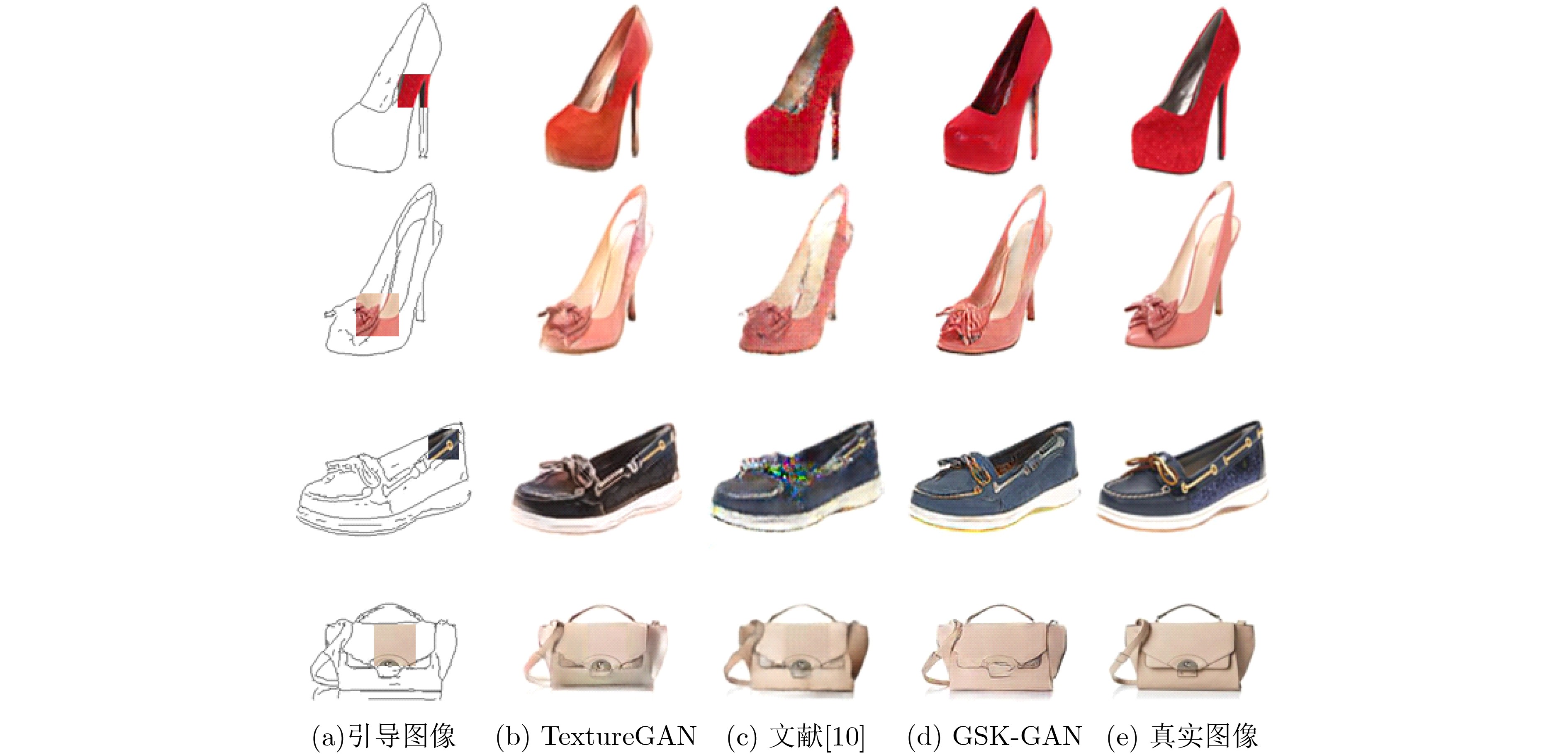
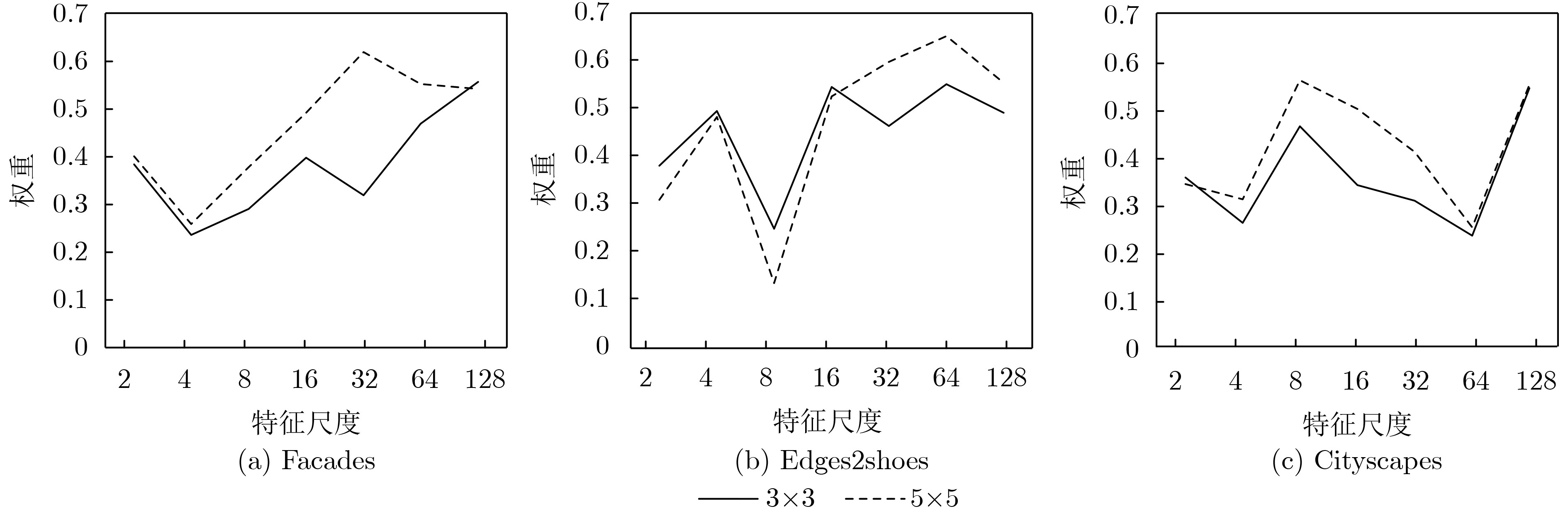
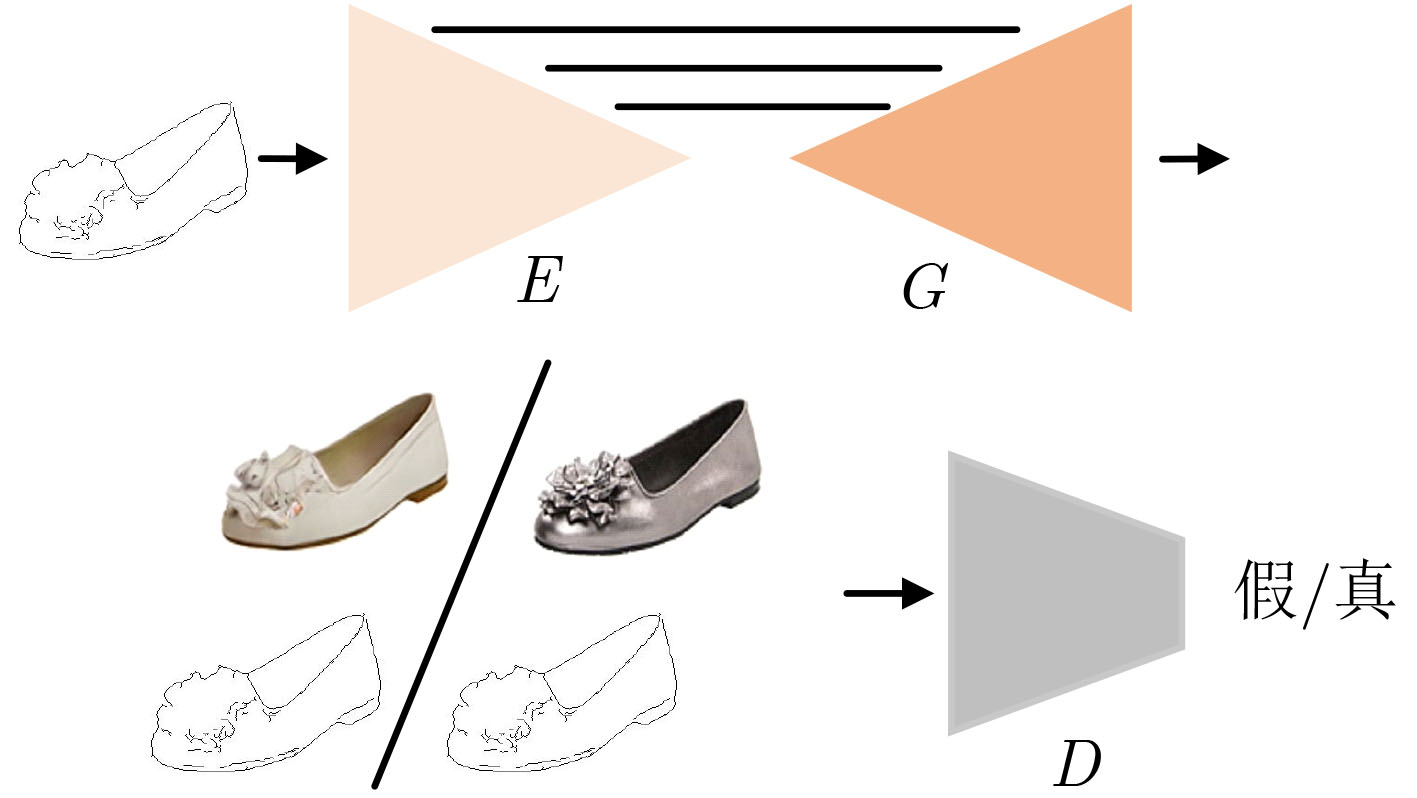
| Citation: | Mengxiao YIN, Zhenfeng LIN, Feng YANG. Adaptive Multi-scale Information Fusion Based on Dynamic Receptive Field for Image-to-image Translation[J]. Journal of Electronics & Information Technology, 2021, 43(8): 2386-2394. doi: 10.11999/JEIT200675

|

| [1] |
ISOLA P, ZHU Junyan, ZHOU Tinghui, et al. Image-to-image translation with conditional adversarial networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 5967–5976. doi: 10.1109/CVPR.2017.632.
|
| [2] |
CHEN Wengling and HAYS J. SketchyGAN: Towards diverse and realistic sketch to image synthesis[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 9416–9425. doi: 10.1109/CVPR.2018.00981.
|
| [3] |
KINGMA D P and WELLING M. Auto-encoding variational Bayes[EB/OL]. https://arxiv.org/abs/1312.6114, 2013.
|
| [4] |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680.
|
| [5] |
RADFORD A, METZ L, and CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. https://arxiv.org/abs/1511.06434, 2015.
|
| [6] |
SUNG T L and LEE H J. Image-to-image translation using identical-pair adversarial networks[J]. Applied Sciences, 2019, 9(13): 2668. doi: 10.3390/app9132668
|
| [7] |
WANG Chao, ZHENG Haiyong, YU Zhibin, et al. Discriminative region proposal adversarial networks for high-quality image-to-image translation[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 796–812. doi: 10.1007/978-3-030-01246-5_47.
|
| [8] |
ZHU Junyan, ZHANG R, PATHAK D, et al. Toward multimodal image-to-image translation[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 465–476.
|
| [9] |
XIAN Wenqi, SANGKLOY P, AGRAWAL V, et al. TextureGAN: Controlling deep image synthesis with texture patches[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8456–8465. doi: 10.1109/CVPR.2018.00882.
|
| [10] |
ALBAHAR B and HUANG Jiabin. Guided image-to-image translation with bi-directional feature transformation[C]. The 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 9015–9024. doi: 10.1109/ICCV.2019.00911.
|
| [11] |
SUN Wei and WU Tianfu. Learning spatial pyramid attentive pooling in image synthesis and image-to-image translation[EB/OL]. https://arxiv.org/abs/1901.06322, 2019.
|
| [12] |
ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 2242–2251. doi: 10.1109/ICCV.2017.244.
|
| [13] |
LI Xiang, WANG Wenhai, HU Xiaolin, et al. Selective kernel networks[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 510–519. doi: 10.1109/CVPR.2019.00060.
|
| [14] |
SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, inception-ResNet and the impact of residual connections on learning[EB/OL]. https://arxiv.org/abs/1602.07261, 2016.
|
| [15] |
柳长源, 王琪, 毕晓君. 基于多通道多尺度卷积神经网络的单幅图像去雨方法[J]. 电子与信息学报, 2020, 42(9): 2285–2292. doi: 10.11999/JEIT190755
LIU Changyuan, WANG Qi, and BI Xiaojun. Research on Rain Removal Method for Single Image Based on Multi-channel and Multi-scale CNN[J]. Journal of Electronics &Information Technology, 2020, 42(9): 2285–2292. doi: 10.11999/JEIT190755
|
| [16] |
LI Juncheng, FANG Faming, MEI Kangfu, et al. Multi-scale residual network for image super-resolution[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 527–542. doi: 10.1007/978-3-030-01237-3_32.
|
| [17] |
MAO Xudong, LI Qing, XIE Haoran, et al. Least squares generative adversarial networks[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 2813–2821. doi: 10.1109/ICCV.2017.304.
|
| [18] |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6629–6640.
|
| [19] |
ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 586–595. doi: 10.1109/CVPR.2018.00068.
|
| [20] |
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 3213–3223. doi: 10.1109/CVPR.2016.350.
|
| [21] |
TYLEČEK R and ŠÁRA R. Spatial pattern templates for recognition of objects with regular structure[C]. The 35th German Conference on Pattern Recognition, Saarbrücken, Germany, 2013: 364–374. doi: 10.1007/978-3-642-40602-7_39.
|
| [22] |
CHEN Qifeng and KOLTUN V. Photographic image synthesis with cascaded refinement networks[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 1520–1529. doi: 10.1109/ICCV.2017.168.
|
Figures(13) / Tables(5)



 DownLoad:
DownLoad: