| Citation: | Zhengyi LIU, Quntao DUAN, Song SHI, Peng ZHAO. RGB-D Image Saliency Detection Based on Multi-modal Feature-fused Supervision[J]. Journal of Electronics & Information Technology, 2020, 42(4): 997-1004. doi: 10.11999/JEIT190297

|
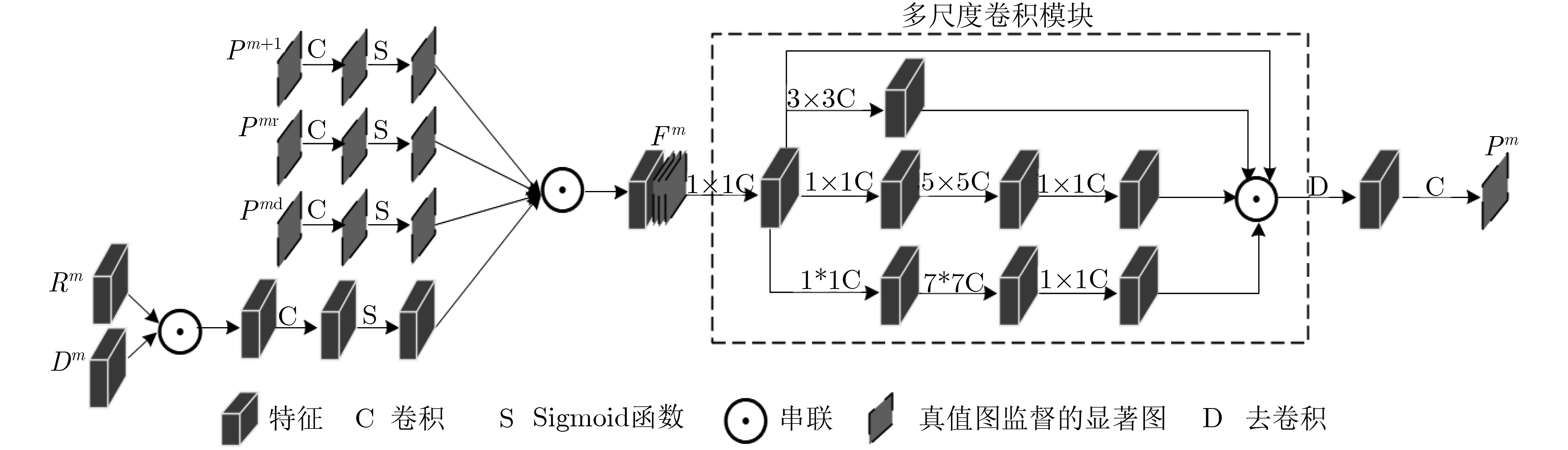
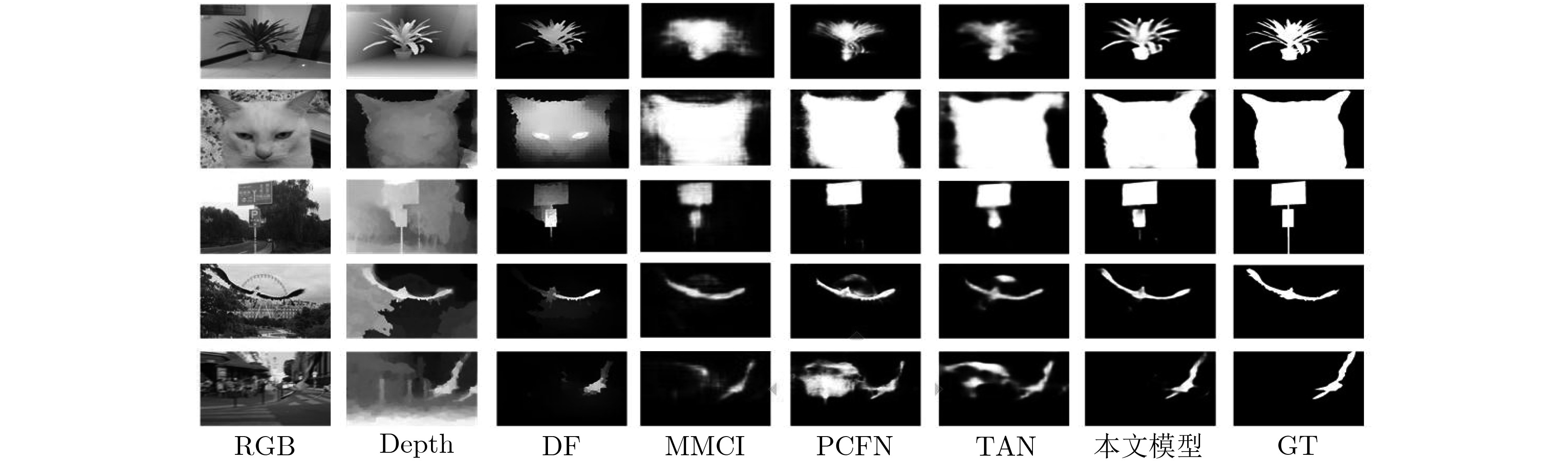
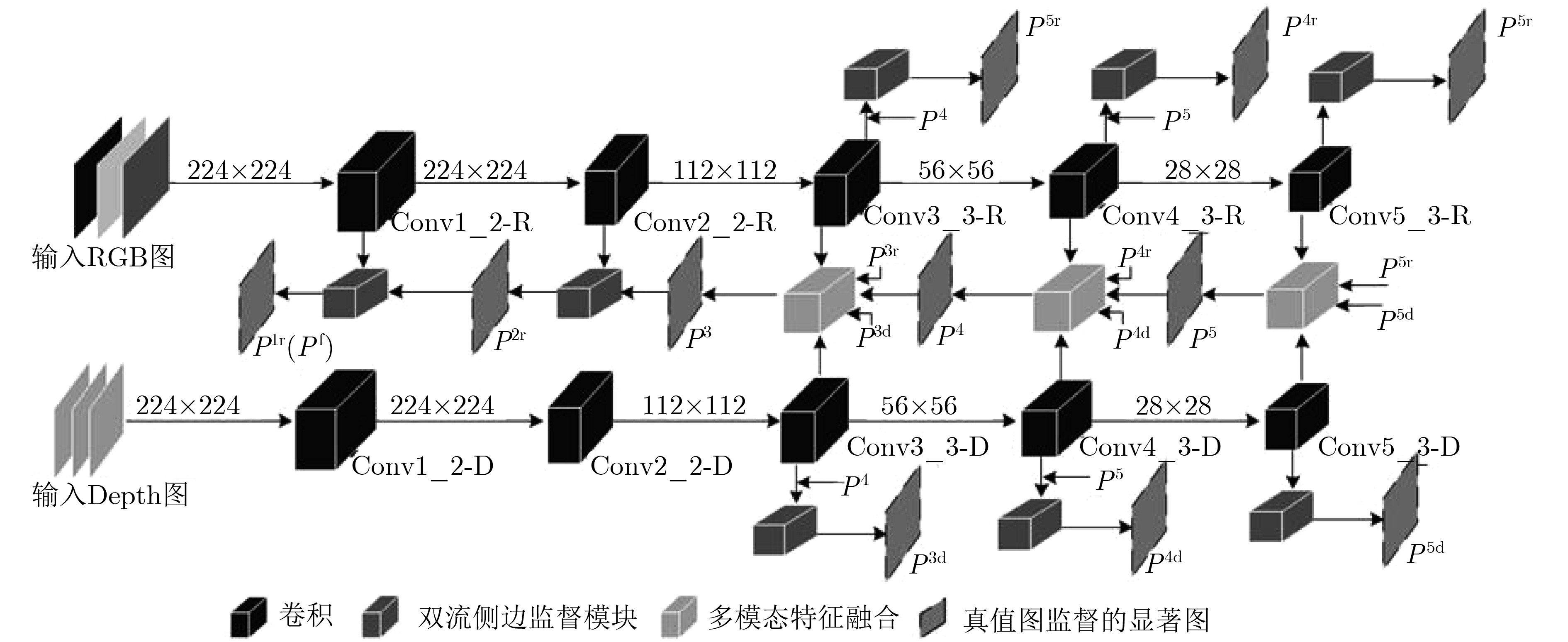
RGB-D saliency detection identifies the most visually attentive target areas in a pair of RGB and Depth images. Existing two-stream networks, which treat RGB and Depth data equally, are almost identical in feature extraction. As the lower layers Depth features with a lot of noise, it causes image features not be well characterized. Therefore, a multi-modal feature-fused supervision of RGB-D saliency detection network is proposed, RGB and Depth data are studied independently through two-stream , double-side supervision module is used respectively to obtain saliency maps of each layer, and then the multi-modal feature-fused module is used to later three layers of the fused RGB and Depth of higher dimensional information to generate saliency predicted results. Finally, the information of lower layers is fused to generate the ultimate saliency maps. Experiments on three open data sets show that the proposed network has better performance and stronger robustness than the current RGB-D saliency detection models.

|
SHAO Ling and BRADY M. Specific object retrieval based on salient regions[J]. Pattern Recognition, 2006, 39(10): 1932–1948. doi: 10.1016/j.patcog.2006.04.010
|
|
GUO Chenlei and ZHANG Liming. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression[J]. IEEE Transactions on Image Processing, 2010, 19(1): 185–198. doi: 10.1109/TIP.2009.2030969
|
|
MAHADEVAN V and VASCONCELOS N. Biologically inspired object tracking using center-surround saliency mechanisms[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(3): 541–554. doi: 10.1109/TPAMI.2012.98
|
|
QU Liangqiong, HE Shengfeng, ZHANG Jiawei, et al. RGBD salient object detection via deep fusion[J]. IEEE Transactions on Image Processing, 2017, 26(5): 2274–2285. doi: 10.1109/TIP.2017.2682981
|
|
CHEN Hao, LI Youfu, and SU Dan. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection[J]. Pattern Recognition, 2019, 86: 376–385. doi: 10.1016/j.patcog.2018.08.007
|
|
HAN Junwei, CHEN Hao, LIU Nian, et al. CNNs-Based RGB-D saliency detection via cross-view transfer and multiview fusion[J]. IEEE Transactions on Cybernetics, 2018, 48(11): 3171–3183. doi: 10.1109/TCYB.2017.2761775
|
|
CHEN Hao, LI Youfu, and SU Dan. RGB-D saliency detection by multi-stream late fusion network[C]. The 11th International Conference on Computer Vision Systems, Shenzhen, China, 2017: 459-468. doi: 10.1007/978-3-319-68345-4_41.
|
|
CHEN Hao and LI Youfu. Progressively complementarity-aware fusion network for RGB-D salient object detection[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3051–3060.
|
|
SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. 2015 International Conference on Learning Representations, San Diego, USA, 2015: 1150–1210.
|
|
LEE C Y, XIE Saining, GALLAGHER P, et al. Deeply-supervised nets[C]. The 18th International Conference on Artificial Intelligence and Statistics, San Diego, USA, 2015: 562–570.
|
|
XIE Saining and TU Zhuowen. Holistically-nested edge detection[J]. International Journal of Computer Vision, 2017, 125(1/3): 3–18. doi: 10.1007/s11263-017-1004-z
|
|
HOU Qibin, CHENG Mingming, HU Xiaowei, et al. Deeply supervised salient object detection with short connections[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 815–828. doi: 10.1109/TPAMI.2018.2815688
|
|
DU Dapeng, XU Xiangyang, REN Tongwei, et al. Depth images could tell us more: Enhancing depth discriminability for RGB-D scene recognition[C]. 2018 IEEE International Conference on Multimedia and Expo, San Diego, USA, 2018: 1–6. doi: 10.1109/ICME.2018.8486573.
|
|
SONG Xinhang, HERRANZ L, and JIANG Shuqiang. Depth CNNs for RGB-D scene recognition: Learning from scratch better than transferring from RGB-CNNs[C]. The 31st AAAI Conference on Artificial Intelligence, San Francisco, USA, 2017: 4271–4277.
|
|
LIU Nian and HAN Junwei. DHSnet: Deep hierarchical saliency network for salient object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 678–686. doi: 10.1109/CVPR.2016.80.
|
|
KIM H J, DUNN E, and FRAHM J M. Learned contextual feature reweighting for image geo-localization[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3251–3260. doi: 10.1109/CVPR.2017.346.
|
|
PENG Houwen, LI Bing, XIONG Weihua, et al. RGBD salient object detection: A benchmark and algorithms[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 92–109. doi: 10.1007/978-3-319-10578-9_7.
|
|
JU Ran, GE Ling, GENG Wenjing, et al. Depth saliency based on anisotropic center-surround difference[C]. 2014 IEEE International Conference on Image Processing, Paris, France, 2014: 1115–1119. doi: 10.1109/ICIP.2014.7025222.
|
|
NIU Yuzhen, GENG Yujie, LI Xueqing, et al. Leveraging stereopsis for saliency analysis[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 454–461. doi: 10.1109/CVPR.2012.6247708.
|
|
MARTIN D R, FOWLKES C C, and MALIK J. Learning to detect natural image boundaries using local brightness, color, and texture cues[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(5): 530–549. doi: 10.1109/TPAMI.2004.1273918
|
|
FAN Dengping, CHENG Mingming, LIU Yun, et al. Structure-measure: A new way to evaluate foreground maps[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 4558–4567.
|
|
FAN Dengping, GONG Cheng, CAO Yang, et al. Enhanced-alignment measure for binary foreground map evaluation[C]. The 27th International Joint Conference on Artificial Intelligence, Stockholm, 2018: 698–704.
|
|
FAN Dengping, CHENG Mingming, LIU Jiangjiang, et al. Salient objects in clutter: Bringing salient object detection to the foreground[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 186–202.
|
|
JIA Yangqing, SHELHAMER E, DONAHUE J, et al. Caffe: Convolutional architecture for fast feature embedding[C]. The 22nd ACM International Conference on Multimedia, Orlando, USA, 2014: 675–678. doi: 10.1145/2647868.2654889.
|
|
CHEN Hao and LI Youfu. Three-stream attention-aware network for RGB-D salient object detection[J]. IEEE Transactions on Image Processing, 2019, 28(6): 2825–2835. doi: 10.1109/TIP.2019.2891104
|
Figures(7) / Tables(4)



 DownLoad:
DownLoad: