| Citation: | Yibin WANG, Gensheng PEI, Yusheng CHENG. Group-Label-Specific Features Learning Based on Label-Density Classification Margin[J]. Journal of Electronics & Information Technology, 2020, 42(5): 1179-1187. doi: 10.11999/JEIT190343

|
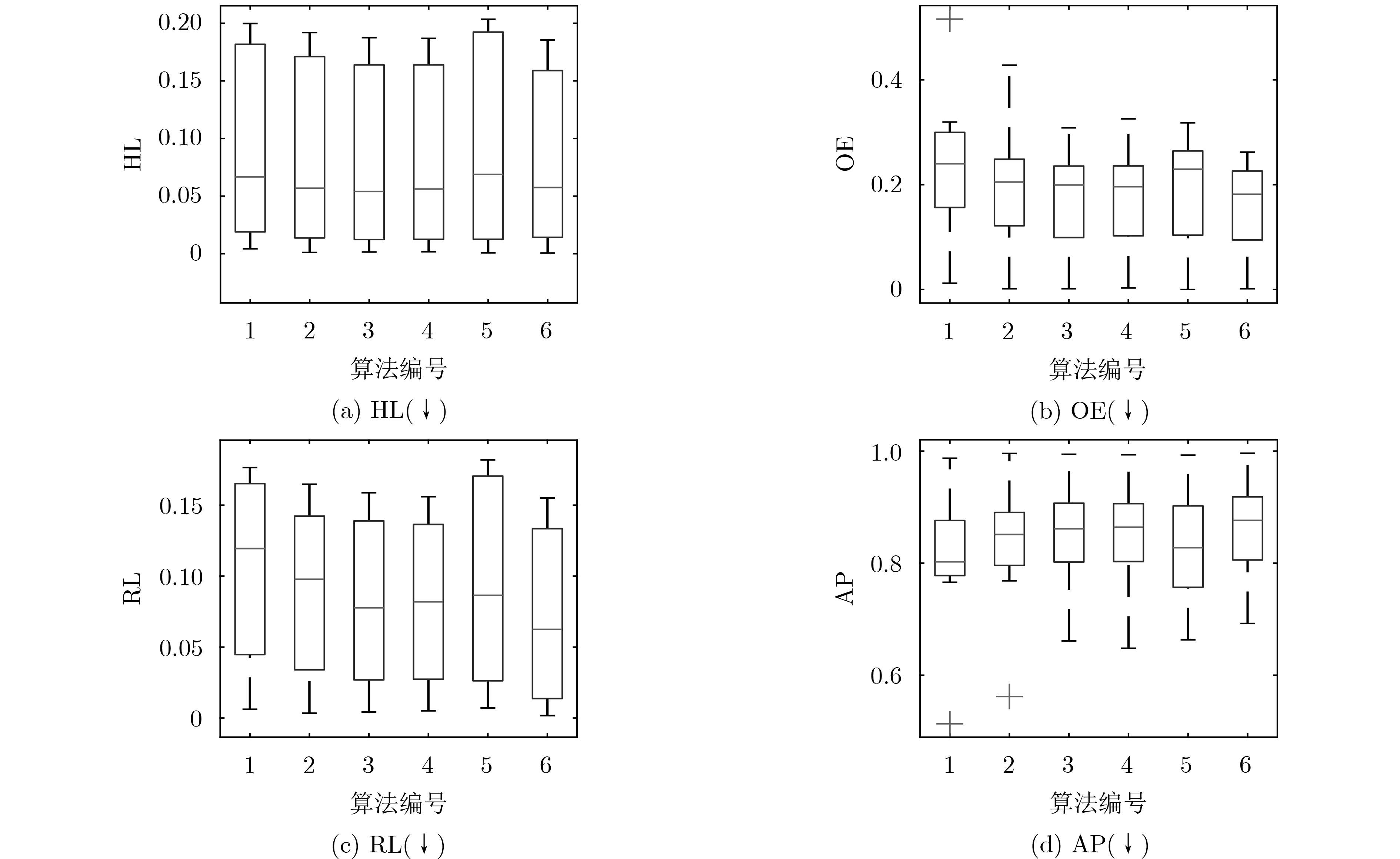
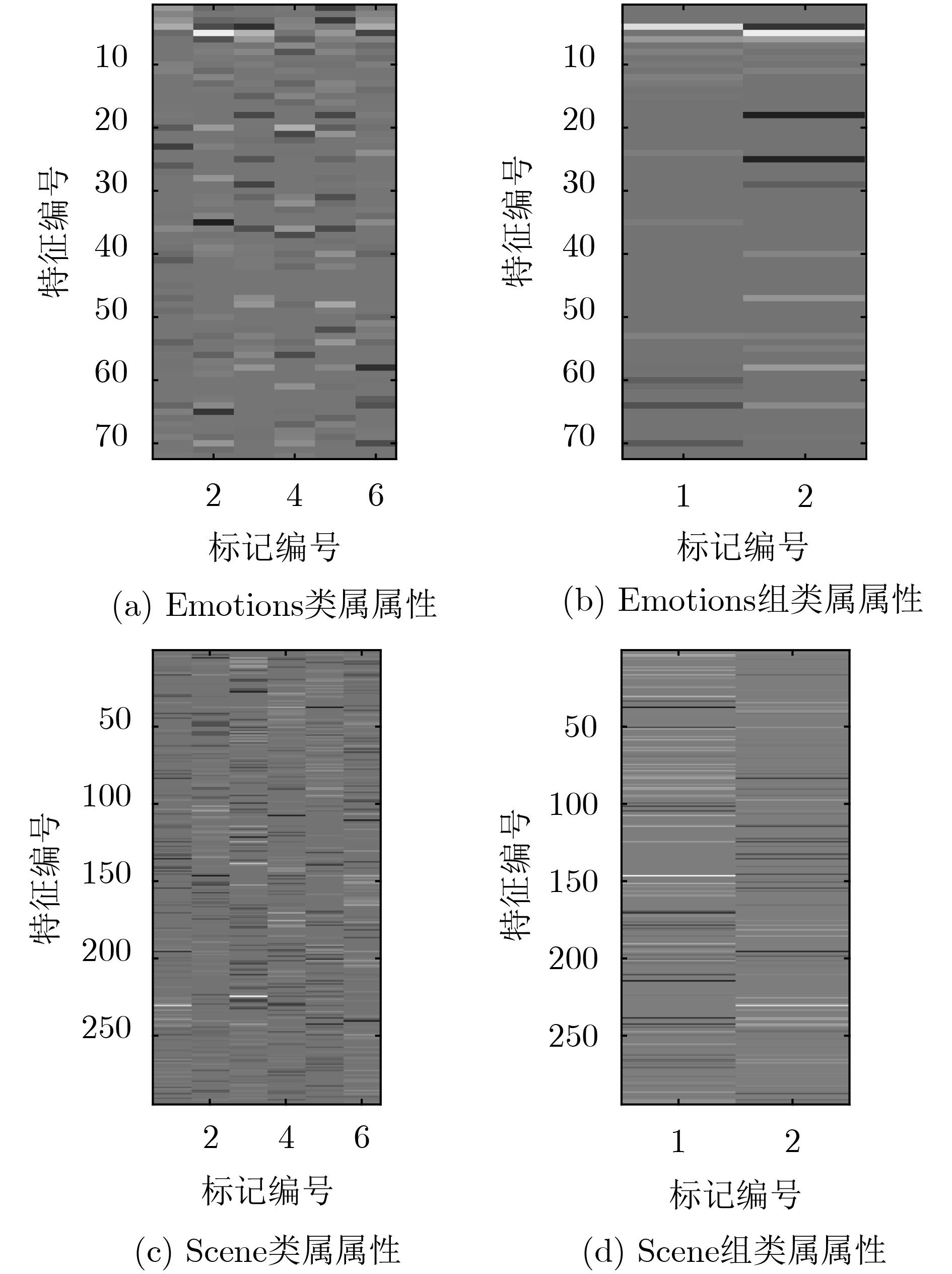
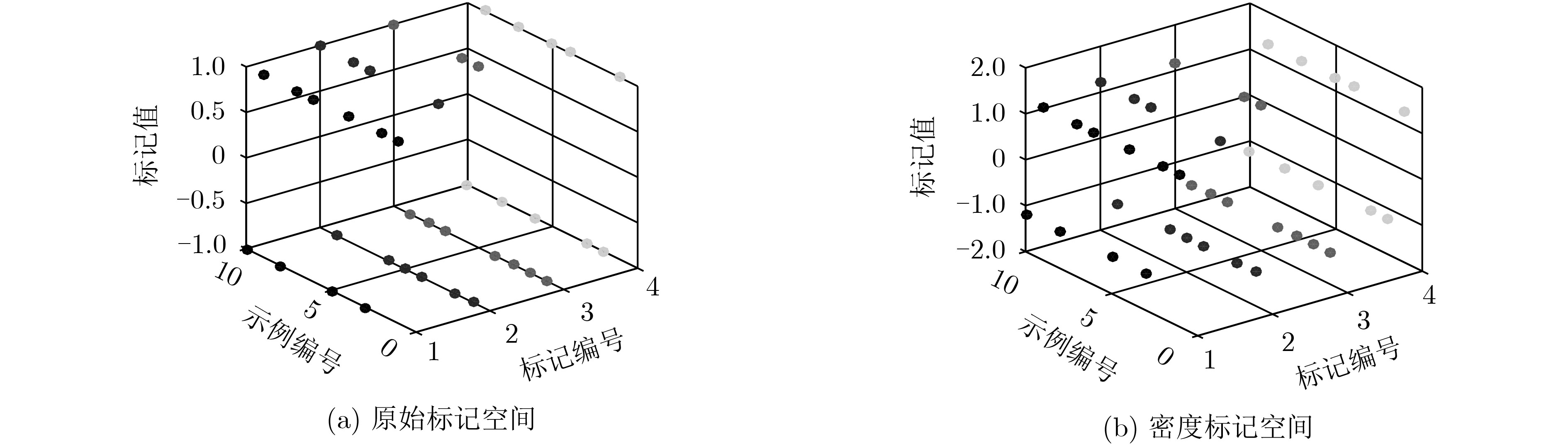
The label-specific features learning avoids the same features prediction for all class labels, it is a kind of framework for extracting the specific features of each label for classification, so it is widely used in multi-label learning. For the problems of large label dimension and unbalanced label distribution density, the existing multi-label learning algorithm based on label-specific features has larger time consumption and lower classification accuracy. In order to improve the performance of classification, a Group-Label-Specific Features Learning method based on Label-Density Classification Margin (GLSFL-LDCM) is proposed. Firstly, the cosine similarity is used to construct the label correlation matrix, and the class labels are grouped by spectral clustering to extract the label-specific features of each label group to reduce the time consumption for calculating the label-specific features of all class labels. Then, the density of each label is calculated to update the label space matrix, the label-density information is added to the original label space. The classification margin between the positive and negative labels is expanded, thus the imbalance label distribution density problem is effectively solved by the method of label-density classification margin. Finally, the final classification model is obtained by inputting the group-label-specific features and the label-density matrix into the extreme learning machine. The comparison experiment results verify fully the feasibility and stability of the proposed algorithm.

|
ZHANG Minling and ZHOU Zhihua. ML-KNN: A lazy learning approach to multi-label learning[J]. Pattern Recognition, 2007, 40(7): 2038–2048. doi: 10.1016/j.patcog.2006.12.019
|
|
LIU Yang, WEN Kaiwen, GAO Quanxue, et al. SVM based multi-label learning with missing labels for image annotation[J]. Pattern Recognition, 2018, 78: 307–317. doi: 10.1016/j.patcog.2018.01.022
|
|
ZHANG Junjie, WU Qi, SHEN Chunhua, et al. Multilabel image classification with regional latent semantic dependencies[J]. IEEE Transactions on Multimedia, 2018, 20(10): 2801–2813. doi: 10.1109/TMM.2018.2812605
|
|
AL-SALEMI B, AYOB M, and NOAH S A M. Feature ranking for enhancing boosting-based multi-label text categorization[J]. Expert Systems with Applications, 2018, 113: 531–543. doi: 10.1016/j.eswa.2018.07.024
|
|
ZHANG Minling and ZHOU Zhihua. Multilabel neural networks with applications to functional genomics and text categorization[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(10): 1338–1351. doi: 10.1109/TKDE.2006.162
|
|
GUAN Renchu, WANG Xu, YANG M Q, et al. Multi-label deep learning for gene function annotation in cancer pathways[J]. Scientific Reports, 2018, 8: No. 267. doi: 10.1038/s41598-017-17842-9
|
|
SAMY A E, EL-BELTAGY S R, and HASSANIEN E. A context integrated model for multi-label emotion detection[J]. Procedia Computer Science, 2018, 142: 61–71. doi: 10.1016/j.procs.2018.10.461
|
|
ALMEIDA A M G, CERRI R, PARAISO E C, et al. Applying multi-label techniques in emotion identification of short texts[J]. Neurocomputing, 2018, 320: 35–46. doi: 10.1016/j.neucom.2018.08.053
|
|
TSOUMAKAS G and KATAKIS I. Multi-label classification: An overview[J]. International Journal of Data Warehousing and Mining, 2007, 3(3): No. 1. doi: 10.4018/jdwm.2007070101
|
|
ZHANG Minling and ZHOU Zhihua. A review on multi-label learning algorithms[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(8): 1819–1837. doi: 10.1109/TKDE.2013.39
|
|
CRAMMER K, DREDZE M, GANCHEV K, et al. Automatic code assignment to medical text[C]. Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing, Stroudsburg, USA, 2007: 129–136.
|
|
ZHANG Minling and WU Lei. Lift: Multi-label learning with label-specific features[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(1): 107–120. doi: 10.1109/TPAMI.2014.2339815
|
|
XU Suping, YANG Xibei, YU Hualong, et al. Multi-label learning with label-specific feature reduction[J]. Knowledge-Based Systems, 2016, 104: 52–61. doi: 10.1016/j.knosys.2016.04.012
|
|
SUN Lu, KUDO M, and KIMURA K. Multi-label classification with meta-label-specific features[C]. 2016 IEEE International Conference on Pattern Recognition, Cancun, Mexico, 2016: 1612–1617. doi: 10.1109/ICPR.2016.7899867.
|
|
HUANG Jun, LI Guorong, HUANG Qingming, et al. Joint feature selection and classification for multilabel learning[J]. IEEE Transactions on Cybernetics, 2018, 48(3): 876–889. doi: 10.1109/TCYB.2017.2663838
|
|
WENG Wei, LIN Yaojin, WU Shunxiang, et al. Multi-label learning based on label-specific features and local pairwise label correlation[J]. Neurocomputing, 2018, 273: 385–394. doi: 10.1016/j.neucom.2017.07.044
|
|
HUANG Jun, LI Guorong, HUANG Qingming, et al. Learning label-specific features and class-dependent labels for multi-label classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(12): 3309–3323. doi: 10.1109/TKDE.2016.2608339
|
|
HUANG Guangbin, ZHU Qinyu, and SIEW C K. Extreme learning machine: Theory and applications[J]. Neurocomputing, 2006, 70(1/3): 489–501. doi: 10.1016/j.neucom.2005.12.126
|
|
HUANG Guangbin, ZHOU Hongming, DING Xiaojian, et al. Extreme learning machine for regression and multiclass classification[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics)
|
|
赵小强, 刘晓丽. 基于公理化模糊子集的改进谱聚类算法[J]. 电子与信息学报, 2018, 40(8): 1904–1910. doi: 10.11999/JEIT170904
ZHAO Xiaoqiang and LIU Xiaoli. An improved spectral clustering algorithm based on axiomatic fuzzy set[J]. Journal of Electronics &Information Technology, 2018, 40(8): 1904–1910. doi: 10.11999/JEIT170904
|
|
BOYD S, PARIKH N, CHU E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations and Trends® in Machine learning, 2010, 3(1): 1–122. doi: 10.1561/2200000016
|
|
LIU Xinwang, WANG Lei, HUANG Guangbin, et al. Multiple kernel extreme learning machine[J]. Neurocomputing, 2015, 149: 253–264. doi: 10.1016/j.neucom.2013.09.072
|
|
邓万宇, 郑庆华, 陈琳, 等. 神经网络极速学习方法研究[J]. 计算机学报, 2010, 33(2): 279–287. doi: 10.3724/SP.J.1016.2010.00279
DENG Wanyu, ZHENG Qinghua, CHEN Lin, et al. Research on extreme learning of neural networks[J]. Chinese Journal of Computers, 2010, 33(2): 279–287. doi: 10.3724/SP.J.1016.2010.00279
|
|
ZHOU Zhihua, ZHANG Minling, HUANG Shengjun, et al. Multi-instance multi-label learning[J]. Artificial Intelligence, 2012, 176(1): 2291–2320. doi: 10.1016/j.artint.2011.10.002
|
|
PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A method for automatic evaluation of machine translation[C]. The 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, USA, 2002: 311–318. doi: 10.3115/1073083.1073135.
|
Figures(3) / Tables(6)



 DownLoad:
DownLoad: