| Citation: | WU Guanhan, JIA Weimin, ZHAO Jianwei, GAO Feifei, YAO Minli. MARL-based Design of Multi-Unmanned Aerial Vehicle Assisted Communication System with Hybrid Gaming Mode[J]. Journal of Electronics & Information Technology, 2022, 44(3): 940-950. doi: 10.11999/JEIT210662

|

| [1] |
YOU Xiaohu, WANG Chengxiang, HUANG Jie, et al. Towards 6G wireless communication networks: Vision, enabling technologies, and new paradigm shifts[J]. Science China Information Sciences, 2021, 64(1): 110301. doi: 10.1007/s11432-020-2955-6
|
| [2] |
SEKANDER S, TABASSUM H, and HOSSAIN E. Multi-tier drone architecture for 5G/B5G cellular networks: Challenges, trends, and prospects[J]. IEEE Communications Magazine, 2018, 56(3): 96–103. doi: 10.1109/MCOM.2018.1700666
|
| [3] |
MISHRA D and NATALIZIO E. A survey on cellular-connected UAVs: Design challenges, enabling 5G/B5G innovations, and experimental advancements[J]. Computer Networks, 2020, 182: 107451. doi: 10.1016/j.comnet.2020.107451
|
| [4] |
ZHAO Jianwei, LIU Jun, JIANG Jing, et al. Efficient deployment with geometric analysis for mmWave UAV communications[J]. IEEE Wireless Communications Letters, 2020, 9(7): 1115–1119. doi: 10.1109/LWC.2020.2982637
|
| [5] |
LI Bin, FEI Zesong, and ZHANG Yan. UAV communications for 5G and beyond: Recent advances and future trends[J]. IEEE Internet of Things Journal, 2019, 6(2): 2241–2263. doi: 10.1109/JIOT.2018.2887086
|
| [6] |
赵太飞, 林亚茹, 马倩文, 等. 无人机编队中无线紫外光隐秘通信的能耗均衡算法[J]. 电子与信息学报, 2020, 42(12): 2969–2975. doi: 10.11999/JEIT190965
ZHAO Taifei, LIN Yaru, MA Qianwen, et al. Energy balance algorithm for wireless ultraviolet secret communication in UAV formation[J]. Journal of Electronics &Information Technology, 2020, 42(12): 2969–2975. doi: 10.11999/JEIT190965
|
| [7] |
WANG Yining, CHEN Mingzhe, YANG Zhaohui, et al. Deep learning for optimal deployment of UAVs with visible light communications[J]. IEEE Transactions on Wireless Communications, 2020, 19(11): 7049–7063. doi: 10.1109/TWC.2020.3007804
|
| [8] |
徐勇军, 刘子腱, 李国权, 等. 基于NOMA的无线携能D2D通信鲁棒能效优化算法[J]. 电子与信息学报, 2021, 43(5): 1289–1297. doi: 10.11999/JEIT200175
XU Yongjun, LIU Zijian, LI Guoquan, et al. Robust energy efficiency optimization algorithm for NOMA-based D2D communication with simultaneous wireless information and power transfer[J]. Journal of Electronics &Information Technology, 2021, 43(5): 1289–1297. doi: 10.11999/JEIT200175
|
| [9] |
ZHAN Cheng, ZENG Yong, and ZHANG Rui. Trajectory design for distributed estimation in UAV-enabled wireless sensor network[J]. IEEE Transactions on Vehicular Technology, 2018, 67(10): 10155–10159. doi: 10.1109/TVT.2018.2859450
|
| [10] |
SHEN Xinyue and GU Yuantao. Nonconvex sparse logistic regression with weakly convex regularization[J]. IEEE Transactions on Signal Processing, 2018, 66(12): 3199–3211. doi: 10.1109/TSP.2018.2824289
|
| [11] |
CUI Fangyu, CAI Yunlong, QIN Zhijin, et al. Multiple access for mobile-UAV enabled networks: Joint trajectory design and resource allocation[J]. IEEE Transactions on Communications, 2019, 67(7): 4980–4994. doi: 10.1109/TCOMM.2019.2910263
|
| [12] |
SAWALMEH A, OTHMAN N S, SHAKHATREH H, et al. Providing wireless coverage in massively crowded events using UAVs[C]. 2017 IEEE 13th Malaysia International Conference on Communications (MICC), Johor Bahru, Malaysia, 2017: 158–163. doi: 10.1109/MICC.2017.8311751.
|
| [13] |
SHAKHATREH H, KHREISHAH A, ALSARHAN A, et al. Efficient 3D placement of a UAV using particle swarm optimization[C]. 2017 8th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 2017: 258–263. doi: 10.1109/IACS.2017.7921981.
|
| [14] |
SAXENA V, JALDÉN J, and KLESSIG H. Optimal UAV base station trajectories using flow-level models for reinforcement learning[J]. IEEE Transactions on Cognitive Communications and Networking, 2019, 5(4): 1101–1112. doi: 10.1109/TCCN.2019.2948324
|
| [15] |
LIU Xiao, LIU Yuanwei, and CHEN Yue. Reinforcement learning in multiple-UAV networks: Deployment and movement design[J]. IEEE Transactions on Vehicular Technology, 2019, 68(8): 8036–8049. doi: 10.1109/TVT.2019.2922849
|
| [16] |
WANG Qiang, ZHANG Wenqi, LIU Yuanwei, et al. Multi-UAV dynamic wireless networking with deep reinforcement learning[J]. IEEE Communications Letters, 2019, 23(12): 2243–2246. doi: 10.1109/LCOMM.2019.2940191
|
| [17] |
CAO Yang, ZHANG Lin, and LIANG Yingchang. Deep reinforcement learning for multi-user access control in UAV networks[C]. ICC 2019 - 2019 IEEE International Conference on Communications (ICC), Shanghai, China, 2019: 1–6. doi: 10.1109/ICC.2019.8761794.
|
| [18] |
YU Chao, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative, multi-agent games[J]. arXiv preprint arXiv: 2103.01955, 2021.
|
| [19] |
CHOU P W, MATURANA D, and SCHERER S. Improving stochastic policy gradients in continuous control with deep reinforcement learning using the Beta distribution[C]. Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 2017: 834–843.
|
| [20] |
ENGSTROM L, ILYAS A, SANTURKAR S, et al. Implementation matters in deep policy gradients: A case study on PPO and TRPO[C]. International Conference on Learning Representations(ICLR), Addis Ababa, Ethiopia, 2020: 1–14.
|
| [21] |
SMITH S L, KINDERMANS P J, YING C, et al. Don’t decay the learning rate, increase the batch size[C]. International Conference on Learning Representations (ICLR), Vancouver, Canada, 2018: 1–11.
|
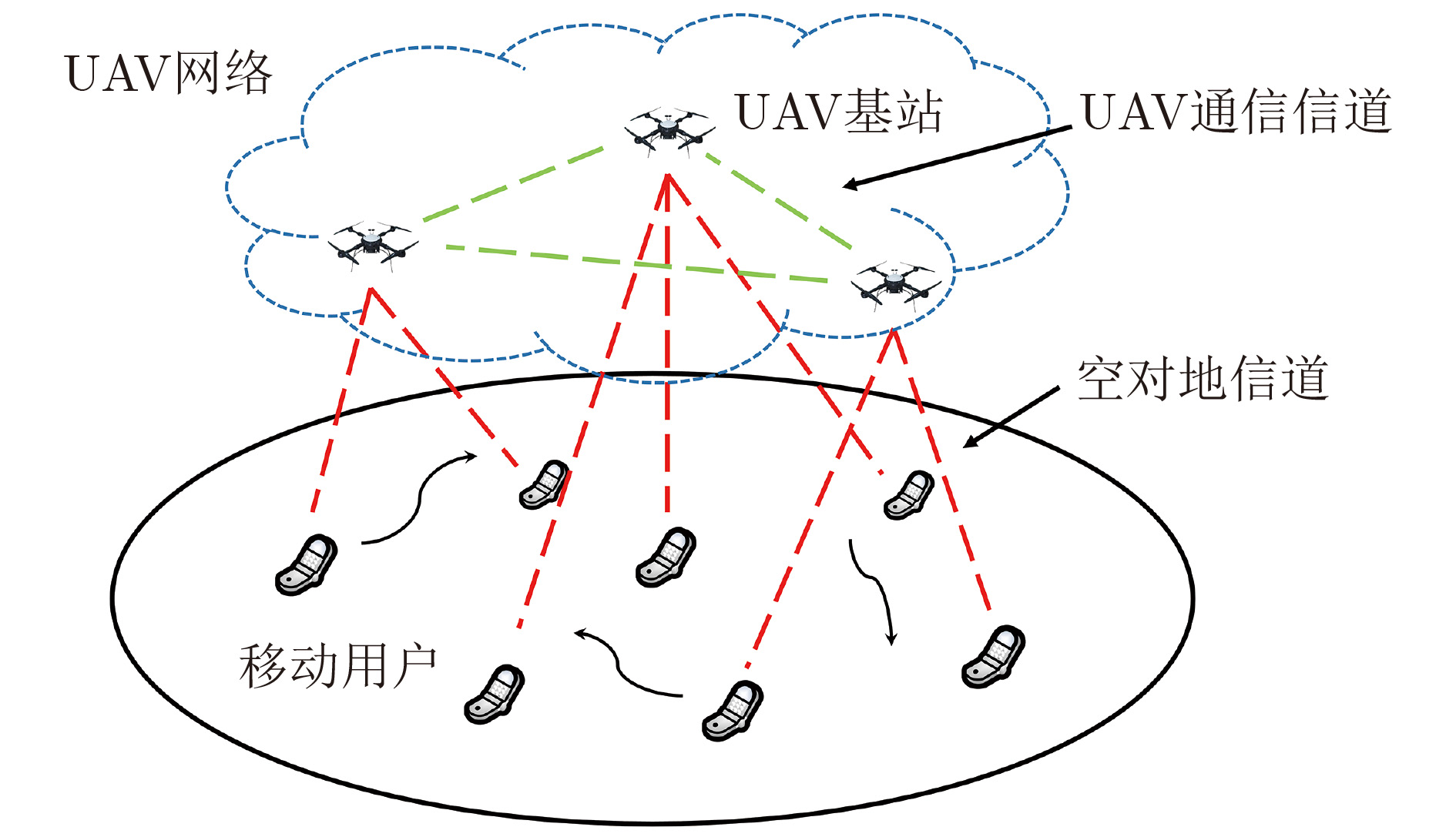
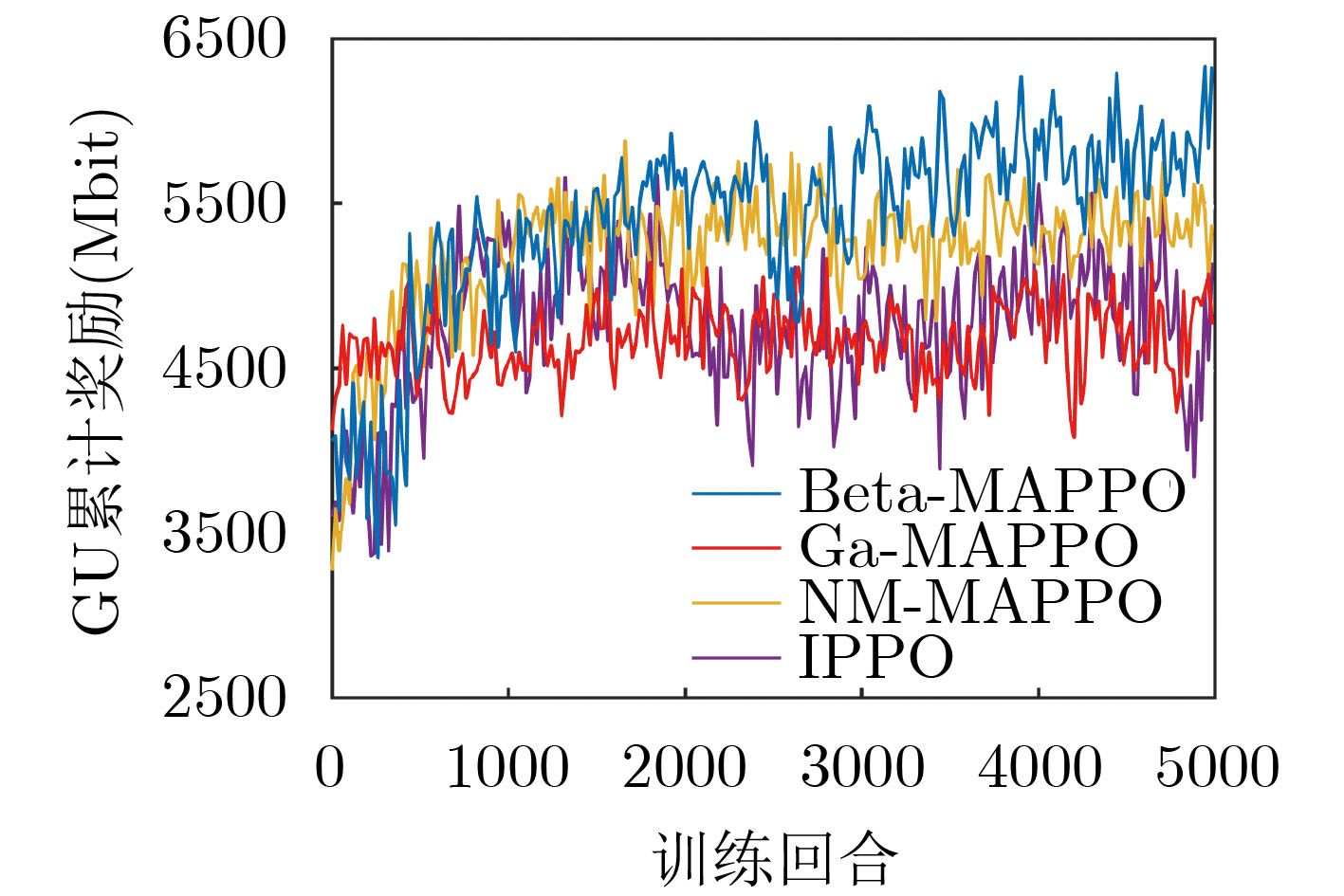
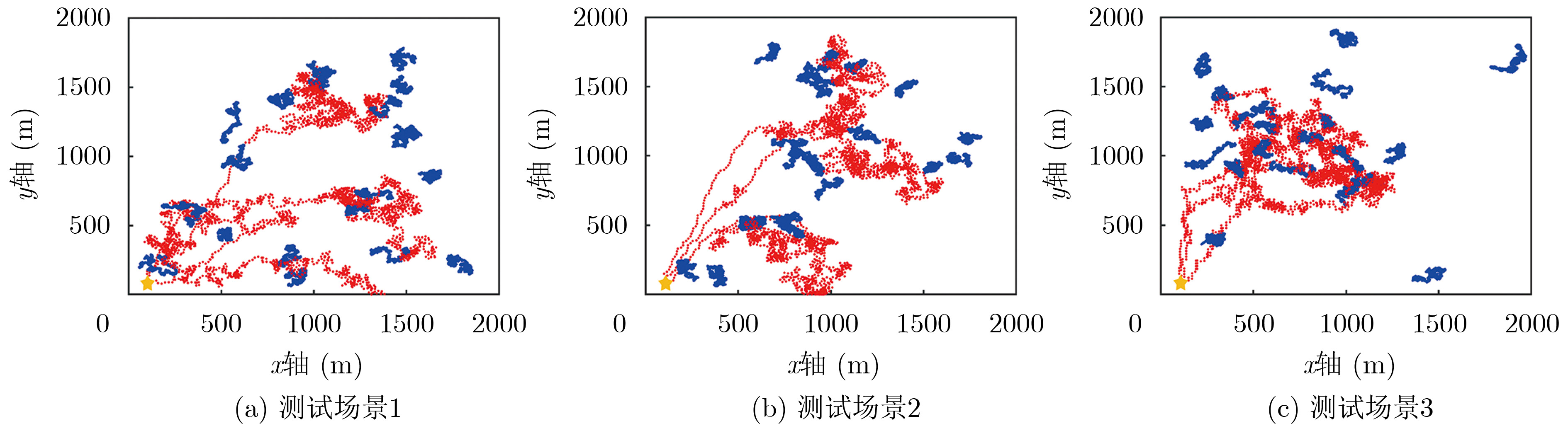
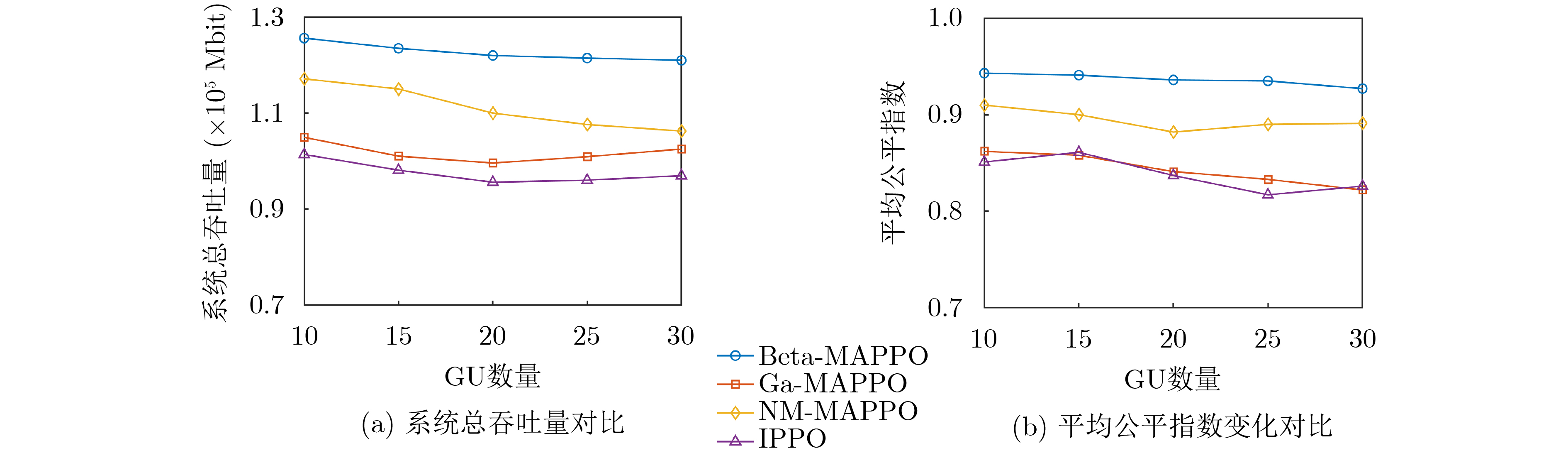
Figures(7) / Tables(2)



 DownLoad:
DownLoad: