| Citation: | Jin WANG, Ke WANG, Zijian MIN, Kaiwei SUN, Xin DENG. Transfer Weight Based Conditional Adversarial Domain Adaptation[J]. Journal of Electronics & Information Technology, 2019, 41(11): 2729-2735. doi: 10.11999/JEIT190115

|

|
YOSINSKI J, CLUNE J, BENGIO Y, et al. How transferable are features in deep neural networks?[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 3320-3328.
|
|
PAN S J and YANG Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345–1359. doi: 10.1109/TKDE.2009.191
|
|
GEBRU T, HOFFMAN J, LI Feifei, et al. Fine-grained recognition in the wild: A multi-task domain adaptation approach[C]. Proceedings of IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1358–1367.
|
|
GLOROT X, BORDES A, and BENGIO Y. Domain adaptation for large-scale sentiment classification: A deep learning approach[C]. Proceedings of the 28th International Conference on Machine Learning, Bellevue, USA, 2011: 513–520.
|
|
WANG Mei and DENG Weihong. Deep visual domain adaptation: A survey[J]. Neurocomputing, 2018, 312: 135–153. doi: 10.1016/j.neucom.2018.05.083
|
|
GRETTON A, BORGWARDT K, RASCH M, et al. A kernel method for the two-sample-problem[C]. Proceedings of the 19th Conference on Neural Information Processing Systems, Vancouver, Canada, 2007: 513–520.
|
|
LONG Mingsheng, CAO Yue, WANG Jianmin, et al. Learning transferable features with deep adaptation networks[C]. Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 2015: 97–105.
|
|
LONG Mingsheng, ZHU Han, WANG Jianmin, et al. Deep transfer learning with joint adaptation networks[C]. Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 2017: 2208–2217.
|
|
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680.
|
|
GANIN Y, USTINOVA E, AJAKAN H, et al. Domain-adversarial training of neural networks[J]. The Journal of Machine Learning Research, 2016, 17(1): 2096–2030.
|
|
TZENG E, HOFFMAN J, SAENKO K, et al. Adversarial discriminative domain adaptation[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2962–2971.
|
|
MIRZA M and OSINDERO S. Conditional generative adversarial nets[EB/OL]. https://arxiv.org/abs/1411.1784, 2014.
|
|
LONG Mingsheng, CAO Zhangjie, WANG Jianmin, et al. Conditional adversarial domain adaptation[C]. Proceedings of the 32nd Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 1647–1657.
|
|
GRANDVALET Y and BENGIO Y. Semi-supervised learning by entropy minimization[C]. Proceedings of the 17th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2004: 529–536.
|
|
SAENKO K, KULIS B, FRITZ M, et al. Adapting visual category models to new domains[C]. Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 2010: 213–226.
|
|
VENKATESWARA H, EUSEBIO J, CHAKRABORTY S, et al. Deep hashing network for unsupervised domain adaptation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 5385–5394.
|
|
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.
|
|
LONG Mingsheng, ZHU Han, WANG Jianmin, et al. Unsupervised domain adaptation with residual transfer networks[C]. Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 136–144.
|
|
SANKARANARAYANAN S, BALAJI Y, CASTILLO C D, et al. Generate to adapt: Aligning domains using generative adversarial networks[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8503–8512.
|
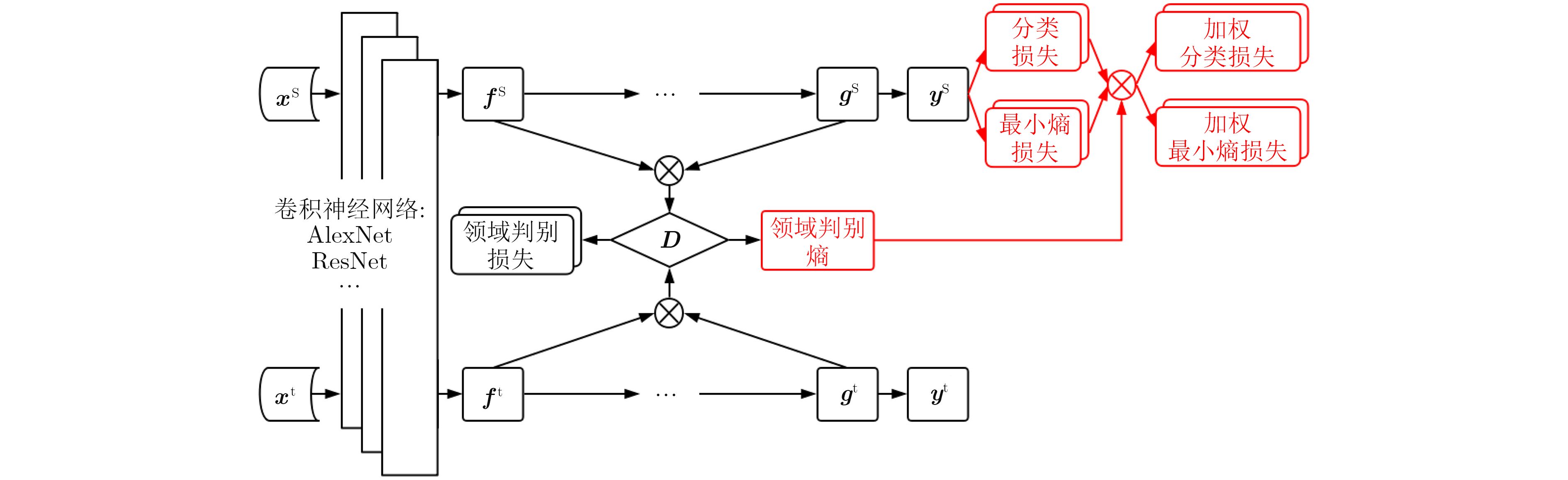
Figures(4) / Tables(3)



 DownLoad:
DownLoad:


