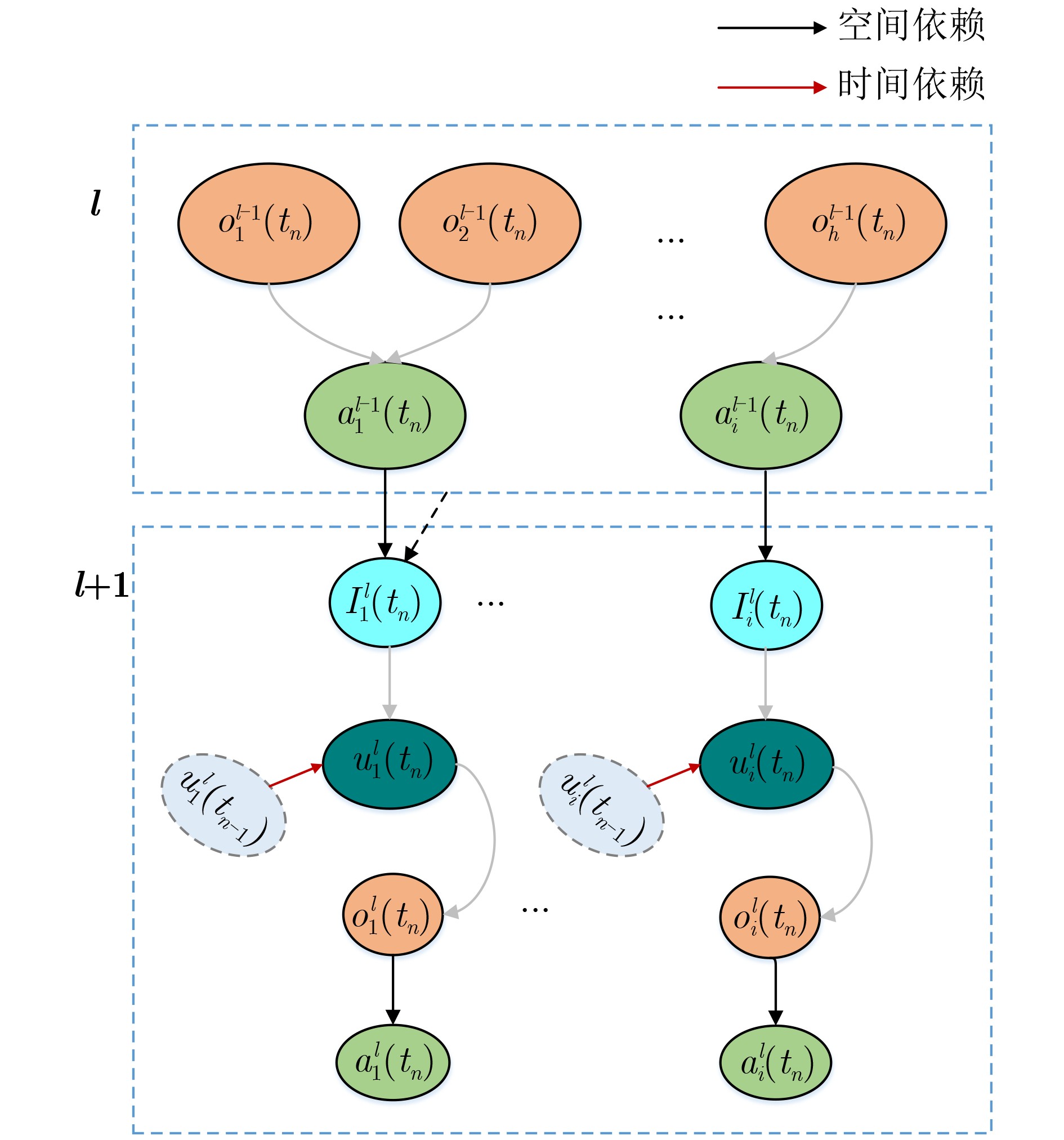
| Citation: | WANG Zihua, YE Ying, LIU Hongyun, XU Yan, FAN Yubo, WANG Weidong. Spiking Sequence Label-Based Spatio-Temporal Back-Propagation Algorithm for Training Deep Spiking Neural Networks[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2596-2604. doi: 10.11999/JEIT230705

|

| [1] |
YAMAZAKI K, VO-HO V K, BULSARA D, et al. Spiking neural networks and their applications: A review[J]. Brain Sciences, 2022, 12(7): 863. doi: 10.3390/brainsci12070863.
|
| [2] |
MAKAROV V A, LOBOV S A, SHCHANIKOV S, et al. Toward reflective spiking neural networks exploiting memristive devices[J]. Frontiers in Computational Neuroscience, 2022, 16: 859874. doi: 10.3389/fncom.2022.859874.
|
| [3] |
BÜCHEL J, ZENDRIKOV D, SOLINAS S, et al. Supervised training of spiking neural networks for robust deployment on mixed-signal neuromorphic processors[J]. Scientific Reports, 2021, 11(1): 23376. doi: 10.1038/s41598-021-02779-x.
|
| [4] |
ASGHAR M S, ARSLAN S, and KIM H. A low-power spiking neural network chip based on a compact LIF neuron and binary exponential charge injector synapse circuits[J]. Sensors, 2021, 21(13): 4462. doi: 10.3390/s21134462.
|
| [5] |
ROY K, JAISWAL A, and PANDA P. Towards spike-based machine intelligence with neuromorphic computing[J]. Nature, 2019, 575(7784): 607–617. doi: 10.1038/s41586-019-1677-2.
|
| [6] |
HODGKIN A L and HUXLEY A F. A quantitative description of membrane current and its application to conduction and excitation in nerve[J]. The Journal of Physiology, 1952, 117(4): 500–544. doi: 10.1113/jphysiol.1952.sp004764.
|
| [7] |
ZHAN Qiugang, LIU Guisong, XIE Xiurui, et al. Effective transfer learning algorithm in spiking neural networks[J]. IEEE Transactions on Cybernetics, 2022, 52(12): 13323–13335. doi: 10.1109/TCYB.2021.3079097.
|
| [8] |
LUO Xiaoling, QU Hong, WANG Yuchen, et al. Supervised learning in multilayer spiking neural networks with spike temporal error backpropagation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(12): 10141–10153. doi: 10.1109/TNNLS.2022.3164930.
|
| [9] |
JIANG Runhao, ZHANG Jie, YAN Rui, et al. Few-shot learning in spiking neural networks by multi-timescale optimization[J]. Neural Computation, 2021, 33(9): 2439–2472. doi: 10.1162/neco_a_01423.
|
| [10] |
XIE Xiurui, YU Bei, LIU Guisong, et al. Effective active learning method for spiking neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024: 1–10. doi: 10.1109/TNNLS.2023.3257333.
|
| [11] |
SENGUPTA A, YE Yuting, WANG R, et al. Going deeper in spiking neural networks: VGG and residual architectures[J]. Frontiers in Neuroscience, 2019, 13: 95. doi: 10.3389/fnins.2019.00095.
|
| [12] |
WU Yujie, DENG Lei, LI Guoji, et al. Spatio-temporal backpropagation for training high-performance spiking neural networks[J]. Frontiers in Neuroscience, 2018, 12: 331. doi: 10.3389/fnins.2018.00331.
|
| [13] |
WU Yujie, DENG Lei, LI Guoji et al. Direct training for spiking neural networks: Faster, larger, better[C]. The 33th AAAI Conference on Artificial Intelligence, California, USA, 2019: 1311–1318. doi: 10.1609/aaai.v33i01.33011311.
|
| [14] |
VAN ROSSUM M C. A novel spike distance[J]. Neural Computation, 2001, 13(4): 751–763. doi: 10.1162/089976601300014321.
|
| [15] |
BOHTE S M, KOK J N, and LA POUTRÉ H. Error-backpropagation in temporally encoded networks of spiking neurons[J]. Neurocomputing, 2002, 48(1/4): 17–37. doi: 10.1016/S0925-2312(1)00658-0.
|
| [16] |
XIAO Mingqing, MENG Qingyan, ZHANG Zongpeng, et al. SPIDE: A purely spike-based method for training feedback spiking neural networks[J]. Neural Networks, 2023, 161: 9–24. doi: 10.1016/j.neunet.2023.01.026.
|
| [17] |
GUO Yufei, HUANG Xuhui, and MA Zhe. Direct learning-based deep spiking neural networks: A review[J]. Frontiers in Neuroscience, 2023, 17: 1209795. doi: 10.3389/fnins.2023.1209795.
|
| [18] |
ZENKE F and GANGULI S. SuperSpike: Supervised learning in multilayer spiking neural networks[J]. Neural Computation, 2018, 30(6): 1514–1541. doi: 10.1162/neco_a_01086.
|
| [19] |
ZHANG Wenrui and LI Peng. Temporal spike sequence learning via backpropagation for deep spiking neural networks[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1008.
|
| [20] |
KRIZHEVSKY A, NAIR V, and HINTON G. The CIFAR-10 dataset[EB/OL]. https://www.cs.toronto.edu/~kriz/cifar.html, 2009.
|
| [21] |
ORCHARD G, JAYAWANT A, COHEN G K, et al. Converting static image datasets to spiking neuromorphic datasets using saccades[J]. Frontiers in Neuroscience, 2015, 9: 437. doi: 10.3389/fnins.2015.00437.
|
| [22] |
ZENKE F and VOGELS T P. The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks[J]. Neural Computation, 2021, 33(4): 899–925. doi: 10.1162/neco_a_01367.
|
| [23] |
TAVANAEI A, GHODRATI M, KHERADPISHEH S R, et al. Deep learning in spiking neural networks[J]. Neural Networks, 2019, 111: 47–63. doi: 10.1016/j.neunet.2018.12.002.
|
| [24] |
HUNSBERGER E and ELIASMITH C. Training spiking deep networks for neuromorphic hardware[EB/OL]. https://arxiv.org/abs/1611.05141, 2016.
|
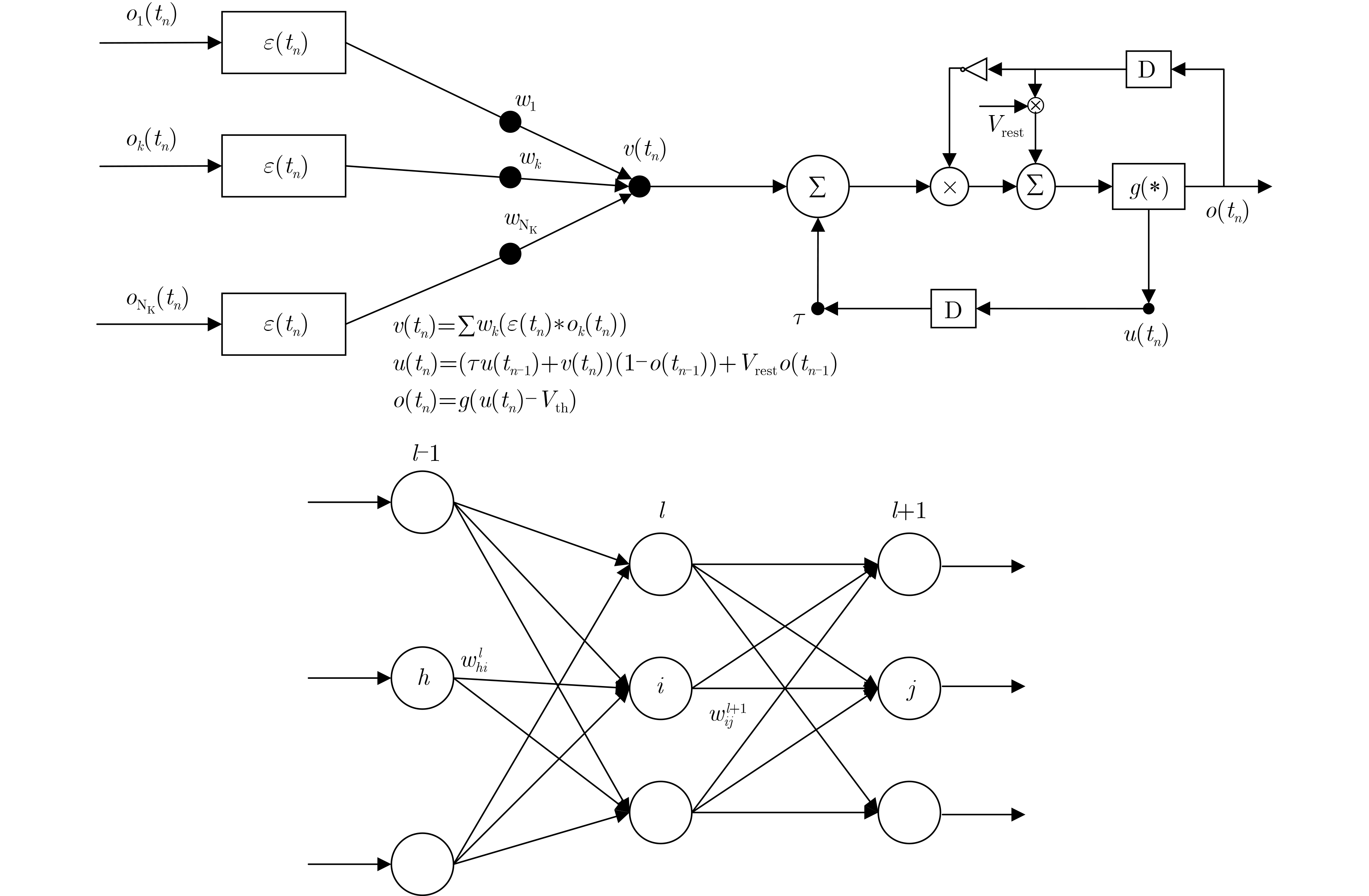
Figures(2) / Tables(5)



 DownLoad:
DownLoad: