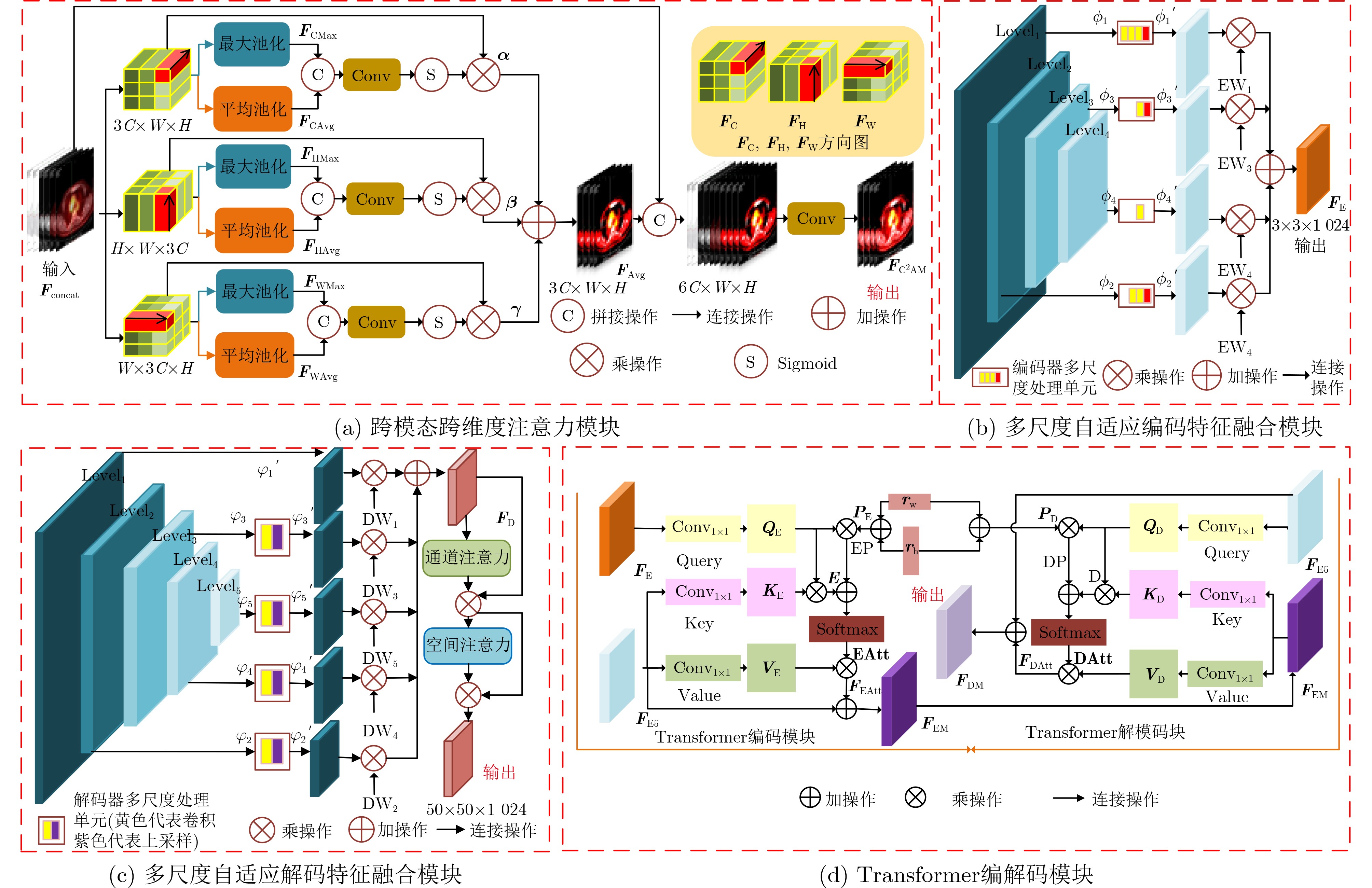
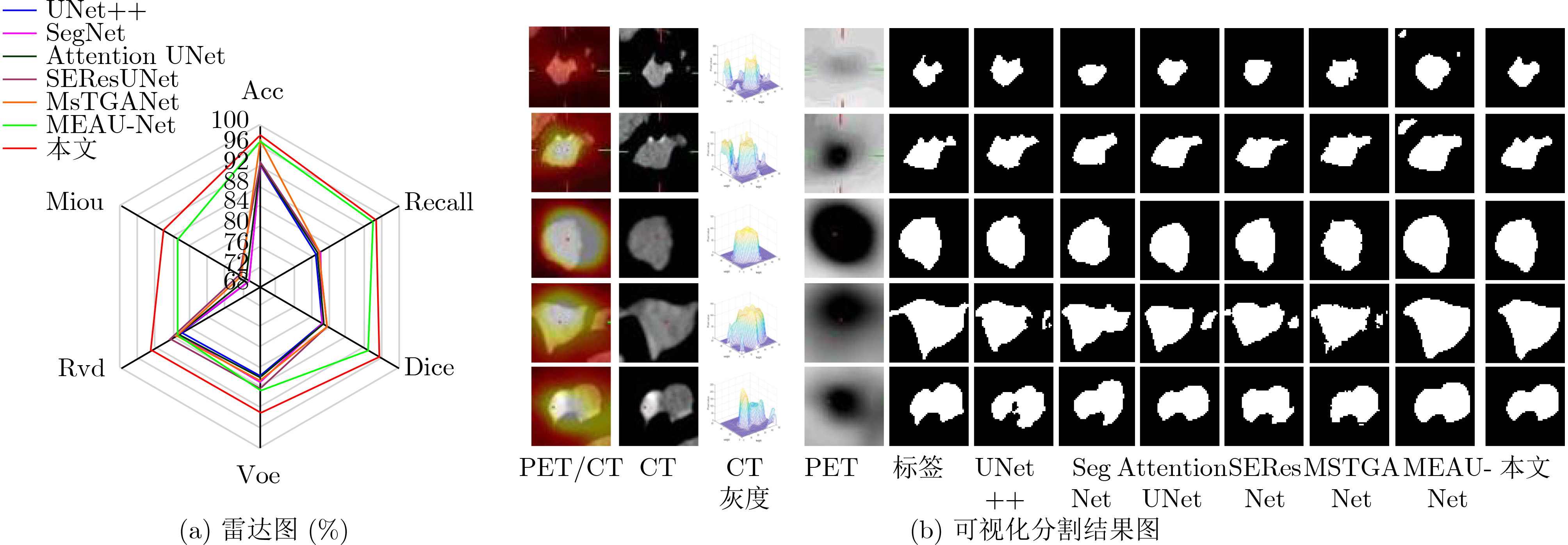
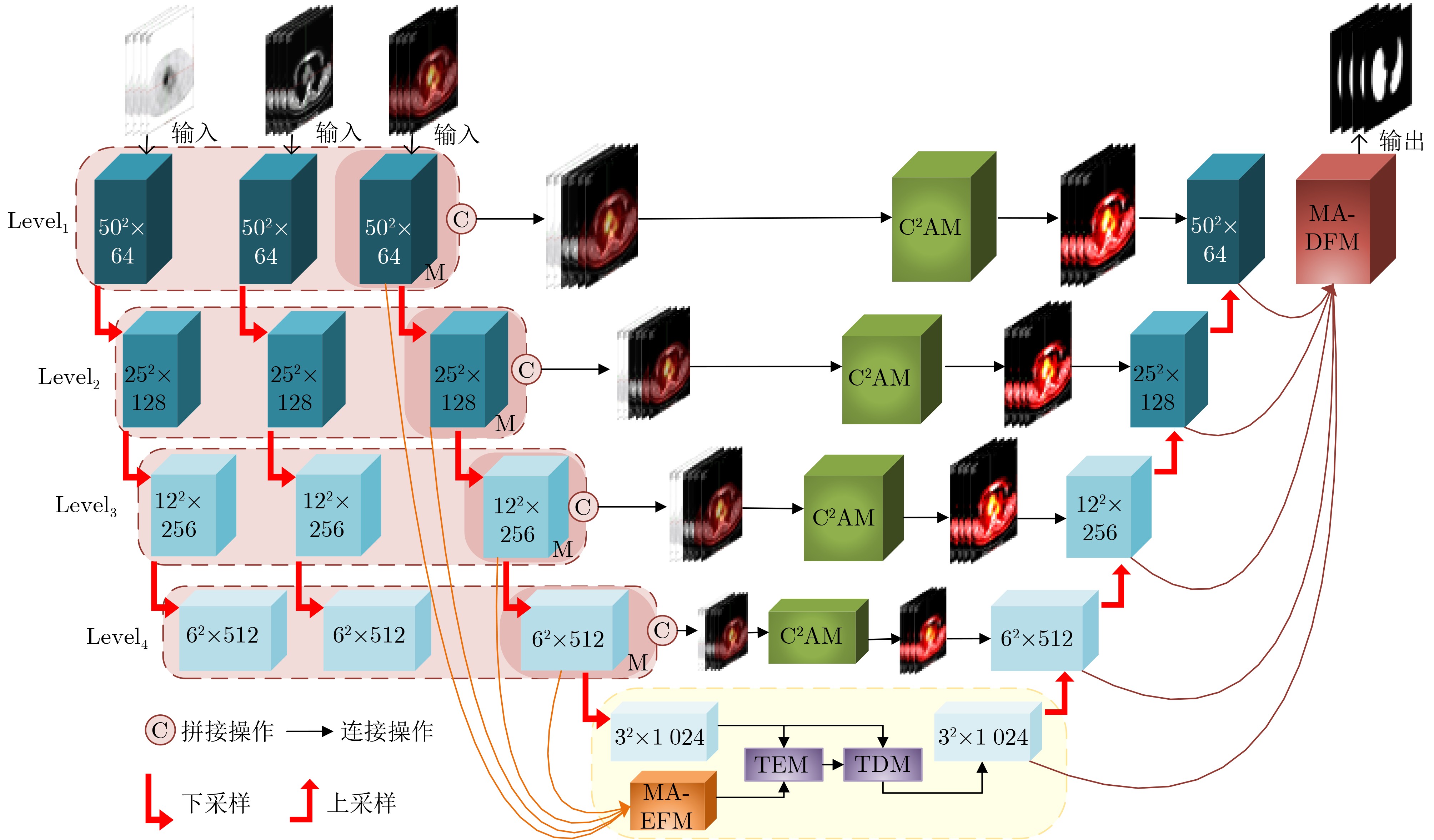
| Citation: | ZHOU Tao, DANG Pei, LU Huiling, HOU Senbao, PENG Caiyue, SHI Hongbin. A Transformer Segmentation Model for PET/CT Images with Cross-modal, Cross-scale and Cross-dimensional[J]. Journal of Electronics & Information Technology, 2023, 45(10): 3529-3537. doi: 10.11999/JEIT221204

|

| [1] |
WANG Xue, LI Zhanshan, HUANG Yongping, et al. Multimodal medical image segmentation using multi-scale context-aware network[J]. Neurocomputing, 2022, 486: 135–146. doi: 10.1016/j.neucom.2021.11.017
|
| [2] |
FU Xiaohang, LEI Bi, KUMAR A, et al. Multimodal spatial attention module for targeting multimodal PET-CT lung tumor segmentation[J]. IEEE Journal of Biomedical and Health Informatics, 2021, 25(9): 3507–3516. doi: 10.1109/JBHI.2021.3059453
|
| [3] |
周涛, 董雅丽, 刘珊, 等. 用于肺部肿瘤图像分割的跨模态多编码混合注意力U-Net[J]. 光子学报, 2022, 51(4): 0410006. doi: 10.3788/gzxb20225104.0410006
ZHOU Tao, DONG Yali, LIU Shan, et al. Cross-modality multi-encoder hybrid attention U-Net for lung tumors images segmentation[J]. Acta Photonica Sinica, 2022, 51(4): 0410006. doi: 10.3788/gzxb20225104.0410006
|
| [4] |
KUMAR A, FULHAM M, FENG Dagan, et al. Co-learning feature fusion maps from PET-CT images of lung cancer[J]. IEEE Transactions on Medical Imaging, 2020, 39(1): 204–217. doi: 10.1109/TMI.2019.2923601
|
| [5] |
田永林, 王雨桐, 王建功, 等. 视觉Transformer研究的关键问题: 现状及展望[J]. 自动化学报, 2022, 48(4): 957–979. doi: 10.16383/j.aas.c220027
TIAN Yonglin, WANG Yutong, WANG Jiangong, et al. Key problems and progress of vision transformers: The state of the art and prospects[J]. Acta Automatica Sinica, 2022, 48(4): 957–979. doi: 10.16383/j.aas.c220027
|
| [6] |
胡敏, 周秀东, 黄宏程, 等. 基于改进U型神经网络的脑出血CT图像分割[J]. 电子与信息学报, 2022, 44(1): 127–137. doi: 10.11999/JEIT200996
HU Min, ZHOU Xiudong, HUANG Hongcheng, et al. Computed-tomography image segmentation of cerebral hemorrhage based on improved U-shaped neural network[J]. Journal of Electronics &Information Technology, 2022, 44(1): 127–137. doi: 10.11999/JEIT200996
|
| [7] |
WANG Ziyue, PENG Yanjun, LI Dapeng, et al. MMNet: A multi-scale deep learning network for the left ventricular segmentation of cardiac MRI images[J]. Applied Intelligence, 2022, 52(5): 5225–5240. doi: 10.1007/s10489-021-02720-9
|
| [8] |
ZHOU Tao, YE Xinyu, LU Huiling, et al. Dense convolutional network and its application in medical image analysis[J]. BioMed Research International, 2022, 2022: 2384830. doi: 10.1155/2022/2384830
|
| [9] |
LIU Songtao, HUANG Di, and WANG Yunhong. Learning spatial fusion for single-shot object detection[EB/OL]. https://arxiv.org/abs/1911.09516v1, 2019.
|
| [10] |
WANG Meng, ZHU Weifang, SHI Fei, et al. MsTGANet: Automatic drusen segmentation from retinal OCT images[J]. IEEE Transactions on Medical Imaging, 2022, 41(2): 394–406. doi: 10.1109/TMI.2021.3112716
|
| [11] |
RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-assisted Intervention, Munich, Germany, 2015: 234–241.
|
| [12] |
LAN Hengrong, JIANG Daohuai, YANG Changchun, et al. Y-Net: Hybrid deep learning image reconstruction for photoacoustic tomography in vivo[J]. Photoacoustics, 2020, 20: 100197. doi: 10.1016/j.pacs.2020.100197
|
| [13] |
ZHOU Zongwei, SIDDIQUEE M R, TAJBAKHSH N, et al. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation[J]. IEEE Transactions on Medical Imaging, 2020, 39(6): 1856–1867. doi: 10.1109/TMI.2019.2959609
|
| [14] |
BADRINARAYANAN V, KENDALL A, and CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481–2495. doi: 10.1109/TPAMI.2016.2644615
|
| [15] |
OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention U-Net: Learning where to look for the pancreas[EB/OL]. https://arxiv.org/abs/1804.03999, 2018.
|
| [16] |
CAO Zheng, YU Bohan, LEI Biwen, et al. Cascaded SE-ResUnet for segmentation of thoracic organs at risk[J]. Neurocomputing, 2021, 453: 357–368. doi: 10.1016/j.neucom.2020.08.086
|
Figures(5) / Tables(4)



 DownLoad:
DownLoad: