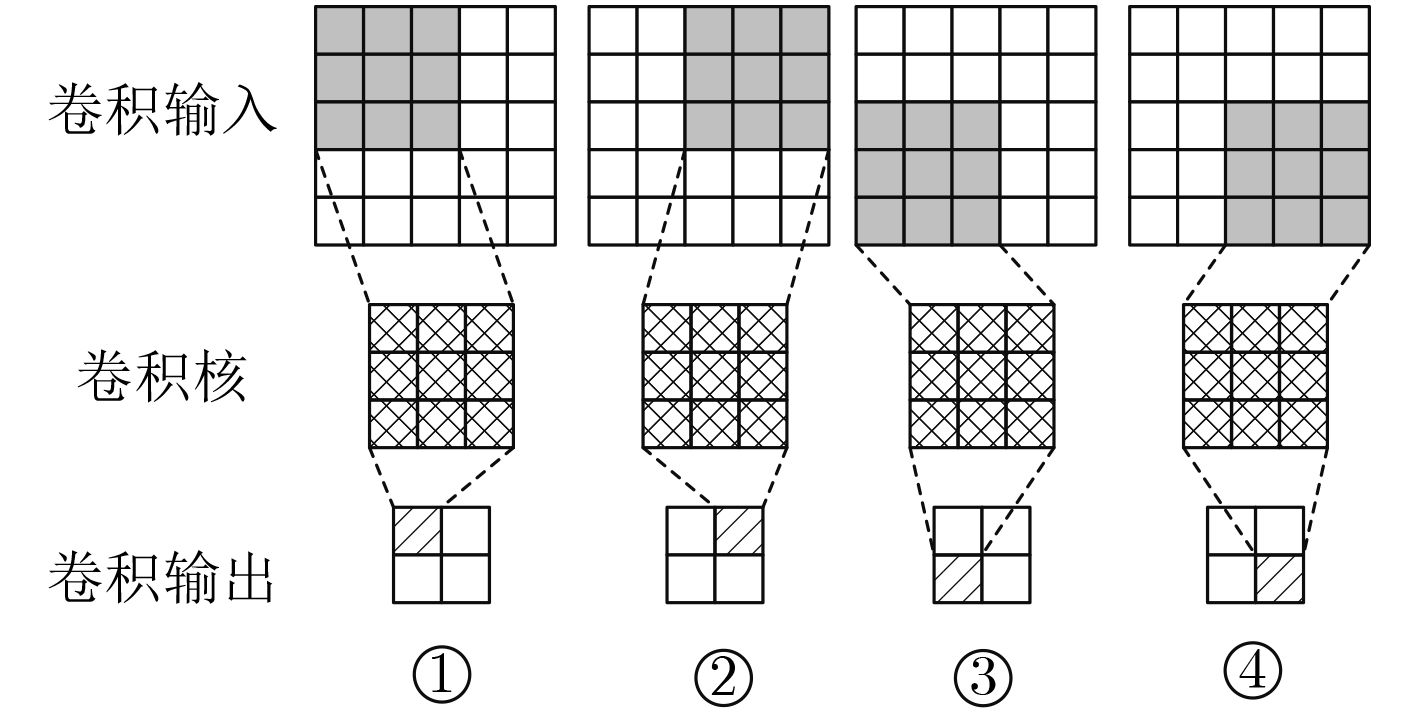
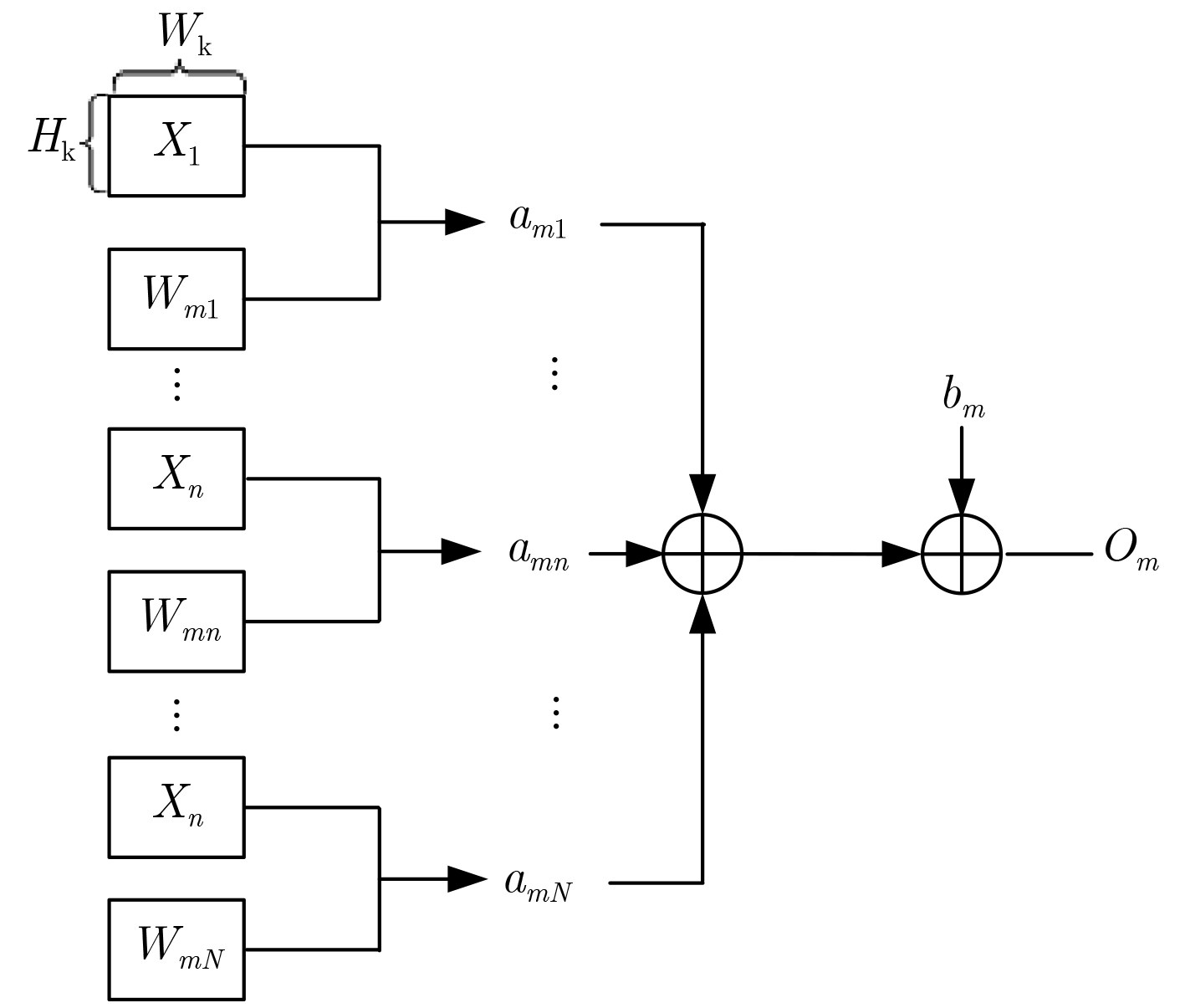
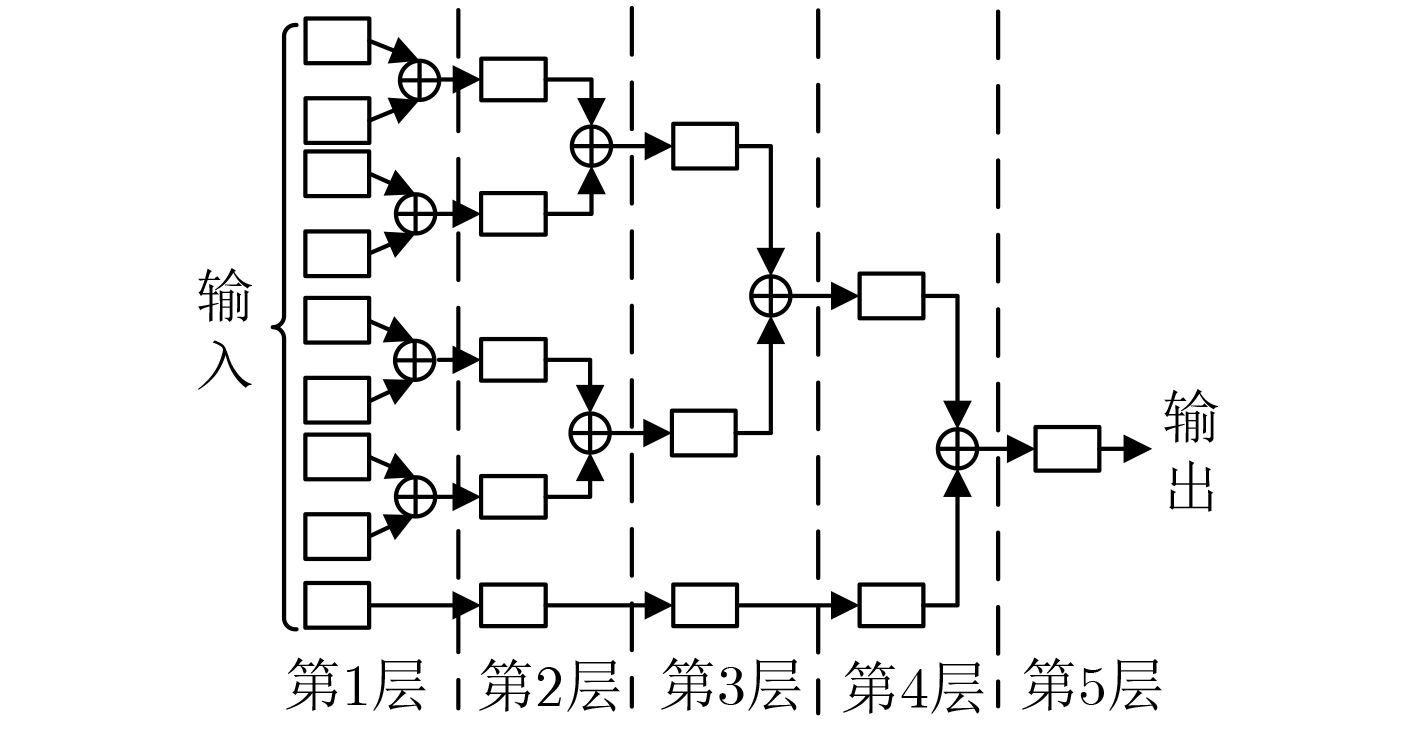
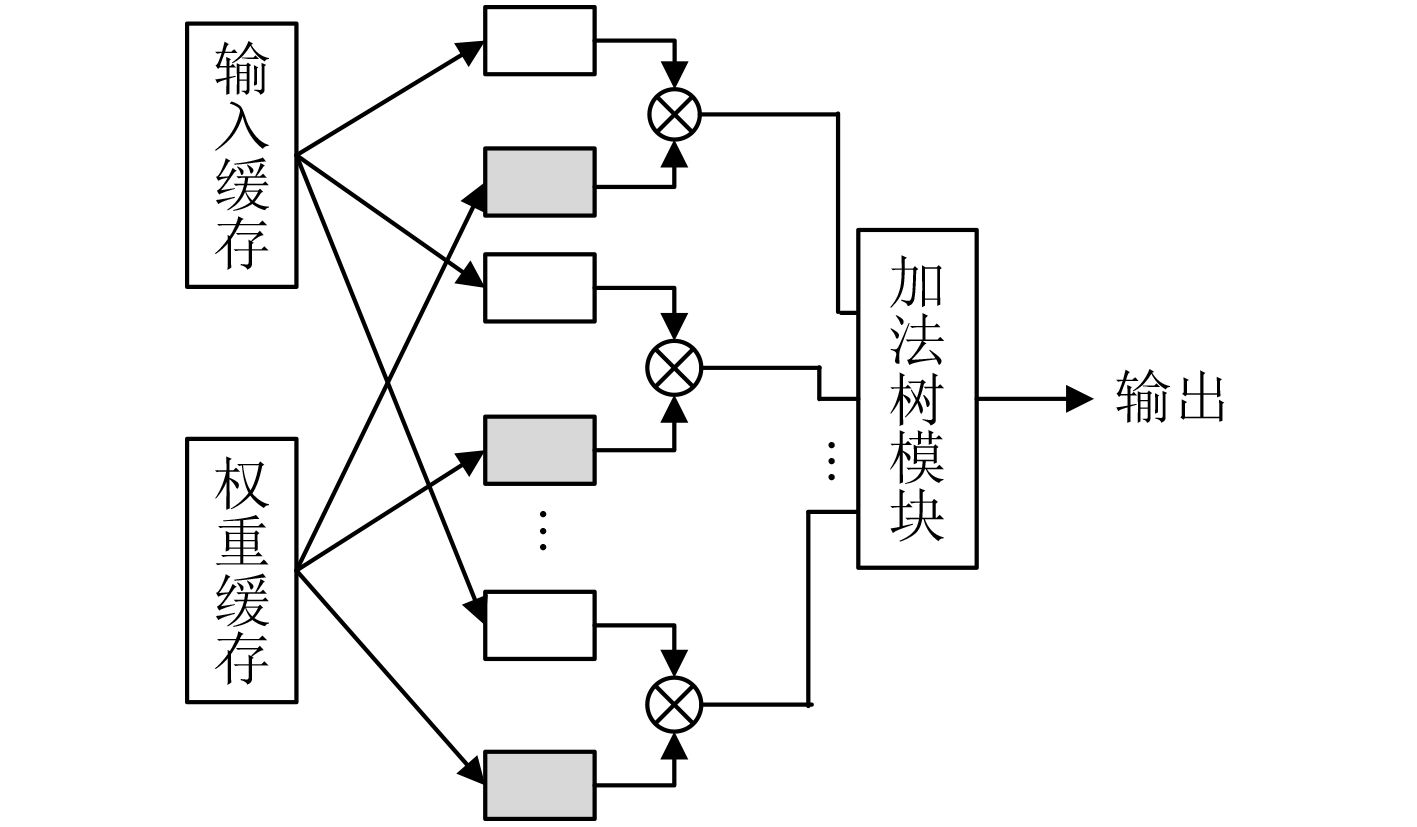
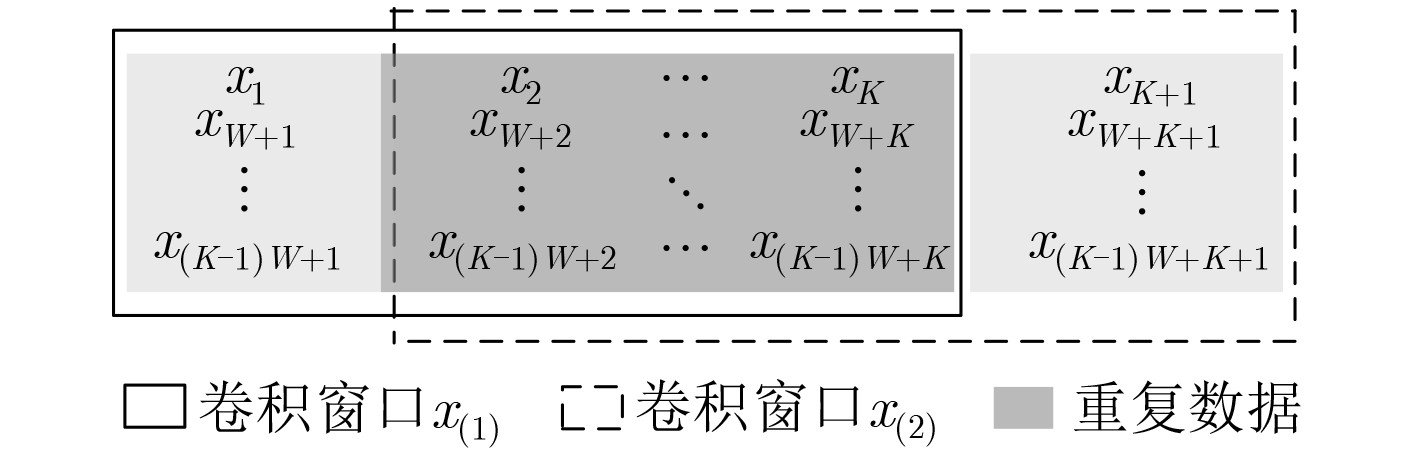
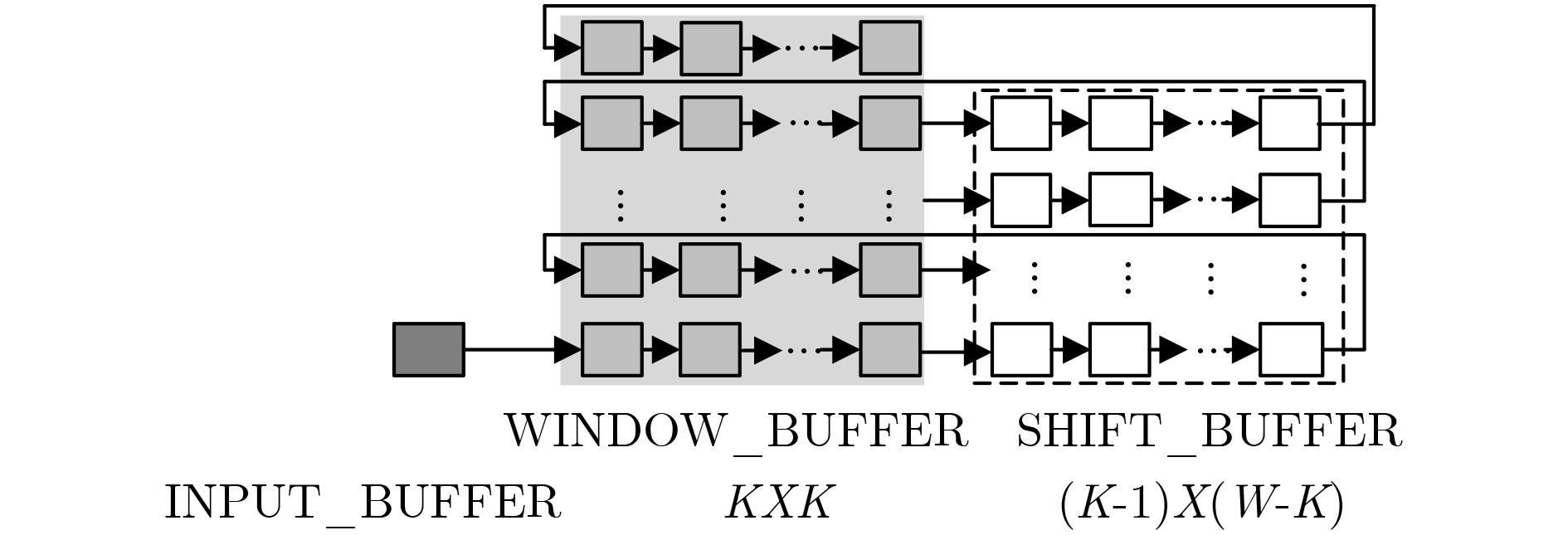
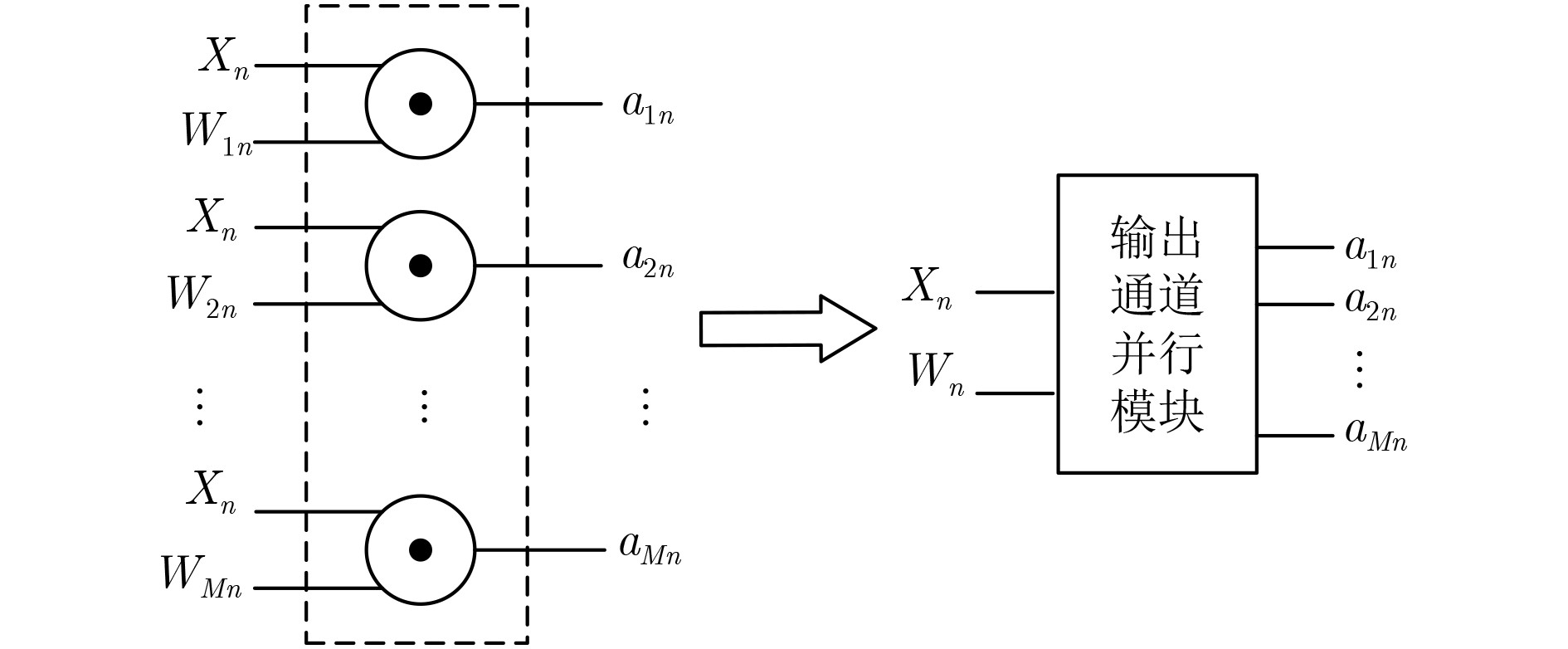
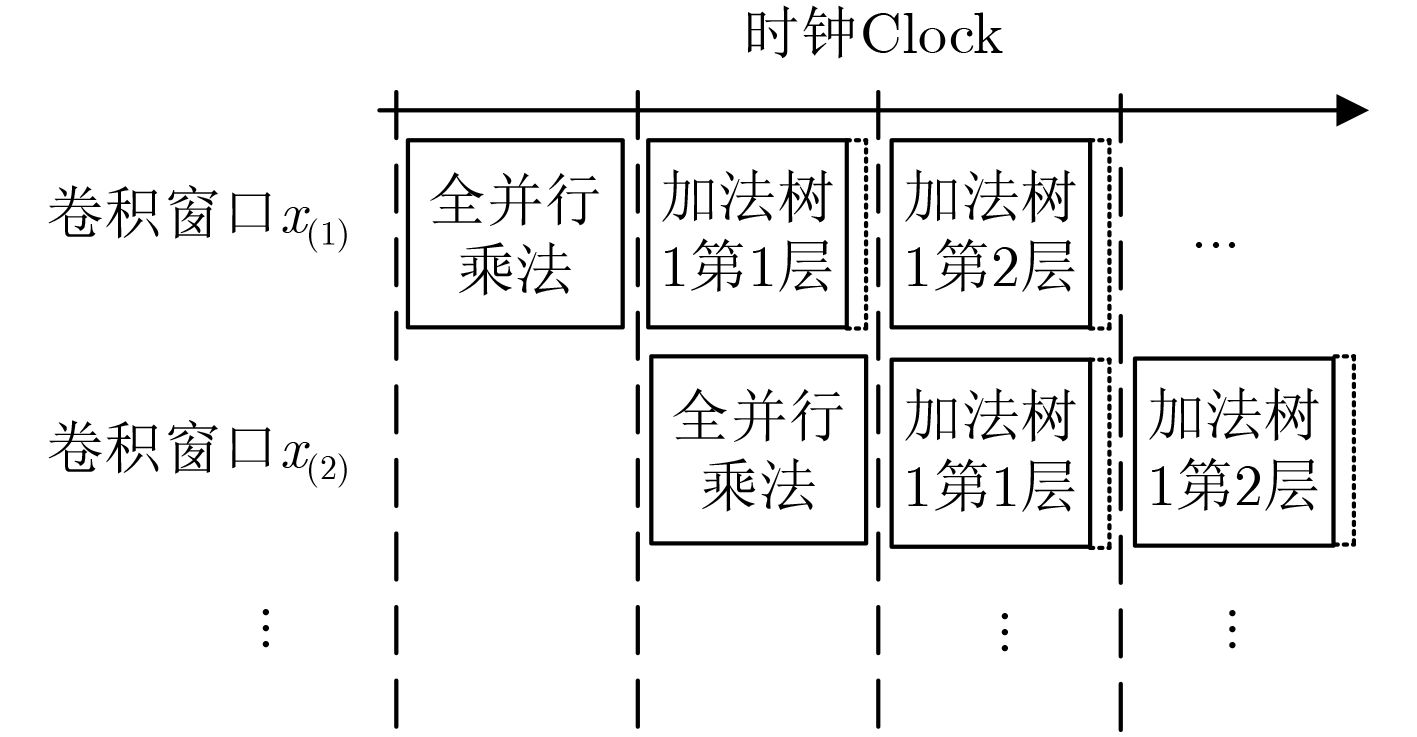
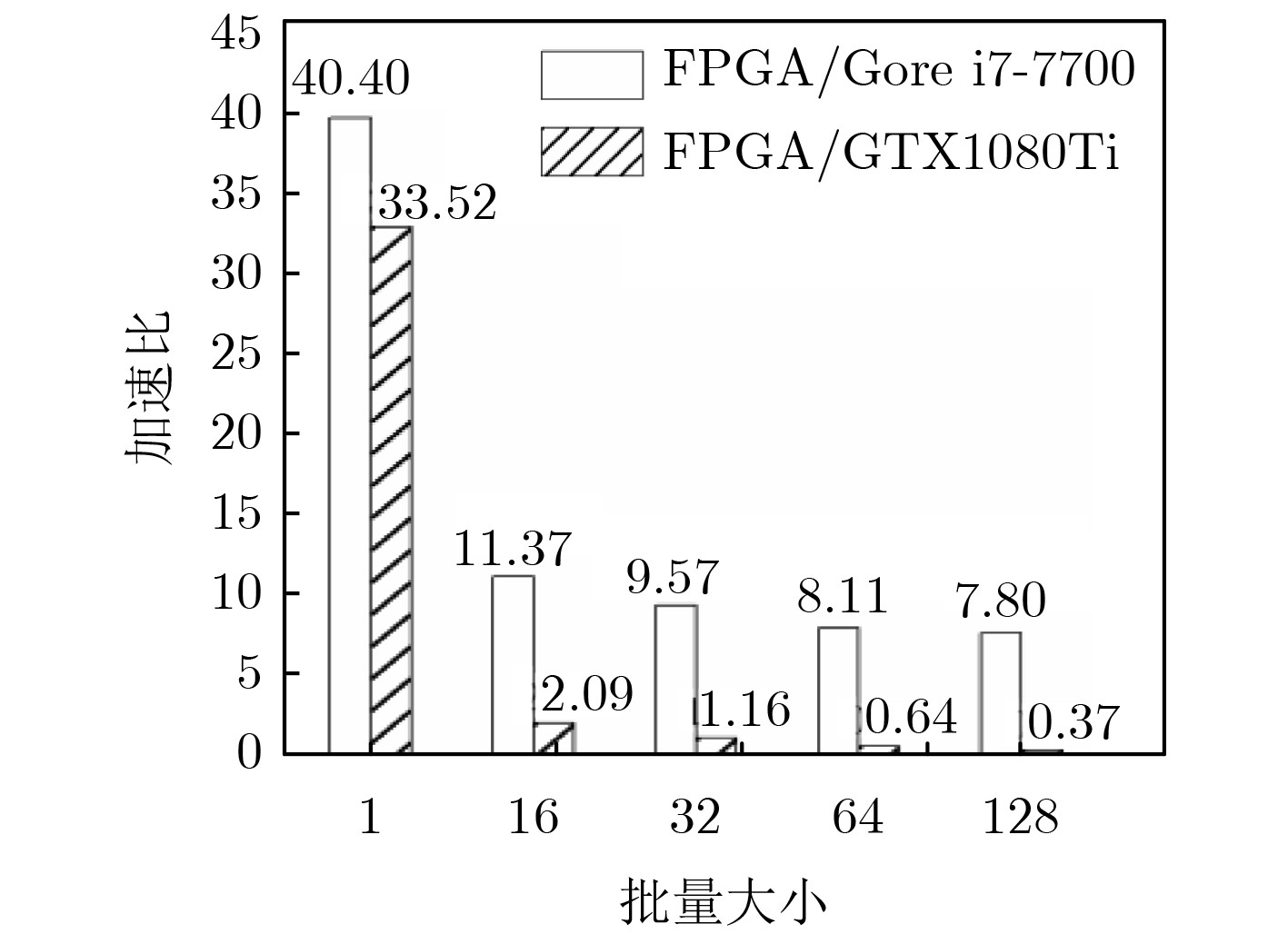
| Citation: | Huabiao QIN, Qinping CAO. Design of Convolutional Neural Networks Hardware Acceleration Based on FPGA[J]. Journal of Electronics & Information Technology, 2019, 41(11): 2599-2605. doi: 10.11999/JEIT190058

|

|
LIU Weibo, WANG Zidong, LIU Xiaohui, et al. A survey of deep neural network architectures and their applications[J]. Neurocomputing, 2017, 234: 11–26. doi: 10.1016/j.neucom.2016.12.038
|
|
HAN Song, MAO Huizi, and DALLY W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv: 1510.00149, 2015.
|
|
COATES A, HUVAL B, WANG Tao, et al. Deep learning with COTS HPC systems[C]. Proceedings of the 30th International Conference on International Conference on Machine Learning, Atlanta, USA, 2013: III-1337–III-1345.
|
|
JOUPPI N P, YOUNG C, PATIL N, et al. In-datacenter performance analysis of a tensor processing unit[C]. Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, Canada, 2017: 1–12. doi: 10.1145/3079856.3080246.
|
|
MOTAMEDI M, GYSEL P, AKELLA V, et al. Design space exploration of FPGA-based deep convolutional neural networks[C]. Proceedings of the 21st Asia and South Pacific Design Automation Conference, Macau, China, 2016: 575–580. doi: 10.1109/ASPDAC.2016.7428073.
|
|
ZHANG Jialiang and LI Jing. Improving the performance of OpenCL-based FPGA accelerator for convolutional neural network[C]. Proceedings of 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2017: 25–34. doi: 10.1145/3020078.3021698.
|
|
QIU Jiantao, WANG Jie, YAO Song, et al. Going deeper with embedded FPGA platform for convolutional neural network[C]. Proceedings of 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2016: 26–35. doi: 10.1145/2847263.2847265.
|
|
余奇. 基于FPGA的深度学习加速器设计与实现[D]. [硕士论文], 中国科学技术大学, 2016: 30–38.
YU Qi. Deep learning accelerator design and implementation based on FPGA[D]. [Master dissertation], University of Science and Technology of China, 2016: 30–38.
|
|
LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791
|
|
ABADI M, BARHAM P, CHEN Jianmin, et al. Tensorflow: A system for large-scale machine learning[C]. Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, USA, 2016: 265–283.
|
|
XIAO Qingcheng, LIANG Yun, LU Liqiang, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs[C]. Proceedings of the 54th Annual Design Automation Conference, Austin, USA, 2017: 62. doi: 10.1145/3061639.3062244.
|
|
SHEN Junzhong, HUANG You, WANG Zelong, et al. Towards a uniform template-based architecture for accelerating 2D and 3D CNNs on FPGA[C]. Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2018: 97–106. doi: 10.1145/3174243.3174257.
|
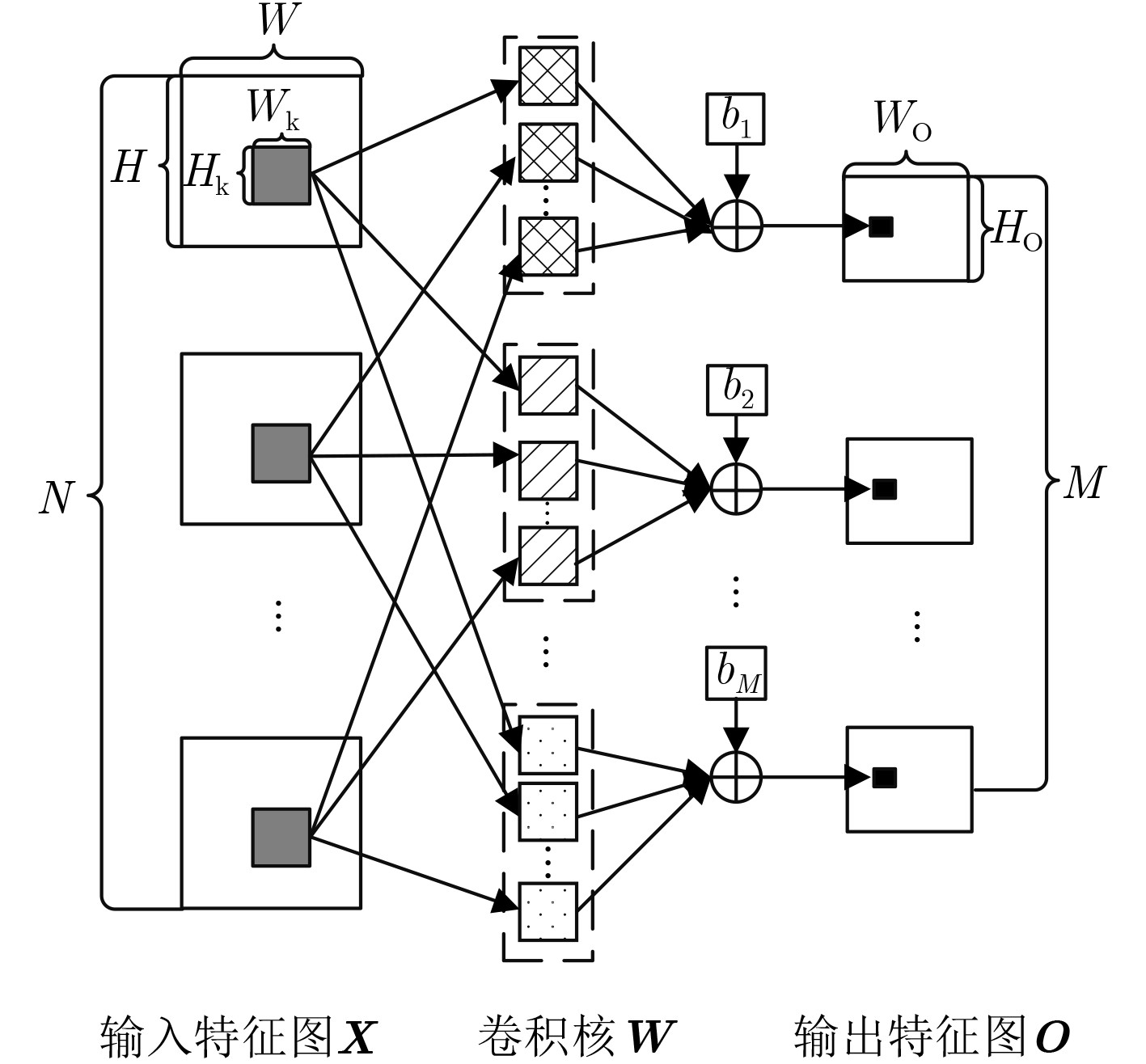
Figures(14) / Tables(3)



 DownLoad:
DownLoad: