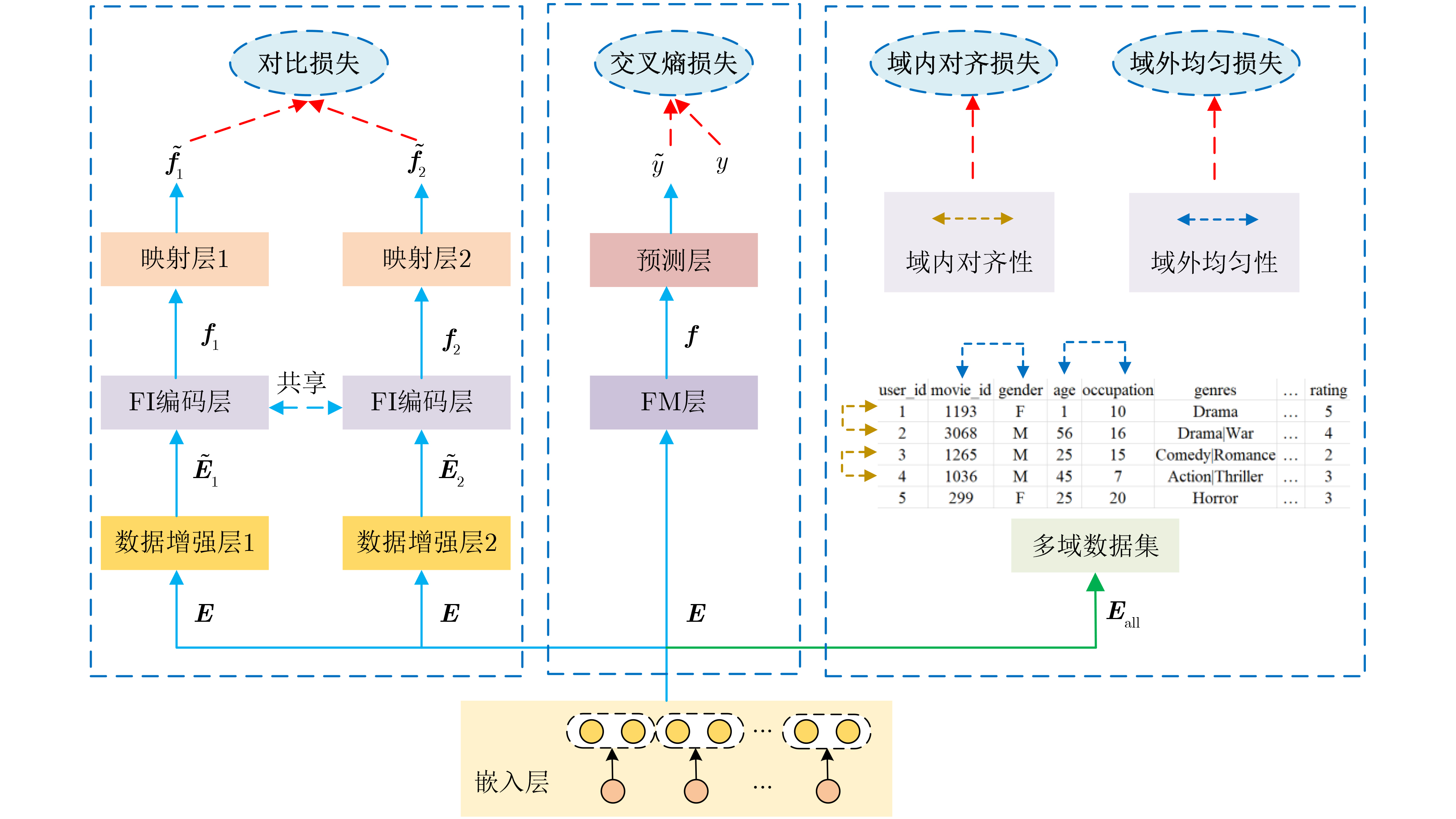
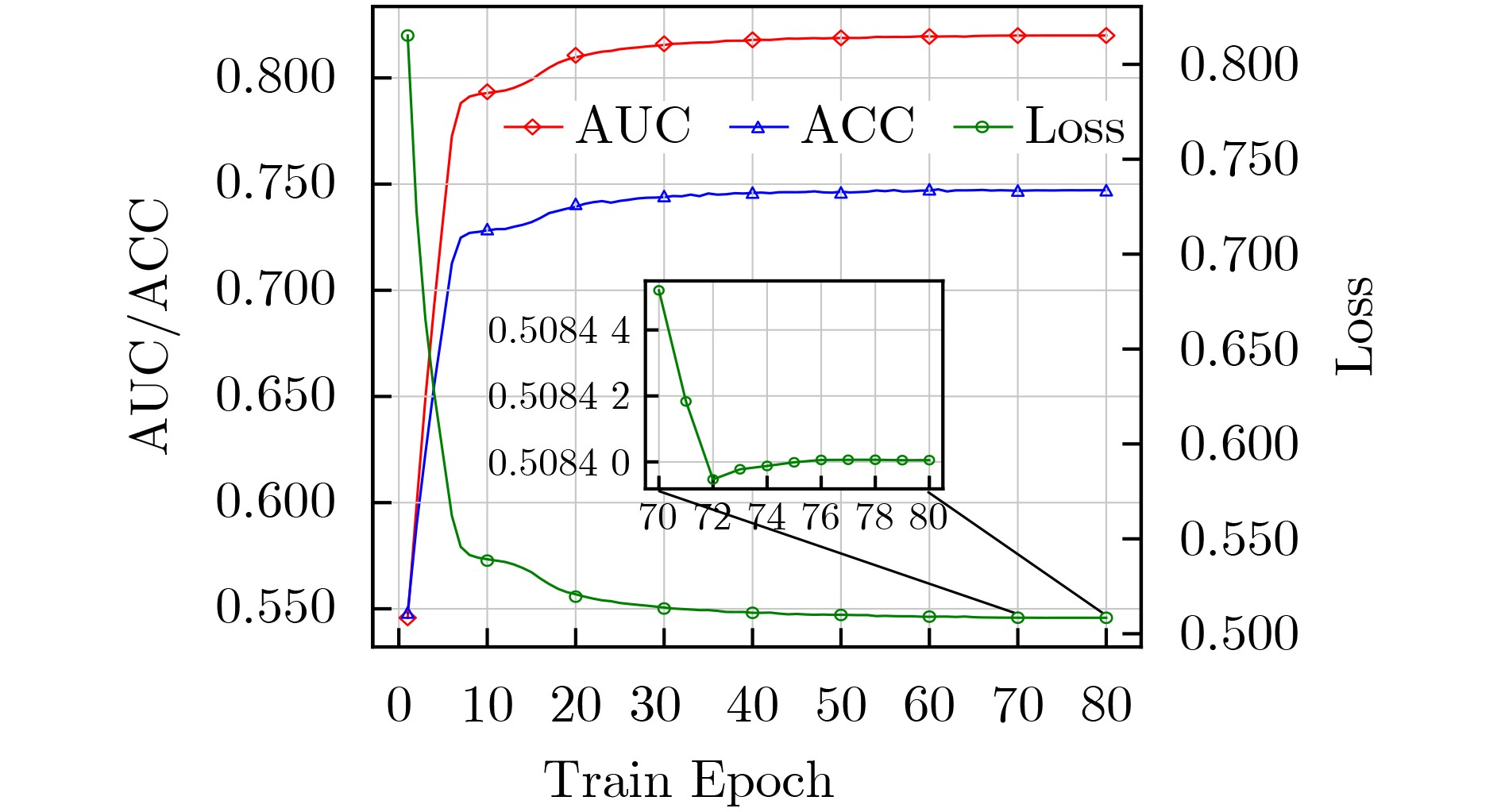
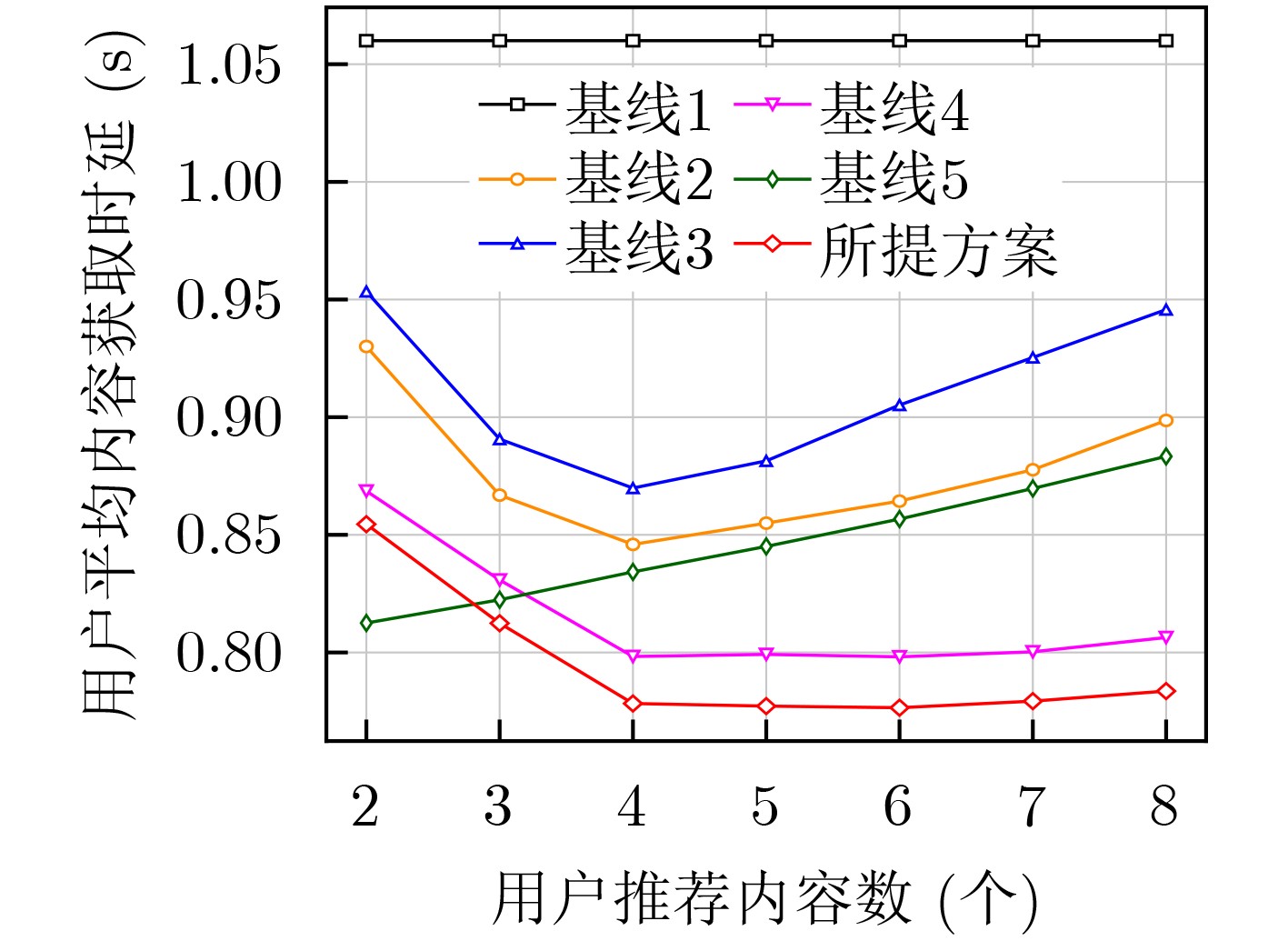
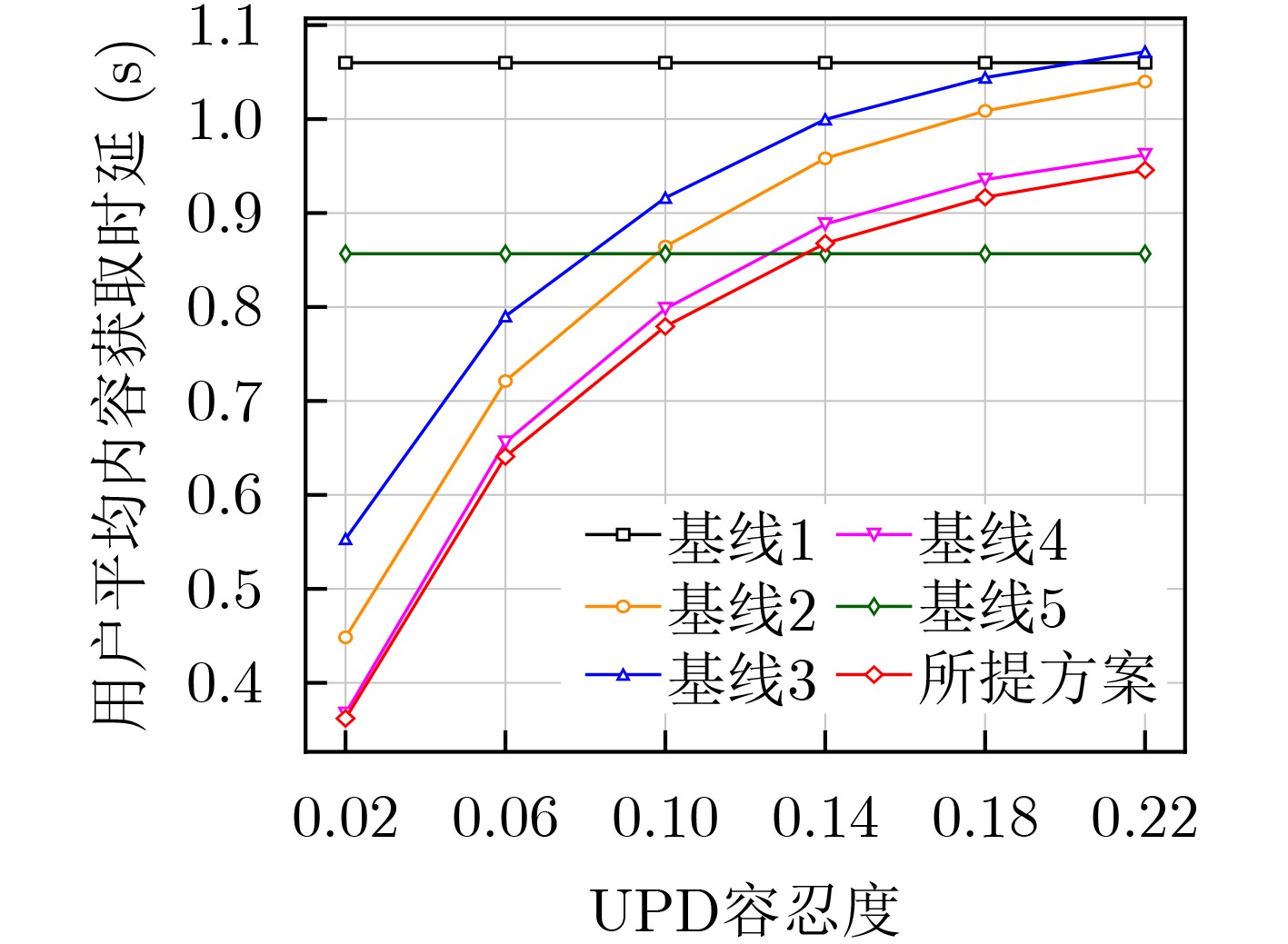
| Citation: | WANG Ruyan, JIANG Hao, TANG Tong, WU Dapeng, ZHONG Ailing. A Joint Optimization Strategy for User Request Perceived Edge Caching and User Recommendation[J]. Journal of Electronics & Information Technology, 2024, 46(7): 2850-2859. doi: 10.11999/JEIT230898

|

| [1] |
VAEZI M, AZARI A, KHOSRAVIRAD S R, et al. Cellular, wide-area, and non-terrestrial IoT: A survey on 5G advances and the road toward 6G[J]. IEEE Communications Surveys & Tutorials, 2022, 24(2): 1117–1174. doi: 10.1109/COMST.2022.3151028.
|
| [2] |
WU Dapeng, SHI Hang, WANG Honggang, et al. A feature-based learning system for internet of things applications[J]. IEEE Internet of Things Journal, 2019, 6(2): 1928–1937. doi: 10.1109/JIOT.2018.2884485.
|
| [3] |
CHENG Guangquan, JIANG Chi, YUE Binglei, et al. AI-driven proactive content caching for 6G[J]. IEEE Wireless Communications, 2023, 30(3): 180–188. doi: 10.1109/MWC.021.2200535.
|
| [4] |
FU Yaru, YANG H H, DOAN K N, et al. Effective cache-enabled wireless networks: An artificial intelligence- and recommendation-oriented framework[J]. IEEE Vehicular Technology Magazine, 2021, 16(1): 20–28. doi: 10.1109/MVT.2020.3033934.
|
| [5] |
LI Zhidu, BAO Ruili, WU Dapeng, et al. Caching at the edge: A group interest aware approach[C]. 2021-IEEE International Conference on Communications, Montreal, Canada, 2021: 1–6. doi: 10.1109/ICC42927.2021.9500942.
|
| [6] |
戚雨龙. 基于用户偏好的D2D缓存技术研究[D]. [硕士论文], 哈尔滨工业大学, 2021.
QI Yulong. Research on D2D cache technology based on user preference[D]. [Master dissertation], Harbin Institute of Technology, 2021.
|
| [7] |
WU Dapeng, LIU Qianru, WANG Honggang, et al. Socially aware energy-efficient mobile edge collaboration for video distribution[J]. IEEE Transactions on Multimedia, 2017, 19(10): 2197–2209. doi: 10.1109/TMM.2017.2733300.
|
| [8] |
CHEN Mingzhe, SAAD W, YIN Changchuan, et al. Echo state networks for proactive caching in cloud-based radio access networks with mobile users[J]. IEEE Transactions on Wireless Communications, 2017, 16(6): 3520–3535. doi: 10.1109/TWC.2017.2683482.
|
| [9] |
CHATZIELEFTHERIOU L E, KARALIOPOULOS M, KOUTSOPOULOS I. Caching-aware recommendations: Nudging user preferences towards better caching performance[C]. 2017-IEEE Conference on Computer Communications, Atlanta, USA, 2017: 1–9. doi: 10.1109/INFOCOM.2017.8057031.
|
| [10] |
CHATZIELEFTHERIOU L E, KARALIOPOULOS M, and KOUTSOPOULOS I. Jointly optimizing content caching and recommendations in small cell networks[J]. IEEE Transactions on Mobile Computing, 2019, 18(1): 125–138. doi: 10.1109/TMC.2018.2831690.
|
| [11] |
FU Yaru, SALAÜN L, YANG Xiaolong, et al. Caching efficiency maximization for device-to-device communication networks: A recommend to cache approach[J]. IEEE Transactions on Wireless Communications, 2021, 20(10): 6580–6594. doi: 10.1109/TWC.2021.3075278.
|
| [12] |
FU Yaru, ZHANG Yue, WONG A K Y, et al. Revenue maximization: The interplay between personalized bundle recommendation and wireless content caching[J]. IEEE Transactions on Mobile Computing, 2023, 22(7): 4253–4265. doi: 10.1109/TMC.2022.3142809.
|
| [13] |
YU Shuai, DAB B, MOVAHEDI Z, et al. A socially-aware hybrid computation offloading framework for multi-access edge computing[J]. IEEE Transactions on Mobile Computing, 2020, 19(6): 1247–1259. doi: 10.1109/TMC.2019.2908154.
|
| [14] |
ANDREWS J G, BACCELLI F, and GANTI R K. A tractable approach to coverage and rate in cellular networks[J]. IEEE Transactions on Communications, 2011, 59(11): 3122–3134. doi: 10.1109/TCOMM.2011.100411.100541.
|
| [15] |
WU Dapeng, LI Jifang, HE Peng, et al. Social-aware graph-based collaborative caching in edge-user networks[J]. IEEE Transactions on Vehicular Technology, 2023, 72(6): 7926–7941. doi: 10.1109/TVT.2023.3241959.
|
| [16] |
YU Junliang, YIN Hongzhi, XIA Xin, et al. Self-supervised learning for recommender systems: A survey[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(1): 335–355. doi: 10.1109/TKDE.2023.3282907.
|
| [17] |
柯智慧. 协作边缘缓存与推荐联合优化策略研究[D]. [硕士论文], 天津大学, 2020.
KE Zhihui. Joint optimization of cooperative edge caching and recommendation[D]. [Master dissertation], Tianjin University, 2020.
|
| [18] |
ZHANG Tiankui, WANG Yi, LIU Yuanwei, et al. Cache-enabling UAV communications: Network deployment and resource allocation[J]. IEEE Transactions on Wireless Communications, 2020, 19(11): 7470–7483. doi: 10.1109/TWC.2020.3011881.
|
| [19] |
HARPER F M and KONSTAN J A. The MovieLens datasets: History and context[J]. ACM Transactions on Interactive Intelligent Systems, 2016, 5(4): 19. doi: 10.1145/2827872.
|
| [20] |
WANG Ruoxi, SHIVANNA R, CHENG D, et al. DCN V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems[C]. The Web Conference 2021, Ljubljana, Slovenia, 2021: 1785–1797. doi: 10.1145/3442381.3450078.
|
Figures(8) / Tables(2)



 DownLoad:
DownLoad: