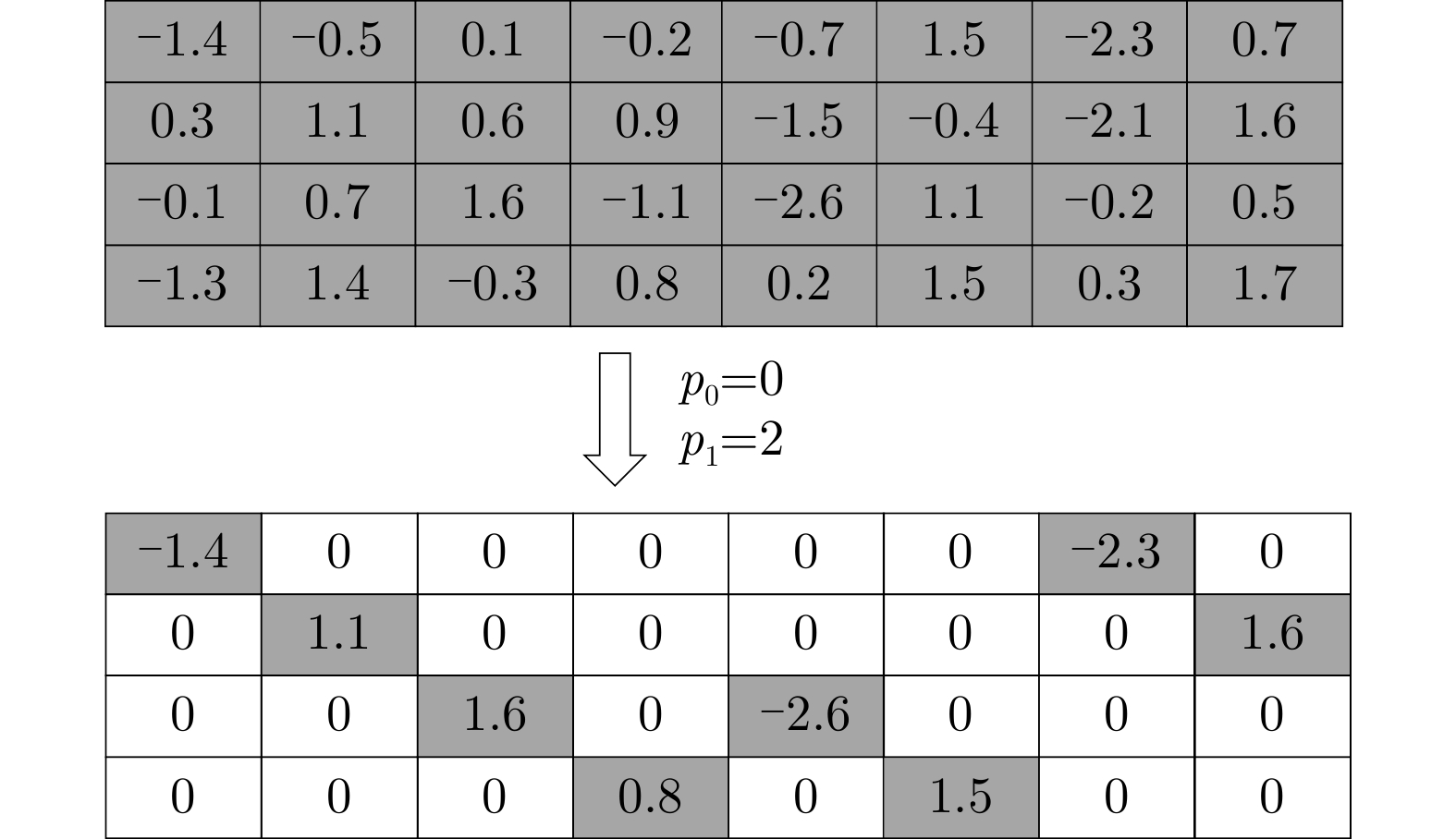
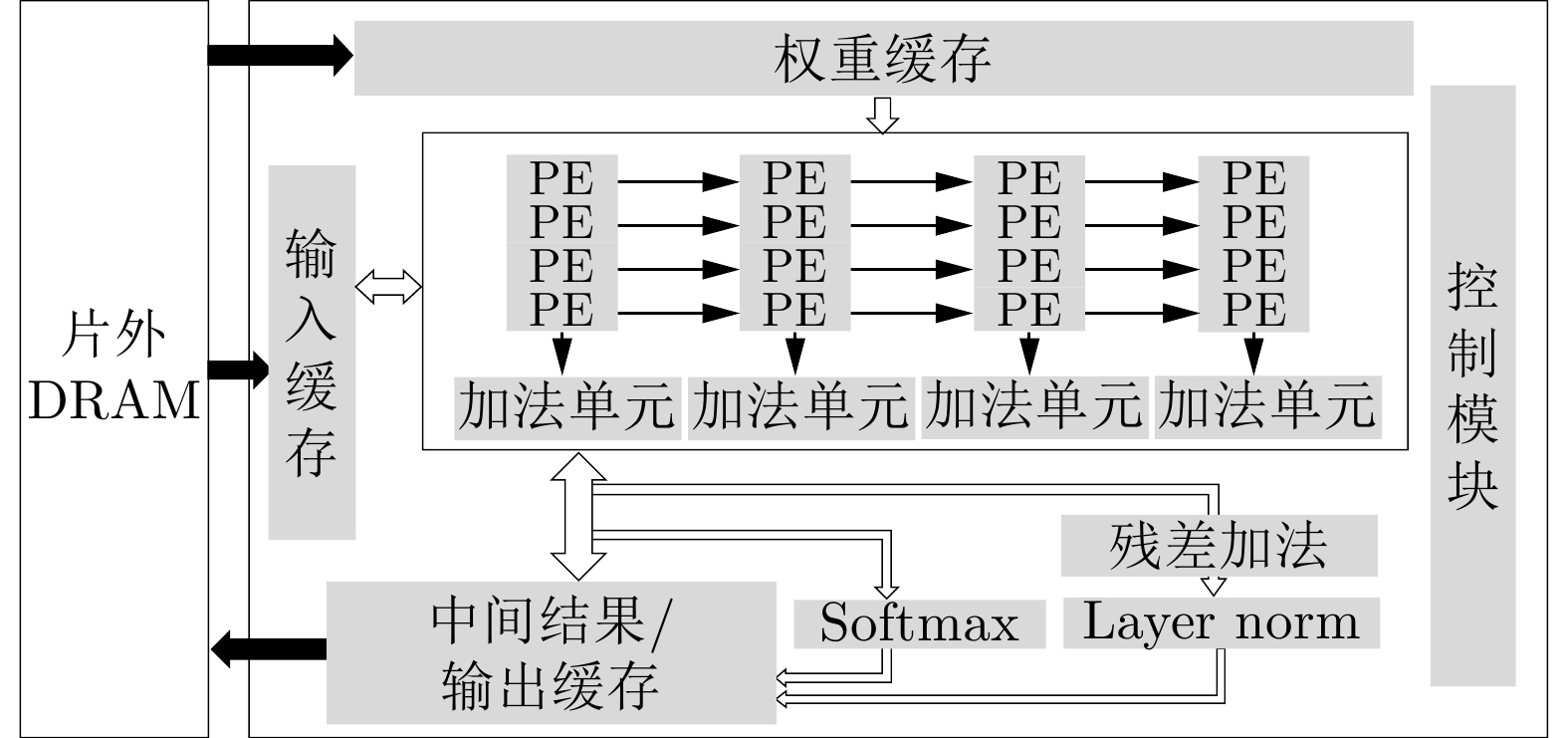
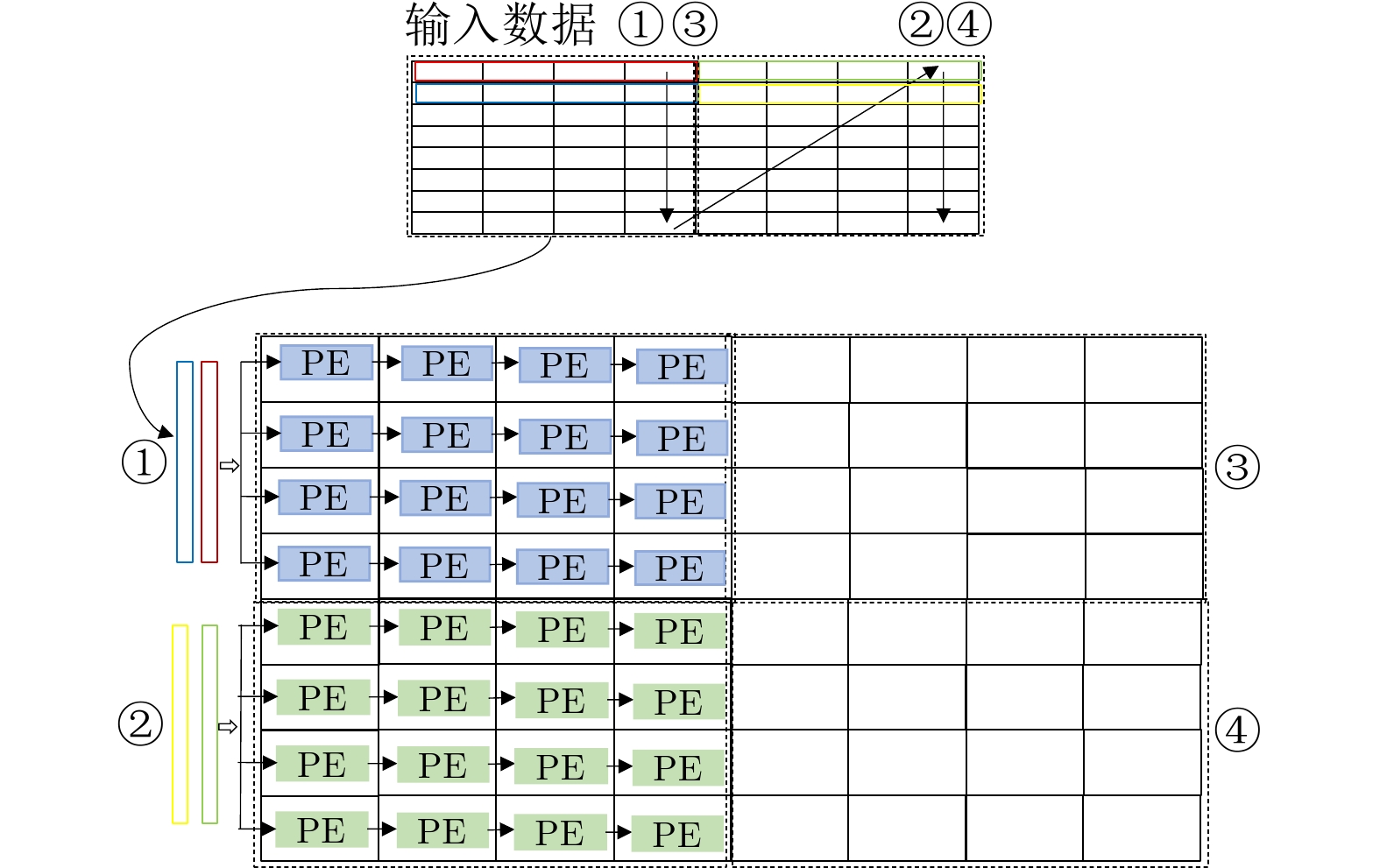
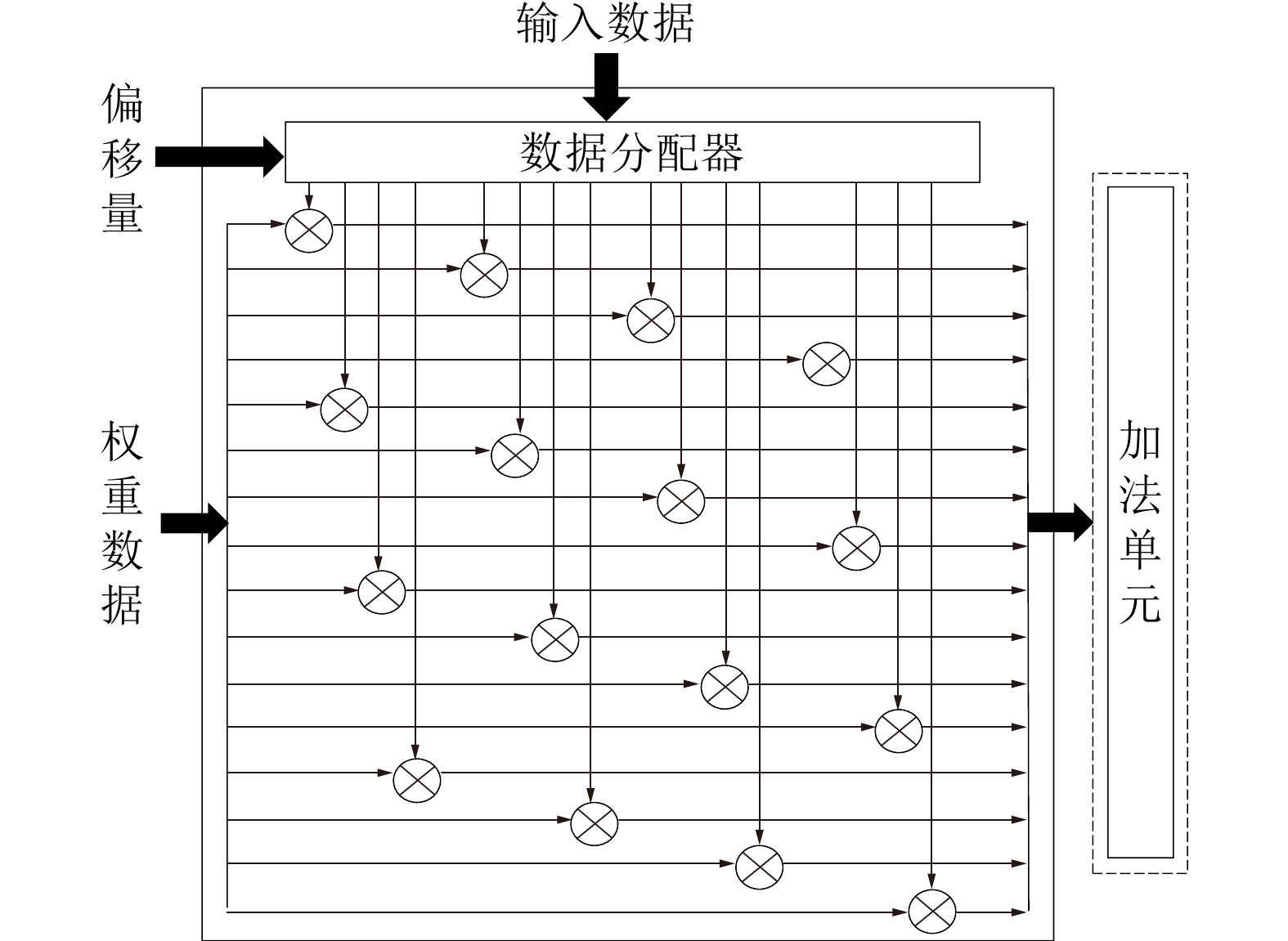
| Citation: | JIANG Xiaobo, DENG Hanke, MO Zhijie, LI Hongyuan. Design of Transformer Accelerator with Regular Compression Model and Flexible Architecture[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1079-1088. doi: 10.11999/JEIT230188

|

| [1] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010.
|
| [2] |
SUN Yu, WANG Shuohuan, LI Yukun, et al. Ernie 2.0: A continual pre-training framework for language understanding[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 8968–8975.
|
| [3] |
LIU Yinhan, OTT M, GOYAL N, et al. Roberta: A robustly optimized BERT pretraining approach[EB/OL]. https://doi.org/10.48550/arXiv.1907.11692, 2019.
|
| [4] |
DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, USA, 2018: 4171–4186.
|
| [5] |
YANG Zhilin, DAI Zihang, YANG Yiming, et al. XLNet: Generalized autoregressive pretraining for language understanding[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 517.
|
| [6] |
ROSSET C. Turing-NLG: A 17-billion-parameter language model by microsoft[EB/OL]. https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/, 2020.
|
| [7] |
ZHANG Xiang, ZHAO Junbo, and LECUN Y. Character-level convolutional networks for text classification[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 649–657.
|
| [8] |
LAI Siwei, XU Liheng, LIU Kang, et al. Recurrent convolutional neural networks for text classification[C]. Twenty-ninth AAAI Conference on Artificial Intelligence, Austin, USA, 2015: 2267–2273.
|
| [9] |
VOITA E, TALBOT D, MOISEEV F, et al. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 5797–5808.
|
| [10] |
LIN Zi, LIU J, YANG Zi, et al. Pruning redundant mappings in transformer models via spectral-normalized identity prior[C]. Findings of the Association for Computational Linguistics: EMNLP 2020, 2020: 719–730.
|
| [11] |
PENG Hongwu, HUANG Shaoyi, GENG Tong, et al. Accelerating transformer-based deep learning models on FPGAs using column balanced block pruning[C]. 2021 22nd International Symposium on Quality Electronic Design (ISQED), Santa Clara, USA, 2021: 142–148.
|
| [12] |
QI Panjie, SONG Yuhong, PENG Hongwu, et al. Accommodating transformer onto FPGA: Coupling the balanced model compression and FPGA-implementation optimization[C]. 2021 on Great Lakes Symposium on VLSI, 2021: 163–168.
|
| [13] |
LI Bingbing, PANDEY S, FANG Haowen, et al. FTRANS: Energy-efficient acceleration of transformers using FPGA[C]. ACM/IEEE International Symposium on Low Power Electronics and Design, Boston, USA, 2020: 175–180.
|
| [14] |
ZHANG Xinyi, WU Yawen, ZHOU Peipei, et al. Algorithm-hardware co-design of attention mechanism on FPGA devices[J]. ACM Transactions on Embedded Computing Systems, 2021, 20(5s): 71. doi: 10.1145/3477002.
|
| [15] |
PARK J, YOON H, AHN D, et al. OPTIMUS: OPTImized matrix MUltiplication structure for transformer neural network accelerator[C]. Machine Learning and Systems, Austin, USA, 2020: 363–378.
|
| [16] |
DENG Chunhua, LIAO Siyu, and YUAN Bo. PermCNN: Energy-efficient convolutional neural network hardware architecture with permuted diagonal structure[J]. IEEE Transactions on Computers, 2021, 70(2): 163–173. doi: 10.1109/TC.2020.2981068.
|
| [17] |
WU Shuang, LI Guoqi, DENG Lei, et al. L1-norm batch normalization for efficient training of deep neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(7): 2043–2051. doi: 10.1109/TNNLS.2018.2876179.
|
| [18] |
BARRETT R, BERRY M, CHAN T F, et al. Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods[M]. Philadelphia: Society for Industrial and Applied Mathematics, 1994: 5–37.
|
| [19] |
LIU Weifeng and VINTER B. CSR5: An efficient storage format for cross-platform sparse matrix-vector multiplication[C]. The 29th ACM on International Conference on Supercomputing, Newport Beach, USA, 2015: 339–350.
|
| [20] |
PINAR A and HEATH M T. Improving performance of sparse matrix-vector multiplication[C]. SC'99: Proceedings of 1999 ACM/IEEE Conference on Supercomputing, Portland, USA, 1999: 30.
|
| [21] |
ZACHARIADIS O, SATPUTE N, GÓMEZ-LUNA J, et al. Accelerating sparse matrix–matrix multiplication with GPU tensor cores[J]. Computers & Electrical Engineering, 2020, 88: 106848. doi: 10.1016/j.compeleceng.2020.106848.
|
| [22] |
KANNAN R. Efficient sparse matrix multiple-vector multiplication using a bitmapped format[C]. 20th Annual International Conference on High Performance Computing, Bengaluru, India, 2013: 286–294.
|
| [23] |
QI Panjie, SHA E H M, ZHUGE Q, et al. Accelerating framework of transformer by hardware design and model compression co-optimization[C]. 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, 2021: 1–9.
|
| [24] |
WANG Hanrui, WU Zhanghao, LIU Zhijian, et al. HAT: Hardware-aware transformers for efficient natural language processing[C]. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020: 7675–7688.
|
| [25] |
LIU Zejian, LI Gang, and CHENG Jian. Hardware acceleration of fully quantized BERT for efficient natural language processing[C]. 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 2021: 513–516.
|
| [26] |
LU Siyuan, WANG Meiqi, LIANG Shuang, et al. Hardware accelerator for multi-head attention and position-wise feed-forward in the transformer[C]. 2020 IEEE 33rd International System-on-Chip Conference (SOCC), Las Vegas, USA, 2020: 84–89.
|
Figures(11) / Tables(10)



 DownLoad:
DownLoad: