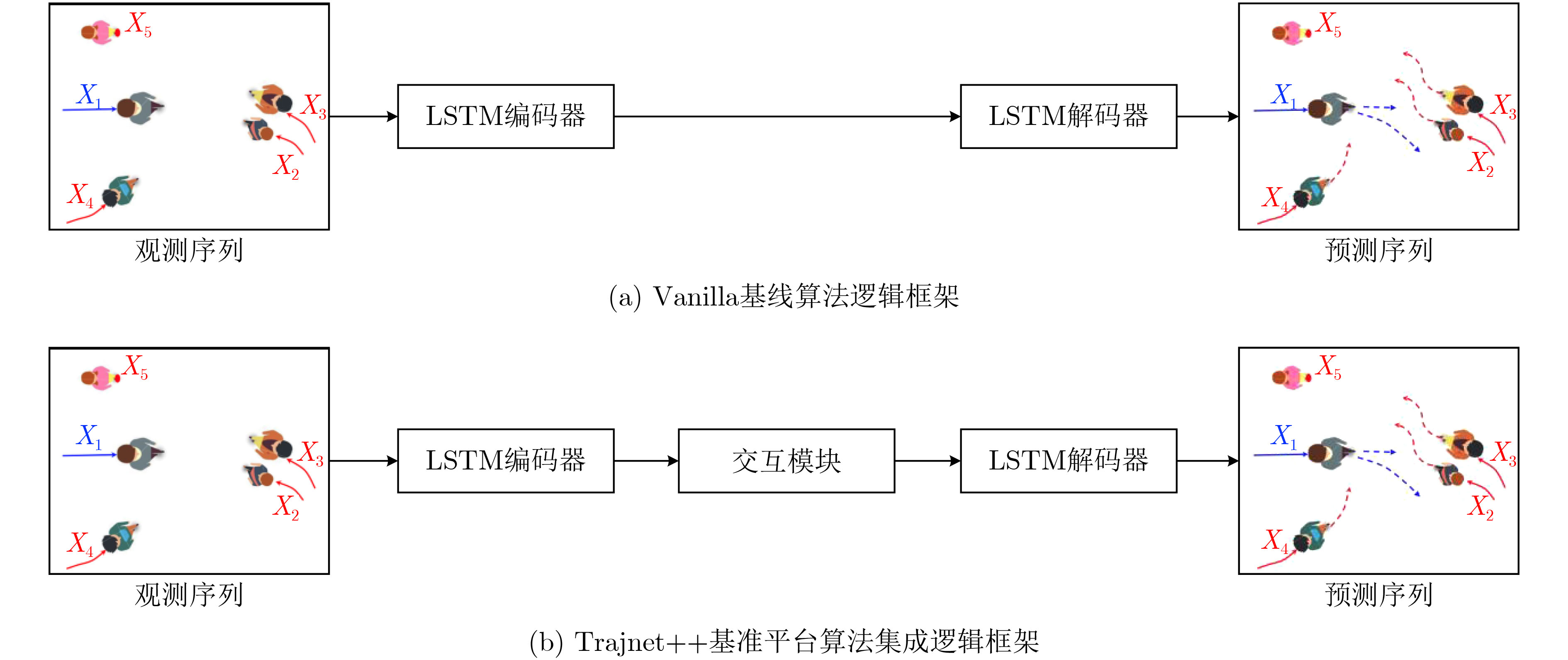
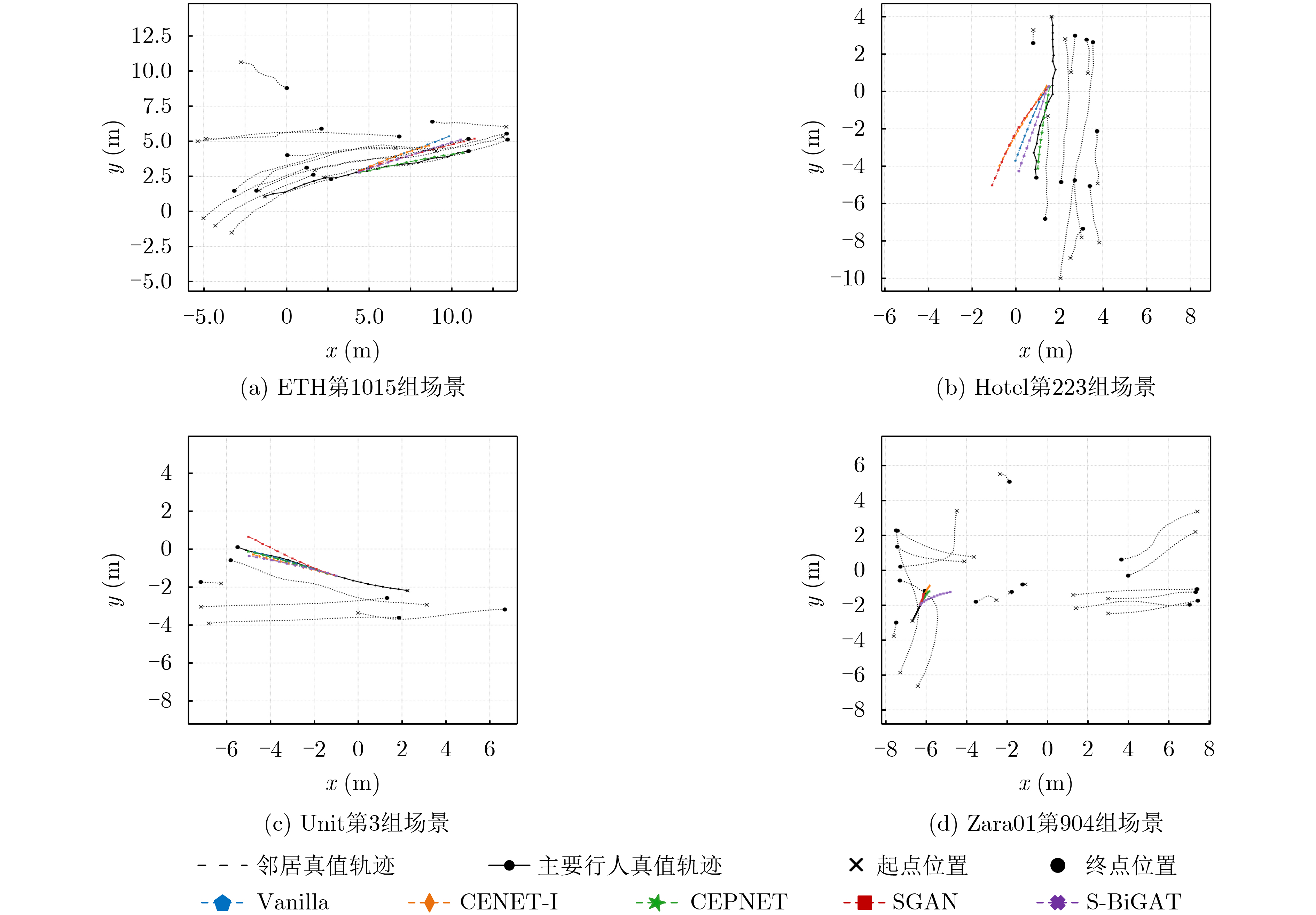
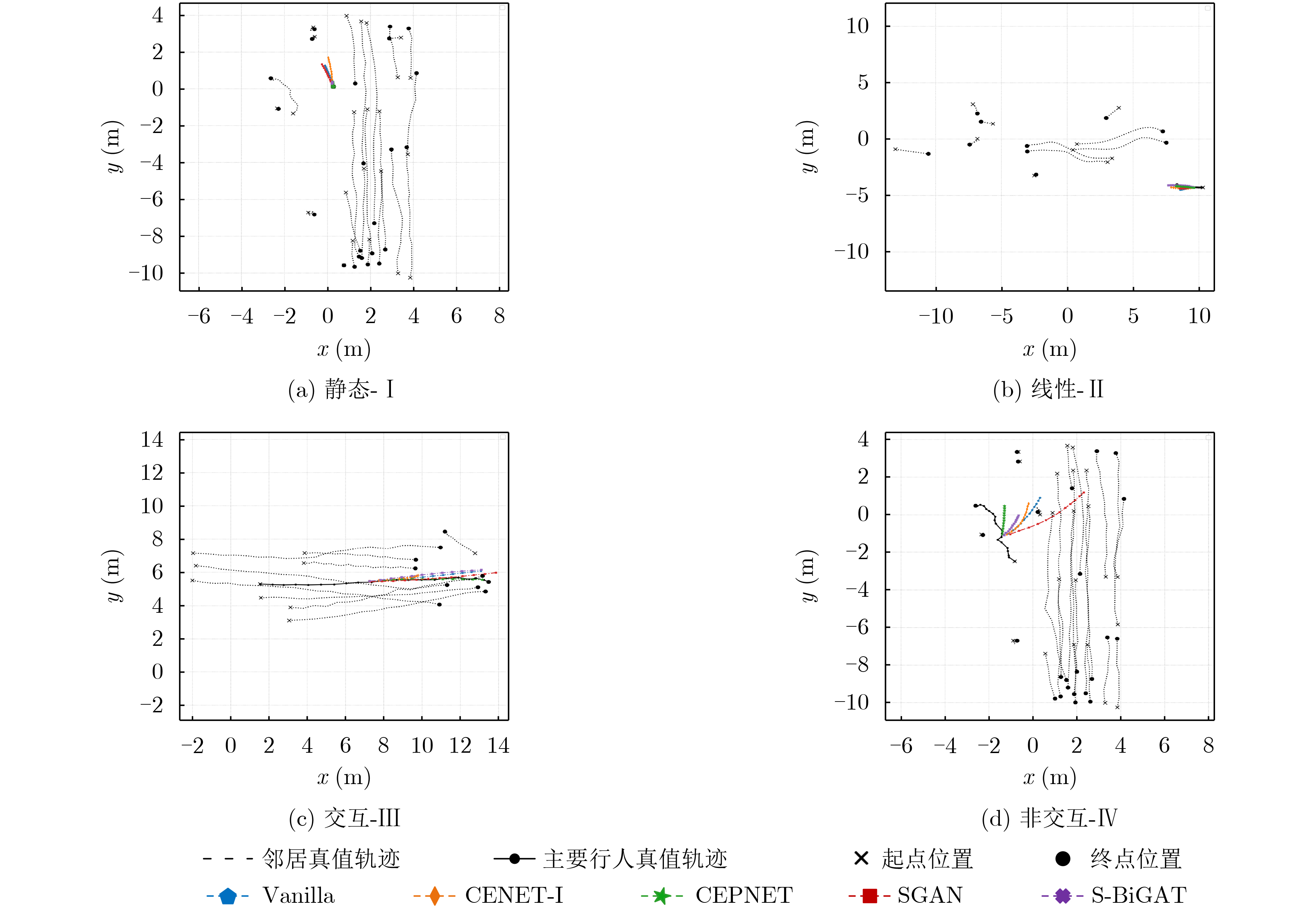
| Citation: | MAO Lin, XIE Yunjiao, YANG Dawei, ZHANG Rubo. Local Destination Pooling Network for Pedestrian Trajectory Prediction of Condition Endpoint[J]. Journal of Electronics & Information Technology, 2022, 44(10): 3465-3475. doi: 10.11999/JEIT210716

|

| [1] |
CHEN Changan, LIU Yuejiang, KREISS S, et al. Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning[C]. 2019 International Conference on Robotics and Automation (ICRA), Montreal, Canada, 2019: 6015–6022.
|
| [2] |
RASOULI A and TSOTSOS J K. Autonomous vehicles that interact with pedestrians: A survey of theory and practice[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(3): 900–918. doi: 10.1109/TITS.2019.2901817
|
| [3] |
BITGOOD S. An analysis of visitor circulation: Movement patterns and the general value principle[J]. Curator:The Museum Journal, 2006, 49(4): 463–475. doi: 10.1111/j.2151-6952.2006.tb00237.x
|
| [4] |
HORNI A, NAGEL K, and AXHAUSEN K W. The Multi-Agent Transport Simulation MATSim[M]. London: Ubiquity Press, 2016: 355–361.
|
| [5] |
DONG Hairong, ZHOU Min, WANG Qianling, et al. State-of-the-art pedestrian and evacuation dynamics[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(5): 1849–1866. doi: 10.1109/TITS.2019.2915014
|
| [6] |
ALAHI A, GOEL K, RAMANATHAN V, et al. Social LSTM: Human trajectory prediction in crowded spaces[C]. 2016 IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, USA, 2016: 961–971.
|
| [7] |
BISAGNO N, ZHANG Bo, and CONCI N. Group LSTM: Group trajectory prediction in crowded scenarios[C]. European Conference on Computer Vision, Munich, Germany, 2018: 213–225.
|
| [8] |
PELLEGRINI S, ESS A, SCHINDLER K, et al. You'll never walk alone: Modeling social behavior for multi-target tracking[C]. 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 2009: 261–268.
|
| [9] |
LERNER A, CHRYSANTHOU Y, and LISCHINSKI D. Crowds by example[J]. Computer Graphics Forum, 2007, 26(3): 655–664. doi: 10.1111/j.1467-8659.2007.01089.x
|
| [10] |
XUE Hao, HUYNH D Q, and REYNOLDS M. SS-LSTM: A hierarchical LSTM model for pedestrian trajectory prediction[C]. 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, USA, 2018: 1186–1194.
|
| [11] |
CHEUNG E, WONG T K, BERA A, et al. LCrowdV: Generating labeled videos for simulation-based crowd behavior learning[C]. European Conference on Computer Vision, Amsterdam, Netherlands, 2016: 709–727.
|
| [12] |
BARTOLI F, LISANTI G, BALLAN L, et al. Context-aware trajectory prediction[C]. 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 2018: 1941–1946.
|
| [13] |
GUPTA A, JOHNSON J, LI Feifei, et al. Social GAN: Socially acceptable trajectories with generative adversarial networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, USA, 2018: 2255–2264.
|
| [14] |
FERNANDO T, DENMAN S, SRIDHARAN S, et al. GD-GAN: Generative adversarial networks for trajectory prediction and group detection in crowds[C]. Asian Conference on Computer Vision, Perth, Australia, 2018: 314–330.
|
| [15] |
VAN DER MAATEN L. Accelerating t-SNE using tree-based algorithms[J]. The Journal of Machine Learning Research, 2014, 15(1): 3221–3245.
|
| [16] |
KOSARAJU V, SADEGHIAN A, MARTÍN-MARTÍN R, et al. Social-BiGAT: Multimodal trajectory forecasting using bicycle-GAN and graph attention networks[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 137–146.
|
| [17] |
MANGALAM K, GIRASE H, AGARWAL S, et al. It is not the journey but the destination: Endpoint conditioned trajectory prediction[C]. European Conference on Computer Vision, Glasgow, United Kingdom, 2020: 759–776.
|
| [18] |
SALZMANN T, IVANOVIC B, CHAKRAVARTY P, et al. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data[C]. European Conference on Computer Vision, Glasgow, United Kingdom, 2020: 683–700.
|
| [19] |
KOTHARI P, KREISS S, and ALAHI A. Human trajectory forecasting in crowds: A deep learning perspective[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(7): 7386–7400. doi: 10.1109/TITS.2021.3069362
|
| [20] |
LEE N, CHOI W, VERNAZA P, et al. DESIRE: Distant future prediction in dynamic scenes with interacting agents[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 336–345.
|
| [21] |
KINGMA D P and WELLING M. Auto-encoding variational Bayes[C]. International Conference on Learning Representations ICLR 2014 Conference Track (ICLR), Banff, Canada, 2014: 1–14.
|

Figures(10) / Tables(4)



 DownLoad:
DownLoad: