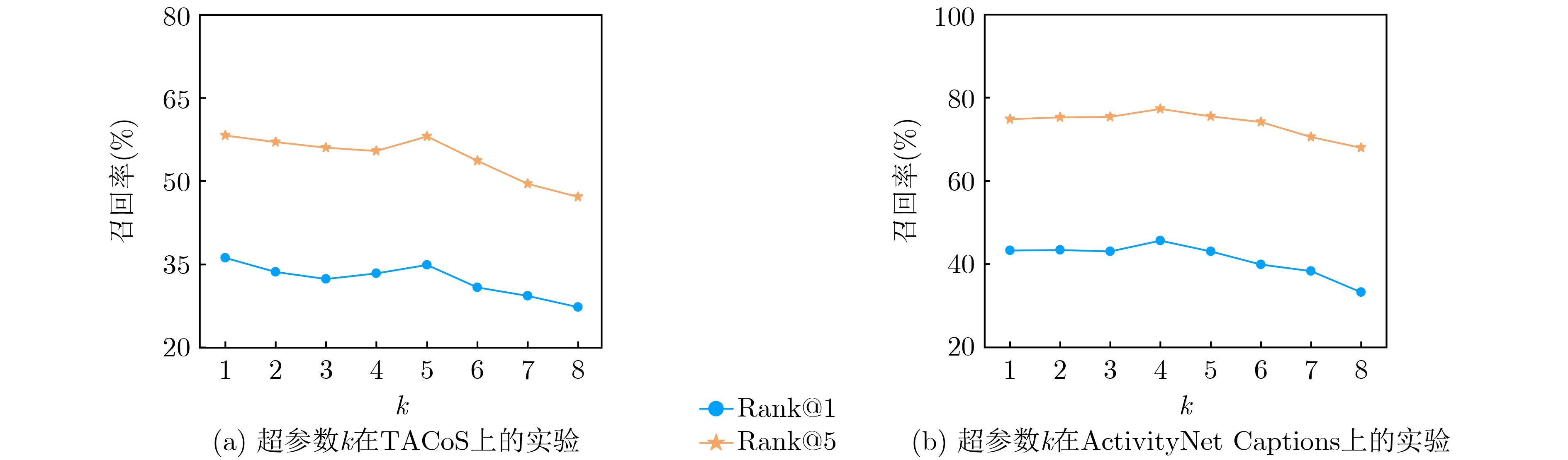
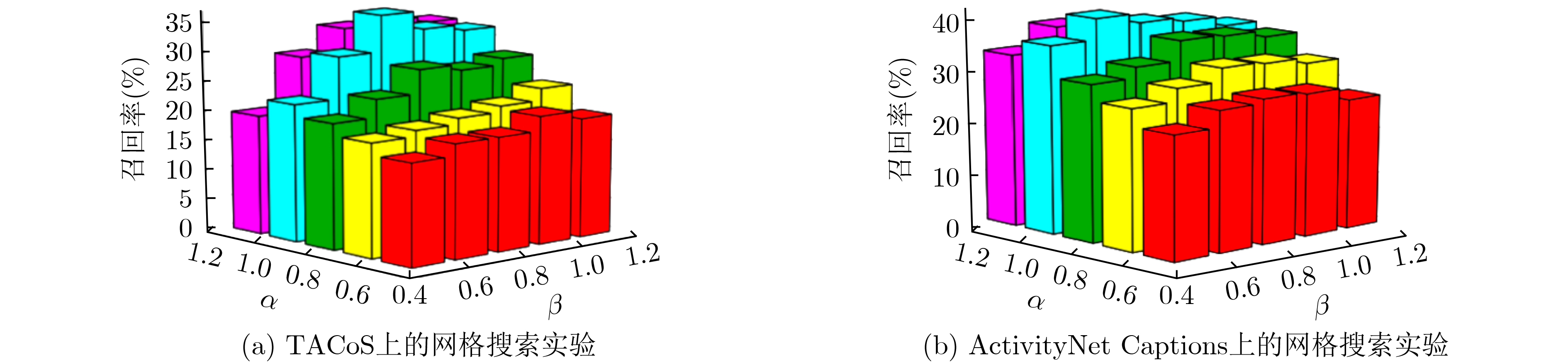
| Citation: | YANG Jinfu, LIU Yubin, SONG Lin, YAN Xue. Cross-modal Video Moment Retrieval Based on Enhancing Significant Features[J]. Journal of Electronics & Information Technology, 2022, 44(12): 4395-4404. doi: 10.11999/JEIT211101

|

| [1] |
GAO Jiyang, SUN Chen, YANG Zhenheng, et al. TALL: Temporal activity localization via language query[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5277–5285.
|
| [2] |
GE Runzhou, GAO Jiyang, CHEN Kan, et al. MAC: Mining activity concepts for language-based temporal localization[C]. 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2019: 245–253.
|
| [3] |
LIU Meng, WANG Xiang, NIE Liqiang, et al. Cross-modal moment localization in videos[C]. The 26th ACM International Conference on Multimedia, Seoul, Korea, 2018: 843–851.
|
| [4] |
ZHANG Songyang, PENG Houwen, FU Jianlong, et al. Learning 2D temporal adjacent networks for moment localization with natural language[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12870–12877.
|
| [5] |
LIU Meng, WANG Xiang, NIE Liqiang, et al. Attentive moment retrieval in videos[C]. The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, USA, 2018: 15–24.
|
| [6] |
NING Ke, XIE Lingxi, LIU Jianzhuang, et al. Interaction-integrated network for natural language moment localization[J]. IEEE Transactions on Image Processing, 2021, 30: 2538–2548. doi: 10.1109/TIP.2021.3052086
|
| [7] |
HAHN M, KADAV A, REHG J M, et al. Tripping through time: Efficient localization of activities in videos[C]. The 31st British Machine Vision Conference, Manchester, UK, 2020.
|
| [8] |
YUAN Yitian, MEI Tao, and ZHU Wenwu. To find where you talk: Temporal sentence localization in video with attention based location regression[C]. The 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 9159–9166.
|
| [9] |
GHOSH S, AGARWAL A, PAREKH Z, et al. ExCL: Extractive clip localization using natural language descriptions[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019: 1984–1990.
|
| [10] |
SUN Xiaoyang, WANG Hanli, and HE Bin. MABAN: Multi-agent boundary-aware network for natural language moment retrieval[J]. IEEE Transactions on Image Processing, 2021, 30: 5589–5599. doi: 10.1109/TIP.2021.3086591
|
| [11] |
RODRIGUEZ-OPAZO C, MARRESE-TAYLOR E, FERNANDO B, et al. DORi: Discovering object relationships for moment localization of a natural language query in a video[C]. 2021 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2021.
|
| [12] |
XU Huijuan, HE Kun, PLUMMER B A, et al. Multilevel language and vision integration for text-to-clip retrieval[C]. The 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 9062–9069.
|
| [13] |
TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4489–4497.
|
| [14] |
HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735
|
| [15] |
CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation[C]. 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1724–1734.
|
| [16] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010.
|
| [17] |
HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141.
|
| [18] |
WOO S, PARK J, LEE J, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19.
|
| [19] |
ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 294–310.
|
| [20] |
WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020.
|
| [21] |
WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803.
|
| [22] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778.
|
| [23] |
ZHENG Zhaohui, WANG Ping, LIU Wei, et al. Distance-IoU Loss: Faster and better learning for bounding box regression[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12993–13000.
|
| [24] |
ZHENG Zhaohui, WANG Ping, REN Dongwei, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics, 2022, 52(8): 8574–8586.
|
| [25] |
REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 658–666.
|
| [26] |
REGNERI M, ROHRBACH M, WETZEL D, et al. Grounding action descriptions in videos[J]. Transactions of the Association for Computational Linguistics, 2013, 1: 25–36. doi: 10.1162/tacl_a_00207
|
| [27] |
KRISHNA R, HATA K, REN F, et al. Dense-captioning events in videos[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 706–715.
|
| [28] |
ROHRBACH M, REGNERI M, ANDRILUKA M, et al. Script data for attribute-based recognition of composite activities[C]. The 12th European Conference on Computer Vision, Florence, Italy, 2012: 144–157.
|
| [29] |
ZHANG Da, DAI Xiyang, WANG Xin, et al. MAN: Moment alignment network for natural language moment retrieval via iterative graph adjustment[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019.
|
| [30] |
PENNINGTON J, SOCHER R, and MANNING C. GloVe: Global vectors for word representation[C]. 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1532–1543.
|
| [31] |
HU Yupeng, LIU Meng, SUN Xiaobin, et al. Video moment localization via deep cross-modal hashing[J]. IEEE Transactions on Image Processing, 2021, 30: 4667–4677. doi: 10.1109/TIP.2021.3073867
|
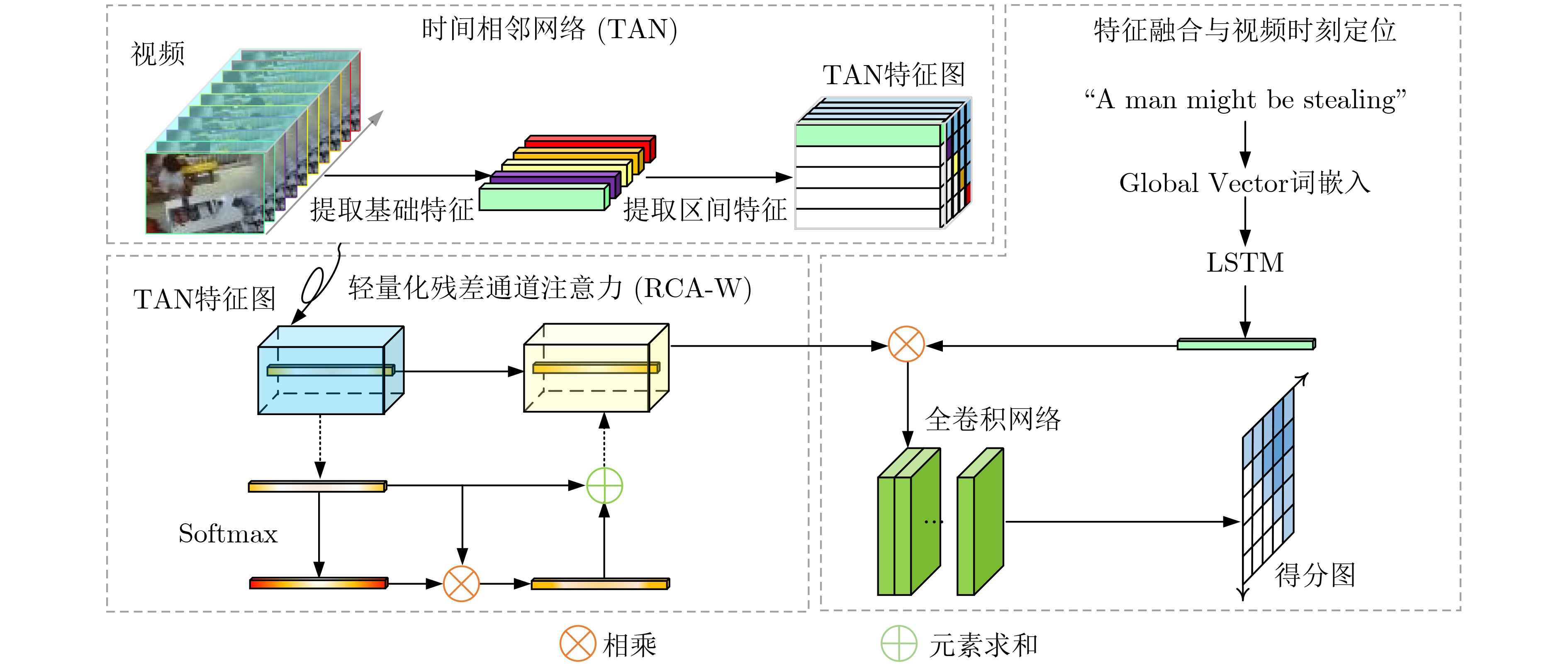
Figures(8) / Tables(5)



 DownLoad:
DownLoad: