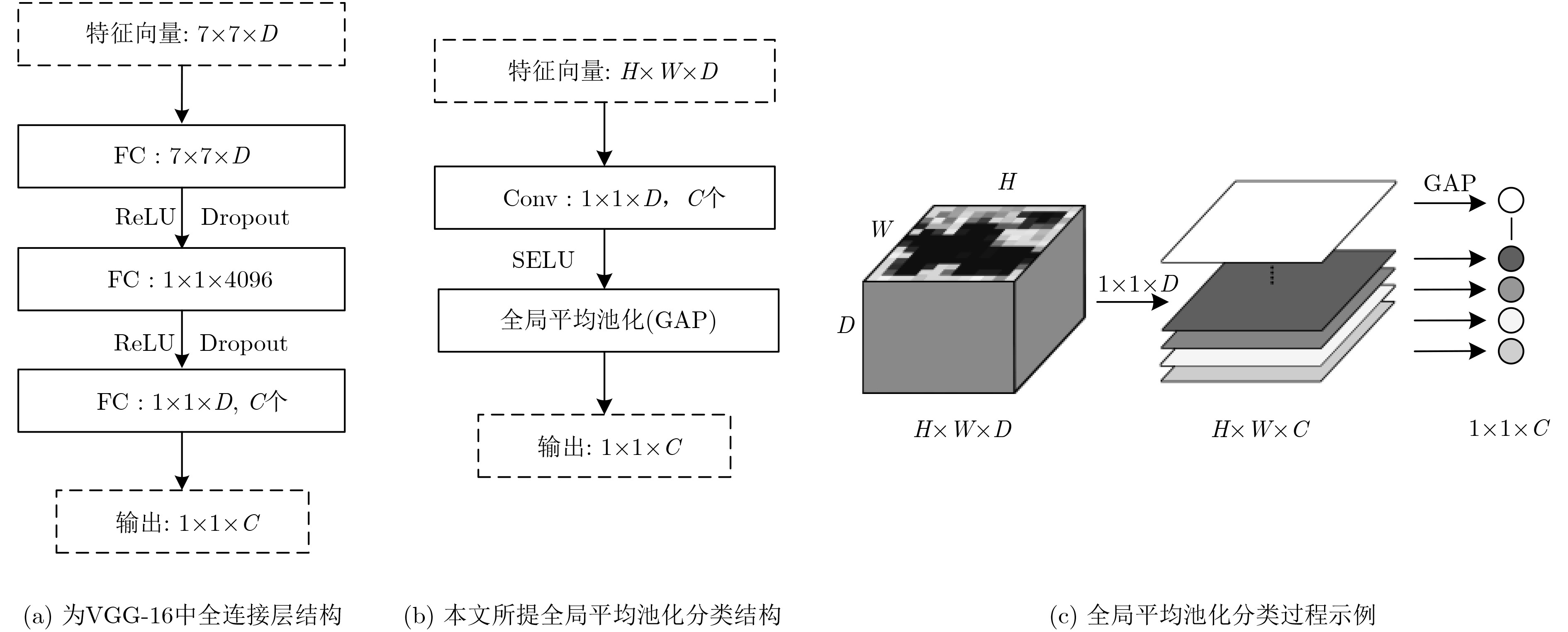
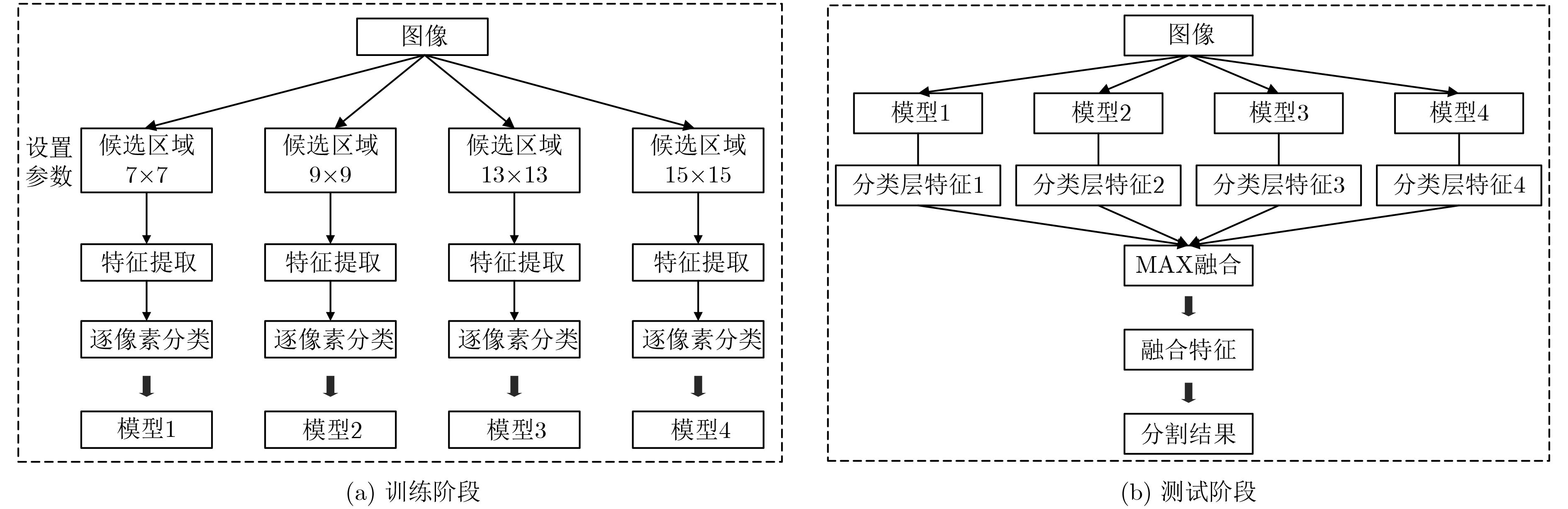
| Citation: | Huilan LUO, Fei LU, Fansheng KONG. Image Semantic Segmentation Based on Region and Deep Residual Network[J]. Journal of Electronics & Information Technology, 2019, 41(11): 2777-2786. doi: 10.11999/JEIT190056

|

|
魏云超, 赵耀. 基于DCNN的图像语义分割综述[J]. 北京交通大学学报, 2016, 40(4): 82–91. doi: 10.11860/j.issn.1673-0291
WEI Yunchao and ZHAO Yao. A review on image semantic segmentation based on DCNN[J]. Journal of Beijing Jiaotong University, 2016, 40(4): 82–91. doi: 10.11860/j.issn.1673-0291
|
|
CARREIRA J, LI Fuxin, and SMINCHISESCU C. Object recognition by sequential figure-ground ranking[J]. International Journal of Computer Vision, 2012, 98(3): 243–262. doi: 10.1007/s11263-011-0507-2
|
|
CARREIRA J, CASEIRO R, BATISTA J, et al. Semantic segmentation with second-order pooling[C]. Proceedings of the 12th European Conference on Computer Vision 2012, Berlin, Germany, 2012: 430–443.
|
|
ARBELÁEZ P, HARIHARAN B, GU Chunhui, et al. Semantic segmentation using regions and parts[C]. Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 3378–3385.
|
|
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2014: 580–587.
|
|
GIRSHICK R. Fast R-CNN[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1440–1448.
|
|
SHELHAMER E, LONG J, and DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(4): 640–651. doi: 10.1109/TPAMI.2016.2572683
|
|
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]. Computer Science, 2015(4): 357–361. doi: 10.1080/17476938708814211
|
|
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184
|
|
UIJLINGS J R R, VAN DE SANDE K E A, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154–171. doi: 10.1007/s11263-013-0620-5
|
|
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824
|
|
YU Tianshu, YAN Junchi, ZHAO Jieyi, et al. Joint cuts and matching of partitions in one graph[C]. Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 705–713.
|
|
HARIHARAN B, ARBELÁEZ P, GIRSHICK R, et al. Simultaneous detection and segmentation[C]. Proceedings of the 13th Conference on Computer Vision, Zurich, Switzerland, 2014: 297–312.
|
|
DAI Jifeng, HE Kaiming, and SUN Jian. Convolutional feature masking for joint object and stuff segmentation[C]. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3992–4000.
|
|
CAESAR H, UIJLINGS J, and FERRARI V. Region-based semantic segmentation with end-to-end training[C]. Proceedings of the 14th European Conference on Computer Vision 2016, Amsterdam, The Netherlands, 2016: 381–397.
|
|
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778.
|
|
YU F and KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. https://arxiv.org/abs/1511.07122, 2015.
|
|
LIN Min, CHEN Qiang, and YAN Shuicheng. Network in network[EB/OL]. https://arxiv.org/abs/1312.4400, 2014.
|
|
LIU Ce, YUEN J, and TORRALBA A. Nonparametric scene parsing via label transfer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(12): 2368–2382. doi: 10.1109/TPAMI.2011.131
|
|
MOTTAGHI R, CHEN Xianjie, LIU Xiaobai, et al. The role of context for object detection and semantic segmentation in the wild[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 891–898.
|
|
YANG Jimei, PRICE B, COHEN S, et al. Context driven scene parsing with attention to rare classes[C]. Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 3294–3301.
|
|
EIGEN D and FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 2650–2658.
|
|
DAI Jifeng, HE Kaiming, and SUN Jian. Boxsup: exploiting bounding boxes to supervise convolutional networks for semantic segmentation[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1635–1643.
|
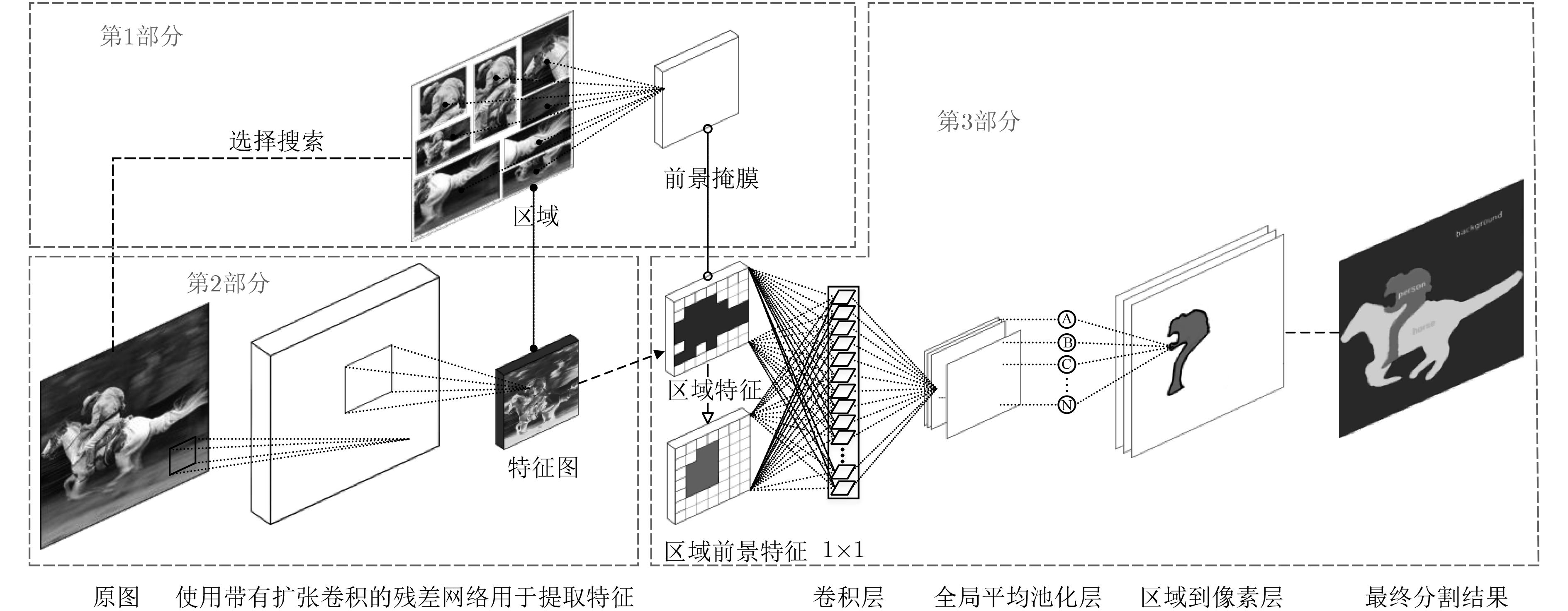
Figures(6) / Tables(4)



 DownLoad:
DownLoad: