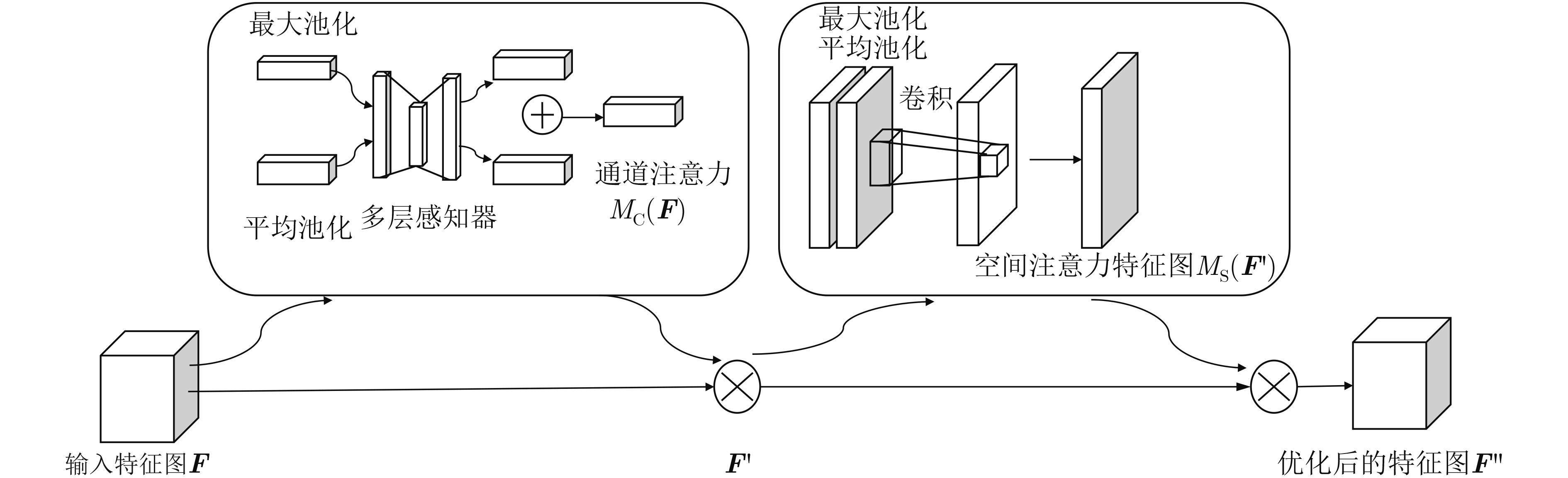
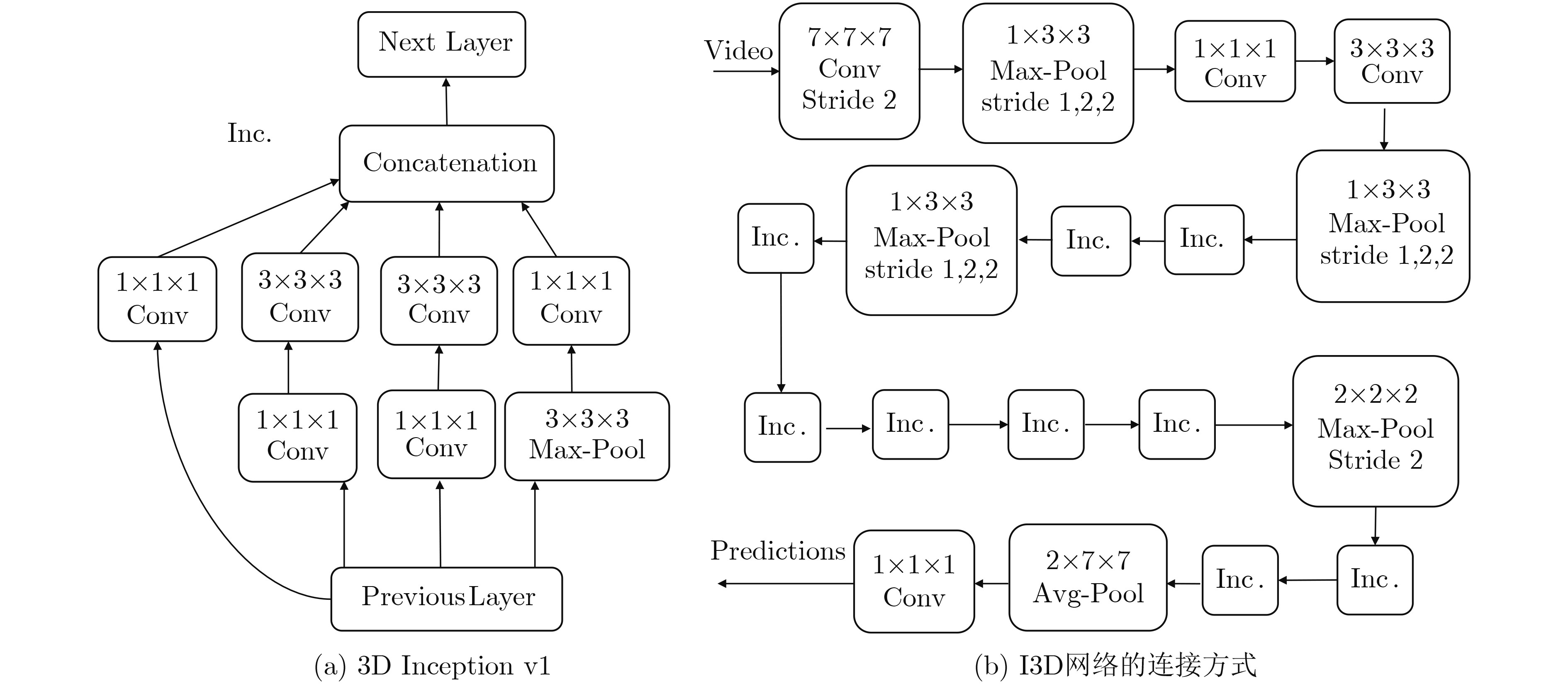
| Citation: | Fenhua WANG, Qiang ZHANG, Chao HUANG, Ran ZHANG. Dynamic Gesture Recognition Combining Two-stream 3D Convolution with Attention Mechanisms[J]. Journal of Electronics & Information Technology, 2021, 43(5): 1389-1396. doi: 10.11999/JEIT200065

|

| [1] |
TAKAHASHI T and KISHINO F. A hand gesture recognition method and its application[J]. Systems and Computers in Japan, 1992, 23(3): 38–48. doi: 10.1002/scj.4690230304
|
| [2] |
BANSAL B. Gesture recognition: A survey[J]. International Journal of Computer Applications, 2016, 139(2): 8–10. doi: 10.5120/ijca2016909103
|
| [3] |
张淑军, 张群, 李辉. 基于深度学习的手语识别综述[J]. 电子与信息学报, 2020, 42(4): 1021–1032. doi: 10.11999/JEIT190416
ZHANG Shujun, ZHANG Qun, and LI Hui. Review of sign language recognition based on deep learning[J]. Journal of Electronics &Information Technology, 2020, 42(4): 1021–1032. doi: 10.11999/JEIT190416
|
| [4] |
PARCHETA Z and MARTÍNEZ-HINAREJOS C D. Sign language gesture recognition using hmm[C]. The 8th Iberian Conference on Pattern Recognition and Image Analysis, Faro, Portugal, 2017: 419–426. doi: 10.1007/978-3-319-58838-4_46.
|
| [5] |
PU Junfu, ZHOU Wengang, ZHANG Jihai, et al. Sign language recognition based on trajectory modeling with HMMs[C]. The 22nd International Conference on Multimedia Modeling, Miami, USA, 2016: 686–697. doi: 10.1007/978-3-319-27671-7_58.
|
| [6] |
SAMANTA O, ROY A, PARUI S K, et al. An HMM framework based on spherical-linear features for online cursive handwriting recognition[J]. Information Sciences, 2018, 441: 133–151. doi: 10.1016/j.ins.2018.02.004
|
| [7] |
MASOOD S, SRIVASTAVA A, THUWAL H C, et al. Real-time sign language gesture (word) recognition from video sequences using CNN and RNN[M]. BHATEJA V, COELLO C A C, SATAPATHY S C, et al. Intelligent Engineering Informatics. Singapore: Springer, 2018: 623–632. doi: 10.1007/978-981-10-7566-7_63.
|
| [8] |
DONAHUE J, JIA Yangqing, VINYALS O, et al. DeCAF: A deep convolutional activation feature for generic visual recognition[C]. The 31st International Conference on International Conference on Machine Learning, Beijing, China, 2014: I-647–I-655.
|
| [9] |
TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3d convolutional networks[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4489–4497. doi: 10.1109/ICCV.2015.510.
|
| [10] |
CHEN Yunpeng, KALANTIDIS Y, LI Jianshu, et al. Multi-fiber networks for video recognition[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 364–380.
|
| [11] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.
|
| [12] |
HUANG Jie, ZHOU Wengang, LI Houqiang, et al. Sign language recognition using 3D convolutional neural networks[C]. 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 2015: 1–6. doi: 10.1109/ICME.2015.7177428.
|
| [13] |
SIMONYAN K and ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 568–576.
|
| [14] |
BAKER S, SCHARSTEIN D, LEWIS J P, et al. A database and evaluation methodology for optical flow[J]. International Journal of Computer Vision, 2011, 92(1): 1–31. doi: 10.1007/s11263-010-0390-2
|
| [15] |
CAO Zhe, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1302–1310. doi: 10.1109/CVPR.2017.143.
|
| [16] |
CARREIRA J and ZISSERMAN A. Quo Vadis, action recognition? A new model and the kinetics dataset[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4724–4733. doi: 10.1109/CVPR.2017.502.
|
| [17] |
WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19.
|
| [18] |
HUANG Jie, ZHOU Wengang, ZHANG Qilin, et al. Video-based sign language recognition without temporal segmentation[C]. The 32nd AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, USA, 2018: 2257–2264.
|
| [19] |
HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2011–2023. doi: 10.1109/CVPR.2018.00745.
|
| [20] |
IOFFE S and SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]. The 32nd International Conference on Machine Learning, Lille, France, 2015: 448–456.
|
| [21] |
刘天亮, 谯庆伟, 万俊伟, 等. 融合空间-时间双网络流和视觉注意的人体行为识别[J]. 电子与信息学报, 2018, 40(10): 2395–2401. doi: 10.11999/JEIT171116
LIU Tianliang, QIAO Qingwei, WAN Junwei, et al. Human action recognition via spatio-temporal dual network flow and visual attention fusion[J]. Journal of Electronics &Information Technology, 2018, 40(10): 2395–2401. doi: 10.11999/JEIT171116
|
Figures(5) / Tables(1)



 DownLoad:
DownLoad: