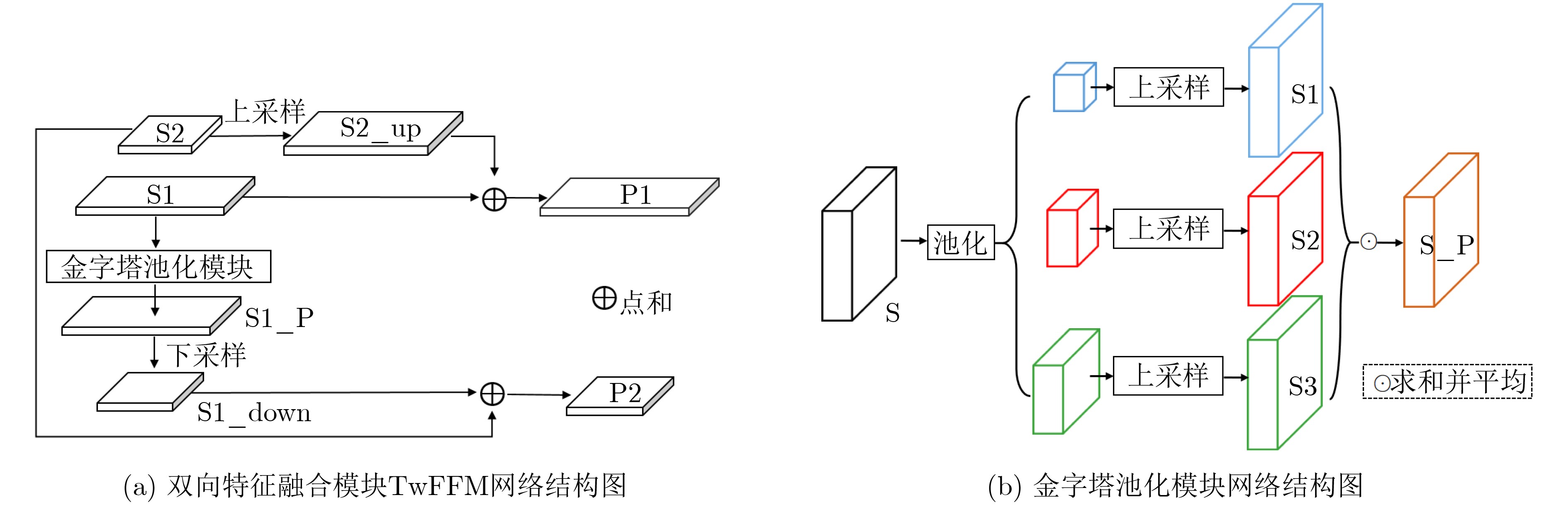
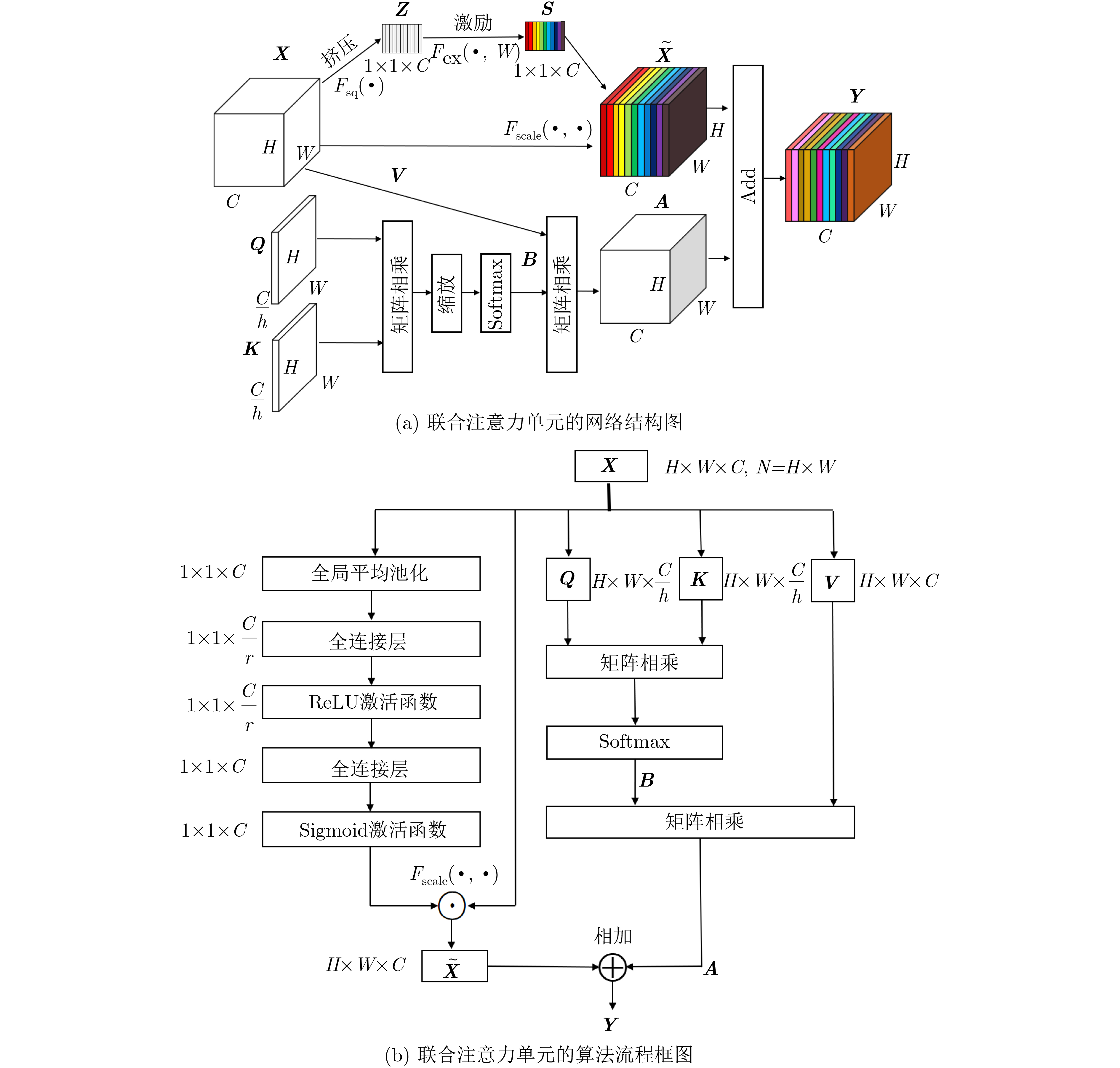
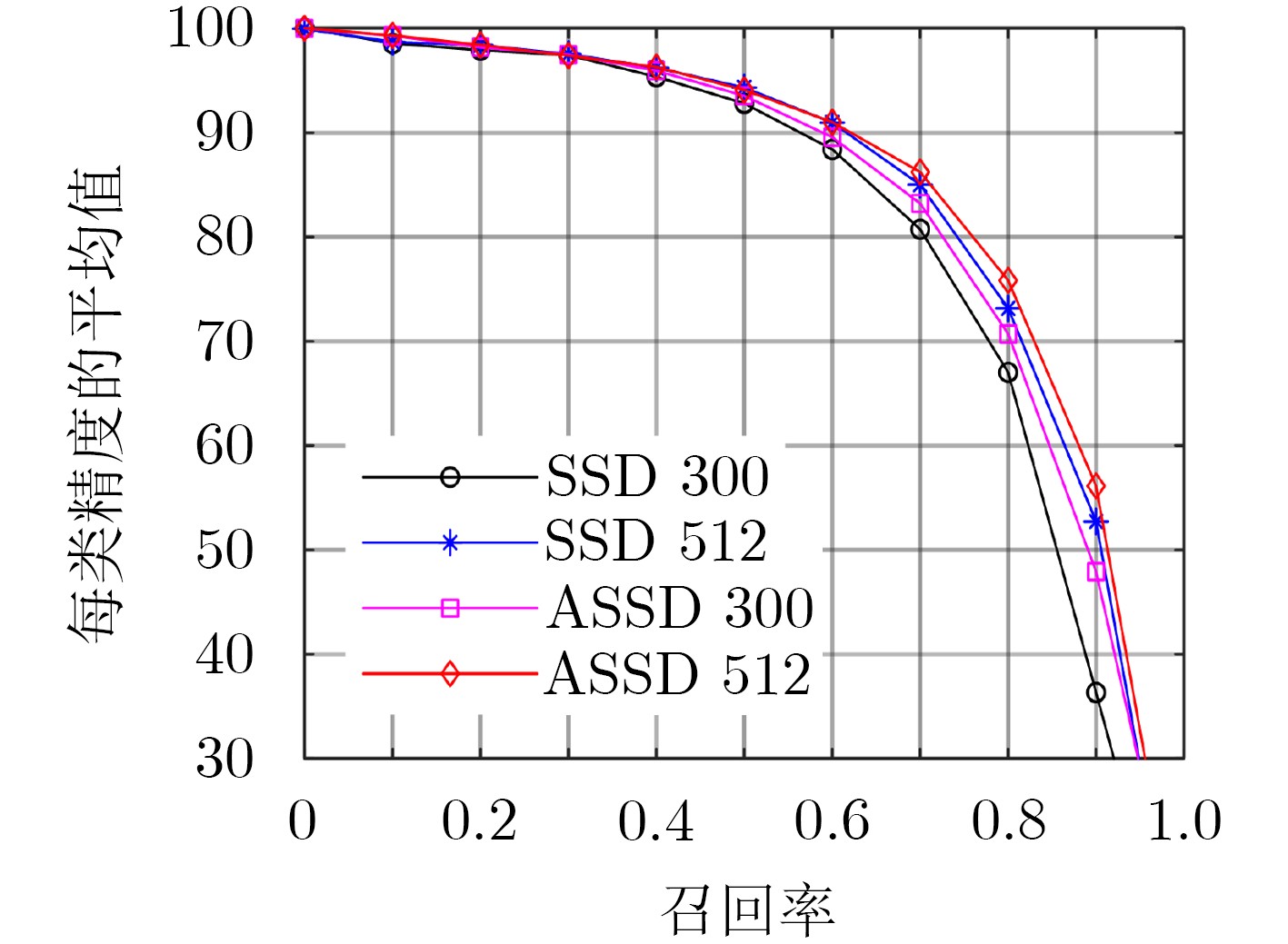
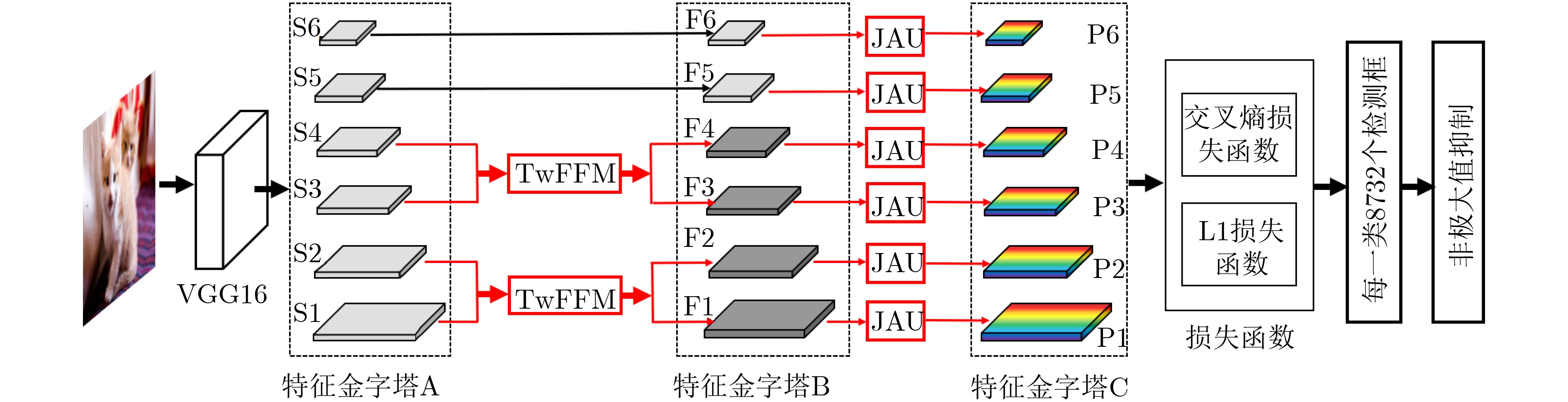
| Citation: | Hui ZHAO, Zhiwei LI, Tianqi ZHANG. Attention Based Single Shot Multibox Detector[J]. Journal of Electronics & Information Technology, 2021, 43(7): 2096-2104. doi: 10.11999/JEIT200304

|

| [1] |
赵凤, 孙文静, 刘汉强, 等. 基于近邻搜索花授粉优化的直觉模糊聚类图像分割[J]. 电子与信息学报, 2020, 42(4): 1005–1012. doi: 10.11999/JEIT190428
ZHAO Feng, SUN Wenjing, LIU Hanqiang, et al. Intuitionistic fuzzy clustering image segmentation based on flower pollination optimization with nearest neighbor searching[J]. Journal of Electronics &Information Technology, 2020, 42(4): 1005–1012. doi: 10.11999/JEIT190428
|
| [2] |
孙彦景, 石韫开, 云霄, 等. 基于多层卷积特征的自适应决策融合目标跟踪算法[J]. 电子与信息学报, 2019, 41(10): 2464–2470. doi: 10.11999/JEIT180971
SUN Yanjing, SHI Yunkai, YUN Xiao, et al. Adaptive strategy fusion target tracking based on multi-layer convolutional features[J]. Journal of Electronics &Information Technology, 2019, 41(10): 2464–2470. doi: 10.11999/JEIT180971
|
| [3] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81.
|
| [4] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824
|
| [5] |
GIRSHICK R. Fast R-CNN[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1440–1448. doi: 10.1109/ICCV.2015.169.
|
| [6] |
SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large scale image recognition[C]. Proceedings of the 3rd International Conference on Learning Representations, San Diego, USA, 2015.
|
| [7] |
REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031
|
| [8] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91.
|
| [9] |
LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2.
|
| [10] |
SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. doi: 10.1109/CVPR.2015.7298594.
|
| [11] |
REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7263–7271. doi: 10.1109/CVPR.2017.690.
|
| [12] |
ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 818–833. doi: 10.1007/978-3-319-10590-1_53.
|
| [13] |
CHEN Chenyi, LIU Mingyu, TUZEL O, et al. R-CNN for small object detection[C]. Proceedings of the 13th Asian Conference on Computer Vision, Taipei, China, 2016: 214–230. doi: 10.1007/978-3-319-54193-8_14.
|
| [14] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.
|
| [15] |
HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4700–4708. doi: 10.1109/CVPR.2017.243.
|
| [16] |
FU Chengyang, LIU Wei, RANGA A, et al. DSSD: Deconvolutional single shot detector[J]. arXiv: 1701.06659, 2017.
|
| [17] |
SHEN Zhiqiang, LIU Zhuang, LI Jianguo, et al. Dsod: Learning deeply supervised object detectors from scratch[C]. Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1919–1927. doi: 10.1109/ICCV.2017.212.
|
| [18] |
ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 818–833.
|
| [19] |
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2117–2125. doi: 10.1109/CVPR.2017.106.
|
| [20] |
JEONG J, PARK H, and KWAK N. Enhancement of SSD by concatenating feature maps for object detection[C]. Proceedings of 2017 British Machine Vision Conference, London, UK, 2017.
|
| [21] |
LI Zuoxin and ZHOU Fuqiang. FSSD: Feature fusion single shot Multibox detector[J]. arXiv: 1712.00960, 2017.
|
| [22] |
MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2204–2212.
|
| [23] |
BAHDANAU D, CHO K, BENGIO Y, et al. Neural machine translation by jointly learning to align and translate[C]. Proceedings of the 3rd International Conference on Learning Representations, San Diego, USA, 2015.
|
| [24] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5998–6008.
|
| [25] |
HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. doi: 10.1109/CVPR.2018.00745.
|
| [26] |
EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4
|
Figures(5) / Tables(3)



 DownLoad:
DownLoad: