| Citation: | Xiongtao ZHANG, Yunliang JIANG, Xingguang PAN, Wenjun HU, Shitong WANG. Iterative Fuzzy C-means Clustering Algorithm & K-Nearest Neighbor and Dictionary Data Based Ensemble TSK Fuzzy Classifiers[J]. Journal of Electronics & Information Technology, 2020, 42(3): 746-754. doi: 10.11999/JEIT190214

|
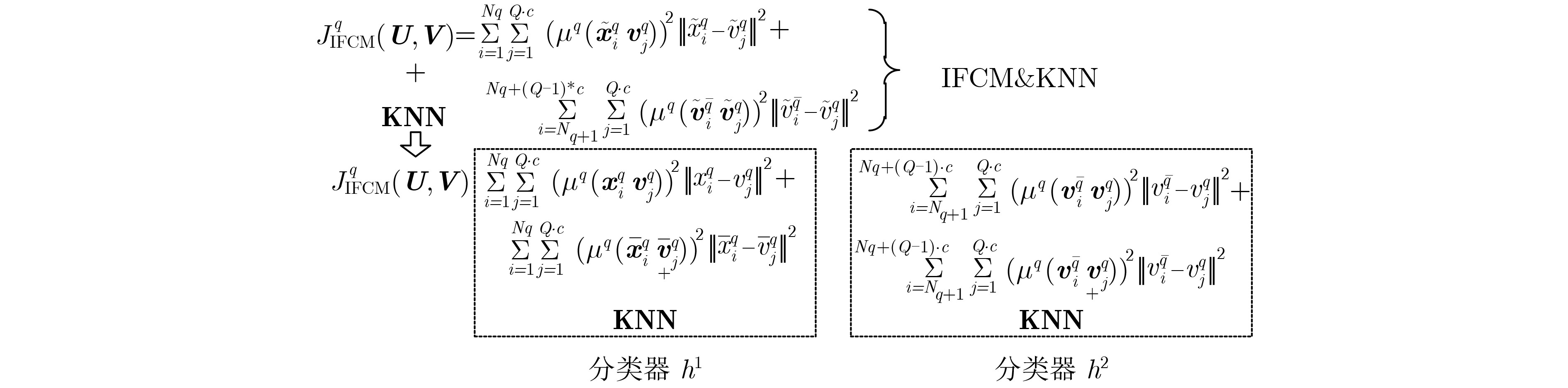
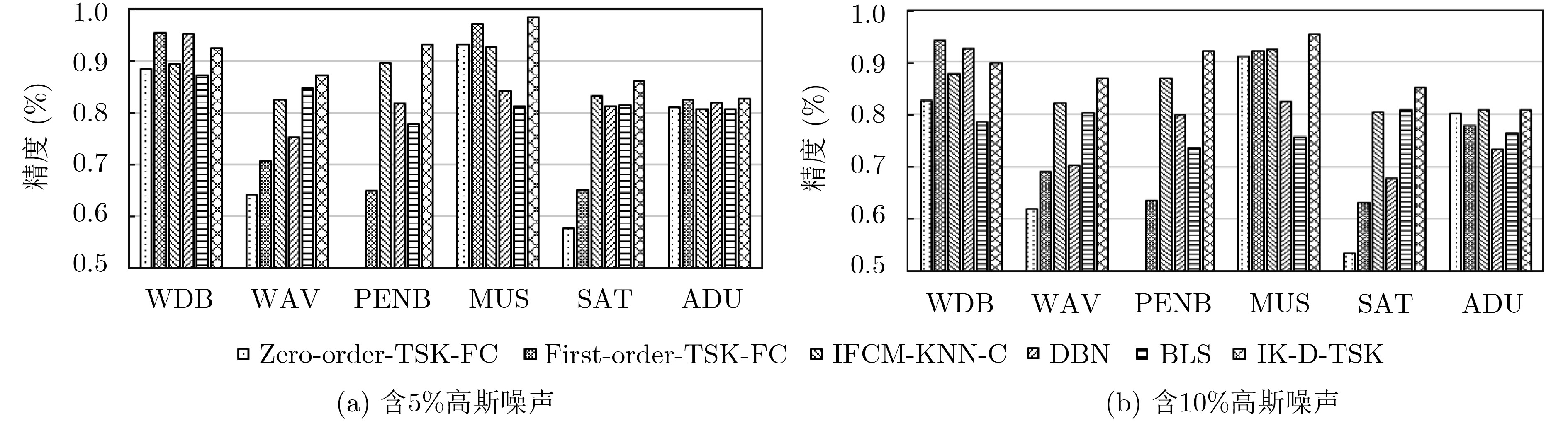
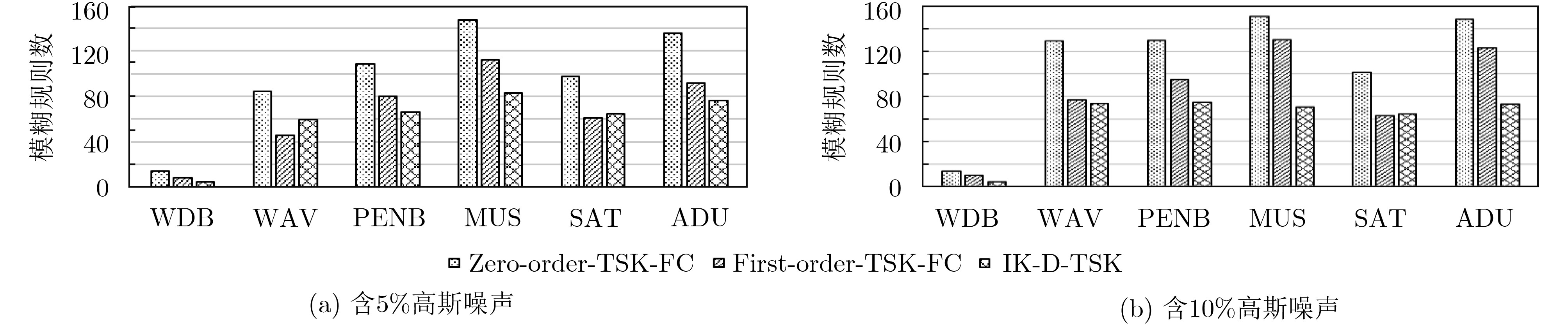
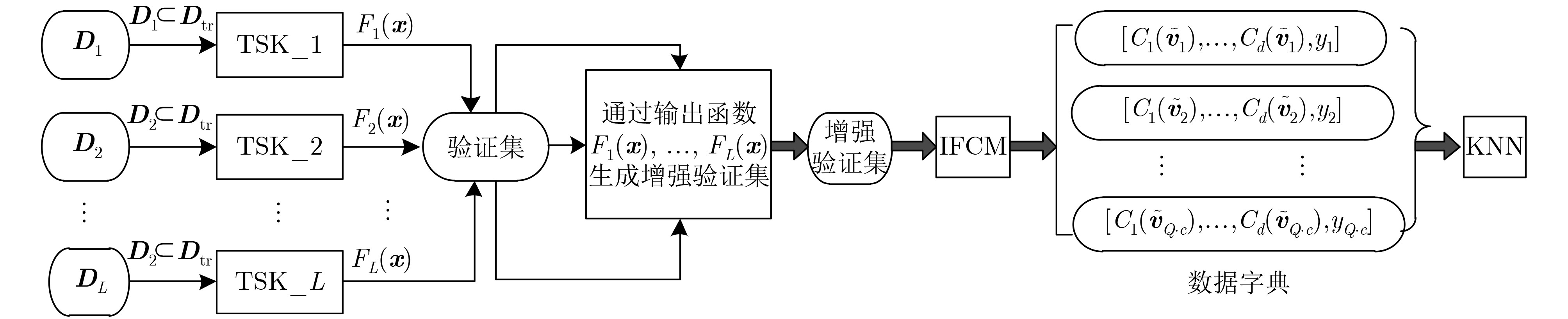
A new ensemble TSK fuzzy classifier (i,e. IK-D-TSK) is proposed. First, all zero-order TSK fuzzy sub-classifiers are organized in a parallel way, then the output of each sub-classifier is augmented to the original (validation) input space, finally, the proposed Iterative Fuzzy C-Means (IFCM) clustering algorithm generates dictionary data on augmented validation dataset, and then KNN is used to predict the result for test data. IK-D-TSK has the following advantages: the output of each zero-order TSK subclassifier is augmented to the original input space to open the manifold structure in parallel, according to the principle of stack generalization, the classification accuracy can be improved; Compared with traditional TSK fuzzy classifiers which trains sequentially, IK-D-TSK trains all the sub-classifiers in parallel, so the running speed can be effectively guaranteed; Because IK-D-TSK works based on dictionary data obtained by IFCM & KNN, it has strong robustness. The theoretical and experimental results show that IK-D-TSK has high classification performance, strong robustness and high interpretability.

|
TEH C Y, KERK Y W, TAY K M, et al. On modeling of data-driven monotone zero-order TSK fuzzy inference systems using a system identification framework[J]. IEEE Transactions on Fuzzy Systems, 2018, 26(6): 3860–3874. doi: 10.1109/TFUZZ.2018.2851258
|
|
PEDRYCZ W and GOMIDE F. Fuzzy Systems Engineering: Toward Human-Centric Computing[M]. Hoboken, NJ: Wiley, 2007: 85–101.
|
|
TAKAGI T and SUGENO M. Fuzzy identification of systems and its applications to modeling and control[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1985, SMC-15(1): 116–132. doi: 10.1109/TSMC.1985.6313399
|
|
TAO Dapeng, CHENG Jun, YU Zhengtao, et al. Domain-weighted majority voting for crowdsourcing[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(1): 163–174. doi: 10.1109/TNNLS.2018.2836969
|
|
HU Mengqiu, YANG Yang, SHEN Fumin, et al. Robust Web image annotation via exploring multi-facet and structural knowledge[J]. IEEE Transactions on Image Processing, 2017, 26(10): 4871–4884. doi: 10.1109/TIP.2017.2717185
|
|
ZHANG Yuanpeng, ISHIBUCHI H, and WANG Shitong. Deep Takagi-Sugeno-Kang fuzzy classifier with shared linguistic fuzzy rules[J]. IEEE Transactions on Fuzzy Systems, 2018, 26(3): 1535–1549. doi: 10.1109/TFUZZ.2017.2729507
|
|
CORDON O, HERRERA F, and ZWIR I. Linguistic modeling by hierarchical systems of linguistic rules[J]. IEEE Transactions on Fuzzy Systems, 2002, 10(1): 2–20. doi: 10.1109/91.983275
|
|
NASCIMENTO D S C, BANDEIRA D R C, CANUTO A M P, et al. Investigating the impact of diversity in ensembles of multi-label classifiers[C]. 2018 International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 2018: 1–8. doi: 10.1109/IJCNN.2018.8489660.
|
|
BISHOP C M. Pattern Recognition and Machine Learning[M]. New York: Springer, 2006: 51–75.
|
|
王士同, 钟富礼. 最小学习机[J]. 江南大学学报: 自然科学版, 2010, 9(5): 505–510. doi: 10.3969/j.issn.1671-7147.2010.05.001
WANG Shitong and CHUNG K F L. On least learning machine[J]. Journal of Jiangnan University:Natural Science Edition, 2010, 9(5): 505–510. doi: 10.3969/j.issn.1671-7147.2010.05.001
|
|
TUR G, DENG Li and HAKKANI-TÜR D, et al. Towards deeper understanding: Deep convex networks for semantic utterance classification[C]. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 2012: 5045-5048. doi: 10.1109/ICASSP.2012.6289054.
|
|
WOLPERT D H. Stacked generalization[J]. Neural Networks, 1992, 5(2): 241–259. doi: 10.1016/s0893-6080(05)80023-1
|
|
ZADEH L A. Fuzzy sets[J]. Information and Control, 1965, 8(3): 338–353. doi: 10.1016/S0019-9958(65)90241-X
|
|
DENG Zhaohong, JIANG Yizhang, CHUNG F L, et al. Knowledge-leverage-based fuzzy system and its modeling[J]. IEEE Transactions on Fuzzy Systems, 2013, 21(4): 597–609. doi: 10.1109/TFUZZ.2012.2212444
|
|
GU Xin, CHUNG F L, ISHIBUCHI H, et al. Multitask coupled logistic regression and its fast implementation for large multitask datasets[J]. IEEE Transactions on Cybernetics, 2015, 45(9): 1953–1966. doi: 10.1109/TCYB.2014.2362771
|
|
BACHE K and LICHMAN M. UCI machine learning repository[EB/OL]. http://archive.ics.uci.edu/ml, 2015.
|
|
ALCALÁ-FDEZ J, FERNÁNDEZ A, LUENGO J, et al. KEEL data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework[J]. Journal of Multiple-Valued Logic & Soft Computing, 2011, 17(2/3): 255–287.
|
|
HINTON G E, OSINDERO S, and TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527–1554. doi: 10.1162/neco.2006.18.7.1527
|
|
CHEN C L P and LIU Zhulin. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(1): 10–24. doi: 10.1109/TNNLS.2017.2716952
|
Figures(4) / Tables(6)



 DownLoad:
DownLoad: