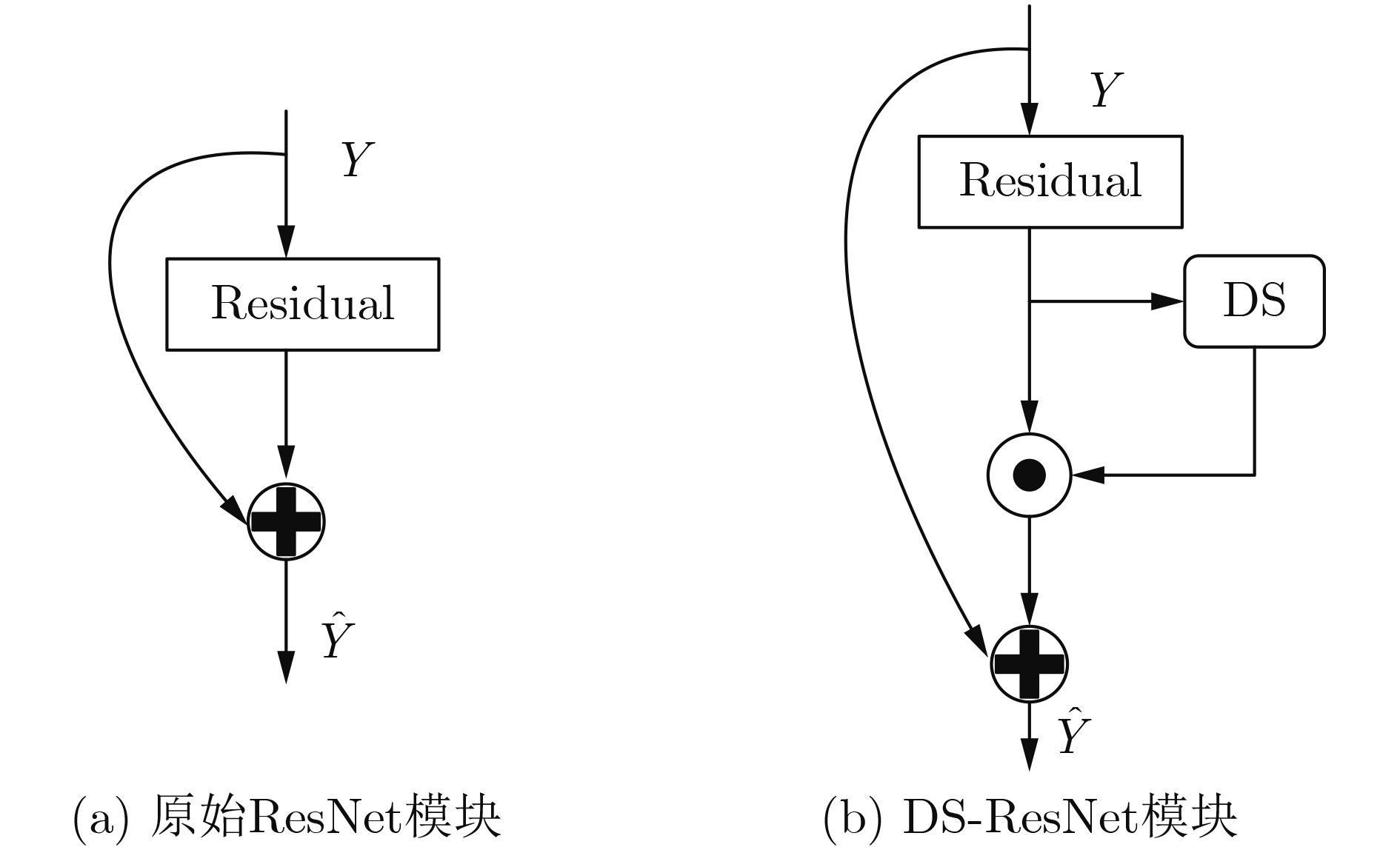
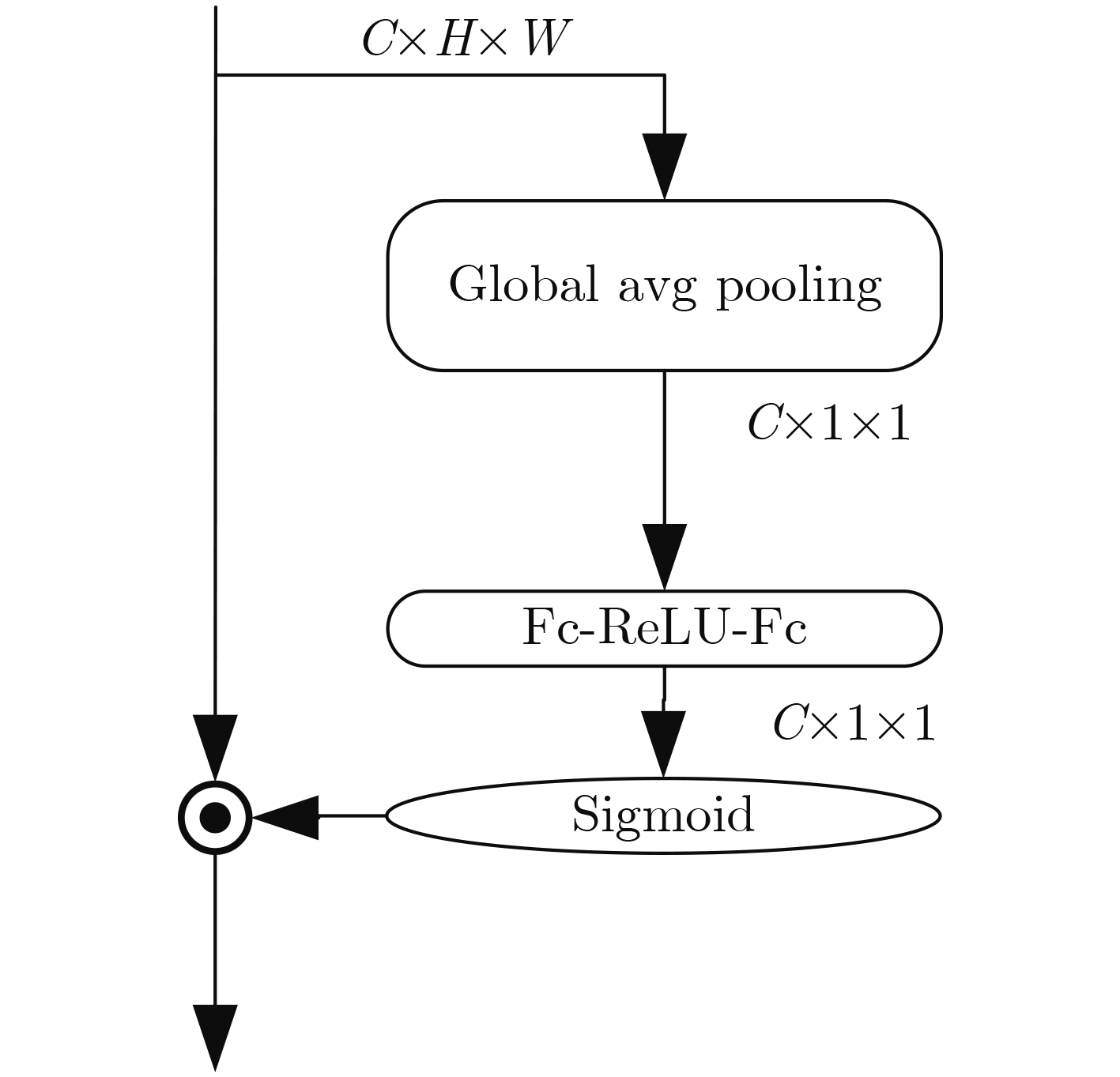
| Citation: | Ying CHEN, Suming GONG. Human Action Recognition Network Based on Improved Channel Attention Mechanism[J]. Journal of Electronics & Information Technology, 2021, 43(12): 3538-3545. doi: 10.11999/JEIT200431

|

| [1] |
IKIZLER-CINBIS N and SCLAROFF S. Object, scene and actions: Combining multiple features for human action recognition[C]. The 11th European Conference on Computer Vision, Heraklion, Greece, 2010: 494–507.
|
| [2] |
张良, 鲁梦梦, 姜华. 局部分布信息增强的视觉单词描述与动作识别[J]. 电子与信息学报, 2016, 38(3): 549–556. doi: 10.11999/JEIT150410
ZHANG Liang, LU Mengmeng, and JIANG Hua. An improved scheme of visual words description and action recognition using local enhanced distribution information[J]. Journal of Electronics &Information Technology, 2016, 38(3): 549–556. doi: 10.11999/JEIT150410
|
| [3] |
KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Colombus, USA, 2014: 1725–1732.
|
| [4] |
SIMONYAN K and ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]. The 27th International Conference on Neural Information Processing Systems - Volume 1, Montreal, Canada, 2014: 568–576.
|
| [5] |
WANG Limin, XIONG Yuanjun, WANG Zhe, et al. Temporal segment networks: Towards good practices for deep action recognition[C]. The 14th European Conference, Amsterdam, The Kingdom of the Netherlands, 2016: 20–36.
|
| [6] |
JI Shuiwang, XU Wei, YANG Ming, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221–231. doi: 10.1109/TPAMI.2012.59
|
| [7] |
ZHU Yi, LAN Zhenzhong, NEWSAM S, et al. Hidden two-stream convolutional networks for action recognition[C]. The 14th Asian Conference on Computer Vision, Perth, Australia, 2018: 363–378.
|
| [8] |
SHARMA S, KIROS R, and SALAKHUTDINOV R. Action recognition using visual attention[C]. The International Conference on Learning Representations 2016, San Juan, The Commonwealth of Puerto Rico, 2016: 1–11.
|
| [9] |
胡正平, 刁鹏成, 张瑞雪, 等. 3D多支路聚合轻量网络视频行为识别算法研究[J]. 电子学报, 2020, 48(7): 1261–1268. doi: 10.3969/j.issn.0372-2112.2020.07.003
HU Zhengping, DIAO Pengcheng, ZHANG Ruixue, et al. Research on 3D multi-branch aggregated lightweight network video action recognition algorithm[J]. Acta Electronica Sinica, 2020, 48(7): 1261–1268. doi: 10.3969/j.issn.0372-2112.2020.07.003
|
| [10] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 770–778.
|
| [11] |
HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141.
|
| [12] |
IOFFE S and SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[EB/OL]. https://arxiv.org/abs/1502.03167v2, 2015.
|
| [13] |
WU Yuxin and HE Kaiming. Group normalization[C]. The European Conference on Computer Vision, Amsterdam, The Kingdom of the Netherlands, 2018: 3–19.
|
| [14] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 2999–3007.
|
| [15] |
周波, 李俊峰. 结合目标检测的人体行为识别[J]. 自动化学报, 2020, 46(9): 1961–1970.
ZHOU Bo and LI Junfeng. Human action recognition combined with object detection[J]. Acta Automatica Sinica, 2020, 46(9): 1961–1970.
|
| [16] |
ZHOU Yizhou, SUN Xiaoyan, ZHA Zhengjun, et al. MiCT: Mixed 3D/2D convolutional tube for human action recognition[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 449–458.
|
| [17] |
QIU Zhaofan, YAO Ting, and MEI Tao. Learning spatio-temporal representation with pseudo-3D residual networks[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 5534–5542.
|
| [18] |
CARREIRA J and ZISSERMAN A. Quo vadis, action recognition? A new model and the kinetics dataset[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 4724–4733.
|
| [19] |
MA C Y, CHEN M H, KIRA Z, et al. TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition[J]. Signal Processing: Image Communication, 2019, 71: 76–87. doi: 10.1016/j.image.2018.09.003
|
| [20] |
DIBA A, SHARMA V, and VAN GOOL L. Deep temporal linear encoding networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 1541–1550.
|
| [21] |
TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]. 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2015: 4489–4497.
|
| [22] |
VAROL G, LAPTEV I, and SCHMID C. Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510–1517. doi: 10.1109/TPAMI.2017.2712608
|
| [23] |
ZHU Jiagang, ZHU Zheng, and ZOU Wei. End-to-end video-level representation learning for action recognition[C]. 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 2018: 645–650.
|
| [24] |
DIBA A, FAYYAZ M, SHARMA V, et al. Temporal 3D convnets: New architecture and transfer learning for video classification[EB/OL]. https://arxiv.org/abs/1711.08200v1, 2017.
|
| [25] |
LIN Ji, GAN Chuang, and HAN Song. TSM: Temporal shift module for efficient video understanding[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea(south), 2019: 7082–7092.
|
Figures(6) / Tables(5)



 DownLoad:
DownLoad: