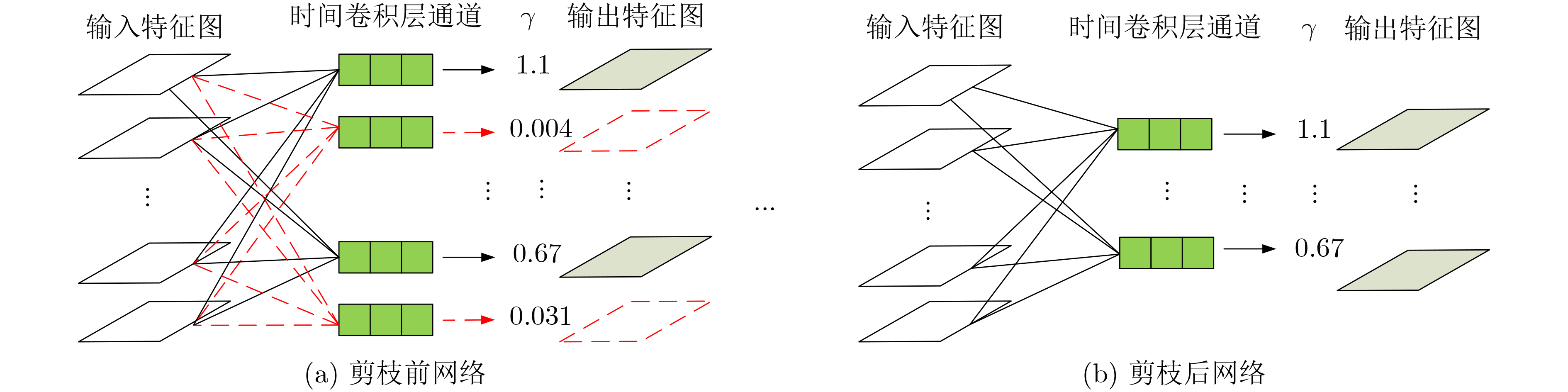
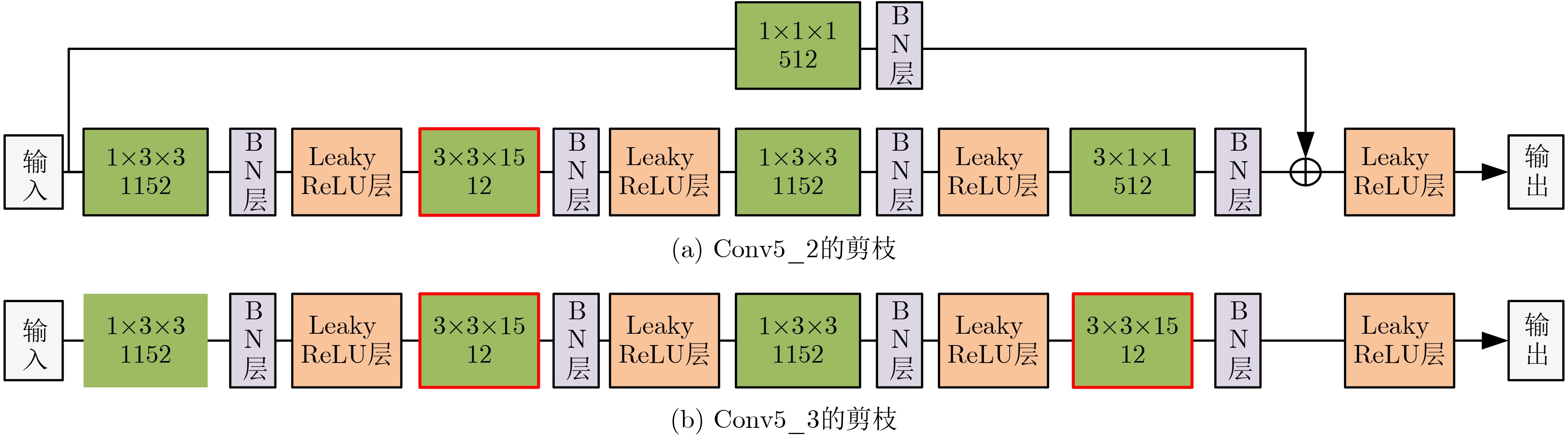
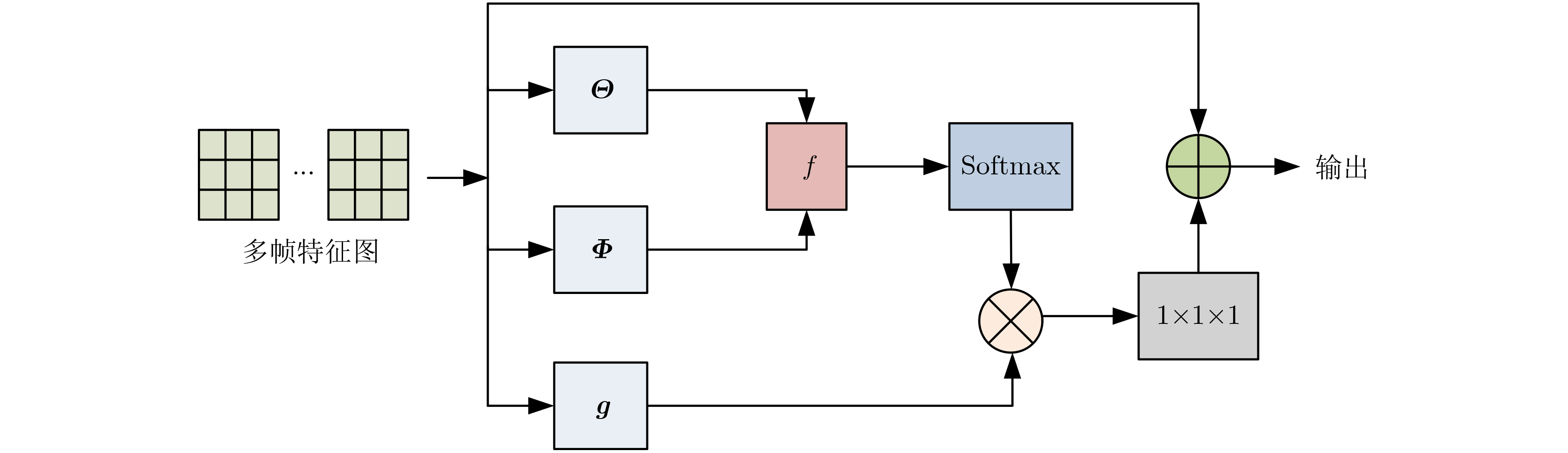
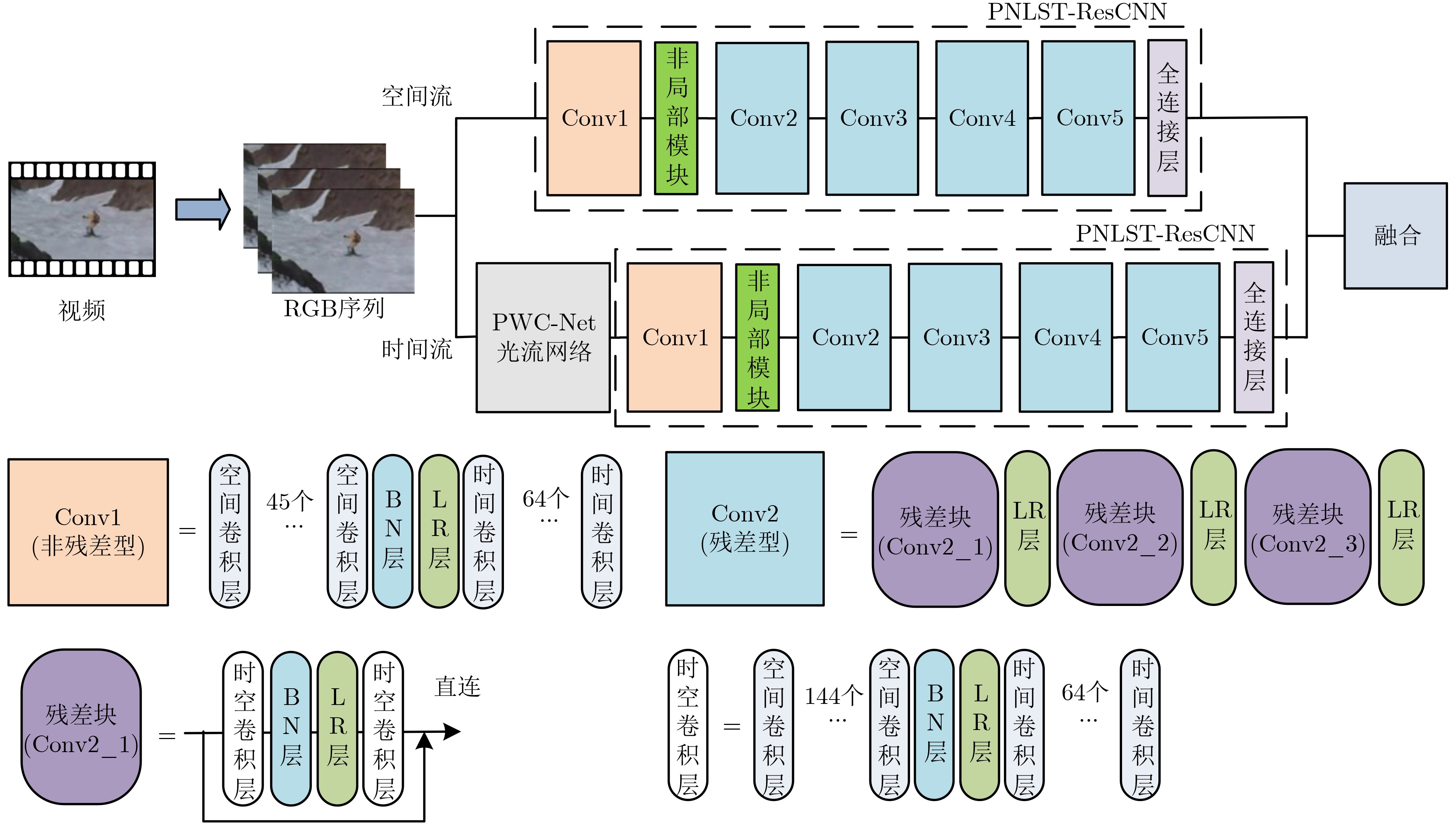
| Citation: | QIAN Huimin, CHEN Shi, HUANGFU Xiaoying. Human Activities Recognition Based on Two-stream NonLocal Spatial Temporal Residual Convolution Neural Network[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1100-1108. doi: 10.11999/JEIT230168

|

| [1] |
白静, 杨瞻源, 彭斌, 等. 三维卷积神经网络及其在视频理解领域中的应用研究[J]. 电子与信息学报, 2023, 45(6): 2273–2283. doi: 10.11999/JEIT220596.
BAI Jing, YANG Zhanyuan, PENG Bin, et al. Research on 3D convolutional neural network and its application to video understanding[J]. Journal of Electronics &Information Technology, 2023, 45(6): 2273–2283. doi: 10.11999/JEIT220596.
|
| [2] |
CARREIRA J and ZISSERMAN A. QUO Vadis, action recognition? A new model and the kinetics dataset[C]. The 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6299–6308.
|
| [3] |
QIU Zhaofan, YAO Ting, and MEI Tao. Learning spatio-temporal representation with pseudo-3D residual networks[C]. The 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5534–5542.
|
| [4] |
王粉花, 张强, 黄超, 等. 融合双流三维卷积和注意力机制的动态手势识别[J]. 电子与信息学报, 2021, 43(5): 1389–1396. doi: 10.11999/JEIT200065.
WANG Fenhua, ZHANG Qiang, HUANG Chao, et al. Dynamic gesture recognition combining two-stream 3D convolution with attention mechanisms[J]. Journal of Electronics &Information Technology, 2021, 43(5): 1389–1396. doi: 10.11999/JEIT200065.
|
| [5] |
PANG Chen, LU Xuequan, and LYU Lei. Skeleton-based action recognition through contrasting two-stream spatial-temporal networks[J]. IEEE Transactions on Multimedia, 2023, 1520–9210.
|
| [6] |
VARSHNEY N and BAKARIYA B. Deep convolutional neural model for human activities recognition in a sequence of video by combining multiple CNN streams[J]. Multimedia Tools and Applications, 2022, 81(29): 42117–42129. doi: 10.1007/s11042-021-11220-4.
|
| [7] |
LI Bing, CUI Wei, WANG Wei, et al. Two-stream convolution augmented transformer for human activity recognition[C]. The 35th AAAI Conference on Artificial Intelligence, 2021: 286–293.
|
| [8] |
ILG E, MAYER N, SAIKIA T, et al. Flownet 2.0: Evolution of optical flow estimation with deep networks[C]. The 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1647–1655.
|
| [9] |
SUN Deqing, YANG Xiaodong, LIU Mingyu, et al. PWC-net: CNNs for optical flow using pyramid, warping, and cost volume[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8934–8943.
|
| [10] |
WEI S E, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]. The 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 4724–4732.
|
| [11] |
LI Xinyu, SHUAI Bing, and TIGHE J. Directional temporal modeling for action recognition[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 275–291.
|
| [12] |
WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803.
|
| [13] |
HUANG Min, QIAN Huimin, HAN Yi, et al. R(2+1)D-based two-stream CNN for human activities recognition in videos[C]. The 40th Chinese Control Conference, Shanghai, China, 2021: 7932–7937.
|
| [14] |
LIU Zhuang, LI Jianguo, SHEN Zhiqiang, et al. Learning efficient convolutional networks through network slimming[C]. The 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2755–2763.
|
| [15] |
VAROL G, LAPTEV I, and SCHMID C. Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510–1517. doi: 10.1109/TPAMI.2017.2712608.
|
| [16] |
SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[OL]. arXiv preprint arXiv: 1907.06987, 2012.
|
| [17] |
KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: A large video database for human motion recognition[C]. The 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2556−2563.
|
| [18] |
KAY W, CARREIRA J, SIMONYAN K, et al. The kinetics human action video dataset[OL]. arXiv preprint arXiv: 1705.06950, 2017.
|
| [19] |
CARREIRA J, NOLAND E, HILLIER C, et al. A short note on the kinetics-700 human action dataset[OL]. arXiv preprint arXiv: 1907.06987, 2019.
|
| [20] |
KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]. The 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1725–1732.
|
| [21] |
KATAOKA H, WAKAMIYA T, HARA K, et al. Would mega-scale datasets further enhance spatiotemporal 3D CNNs?[OL]. arXiv preprint arXiv: 2004.04968, 2020.
|
| [22] |
WANG Mengmeng, XING Jiazheng, and LIU Yong. ActionCLIP: A new paradigm for video action recognition[J]. arXiv preprint arXiv: 2109.08472, 2021.
|
| [23] |
JIANG Boyuan, WANG Mengmeng, GAN Weihao, et al. STM: SpatioTemporal and motion encoding for action recognition[C]. The 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 2000–2009.
|
| [24] |
TRAN D, WANG Heng, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]. The 2018 IEEE/CVF conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6450–6459.
|
Figures(4) / Tables(6)



 DownLoad:
DownLoad: