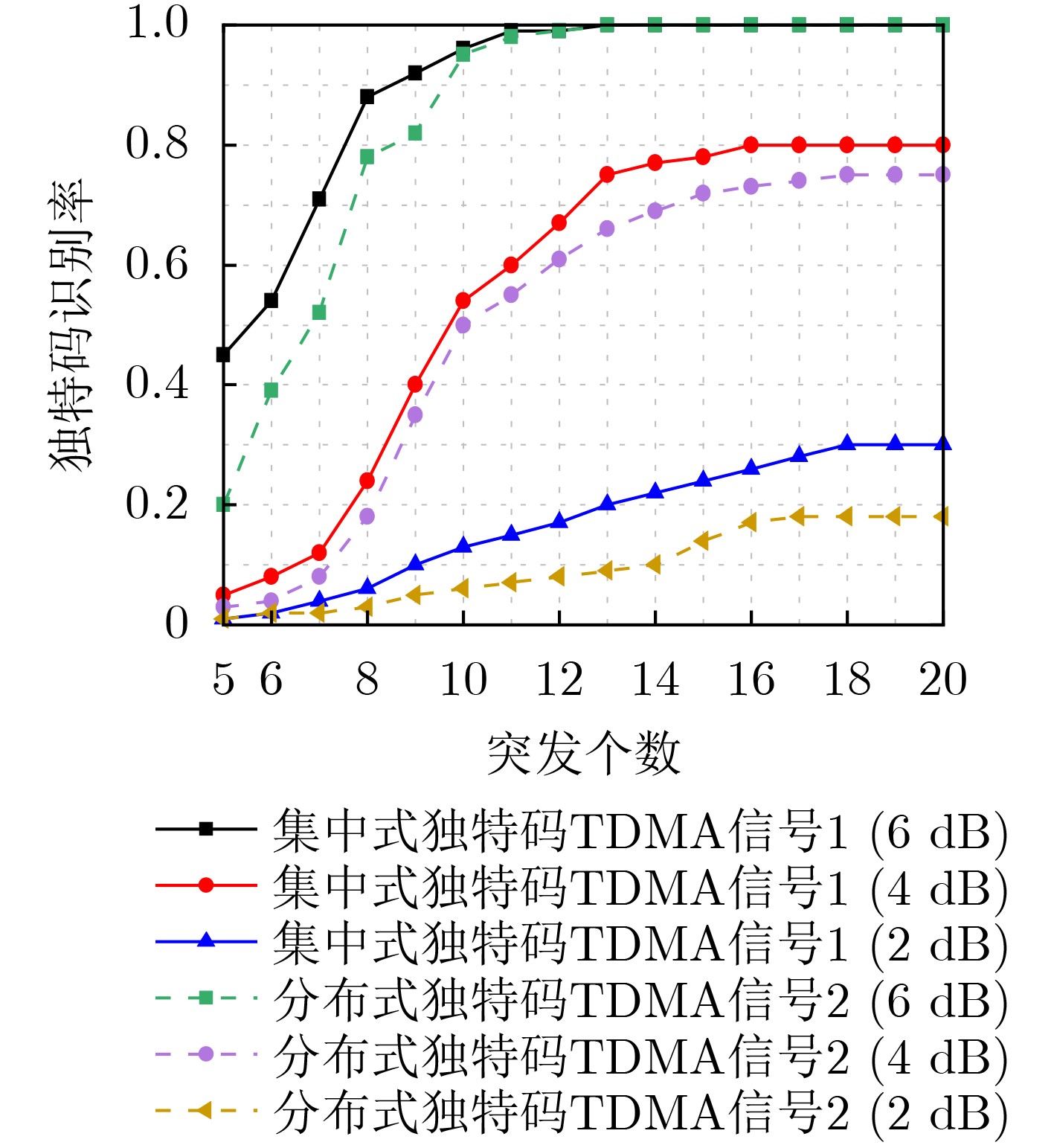
| Citation: | JIANG Hua, SONG Kaifei, ZOU Kunheng, SUN Peng, GONG Kexian, ZHANG Ling, WANG Wei. Unique Words Blind Identification of Time Division Multiple Access Modulated Data Based on Fourth Order Correlation[J]. Journal of Electronics & Information Technology, 2024, 46(7): 2803-2811. doi: 10.11999/JEIT230935

|

| [1] |
张永光, 楼才义. 信道编码及其识别分析[M]. 4版. 北京: 电子工业出版社, 2010: 1–2.
ZHANG Yongguang and LOU Caiyi. Channel Coding and Recognition Analysis[M]. 4th ed. Beijing: Publishing House of Electronics Industry, 2010: 1–2.
|
| [2] |
AL-AZZEH J, FAURE E, SHCHERBA A, et al. Permutation-based frame synchronization method for data transmission systems with short packets[J]. Egyptian Informatics Journal, 2022, 23(3): 529–545. doi: 10.1016/j.eij.2022.05.005.
|
| [3] |
SON W, CHOI J, PARK S, et al. A time synchronization protocol for barrage relay networks[J]. Sensors, 2023, 23(5): 2447. doi: 10.3390/s23052447.
|
| [4] |
LI Xinhao, MA Tao, and QIAN Qishu. Frame synchronization method based on association rules for CNAV-2 messages[J]. Chinese Journal of Electronics, 2023, 32(2): 295–302. doi: 10.23919/cje.2021.00.148.
|
| [5] |
侯骁宇, 李天昀, 杨司韩. 分布式独特码TDMA信号的检测和频率估计[J]. 信号处理, 2018, 34(10): 1211–1220. doi: 10.16798/j.issn.1003-0530.2018.10.009.
HOU Xiaoyu, LI Tianyun, and YANG Sihan. Detection and frequency estimation of distributed unique word TDMA signal[J]. Journal of Signal Processing, 2018, 34(10): 1211–1220. doi: 10.16798/j.issn.1003-0530.2018.10.009.
|
| [6] |
刘明. 一种改进的分段式互相关帧同步检测方法[J]. 通信技术, 2023, 56(6): 708–713. doi: 10.3969/j.issn.1002-0802.2023.06.006.
LIU Ming. A modified segmental cross-correlation algorithm for frame synchronization detection[J]. Communications Technology, 2023, 56(6): 708–713. doi: 10.3969/j.issn.1002-0802.2023.06.006.
|
| [7] |
ZHANG Shengyuan, SUN Houteng, YUAN Jiangnan, et al. A practical method for blind detection of centralized unique word TDMA signal[C]. 2022 4th International Conference on Communications, Information System and Computer Engineering, Shenzhen, China, 2022: 7–10. doi: 10.1109/CISCE55963.2022.9851161.
|
| [8] |
QASEM Z A H, WANG Junfeng, KUAI Xiaoyan, et al. Enabling unique word OFDM for underwater acoustic communication[J]. IEEE Wireless Communications Letters, 2021, 10(9): 1886–1889. doi: 10.1109/LWC.2021.3085020.
|
| [9] |
D’AMICO A A and MORELLI M. Joint frame detection and channel parameter estimation for OOK free-space optical communications[J]. IEEE Transactions on Communications, 2022, 70(7): 4731–4744. doi: 10.1109/TCOMM.2022.3177768.
|
| [10] |
XU Yiyao, ZHONG Yang, and HUANG Zhiping. An improved blind recognition algorithm of frame parameters based on self-correlation[J]. Information, 2019, 10(2): 64. doi: 10.3390/info10020064.
|
| [11] |
KIL Y S, LEE H, KIM S H, et al. Analysis of blind frame recognition and synchronization based on sync word periodicity[J]. IEEE Access, 2020, 8: 147516–147532. doi: 10.1109/ACCESS.2020.3014426.
|
| [12] |
QIN Jiangyi, HUANG Zhiping, LIU Chunwu, et al. Novel blind recognition algorithm of frame synchronization words based on soft-decision in digital communication systems[J]. PLoS One, 2015, 10(7): e0132114. doi: 10.1371/journal.pone.0132114.
|
| [13] |
熊颢, 雷迎科, 吴子龙. 基于码元密度检测的帧同步码盲识别算法[J]. 探测与控制学报, 2021, 43(1): 73–78.
XIONG Hao, LEI Yingke, and WU Zilong. Frame synchronization code blind recognition based on symbol density detection[J]. Journal of Detection & Control, 2021, 43(1): 73–78.
|
| [14] |
张玉, 杨晓静. 集中插入式帧同步识别方法[J]. 兵工学报, 2013, 34(5): 554–560. doi: 10.3969/j.issn.1000-1093.2013.05.007.
ZHANG Yu and YANG Xiaojing. Recognition method of concentratively inserted frame synchronization[J]. Acta Armamentarii, 2013, 34(5): 554–560. doi: 10.3969/j.issn.1000-1093.2013.05.007.
|
| [15] |
邵堃, 雷迎科. 基于离散度分析的帧同步快速盲识别算法[J]. 信号处理, 2020, 36(3): 361–372. doi: 10.16798/j.issn.1003-0530.2020.03.006.
SHAO Kun and LEI Yingke. Fast blind recognition algorithm of frame synchronization based on dispersion analysis[J]. Journal of Signal Processing, 2020, 36(3): 361–372. doi: 10.16798/j.issn.1003-0530.2020.03.006.
|
| [16] |
李歆昊, 张旻, 韩树楠. 基于多重分形谱的链路层协议帧同步字盲识别[J]. 电子与信息学报, 2017, 39(7): 1666–1672. doi: 10.11999/JEIT161045.
LI Xinhao, ZHANG Min, and HAN Shunan. Frame synchronization word identification of link layer protocol based on multi-fractal spectrum[J]. Journal of Electronics & Information Technology, 2017, 39(7): 1666–1672. doi: 10.11999/JEIT161045.
|
| [17] |
白彧, 杨晓静, 张玉. 基于高阶统计处理技术的m-序列帧同步码识别[J]. 电子与信息学报, 2012, 34(1): 33–37. doi: 10.3724/SP.J.1146.2011.00500.
BAI Yu, YANG Xiaojing, and ZHANG Yu. A recognition method of m-sequence synchronization codes using higher-order statistical processing[J]. Journal of Electronics & Information Technology, 2012, 34(1): 33–37. doi: 10.3724/SP.J.1146.2011.00500.
|
| [18] |
KIL Y S, SONG J M, KIM S H, et al. Deep learning aided blind synchronization word estimation[J]. IEEE Access, 2021, 9: 30321–30334. doi: 10.1109/ACCESS.2021.3058351.
|
| [19] |
熊静华, 杨战平. 独特码及其编码原理研究[J]. 信息与电子工程, 2003, 1(2): 26–30. doi: 10.3969/j.issn.1672-2892.2003.02.006.
XIONG Jinghua and YANG Zhanping. Study on unique signal and its coding principle[J]. Information and Electronic Engineering, 2003, 1(2): 26–30. doi: 10.3969/j.issn.1672-2892.2003.02.006.
|
| [20] |
何玉红. 基于双滑动窗的TDMA信号盲检测算法实现[J]. 通信技术, 2012, 45(6): 70–72. doi: 10.3969/j.issn.1002-0802.2012.06.021.
HE Yuhong. Implementation of TDMA signal blind detection algorithm based on double sliding windows[J]. Communications Technology, 2012, 45(6): 70–72. doi: 10.3969/j.issn.1002-0802.2012.06.021.
|

Figures(12) / Tables(4)



 DownLoad:
DownLoad: