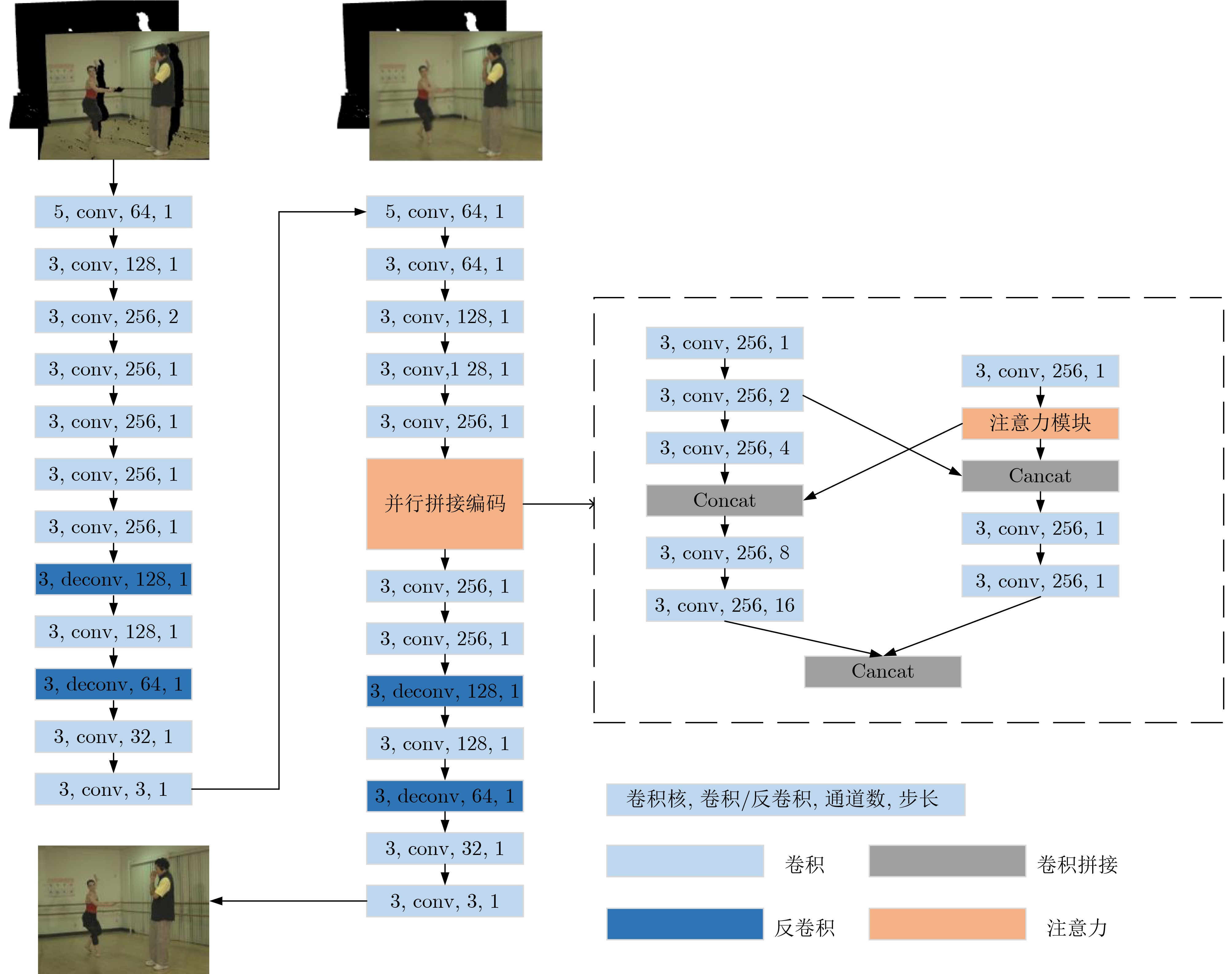
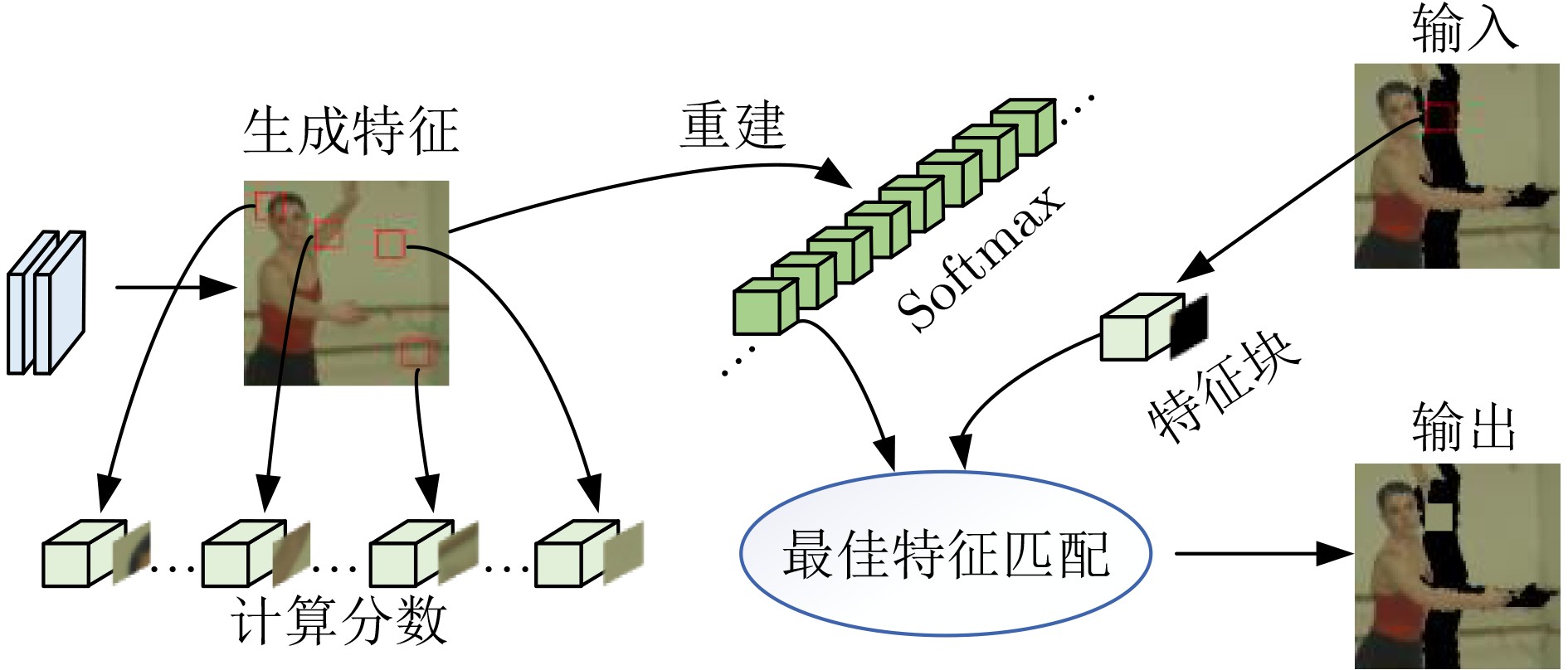
| Citation: | ZHOU Yang, CAI Maomao, HUANG Xiaofeng, YIN Haibing. Hole Filling for Virtual View Synthesized Image by Combining with Contextual Feature Fusion[J]. Journal of Electronics & Information Technology, 2024, 46(4): 1479-1487. doi: 10.11999/JEIT230181

|

| [1] |
DE OLIVEIRA A Q, DA SILVEIRA T L T, WALTER M, et al. A hierarchical superpixel based approach for DIBR view synthesis[J]. IEEE Transactions on Image Processing, 2021, 30: 6408–6419. doi: 10.1109/TIP.2021.3092817.
|
| [2] |
CRIMINISI A, PEREZ P, and TOYAMA K. Region filling and object removal by exemplar-based image inpainting[J]. IEEE Transactions on Image Processing, 2004, 13(9): 1200–1212. doi: 10.1109/TIP.2004.833105.
|
| [3] |
ZHU Ce and LI Shuai. Depth image based view synthesis: New insights and perspectives on Hole generation and filling[J]. IEEE Transactions on Broadcasting, 2016, 62(1): 82–93. doi: 10.1109/TBC.2015.2475697.
|
| [4] |
CHANG Yuan, CHEN Yisong, and WANG Guoping. Range guided depth refinement and uncertainty-aware aggregation for view synthesis[C]. International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 2290-2294. doi: 10.1109/ICASSP39728.2021.9413981.
|
| [5] |
CHENG Cong, LIU Ju, YUAN Hui, et al. A DIBR method based on inverse mapping and depth-aided image inpainting[C]. 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 2013: 518-522. doi: 10.1109/ChinaSIP.2013.6625394.
|
| [6] |
ANH I and KIM C. A novel depth-based virtual view synthesis method for free viewpoint video[J]. IEEE Transactions on Broadcasting, 2013, 59(4): 614–626. doi: 10.1109/TBC.2013.2281658.
|
| [7] |
RAHAMAN D M M and PAUL M. Virtual view synthesis for free viewpoint video and Multiview video compression using Gaussian mixture modelling[J]. IEEE Transactions on Image Processing, 2018, 27(3): 1190–1201. doi: 10.1109/TIP.2017.2772858.
|
| [8] |
LUO Guibo, ZHU Yuesheng, WENG Zhenyu, et al. A disocclusion inpainting framework for depth-based view synthesis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(6): 1289–1302. doi: 10.1109/TPAMI.2019.2899837.
|
| [9] |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. doi: 10.5555/2969033.2969125.
|
| [10] |
RADFORD A, METZ L, and CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[C]. 4th International Conference on Learning Representations, Puerto Rico, 2016: 1–16.
|
| [11] |
IIZUKA S, SIMO-SERRA E, and ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 107. doi: 10.1145/3072959.3073659.
|
| [12] |
LI Jingyuan, WANG Ning, ZHANG Lefei, et al. Recurrent feature reasoning for image inpainting[C]. Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7757–7765. doi: 10.1109/CVPR42600.2020.00778.
|
| [13] |
XU Shunxin, LIU Dong, and XIONG Zhiwei. E2I: Generative inpainting from edge to image[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(4): 1308–1322. doi: 10.1109/TCSVT.2020.3001267.
|
| [14] |
SHIN Y G, SAGONG M C, YEO Y J, et al. PEPSI++: Fast and lightweight network for image inpainting[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 252–265. doi: 10.1109/TNNLS.2020.2978501.
|
| [15] |
孙磊, 杨宇, 毛秀青, 等. 基于空间特征的生成对抗网络数据生成方法[J]. 电子与信息学报, 2023, 45(6): 1959–1969. doi: 10.11999/JEIT211285.
SUN Lei, YANG Yu, MAO Xiuqing, et al. Data Generation based on generative adversarial network with spatial features[J]. Journal of Electronics & Information Technology, 2023, 45(6): 1959–1969. doi: 10.11999/JEIT211285.
|
| [16] |
YU Jiahui, LIN Zhe, YANG Jimei, et al. Free-form image inpainting with gated convolution[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 4470–4479. doi: 10.1109/ICCV.2019.00457.
|
| [17] |
PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2536–2544. doi: 10.1109/CVPR.
|
| [18] |
LIU Guilin, DUNDAR A, SHIH K J, et al. Partial convolution for padding, inpainting, and image synthesis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 6096–6110. doi: 10.1109/TPAMI.2022.3209702.
|
| [19] |
Microsoft. MSR 3D Video dataset from official microsoft download center[EB/OL]. https://www.microsoft.com/en-us/download/details.aspx?id=52358, 2014.
|
| [20] |
JOHNSON J, ALAHI A, and LI Feifei. Perceptual losses for real-time style transfer and super-resolution[C]. 14th European Conference Computer Vision 2016, Amsterdam, Netherlands, 2016: 694–711. doi: 10.1007/978-3-319-46475-6_43.
|
| [21] |
YUAN H L and VELTKAMP R C. Free-viewpoint image based rendering with multi-layered depth maps[J]. Optics and Lasers in Engineering, 2021, 147: 106726. doi: 10.1016/j.optlaseng.2021.106726.
|
| [22] |
UDDIN S M N and JUNG Y J. Global and local attention-based free-form image inpainting[J]. Sensors, 2020, 20(11): 3204. doi: 10.3390/s20113204.
|
| [23] |
STANKIEWICZ O and WEGNER K. Depth estimation reference software and view synthesis reference software[S]. Switzerland: ISO/IEC JTC1/SC29/WG11 MPEG/M16027, 2009.
|
| [24] |
LI Zhen, LU Chengze, QIN Jianhua, et al. Towards an end-to-end framework for flow-guided video inpainting[C]. Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 17541–17550. doi: 10.1109/CVPR52688.2022.01704.
|
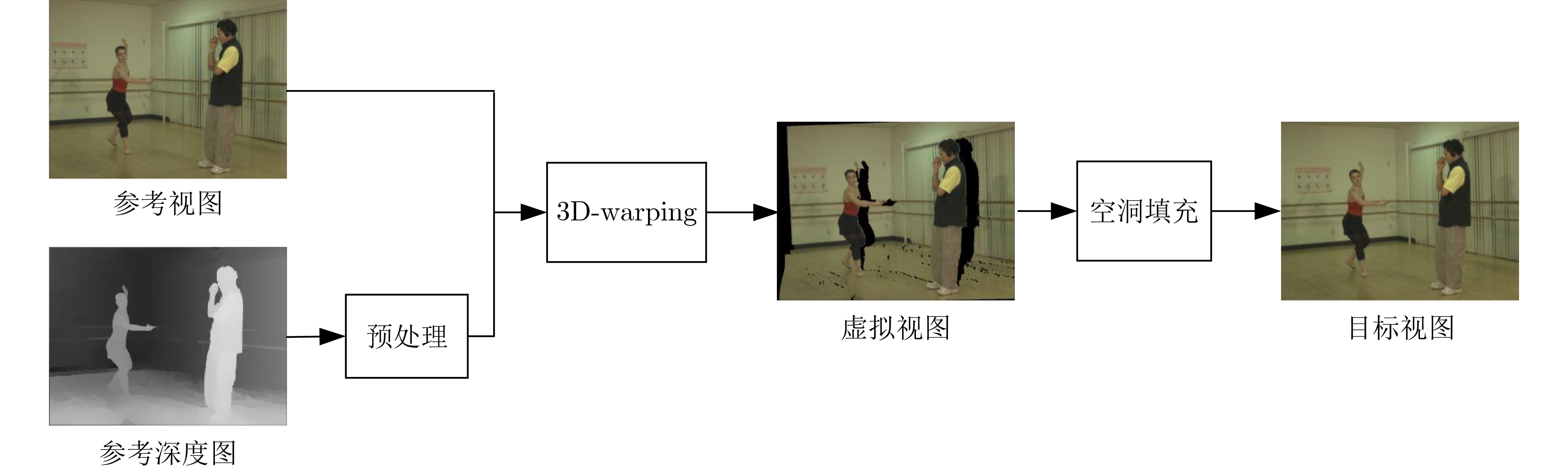
Figures(8) / Tables(4)



 DownLoad:
DownLoad: