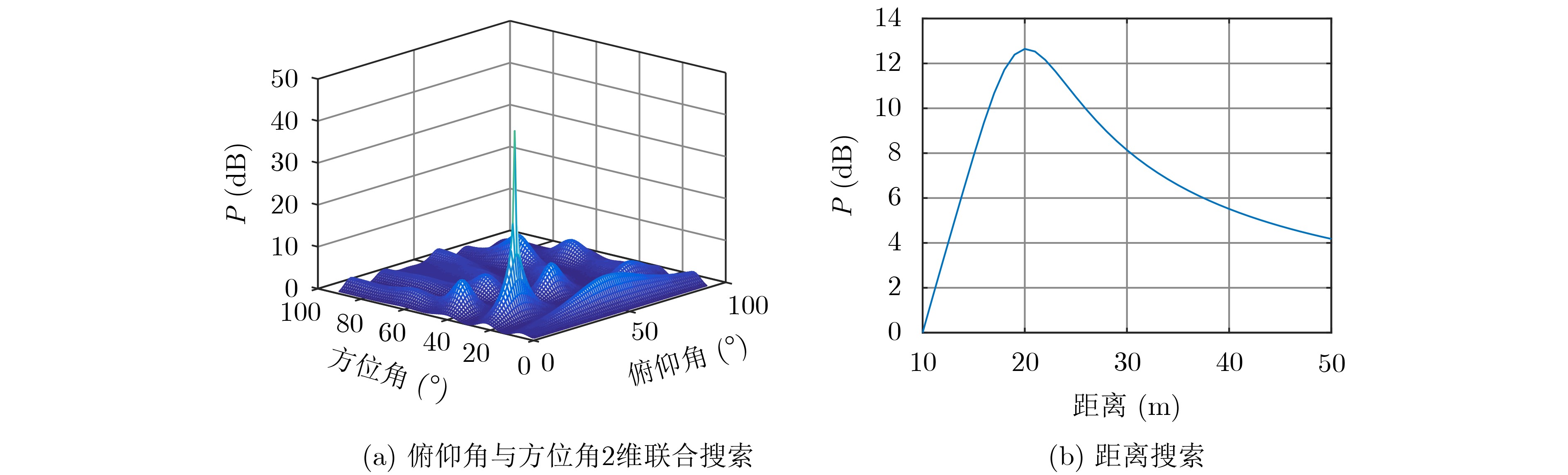
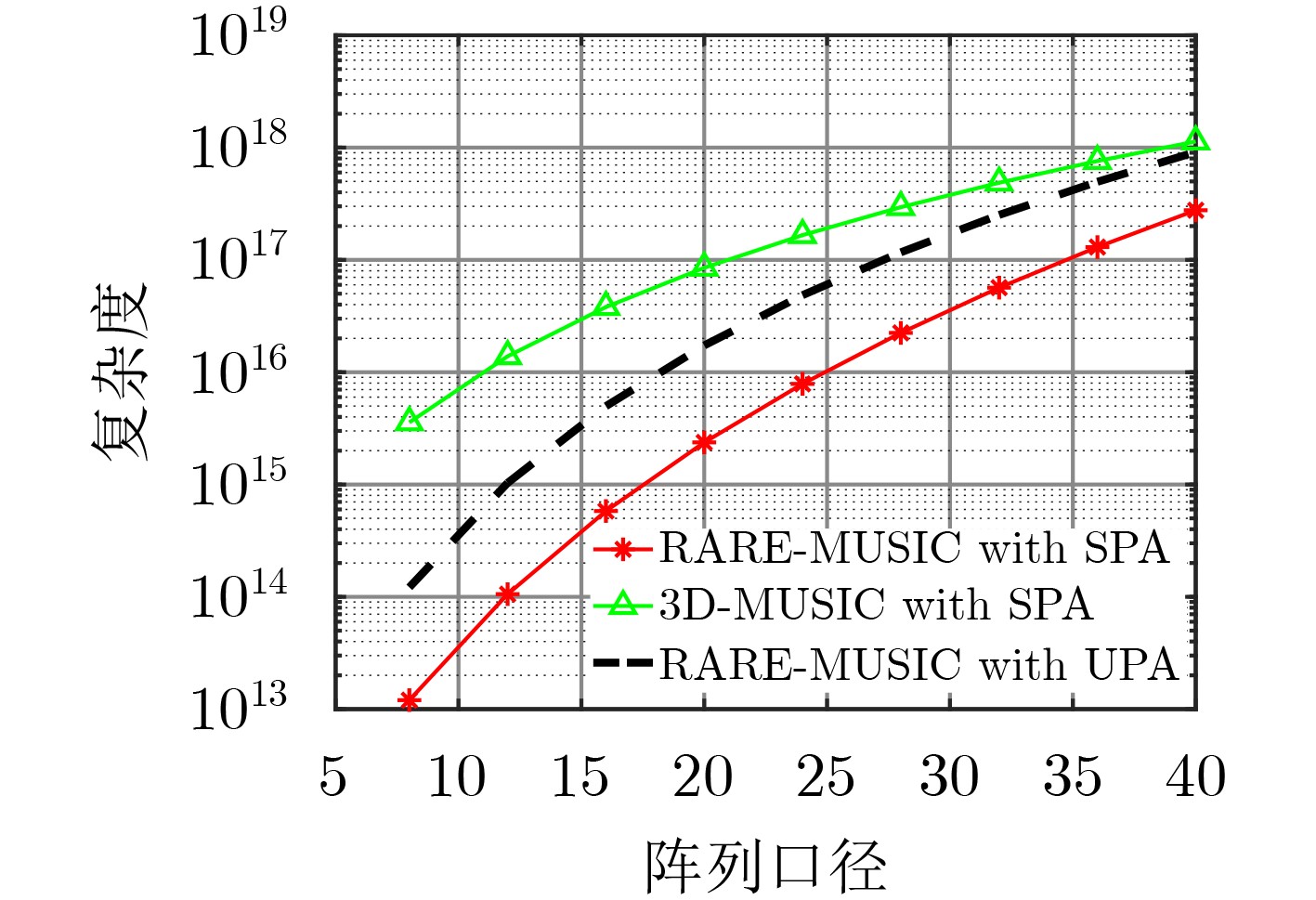
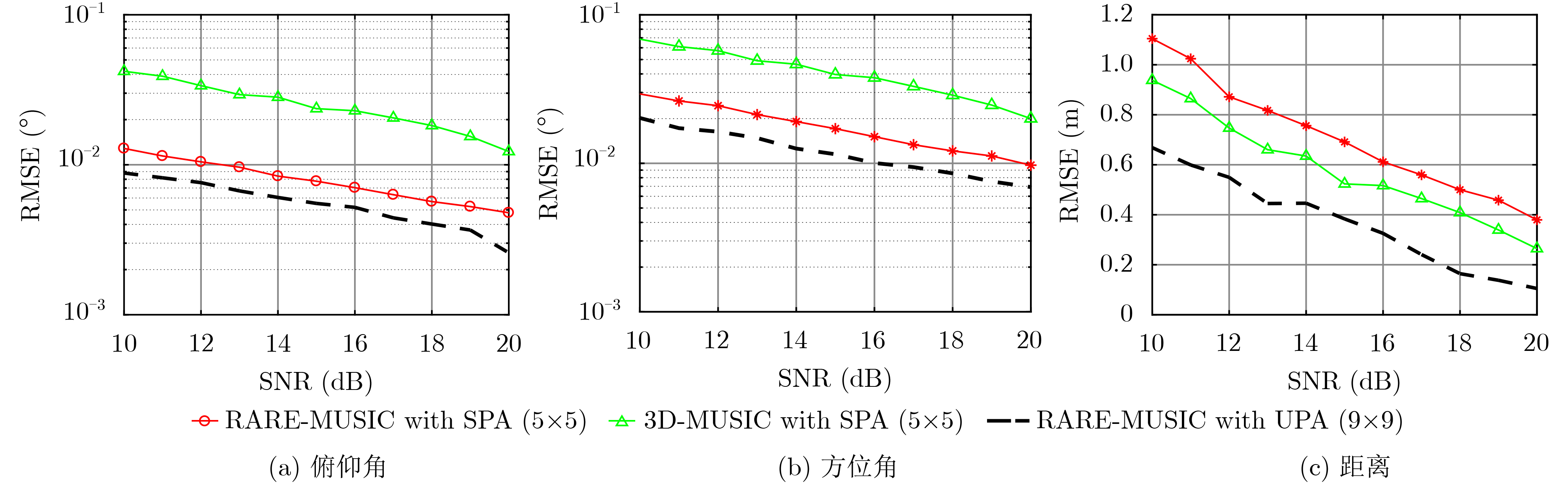
| Citation: | Haowei WU, Chang SHU, Jinglan OU, Shizhong YANG. A Three-dimensional Source Location Algorithm Based on Sparse Planar Array with Low Complexity[J]. Journal of Electronics & Information Technology, 2021, 43(8): 2207-2213. doi: 10.11999/JEIT190779

|

| [1] |
GUZEY N, XU Hao, and JAGANNATHAN S. Localization of near-field sources in spatially colored noise[J]. IEEE Transactions on Instrumentation and Measurement, 2015, 64(8): 2302–2311. doi: 10.1109/TIM.2015.2390813
|
| [2] |
LIANG Junli and LIU Ding. Passive Localization of mixed near-field and far-field sources using two-stage MUSIC algorithm[J]. IEEE Transactions on Signal Processing, 2010, 58(1): 108–120. doi: 10.1109/TSP.2009.2029723
|
| [3] |
TICHAVSKY D, WONG T K, and ZOLTOWSKI M D. Near-field/far-field azimuth and elevation angle estimation using a single vector hydrophone[J]. IEEE Transactions on Signal Processing, 2001, 49(11): 2498–2510. doi: 10.1109/78.960397
|
| [4] |
JI Yilin, FAN Wei, and PEDERSEN G F. Near-field signal model for large-scale uniform circular array and its experimental validation[J]. IEEE Antennas and Wireless Propagation Letters, 2017, 16: 1237–1240. doi: 10.1109/LAWP.2016.2629189
|
| [5] |
LIANG Junli and LIU Ding. Passive localization of near-field sources using cumulant[J]. IEEE Sensors Journal, 2009, 9(8): 953–960. doi: 10.1109/JSEN.2009.2025580
|
| [6] |
JUNG T J and LEE K. Closed-Form algorithm for 3-D single-source localization with uniform circular array[J]. IEEE Antennas and Wireless Propagation Letters, 2014, 13: 1096–1099. doi: 10.1109/LAWP.2014.2327992
|
| [7] |
SCHMIDT R. Multiple emitter location and signal parameter estimation[J]. IEEE Transactions on Antennas and Propagation, 1986, 34(3): 276–280. doi: 10.1109/TAP.1986.1143830
|
| [8] |
ROY R and KAILATH T. ESPRIT-estimation of signal parameters via rotational invariance techniques[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1989, 37(7): 984–995. doi: 10.1109/29.32276
|
| [9] |
WEN Fei, WAN Qun, FAN Rong, et al. Improved MUSIC algorithm for multiple noncoherent subarrays[J]. IEEE Signal Processing Letters, 2014, 21(5): 527–530. doi: 10.1109/LSP.2014.2308271
|
| [10] |
ZHANG Dong, ZHANG Yongshun, ZHENG Guimei, et al. Two-dimensional direction of arrival estimation for coprime planar arrays via polynomial root finding technique[J]. IEEE Access, 2018, 6: 19540–19549. doi: 10.1109/ACCESS.2018.2821919
|
| [11] |
ZHAO Hongwei, CAI Muren, and LIU Heng. Two-dimensional DOA estimation with reduced-dimension MUSIC algorithm[C]. International Applied Computational Electromagnetics Society Symposium (ACES), Suzhou, China, 2017: 1–2.
|
| [12] |
李建峰, 沈明威, 蒋德富. 互质阵中基于降维求根的波达角估计算法[J]. 电子与信息学报, 2018, 40(8): 1853–1859. doi: 10.11999/JEIT171087
LI Jianfeng, SHEN Mingwei, and JIANG Defu. Reduced-dimensional root finding based direction of arrival estimation for coprime array[J]. Journal of Electronics &Information Technology, 2018, 40(8): 1853–1859. doi: 10.11999/JEIT171087
|
| [13] |
XIE Jian, TAO Haihong, RAO Xuan, et al. Passive localization of noncircular sources in the near-field[C]. International Radar Symposium (IRS), Dresden, Germany, 2015: 493–498. doi: 10.1109/IRS.2015.7226309.
|
| [14] |
ZHENG Wang, ZHANG Xiaofei, and ZHAI Hui. Generalized coprime planar array geometry for 2-D DOA estimation[J]. IEEE Communications Letters, 2017, 21(5): 1075–1078. doi: 10.1109/LCOMM.2017.2664809
|
| [15] |
ASCHER A, LECHNER J, NOSOVIC S, et al. 3D localization of passive UHF RFID transponders using direction of arrival and distance estimation techniques[C]. The 2nd IEEE Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 2017: 1373–1379. doi: 10.1109/IAEAC.2017.8054239.
|
| [16] |
李建峰, 蒋德富, 沈明威. 基于平行嵌套阵互协方差的二维波达角联合估计算法[J]. 电子与信息学报, 2017, 39(3): 670–676. doi: 10.11999/JEIT160488
LI Jianfeng, JIANG Defu, and SHEN Mingwei. Joint two-dimensional direction of arrival estimation based on cross covariance matrix of parallel nested array[J]. Journal of Electronics &Information Technology, 2017, 39(3): 670–676. doi: 10.11999/JEIT160488
|

Figures(5) / Tables(1)



 DownLoad:
DownLoad: