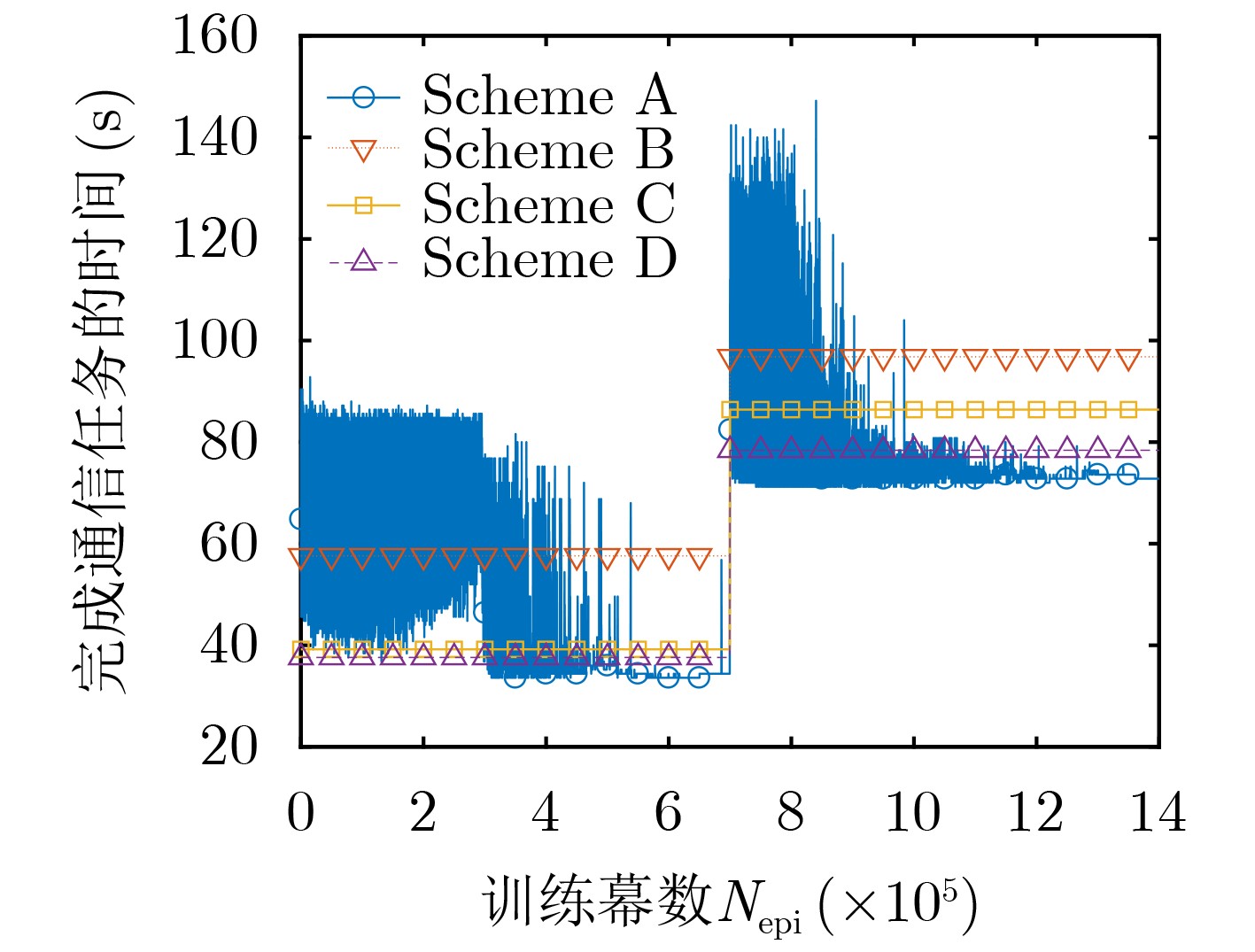
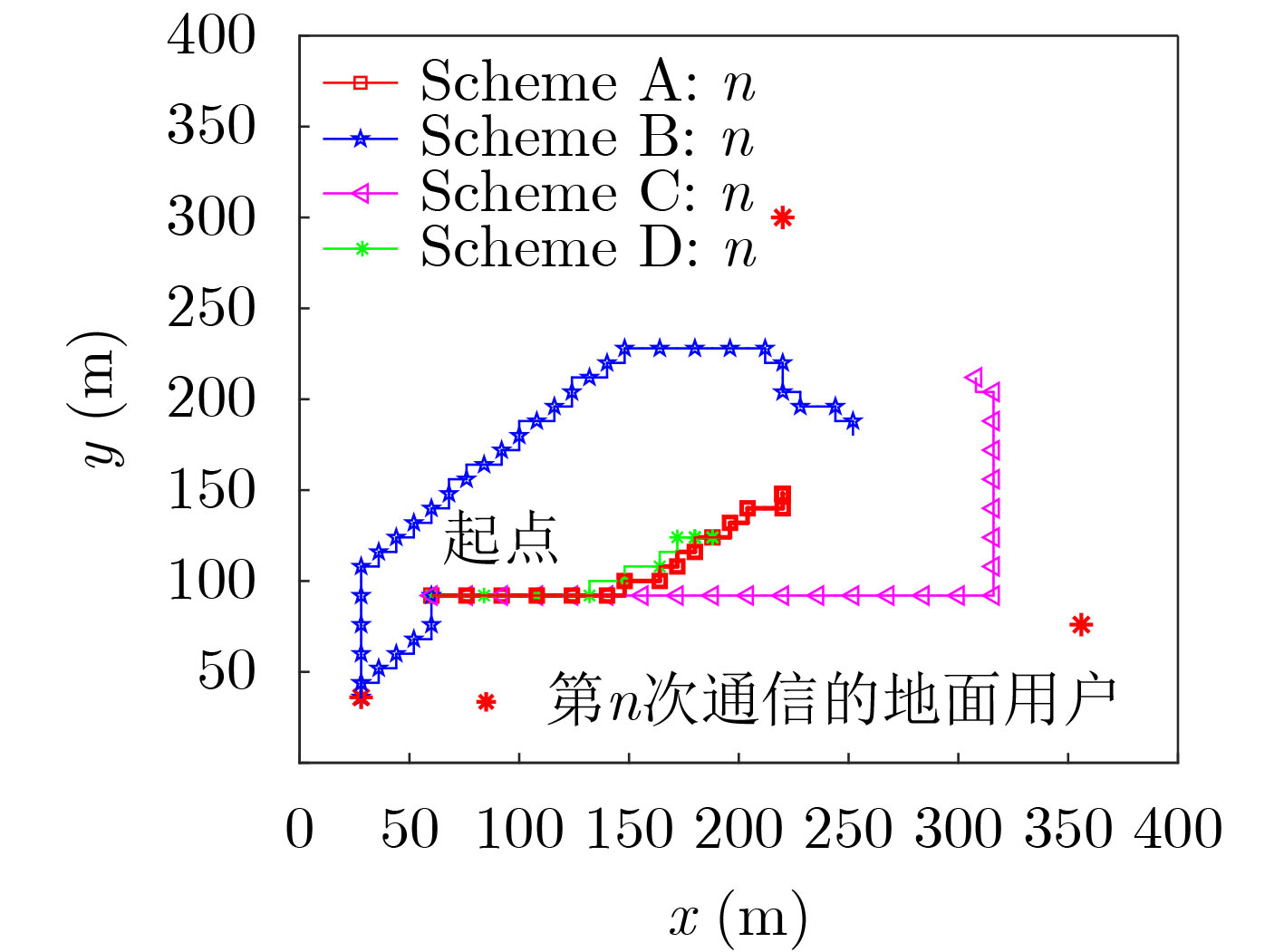
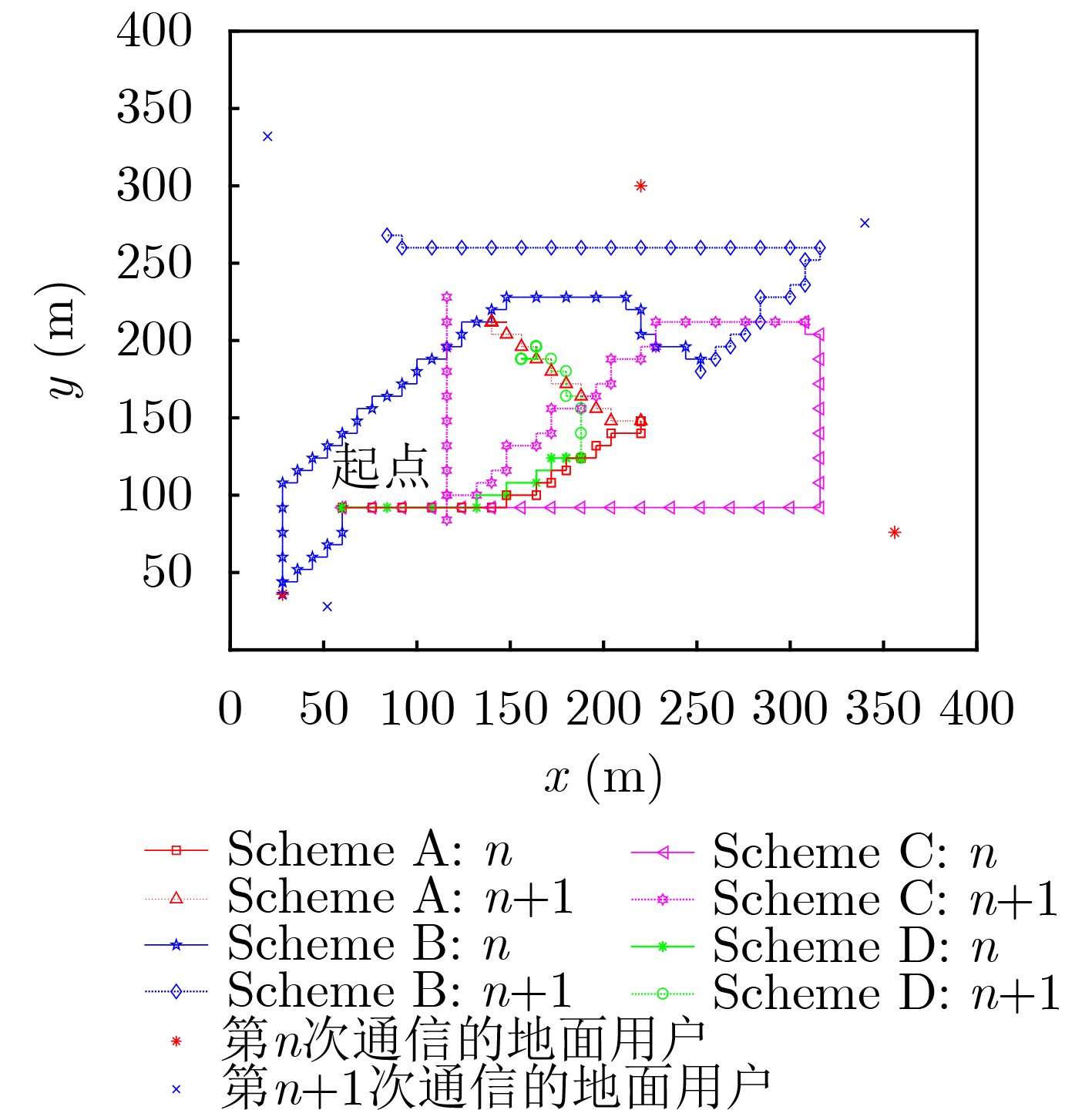
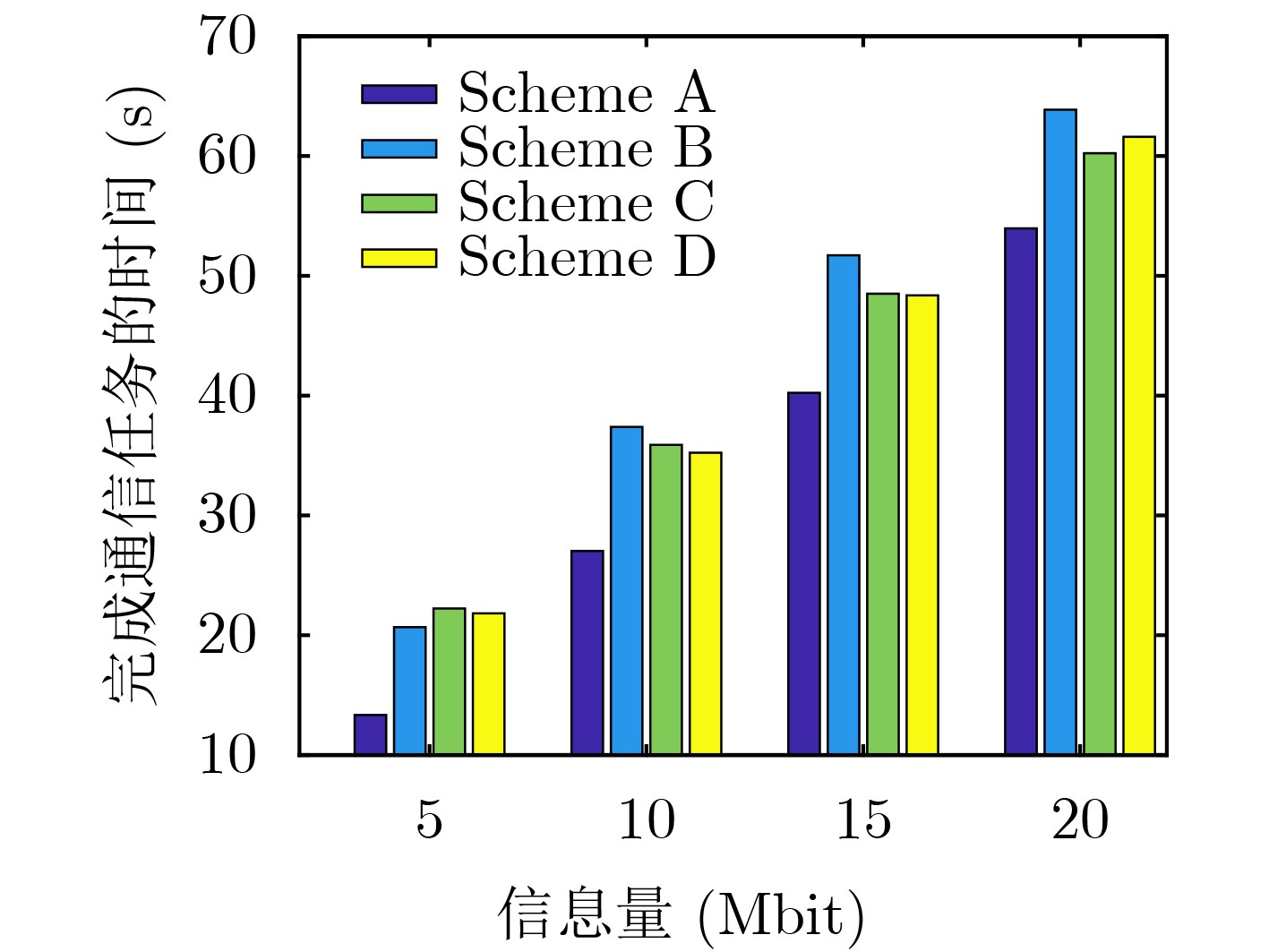
| Citation: | ZHANG Guangchi, YAN Yulin, CUI Miao, CHEN Wei, ZHANG Jing. Online Trajectory Optimization for the UAV-Enabled Base Station Multicasting System Based on Reinforcement Learning[J]. Journal of Electronics & Information Technology, 2022, 44(3): 969-975. doi: 10.11999/JEIT210429

|

| [1] |
WU Qingqing, XU Jie, ZENG Yong, et al. A comprehensive overview on 5G-and-beyond networks with UAVs: From communications to sensing and intelligence[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(10): 2912–2945. doi: 10.1109/JSAC.2021.3088681
|
| [2] |
LYU Jiangbin, ZENG Yong, and ZHANG Rui. UAV-aided offloading for cellular hotspot[J]. IEEE Transactions on Wireless Communications, 2018, 17(6): 3988–4001. doi: 10.1109/TWC.2018.2818734
|
| [3] |
FENG Wanmei, TANG Jie, ZHAO Nan, et al. NOMA-based UAV-aided networks for emergency communications[J]. China Communications, 2020, 17(11): 54–66. doi: 10.23919/JCC.2020.11.005
|
| [4] |
ZENG Yong, ZHANG Rui, and LIM T J. Throughput maximization for UAV-enabled mobile relaying systems[J]. IEEE Transactions on Communications, 2016, 64(12): 4983–4996. doi: 10.1109/TCOMM.2016.2611512
|
| [5] |
MOZAFFARI M, SAAD W, BENNIS M, et al. Mobile Unmanned Aerial Vehicles (UAVs) for energy-efficient internet of things communications[J]. IEEE Transactions on Wireless Communications, 2017, 16(11): 7574–7589. doi: 10.1109/TWC.2017.2751045
|
| [6] |
WANG Zhe, DUAN Lingjie, and ZHANG Rui. Adaptive deployment for UAV-aided communication networks[J]. IEEE Transactions on Wireless Communications, 2019, 18(9): 4531–4543. doi: 10.1109/TWC.2019.2926279
|
| [7] |
ZENG Yong, XU Jie, and ZHANG Rui. Energy minimization for wireless communication with rotary-wing UAV[J]. IEEE Transactions on Wireless Communications, 2019, 18(4): 2329–2345. doi: 10.1109/TWC.2019.2902559
|
| [8] |
WU Qingqing, ZENG Yong, and ZHANG Rui. Joint trajectory and communication design for multi-UAV enabled wireless networks[J]. IEEE Transactions on Wireless Communications, 2017, 17(3): 2109–2121. doi: 10.1109/TWC.2017.2789293
|
| [9] |
LIU Tianyu, CUI Miao, ZHANG Guangchi, et al. 3D trajectory and transmit power optimization for UAV-enabled multi-link relaying systems[J]. IEEE Transactions on Green Communications and Networking, 2021, 5(1): 392–405. doi: 10.1109/TGCN.2020.3048135
|
| [10] |
ZENG Yong and XU Xiaoli. Path design for cellular-connected UAV with reinforcement learning[C]. 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, USA, 2019: 1–6.
|
| [11] |
KHAMIDEHI B and SOUSA E S. Reinforcement learning-based trajectory design for the aerial base stations[C]. The 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkey, 2019: 1–6.
|
| [12] |
LIU Xiao, LIU Yuanwei, and CHEN Yue. Reinforcement learning in multiple-UAV networks: Deployment and movement design[J]. IEEE Transactions on Vehicular Technology, 2019, 68(8): 8036–8049. doi: 10.1109/TVT.2019.2922849
|
| [13] |
SAXENA V, JALDÉN J, and KLESSIG H. Optimal UAV base station trajectories using flow-level models for reinforcement learning[J]. IEEE Transactions on Cognitive Communications and Networking, 2019, 5(4): 1101–1112. doi: 10.1109/TCCN.2019.2948324
|
| [14] |
ZENG Yong, XU Xiaoli, and ZHANG Rui. Trajectory design for completion time minimization in UAV-enabled multicasting[J]. IEEE Transactions on Wireless Communications, 2018, 17(4): 2233–2246. doi: 10.1109/TWC.2018.2790401
|
| [15] |
GOLDSMITH A. Wireless Communications[M]. Cambridge: Cambridge University Press, 2005: 26–27.
|
| [16] |
SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 2018: 1–130.
|
| [17] |
BELLMAN R. A markovian decision process[J]. Journal of Mathematics and Mechanics, 1957, 6(5): 679–684. doi: 10.1512/iumj.1957.6.56038
|

Figures(6)



 DownLoad:
DownLoad: