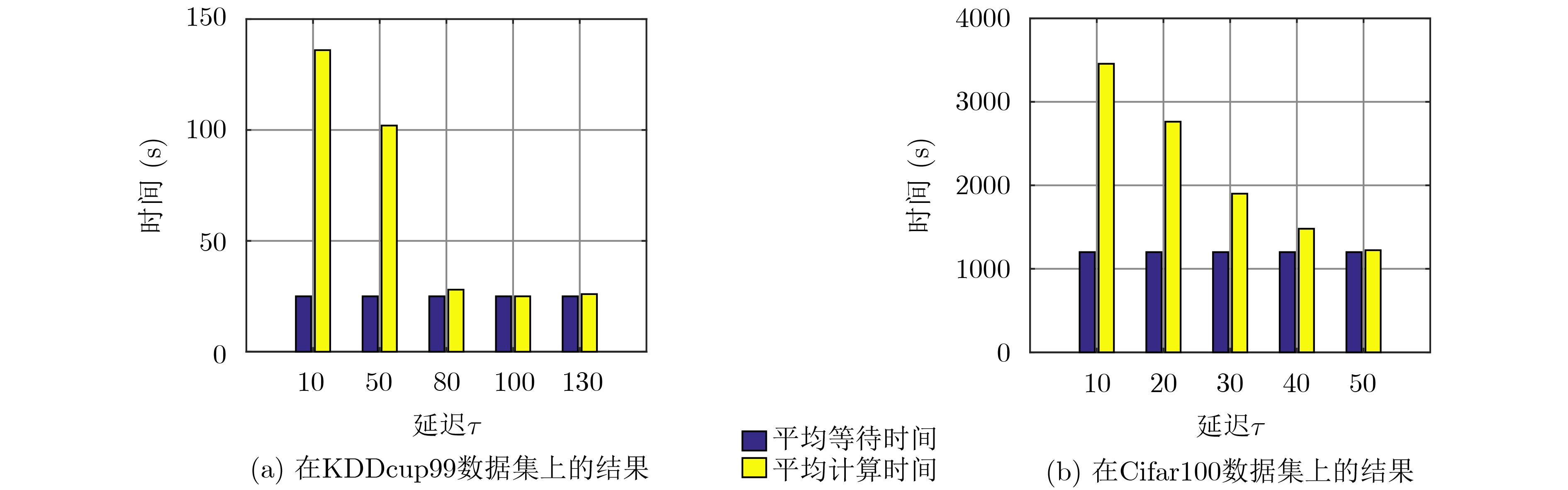
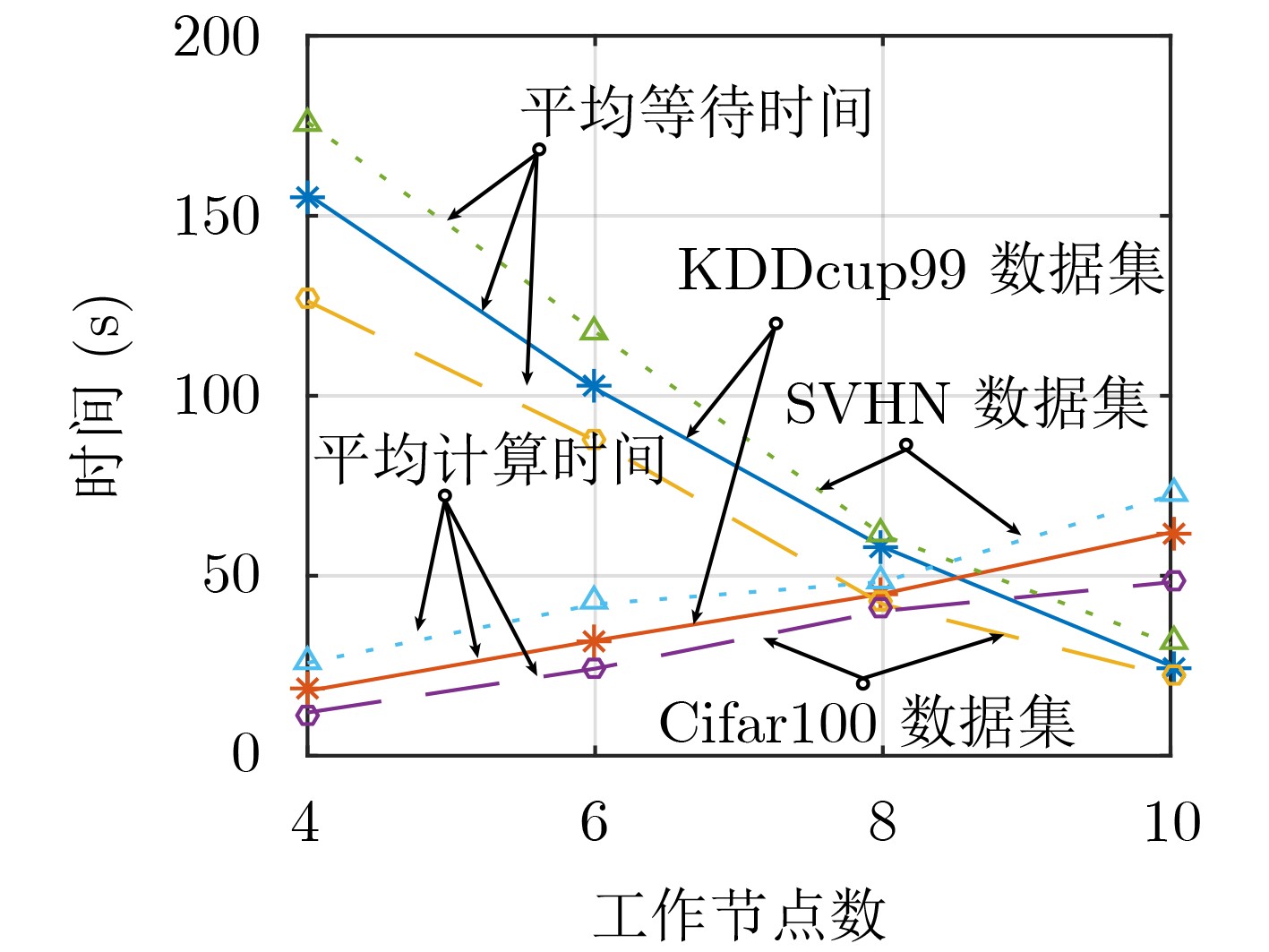
| Citation: | Tao XIE, Chunjiong ZHANG, Yongjian XU. Collaborative Parameter Update Based on Average Variance Reduction of Historical Gradients[J]. Journal of Electronics & Information Technology, 2021, 43(4): 956-964. doi: 10.11999/JEIT200061

|

|
周辉林, 欧阳韬, 刘健. 基于随机平均梯度下降和对比源反演的非线性逆散射算法研究[J]. 电子与信息学报, 2020, 42(8): 2053–2058. doi: 10.11999/JEIT190566
ZHOU Huilin, OUYANG Tao, and LIU Jian. Stochastic average gradient descent contrast source inversion based nonlinear inverse scattering method for complex objects reconstruction[J]. Journal of Electronics &Information Technology, 2020, 42(8): 2053–2058. doi: 10.11999/JEIT190566
|
|
XING E P, HO Q, DAI Wei, et al. Petuum: A new platform for distributed machine learning on big data[J]. IEEE Transactions on Big Data, 2015, 1(2): 49–67. doi: 10.1109/TBDATA.2015.2472014
|
|
HO Qirong, CIPAR J, CUI Henggang, et al. More effective distributed ml via a stale synchronous parallel parameter server[C]. Advances in Neural Information Processing Systems, Stateline, USA, 2013: 1223–1231.
|
|
SHI Hang, ZHAO Yue, ZHANG Bofeng, et al. A free stale synchronous parallel strategy for distributed machine learning[C]. The 2019 International Conference on Big Data Engineering, Hong Kong, China, 2019: 23–29. doi: 10.1145/3341620.3341625.
|
|
ZHAO Xing, AN Aijun, LIU Junfeng, et al. Dynamic stale synchronous parallel distributed training for deep learning[C]. 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, USA, 2019: 1507–1517. doi: 10.1109/ICDCS.2019.00150.
|
|
DEAN J, CORRADO G S, MONGA R, et al. Large scale distributed deep networks[C]. The 25th International Conference on Neural Information Processing Systems, Red Hook, USA, 2012: 1223–1231.
|
|
赵小强, 宋昭漾. 多级跳线连接的深度残差网络超分辨率重建[J]. 电子与信息学报, 2019, 41(10): 2501–2508. doi: 10.11999/JEIT190036
ZHAO Xiaoqiang and SONG Zhaoyang. Super-resolution reconstruction of deep residual network with multi-level skip connections[J]. Journal of Electronics &Information Technology, 2019, 41(10): 2501–2508. doi: 10.11999/JEIT190036
|
|
LI Mu, ANDERSEN D G, PARK J W, et al. Scaling distributed machine learning with the parameter server[C]. The 2014 International Conference on Big Data Science and Computing, Beijing, China, 2014: 583–598. https://doi.org/10.1145/2640087.2644155.
|
|
ZHANG Ruiliang, ZHENG Shuai, and KWOK J T. Asynchronous distributed semi-stochastic gradient optimization[C]. The Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, USA, 2016: 2323–2329.
|
|
XIE Pengtao, KIM J K, ZHOU Yi, et al. Distributed machine learning via sufficient factor broadcasting[J]. arXiv: 1511. 08486, 2015.
|
|
LI Mu, ZHANG Tong, CHEN Yuqiang, et al. Efficient mini-batch training for stochastic optimization[C]. The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA, 2014: 661–670. doi: 10.1145/2623330.2623612.
|
|
WU Jiaxiang, HUANG Weidong, HUANG Junzhou, et al. Error compensated quantized SGD and its applications to large-scale distributed optimization[C]. The 35th International Conference on Machine Learning, Stockholm, The Kingdom of Sweden, 2018.
|
|
LE ROUX N, SCHMIDT M, and BACH F. A stochastic gradient method with an exponential convergence rate for finite training sets[C]. The 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 2663–2671.
|
|
DEFAZIO A, BACH F, and LACOSTE-JULIEN S. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives[C]. The 27th International Conference on Neural Information Processing Systems, Cambridge, USA, 2014: 1646–1654.
|
|
BAN Zhihua, LIU Jianguo, and CAO Li. Superpixel segmentation using Gaussian mixture model[J]. IEEE Transactions on Image Processing, 2018, 27(8): 4105–4117. doi: 10.1109/TIP.2018.2836306
|
|
WANG Pengfei, LIU Risheng, ZHENG Nenggan, et al. Asynchronous proximal stochastic gradient algorithm for composition optimization problems[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 1633–1640. doi: 10.1609/aaai.v33i01.33011633
|
|
FERRANTI L, PU Ye, JONES C N, et al. SVR-AMA: An asynchronous alternating minimization algorithm with variance reduction for model predictive control applications[J]. IEEE Transactions on Automatic Control, 2019, 64(5): 1800–1815. doi: 10.1109/TAC.2018.2849566
|
|
邵言剑, 陶卿, 姜纪远, 等. 一种求解强凸优化问题的最优随机算法[J]. 软件学报, 2014, 25(9): 2160–2171. doi: 10.13328/j.cnki.jos.004633
SHAO Yanjian, TAO Qing, JIANG Jiyuan, et al. Stochastic algorithm with optimal convergence rate for strongly convex optimization problems[J]. Journal of Software, 2014, 25(9): 2160–2171. doi: 10.13328/j.cnki.jos.004633
|
|
赵海涛, 程慧玲, 丁仪, 等. 基于深度学习的车联边缘网络交通事故风险预测算法研究[J]. 电子与信息学报, 2020, 42(1): 50–57. doi: 10.11999/JEIT190595
ZHAO Haitao, CHENG Huiling, DING Yi, et al. Research on traffic accident risk prediction algorithm of edge internet of vehicles based on deep learning[J]. Journal of Electronics &Information Technology, 2020, 42(1): 50–57. doi: 10.11999/JEIT190595
|
|
RAMAZANLI I, NGUYEN H, PHAM H, et al. Adaptive sampling distributed stochastic variance reduced gradient for heterogeneous distributed datasets[J]. arXiv: 2002. 08528, 2020.
|
|
SUSSMAN D M. CellGPU: Massively parallel simulations of dynamic vertex models[J]. Computer Physics Communications, 2017, 219: 400–406. doi: 10.1016/j.cpc.2017.06.001
|
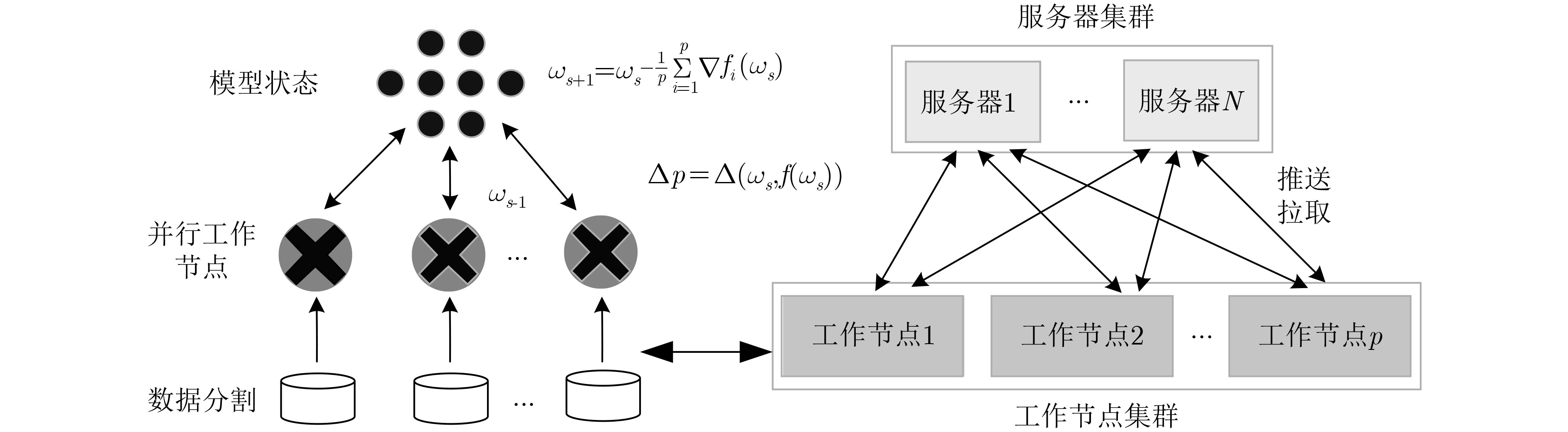
Figures(7) / Tables(3)



 DownLoad:
DownLoad: